Downloaded Can Be Instantly Recorded and Counted
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Citebase Search: Autonomous Citation Database for E-Print Archives
Citebase Search: Autonomous Citation Database for e-Print Archives Citebase Search: Autonomous Citation Database for e-Print Archives Tim Brody <[email protected]> Intelligence, Agents, Multimedia Group University of Southampton Abstract Citebase is a culmination of the Opcit Project and the Open Archives Initiative. The Opcit Project's aim to citation-link arXiv.org was coupled with the interoperability of the OAI to develop a cross-archive search engine with the ability to harvest, parse, and link research paper bibliographies. These citation links create a classic citation database which is used to generate citation analysis and navigation over the e- print literature. Citebase is now linked from arXiv.org, alongside SLAC/SPIRES, and is integrated with e- Prints.org repositories using Paracite. Introduction Citebase Search is a Web service that harvests research articles from online, e- print archives (both pre- and post- peer-reviewed articles). Citebase parses references from the full-text, citation-linking those references to the cited articles. This is the basis for a classical citation database. Citebase was first announced in December 2001 [1], although it was not until Citebase was integrated in August 2002 with arXiv.org that any sizeable number of users started to use Citebase. As an add-on to arXiv.org, arXiv provides links from its abstract pages to the equivalent abstract page in Citebase. Citebase currently draws most of its traffic from users following these links, without them then going onto use Citebase’s own search service (see Figure 1). In the first section I will introduce the motivation behind Citebase, section 2 gives some of the structure of the system, section 3 introduces the service as seen by the user and section 4 gives an example of some of the data mining that can be performed on Citebase’s database. -

Open Access Self-Archiving: an Author Study
Open access self-archiving: An author study May 2005 Alma Swan and Sheridan Brown Key Perspectives Limited 48 Old Coach Road, Playing Place, TRURO, Cornwall, TR3 6ET, UK (Registered Office) Tel. +44 (0)1392 879702 www.keyperspectives.co.uk www.keyperspectives.com CONTENTS Executive summary 1. Introduction 1 2. The respondents 7 3. Open access journals 10 4. The use of research information 13 4.1 Ease of access to work-related information 13 4.2 Age of articles most commonly used 13 4.3 Respondents’ publishing activities 17 4.3.1 Number of articles published 17 4.3.2 Respondents’ citation records 20 4.3.3 Publishing objectives 23 4.4 Searching for information 23 4.4.1 Research articles in closed archives 24 4.4.2 Research articles in open archives 24 5. Self-archiving 26 5.1 Self-archiving experience 26 5.1.1 The level of self-archiving activity 26 5.1.2 Length of experience of self-archiving 38 5.2 Awareness of self-archiving as a means to providing open access 43 5.3 Motivation issues 49 5.4 The mechanics of self-archiving 51 5.4.1 Who has actually done the depositing? 51 5.4.2 How difficult is it to self-archive? 51 5.4.3 How long does it take to self-archive? 53 5.4.4 Preservation of archived articles 55 5.4.5 Copyright 56 5.4.6 Digital objects being deposited in open archives 57 5.4.7 Mandating self-archiving? 62 6. Discussion 69 References 74 Appendices: Appendix 1: Reasons for publishing in open access journals, by subject area (table) 77 Appendix 2: Reasons for publishing in open access journals, by subject area (verbatim responses) 79 Appendix 3: Reasons for not publishing in open access journals, by subject area (table) 83 Appendix 4: Reasons for not publishing in open access journals, by subject area (verbatim responses) 86 Appendix 5: Ease of access to research articles needed for work, by subject area 93 Appendix 6: Reasons for publishing research results (verbatim responses) 94 Appendix 7: Use of closed archives: results broken down by subject area 97 Tables 1. -

Astronomy Libraries – Your Gateway to Information
Scientific Writing for Young Astronomers C. Sterken, Ed. EAS Publications Series (to be published) www.eas-journal.org ASTRONOMY LIBRARIES – YOUR GATEWAY TO INFORMATION Uta Grothkopf1 Abstract. This chapter reviews services offered by astronomy libraries for as- sisting astronomers in their research. Special attention is given to the two most important information tools in astronomy: the NASA Astrophysics Data Sys- tem (ADS) and the arXiv e-print server. Some less known features will be presented to lead to more efficient use of these tools. The core astronomy jour- nals are explained, along with the open access concept and how it interacts with existing journals. The chapter also provides an introduction to bibliomet- ric studies and shows why publication and citation statistics are important for both researchers and observatories. Finally, examples of cooperation between librarians and astronomers are presented in the context of working groups and conferences. 1 Introduction The world of libraries is changing fast. The times when they were simply repositories of printed documents are long gone, because preserving the astronomy legacy and being curators of historic documents is important, but is not the only challenge librarians meet today. In the internet era, librarians deliver services directly to the scienstist’s desktop, either by providing access to scientific journals and databases through assistance in us- ing specific information tools or simply by answering reference questions via email or messaging systems. Astronomy libraries are a good example of this changing paradigm, because the vast majority of information resources are available electronically, and most astronomers are used to, and actually prefer, online resources over printed formats. -
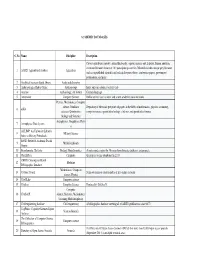
Academic Databases
ACADEMIC DATABASES S. No. Name Discipline Description Covers agriculture, forestry, animal husbandry, aquatic sciences and fisheries, human nutrition, extension literature from over 100 participating countries. Material includes unique grey literature 1 AGRIS: Agricultural database Agriculture such as unpublished scientific and technical reports, theses, conference papers, government publications, and more. 2 Analytical sciences digital library Analytical chemistry 3 Anthropological Index Online Anthropology Index only (no abstracts or full-text). 4 Arachne Archaeology, Art history German language 5 Arnetminer Computer Science Online service used to index and search academic social networks Physics, Mathematics, Computer science, Nonlinear Repository of electronic pre-prints of papers in the fields of mathematics, physics, astronomy, 6 arXiv sciences, Quantitative computer science, quantitative biology, statistics, and quantitative finance. biology and Statistics Astrophysics, Geophysics, Physi 7 Astrophysics Data System cs AULIMP: Air University Library's 8 Military Science Index to Military Periodicals BASE: Bielefeld Academic Search 9 Multidisciplinary Engine 10 Bioinformatic Harvester Biology, Bioinformatics A meta search engine for 50 major bioinformatic databases and projects. 11 ChemXSeer Chemistry the projects seems abandoned in 2018 CHBD: Circumpolar Health 12 Medicine Bibliographic Database Mathematics, Computer 13 Citebase Search Semi-autonomous citation index of free online research science, Physics 14 CiteULike Computer science -

Open Access Bibliography
open access bibliography Open Access Bibliography Liberating Scholarly Literature with E-Prints and Open Access Journals Charles W. Bailey, Jr. Association of Research Libraries 2005 Association of Research Libraries 21 Dupont Circle, NW, Suite 800 Washington, D.C. 20036 © 2005 Charles W. Bailey, Jr. This work is licensed under the Creative Commons Attribution-NonCommercial License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc/2.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA. ISBN 1-59407-670-7 ISBN 978-1-59407-670-1 � The paper used in this publication meets the requirements of ANSI/NISO Z39.48-1992 (R1997) Permanence of Paper for Publications and Documents in Libraries and Archives. Design and layout by David S. Noble. contents preface xi acknowledgments xv key open access concepts xvi i. general works 3 1.1 Overviews 3 1.2 Analysis and Critiques 6 1.3 Debates and Dialogs 10 1.3.1 Nature Web Debate on Future E-Access to the Primary Literature 10 1.3.2 Nature Web Focus on Access to the Literature: The Debate Continues 13 1.3.3 Other 15 1.4 Research Studies 15 1.5 Other 16 ii. open access statements 20 2.1 Berlin Declaration on Open Access to Knowledge in the Sciences and Humanities 20 2.2 Bethesda Statement on Open Access 20 2.3 Budapest Open Access Initiative 20 2.4 NEAR 21 2.5 OECD Final Communique 22 2.6 Tempe Principles 22 2.7 Washington D.C. -

A Scalable Architecture for Harvest-Based Digital Libraries Xiaoming Liu Old Dominion University
Old Dominion University ODU Digital Commons Computer Science Faculty Publications Computer Science 2002 A Scalable Architecture for Harvest-Based Digital Libraries Xiaoming Liu Old Dominion University Tim Brody Stevan Harnard Les Carr Kurt Maly Old Dominion University See next page for additional authors Follow this and additional works at: https://digitalcommons.odu.edu/computerscience_fac_pubs Part of the Computer Sciences Commons, and the Digital Communications and Networking Commons Repository Citation Liu, Xiaoming; Brody, Tim; Harnard, Stevan; Carr, Les; Maly, Kurt; Zubair, Mohammad; and Nelson, Michael L., "A Scalable Architecture for Harvest-Based Digital Libraries" (2002). Computer Science Faculty Publications. 34. https://digitalcommons.odu.edu/computerscience_fac_pubs/34 Original Publication Citation Liu, X., Brody, T., Harnad, S., Carr, L., Maly, K., Zubair, M., & Nelson, M.L. (2002). A scalable architecture for harvest-based digital libraries. D-Lib Magazine, 8(11), 1-16. doi: 10.1045/november2002-liu This Article is brought to you for free and open access by the Computer Science at ODU Digital Commons. It has been accepted for inclusion in Computer Science Faculty Publications by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. Authors Xiaoming Liu, Tim Brody, Stevan Harnard, Les Carr, Kurt Maly, Mohammad Zubair, and Michael L. Nelson This article is available at ODU Digital Commons: https://digitalcommons.odu.edu/computerscience_fac_pubs/34 A Scalable Architecture for Harvest-Based Digital Libraries: The ODU/Southampton Experiments Search | Back Issues | Author Index | Title Index | Contents D-Lib Magazine November 2002 Volume 8 Number 11 ISSN 1082-9873 A Scalable Architecture for Harvest-Based Digital Libraries The ODU/Southampton Experiments Xiaoming Liu, Tim Brody*, Stevan Harnad*, Les Carr*, Kurt Maly, Mohammad Zubair, Michael L.