Quantifying the Direct Overhead of Virtual Function Calls on Massively Parallel Architectures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Improving Virtual Function Call Target Prediction Via Dependence-Based Pre-Computation
Improving Virtual Function Call Target Prediction via Dependence-Based Pre-Computation Amir Roth, Andreas Moshovos and Gurindar S. Sohi Computer Sciences Department University of Wisconsin-Madison 1210 W Dayton Street, Madison, WI 53706 {amir, moshovos, sohi}@cs.wisc.edu Abstract In this initial work, we concentrate on pre-computing virtual function call (v-call) targets. The v-call mecha- We introduce dependence-based pre-computation as a nism enables code reuse by allowing a single static func- complement to history-based target prediction schemes. tion call to transparently invoke one of multiple function We present pre-computation in the context of virtual implementations based on run-time type information. function calls (v-calls), a class of control transfers that As shown in Table 1, v-calls are currently used in is becoming increasingly important and has resisted object-oriented programs with frequencies ranging from conventional prediction. Our proposed technique 1 in 200 to 1000 instructions (4 to 20 times fewer than dynamically identifies the sequence of operations that direct calls and 30 to 150 times fewer than conditional computes a v-call’s target. When the first instruction in branches). V-call importance will increase as object-ori- such a sequence is encountered, a small execution ented languages and methodologies gain popularity. For engine speculatively and aggressively pre-executes the now, v-calls make an ideal illustration vehicle for pre- rest. The pre-computed target is stored and subse- computation techniques since their targets are both diffi- quently used when a prediction needs to be made. We cult to predict and easy to pre-compute. -

Valloy – Virtual Functions Meet a Relational Language
VAlloy – Virtual Functions Meet a Relational Language Darko Marinov and Sarfraz Khurshid MIT Laboratory for Computer Science 200 Technology Square Cambridge, MA 02139 USA {marinov,khurshid}@lcs.mit.edu Abstract. We propose VAlloy, a veneer onto the first order, relational language Alloy. Alloy is suitable for modeling structural properties of object-oriented software. However, Alloy lacks support for dynamic dis- patch, i.e., function invocation based on actual parameter types. VAlloy introduces virtual functions in Alloy, which enables intuitive modeling of inheritance. Models in VAlloy are automatically translated into Alloy and can be automatically checked using the existing Alloy Analyzer. We illustrate the use of VAlloy by modeling object equality, such as in Java. We also give specifications for a part of the Java Collections Framework. 1 Introduction Object-oriented design and object-oriented programming have become predom- inant software methodologies. An essential feature of object-oriented languages is inheritance. It allows a (sub)class to inherit variables and methods from su- perclasses. Some languages, such as Java, only support single inheritance for classes. Subclasses can override some methods, changing the behavior inherited from superclasses. We use C++ term virtual functions to refer to methods that can be overridden. Virtual functions are dynamically dispatched—the actual function to invoke is selected based on the dynamic types of parameters. Java only supports single dynamic dispatch, i.e., the function is selected based only on the type of the receiver object. Alloy [9] is a first order, declarative language based on relations. Alloy is suitable for specifying structural properties of software. Alloy specifications can be analyzed automatically using the Alloy Analyzer (AA) [8]. -

Inheritance & Polymorphism
6.088 Intro to C/C++ Day 5: Inheritance & Polymorphism Eunsuk Kang & JeanYang In the last lecture... Objects: Characteristics & responsibilities Declaring and defining classes in C++ Fields, methods, constructors, destructors Creating & deleting objects on stack/heap Representation invariant Today’s topics Inheritance Polymorphism Abstract base classes Inheritance Types A class defines a set of objects, or a type people at MIT Types within a type Some objects are distinct from others in some ways MIT professors MIT students people at MIT Subtype MIT professor and student are subtypes of MIT people MIT professors MIT students people at MIT Type hierarchy MIT Person extends extends Student Professor What characteristics/behaviors do people at MIT have in common? Type hierarchy MIT Person extends extends Student Professor What characteristics/behaviors do people at MIT have in common? �name, ID, address �change address, display profile Type hierarchy MIT Person extends extends Student Professor What things are special about students? �course number, classes taken, year �add a class taken, change course Type hierarchy MIT Person extends extends Student Professor What things are special about professors? �course number, classes taught, rank (assistant, etc.) �add a class taught, promote Inheritance A subtype inherits characteristics and behaviors of its base type. e.g. Each MIT student has Characteristics: Behaviors: name display profile ID change address address add a class taken course number change course classes taken year Base type: MITPerson -

CSE 307: Principles of Programming Languages Classes and Inheritance
OOP Introduction Type & Subtype Inheritance Overloading and Overriding CSE 307: Principles of Programming Languages Classes and Inheritance R. Sekar 1 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Topics 1. OOP Introduction 3. Inheritance 2. Type & Subtype 4. Overloading and Overriding 2 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Section 1 OOP Introduction 3 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding OOP (Object Oriented Programming) So far the languages that we encountered treat data and computation separately. In OOP, the data and computation are combined into an “object”. 4 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP more convenient: collects related information together, rather than distributing it. Example: C++ iostream class collects all I/O related operations together into one central place. Contrast with C I/O library, which consists of many distinct functions such as getchar, printf, scanf, sscanf, etc. centralizes and regulates access to data. If there is an error that corrupts object data, we need to look for the error only within its class Contrast with C programs, where access/modification code is distributed throughout the program 5 / 52 OOP Introduction Type & Subtype Inheritance Overloading and Overriding Benefits of OOP (Continued) Promotes reuse. by separating interface from implementation. We can replace the implementation of an object without changing client code. Contrast with C, where the implementation of a data structure such as a linked list is integrated into the client code by permitting extension of new objects via inheritance. Inheritance allows a new class to reuse the features of an existing class. -

Inheritance | Data Abstraction Z Information Hiding, Adts | Encapsulation | Type Extensibility for : COP 3330
OOP components Inheritance | Data Abstraction z Information Hiding, ADTs | Encapsulation | Type Extensibility For : COP 3330. z Operator Overloading Object oriented Programming (Using C++) | Inheritance http://www.compgeom.com/~piyush/teach/3330 z Code Reuse | Polymorphism Piyush Kumar “Is a” Vs “Has a” Another Example UML Vehicle Inheritance class Car : public Vehicle { public: Considered an “Is a” class relationship // ... Car }; e.g.: An HourlyEmployee “is a” Employee A Convertible “is a” Automobile We state the above relationship in several ways: * Car is "a kind of a" Vehicle A class contains objects of another class * Car is "derived from" Vehicle as it’s member data * Car is "a specialized" Vehicle * Car is the "subclass" of Vehicle Considered a “Has a” class relationship * Vehicle is the "base class" of Car * Vehicle is the "superclass" of Car (this not as common in the C++ community) e.g.: One class “has a” object of another class as it’s data Virtual Functions Virtual Destructor rule | Virtual means “overridable” | If a class has one virtual function, you | Runtime system automatically invokes want to have a virtual destructor. the proper member function. | A virtual destructor causes the compiler to use dynamic binding when calling the destructor. | Costs 10% to 20% extra overhead compared to calling a non-virtual | Constructors: Can not be virtual. You function call. should think of them as static member functions that create objects. 1 Pure virtual member Pure virtual. functions. | A pure virtual member function is a | Specified by writing =0 after the member function that the base class function parameter list. forces derived classes to provide. -

Virtual Function in C++
BCA SEMESTER-II Object Oriented Programming using C++ Paper Code: BCA CC203 Unit :4 Virtual Function in C++ By: Ms. Nimisha Manan Assistant Professor Dept. of Computer Science Patna Women’s College Virtual Function When the same function name is defined in the base class as well as the derived class , then the function in the base class is declared as Virtual Function. Thus a Virtual function can be defined as “ A special member function that is declared within a base class and redefined by a derived class is known as virtual function”. To declare a virtual function, in the base class precede the function prototype with the keyword virtual. Syntax for defining a virtual function is as follows:- virtual return_type function_name(arguments) { ------ } Through virtual function, functions of the base class can be overridden by the functions of the derived class. With the help of virtual function, runtime polymorphism or dynamic polymorphism which is also known as late binding is implemented on that function. A function call is resolved at runtime in late binding and so compiler determines the type of object at runtime. Late binding allows binding between the function call and the appropriate virtual function (to be called) to be done at the time of execution of the program. A class that declares or inherits a virtual function is called a polymorphic class. For Example: Virtual void show() { Cout<<”This is a virtual function”; } Implementation of Dynamic Polymorphism through Virtual Function Dynamic Polymorphism is implemented through virtual function by using a single pointer to the base class that points to all the objects of derived class classes. -

All Your Base Transactions Belong to Us
All Your Base Transactions Belong to Us Jeff Vance, Alex Melikian Verilab, Inc Austin, TX, USA www.verilab.com ABSTRACT Combining diverse transaction classes into an integrated testbench, while common practice, typically produces a cumbersome and inadequate setup for system-level verification. UVM sequence item classes from different VIPs typically have different conventions for storing, printing, constraining, comparing, and covering behavior. Additionally, these classes focus on generic bus aspects and lack context for system coverage. This paper solves these problems using the mixin design pattern to supplement all transaction classes with a common set of metadata and functions. A mixin solution can be applied to any project with minimal effort to achieve better visibility of system-wide dataflow. This setup enables significantly faster debug time, higher quality bug reports, and increases the efficiency of the verification team. Combining a mixin with an interface class results in a powerful and extensible tool for verification. We show how to define more accurate transaction coverage with extensible covergroups that are reusable with different transaction types. Scoreboard complexity is reduced with virtual mixin utility methods, and stimulus is managed with shared constraints for all interface traffic. Finally, we show this solution can be retrofitted to any legacy UVM testbench using standard factory overrides. SNUG 2019 Table of Contents 1. Introduction ........................................................................................................................................................................... -

Importance of Virtual Function, Function Call Binding, Virtual Functions, Implementing Late Binding, Need for Virtual Functions
Object Oriented Programming Using C++ Unit 7th Semester 4th Importance of virtual function, function call binding, virtual functions, implementing late binding, need for virtual functions, abstract base classes and pure virtual functions, virtual destructors _______________________________________________________________________________ Importance of virtual function: A virtual function is a member function that is declared within a base class and redefined by a derived class. To create virtual function, precede the function’s declaration in the base class with the keyword virtual. When a class containing virtual function is inherited, the derived class redefines the virtual function to suit its own needs. Virtual Functions are used to support "Run time Polymorphism". You can make a function virtual by preceding its declaration within the class by keyword 'virtual'. When a Base Class has a virtual member function, any class that inherits from the Base Class can redefine the function with exactly the same prototype i.e. only functionality can be redefined, not the interface of the function. A Base class pointer can be used to point to Base Class Object as well as Derived Class Object. When the virtual function is called by using a Base Class Pointer, the Compiler decides at Runtime which version of the function i.e. Base Class version or the overridden Derived Class version is to be called. This is called Run time Polymorphism. What is Virtual Function? A virtual function is a member function within the base class that we redefine in a derived class. It is declared using the virtual keyword. When a class containing virtual function is inherited, the derived class redefines the virtual function to suit its own needs. -
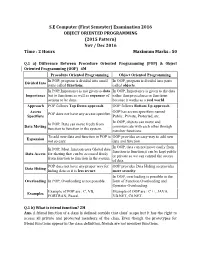
Examination 2016 OBJECT ORIENTED PROGRAMMING (2015 Pattern) Nov / Dec 2016 Time : 2 Hours Maximum Marks : 50
S.E Computer (First Semester) Examination 2016 OBJECT ORIENTED PROGRAMMING (2015 Pattern) Nov / Dec 2016 Time : 2 Hours Maximum Marks : 50 Q.1 a) Difference Between Procedure Oriented Programming (POP) & Object Oriented Programming (OOP) 4M Procedure Oriented Programming Object Oriented Programming In POP, program is divided into small In OOP, program is divided into parts Divided Into parts called functions. called objects. In POP,Importance is not given to data In OOP, Importance is given to the data Importance but to functions as well as sequence of rather than procedures or functions actions to be done. because it works as a real world. Approach POP follows Top Down approach. OOP follows Bottom Up approach. Access OOP has access specifiers named POP does not have any access specifier. Specifiers Public, Private, Protected, etc. In OOP, objects can move and In POP, Data can move freely from Data Moving communicate with each other through function to function in the system. member functions. To add new data and function in POP is OOP provides an easy way to add new Expansion not so easy. data and function. In OOP, data can not move easily from In POP, Most function uses Global data function to function,it can be kept public Data Access for sharing that can be accessed freely or private so we can control the access from function to function in the system. of data. POP does not have any proper way for OOP provides Data Hiding so provides Data Hiding hiding data so it is less secure. more security. In OOP, overloading is possible in the Overloading In POP, Overloading is not possible. -

Learn Objective–C on The
CYAN YELLOW SPOT MATTE MAGENTA BLACK PANTONE 123 C BOOKS FOR PROFESSIONALS BY PROFESSIONALS® Companion eBook Available Learn Objective-CLearn • Learn the native programming language for Mac OS X, Everything You Need to Know as well as the iPhone! to Become an Objective-C Guru • Get up and running quickly with Objective-C. We don’t waste time teaching you basic programming; instead, we focus on what makes Objective-C di!erent and cool. • Learn about sophisticated programming concepts, including object-oriented programming, the Open-Closed Principle, refactoring, key-value coding, and predicates. n this book, you’ll !nd a full exploration of the Objective-C programming Ilanguage, the primary language for creating Mac OS X and iPhone applica- tions. There are goodies here for everyone, whether you’re just starting out as a Mac developer or a grizzled programmer coming from another language. You’ll discover all of the object-oriented purity and Smalltalk heritage coolness of Objective-C—such as instantiation, protocols for multiple inheritance, dynamic typing, and message forwarding. Along the way, you’ll meet Xcode, the Mac development environment, and you’ll learn about Apple’s Cocoa toolkit. on the Nearly everyone wants to be able to develop for Mac OS X or the iPhone these days, and it’s no wonder. The Mac is a fun and powerful platform, and Objective-C is a wonderful language for writing code. You can have a great time programming the Mac in Objective-C. We do, and want you to join us! Mark Dalrymple is a longtime Mac and Unix programmer who has Mac code running all over the world. -

Introduction to Object-Oriented Programming (OOP)
QUIZ Write the following for the class Bar: • Default constructor • Constructor • Copy-constructor • Overloaded assignment oper. • Is a destructor needed? Or Foo(x), depending on how we want the initialization to be made. Criticize! Ch. 15: Polymorphism & Virtual Functions Virtual functions enhance the concept of type. There is no analog to the virtual function in a traditional procedural language. As a procedural programmer, you have no referent with which to think about virtual functions, as you do with almost every text other feature in the language. Features in a procedural language can be understood on an algorithmic level, but, in an OOL, virtual functions can be understood only from a design viewpoint. Remember upcasting Draw the UML diagram! We would like the more specific version of play() to be called, since flute is a Wind object, not a generic Instrument. Ch. 1: Introduction to Objects Remember from ch.1 … Early binding vs. late binding “The C++ compiler inserts a special bit of code in lieu of the absolute call. This code calculates the text address of the function body, using information stored in the object at runtime!” Ch. 15: Polymorphism & Virtual Functions virtual functions To cause late binding to occur for a particular function, C++ requires that you use the virtual keyword when declaring the function in the base text class. All derived-class functions that match the signature of the base-class declaration will be called using the virtual mechanism. example It is legal to also use the virtual keyword in the derived-class declarations, but it is redundant and can be confusing. -

Virtual Base Class, Overloading and Overriding Design Pattern in Object Oriented Programming with C++
Asian Journal of Computer Science And Information Technology 7: 3 July (2017) 68 –71. Contents lists available at www.innovativejournal.in Asian Journal of Computer Science And Information Technology Journal Homepage: http://innovativejournal.in/ajcsit/index.php/ajcsit VIRTUAL BASE CLASS, OVERLOADING AND OVERRIDING DESIGN PATTERN IN OBJECT ORIENTED PROGRAMMING WITH C++ Dr. Ashok Vijaysinh Solanki Assistant Professor, College of Applied Sciences and Professional Studies, Chikhli ARTICLE INFO ABSTRACT Corresponding Author: The objective of this research paper is to discuss prime concept Dr. Ashok Vijaysinh Solanki of inheritance in object oriented programming. Inheritance play major role in Assistant Professor, College of design pattern of modern programming concept. In this research paper I Applied Sciences and Professional explained about inheritance and reusability concepts of oops. Since object Studies, Chikhli oriented concepts has been introduced in modern days technology it will be assist to creation of reusable software. Inheritance and polymorphism play Key Words: Inheritance; vital role for code reusability. OOPs have evolved to improve the quality of the Encapsulation; Polymorphism; programs. I also discuss about the relationship between function overloading, Early binding; Late binding. operator overloading and run-time polymorphism. Key focus of this research paper is to discuss new approach of inheritance mechanism which helps to solve encapsulation issues. Through virtual base class concept we explore the relationship and setup connection between code reusability and inheritance. Paper explained virtual base class, early binding and late binding concepts DOI:http://dx.doi.org/10.15520/ using coding demonstration. ajcsit.v7i3.63 ©2017, AJCSIT, All Right Reserved. I INTRODUCTION Object oriented programming model is modern such as hierarchical and multiple inheritances which is practical approach and it is important programming known as pure hybrid inheritance.