Iso/Iec 10646:2017
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

International Standard Iso/Iec 10646
This is a preview - click here to buy the full publication INTERNATIONAL ISO/IEC STANDARD 10646 Sixth edition 2020-12 Information technology — Universal coded character set (UCS) Technologies de l'information — Jeu universel de caractères codés (JUC) Reference number ISO/IEC 10646:2020(E) © ISO/IEC 2020 This is a preview - click here to buy the full publication ISO/IEC 10646:2020 (E) CONTENTS 1 Scope ..................................................................................................................................................1 2 Normative references .........................................................................................................................1 3 Terms and definitions .........................................................................................................................2 4 Conformance ......................................................................................................................................8 4.1 General ....................................................................................................................................8 4.2 Conformance of information interchange .................................................................................8 4.3 Conformance of devices............................................................................................................8 5 Electronic data attachments ...............................................................................................................9 6 General structure -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

CJKV Unified Ideographs Extension C
22nd International Unicode Conference (IUC22) Unicode and the Web: Evolution or Revolution? September 9 - 13, 2002, San Jose, California http://www.unicode.org/iuc/iuc22/ CJKV Unified Ideographs Extension C Richard S. COOK Linguistics Department University of California, Berkeley [email protected] http://stedt.berkeley.edu/ 2002-09-18-10:31 INTRODUCTION This presentation is concerned with introducing the audience to some of the issues surrounding Ideographic Rapporteur Group (ISO/IEC JTC1/SC2/WG2/IRG) work on “CJK Unified Ideographs Extension C” (Ext C), including the following: (1) The IRG methodology constraining glyph submissions for Ext C1 (why more Han characters and which?) (2) The method of preparing glyph submissions for the Unicode Technical Committee (UTC) (3) IRG member submissions for Ext C1, introducing some of the submitted glyphs, the print sources for the glyph submissions (4) The IRG process of submission evaluation (5) The impact of submitted glyphs on the “Han Variant” problem (see Cook, IUC-19) (6) Plans for Ext C2 UTC submissions 22nd International Unicode Conference1 San Jose, California, September 2002 CJKV Unified Ideographs Extension C BACKGROUND As many people already know, The Unicode Standard 3.2 is the best thing ever to happen to the digitization of Chinese texts. The immense work done to produce the CJKV1 part of this standard, undertaken by the Ideographic Rapporteur Group (IRG)2, has pushed CJKV computing to higher levels than many had ever thought possible. With the IRG’s creation of “Extension B”, 42,711 new characters were added to The Unicode Standard, so that it now encodes a total of 70,207 unique “ideographs”.3 The issue is somewhat complicated by things such as “compatibility characters which are not actually compatibility characters”. -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -
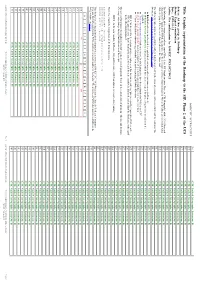
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2/IRG Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2/IRGN2153 SC2N5405 (Revision of IRG N1503/N1772/N1823/N1920/N1942/N1975/N2016/N2092) 2016-10-20 Title: IRG Principles and Procedures(IRG PnP) Version 9 Source: IRG Rapporteur Action: For review by the IRG and WG2 Distribution: IRG Member Bodies and Ideographic Experts Editor in chief: Lu Qin, IRG Rapporteur References: IRG Meeting No. 45 Recommendations(IRGN2150), IRG Special Meeting No. 44 discussions and recommendation No. 44.6(IRGN2080), IRGN2016, and IRGN 1975 and IRG Meeting No. 42 discussions IRGN 1952 and feedback from HKSARG, Japan, ROK and TCA, IRG 1920 Draft(2012-11-15), Draft 2(2013-05-04) and Draft 3(2013-05-22); feedback from Japan(2013-04-23) and ROK(2013-05-16 and 2013-05-21); and IRG Meeting No. 40 discussions IRG 1823 Draft 3 and feedback from HKSAR, Korea and IRG Meeting No. 39 discussions IRGN1823 Draft2 feedback from HKSAR and Japan IRG N1823Draft_gimgs2_Feedback IRG N1781 and N1782 Feedback from KIM Kyongsok IRGN1772 (P&P Version 5) IRG N1646 (P&P Version 4 draft) IRG N1602 (P&P Draft 4) and IRG N1633 (P&P Editorial Report) IRG N1601 (P&P Draft 3 Feedback from HKSAR) IRG N1590 and IRGN 1601(P&P V2 and V3 draft and all feedback) IRG N1562 (P&P V3 Draft 1 and Feedback from HKSAR) IRG N1561 (P&P V2 and all feedback) IRG N1559 (P&P V2 Draft and all feedback) IRG N1516 (P&P V1 Feedback from HKSAR) IRG N1489 (P&P V1 Feedback from Taichi Kawabata) IRG N1487 (P&P V1 Feedback from HKSAR) IRG N1465, IRG N1498 and IRG N1503 (P&P V1 drafts) Table of Contents 1. -

Character and String Representation
Character and String Representation CS520 Department of Computer Science University of New Hampshire CDC 6600 • 6-bit character encodings • i.e. only 64 characters • Designers were not too concerned about text processing! The table is from Assembly Language Programming for the Control Data 6000 series and the Cyber 70 series by Grishman. C Strings • Usually implemented as a series of ASCII characters terminated by a null byte (0x00). • ″abc″ in memory is: n 0x61 n+1 0x62 n+2 0x63 n+3 0x00 Unicode • The space of values is divided into 17 planes. • Plane 0 is the Basic Multilingual Plane (BMP). – Supports nearly all modern languages. – Encodings are 0x0000-0xFFFF. • Planes 1-16 are supplementary planes. – Supports historic scripts and special symbols. – Encodings are 0x10000-0x10FFFF. • Planes are divided into blocks. Unicode and ASCII • ASCII is the bottom block in the BMP, known as the Basic Latin block. • So ASCII values are embedded “as is” into Unicode. • i.e. 'a' is 0x61 in ASCII and 0x0061 in Unicode. Special Encodings • The Byte-Order Mark (BOM) is used to signal endian-ness. • Has no other meaning (i.e. usually ignored). • Encoded as 0xFEFF. • 0xFFFE is a noncharacter. – Cannot appear in any exchange of Unicode. • So file can be started with a BOM; the reader can then know the endian-ness of the file. • In absence of a BOM, Big Endian is assumed. Other Noncharacters • There are a total of 66 noncharacters: – 0xFFFE and 0xFFFF of the BMP – 0x1FFFE and 0x1FFFF of plane 1 – 0x2FFFE and 0x2FFFF of plane 2 – etc., up to – 0x10FFFE and 0x10FFFF of plane 16 – Also 0xFDD0-0xFDEF of the BMP. -

Section 18.1, Han
The Unicode® Standard Version 13.0 – Core Specification To learn about the latest version of the Unicode Standard, see http://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2020 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at http://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see http://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 13.0. Includes index. ISBN 978-1-936213-26-9 (http://www.unicode.org/versions/Unicode13.0.0/) 1. -

Character Properties 4
The Unicode® Standard Version 14.0 – Core Specification To learn about the latest version of the Unicode Standard, see https://www.unicode.org/versions/latest/. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the publisher was aware of a trade- mark claim, the designations have been printed with initial capital letters or in all capitals. Unicode and the Unicode Logo are registered trademarks of Unicode, Inc., in the United States and other countries. The authors and publisher have taken care in the preparation of this specification, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. © 2021 Unicode, Inc. All rights reserved. This publication is protected by copyright, and permission must be obtained from the publisher prior to any prohibited reproduction. For information regarding permissions, inquire at https://www.unicode.org/reporting.html. For information about the Unicode terms of use, please see https://www.unicode.org/copyright.html. The Unicode Standard / the Unicode Consortium; edited by the Unicode Consortium. — Version 14.0. Includes index. ISBN 978-1-936213-29-0 (https://www.unicode.org/versions/Unicode14.0.0/) 1. -

Proper Display of Bidirectional Structured Text
Proper display of bidirectional structured text Authors ● Aharon Lanin (Google) ● Gilead Almosnino (Microsoft) ● Lina Kemmel (IBM) ● Mati Allouche (former IBM) ● Mohamed Mohie (IBM) ● Tomer Mahlin (IBM) Basic terminology 1. Structured text text with inherent structure which must be preserved during display to assure its readability. This article focuses exclusively on the following types of structured text: a. URI (i.e. http://www.hello.world.com/folder) b. email address (i.e [email protected]) c. regular expression (i.e. [az]{1}) In this article the term also appears abbreviated as STT (structured text). 2. Bidi Bidirectional a. RTL character character which belongs to a language with righttoleft script (e.g. Arabic, Hebrew, Farsi etc.) b. RTL language language with RTL script (e.g. Arabic, Hebrew, Farsi etc.) c. Bidi language1 a synonym for RTL language d. RTL sentence / phrase / message a sentence, message or phrase which belongs to a RTL language (e.g. Arabic, Hebrew, Farsi etc.) e. Bidi text / data / string text which includes RTL characters but not necessarily belongs to a bidi language. It can be an English sentence that includes RTL, e.g a word in Hebrew or Arabic script. 3. BTD – base text direction. The overall direction of a piece of text and a parameter to the UBA. LTR for English sentences. RTL for Arabic and Hebrew sentences. If the incorrect BTD is applied to a piece of text, it may 1 Please note that neither characters nor languages themselves are bidirectional. Each separate character either has a well defined unique direction (e.g.