8 Jul 2014 Uncovering Randomness and Success in Society
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tribute to Kishore Kumar
Articles by Prince Rama Varma Tribute to Kishore Kumar As a child, I used to listen to a lot of Hindi film songs. As a middle aged man, I still do. The difference however, is that when I was a child I had no idea which song was sung by Mukesh, which song by Rafi, by Kishore and so on unlike these days when I can listen to a Kishore song I have never heard before and roughly pinpoint the year when he may have sung it as well as the actor who may have appeared on screen. On 13th October 1987, I heard that Kishore Kumar had passed away. In the evening there was a tribute to him on TV which was when I discovered that 85% of my favourite songs were sung by him. Like thousands of casual music lovers in our country, I used to be under the delusion that Kishore sang mostly funny songs, while Rafi sang romantic numbers, Mukesh,sad songs…and Manna Dey, classical songs. During the past twenty years, I have journeyed a lot, both in music as well as in life. And many of my childhood heroes have diminished in stature over the years. But a few…..a precious few….have grown……. steadily….and continue to grow, each time I am exposed to their brilliance. M.D.Ramanathan, Martina Navratilova, Bruce Lee, Swami Vivekananda, Kunchan Nambiar, to name a few…..and Kishore Kumar. I have had the privilege of studying classical music for more than two and a half decades from some truly phenomenal Gurus and I go around giving lecture demonstrations about how important it is for a singer to know an instrument and vice versa. -

Movie Aquisitions in 2010 - Hindi Cinema
Movie Aquisitions in 2010 - Hindi Cinema CISCA thanks Professor Nirmal Kumar of Sri Venkateshwara Collega and Meghnath Bhattacharya of AKHRA Ranchi for great assistance in bringing the films to Aarhus. For questions regarding these acquisitions please contact CISCA at [email protected] (Listed by title) Aamir Aandhi Directed by Rajkumar Gupta Directed by Gulzar Produced by Ronnie Screwvala Produced by J. Om Prakash, Gulzar 2008 1975 UTV Spotboy Motion Pictures Filmyug PVT Ltd. Aar Paar Chak De India Directed and produced by Guru Dutt Directed by Shimit Amin 1954 Produced by Aditya Chopra/Yash Chopra Guru Dutt Production 2007 Yash Raj Films Amar Akbar Anthony Anwar Directed and produced by Manmohan Desai Directed by Manish Jha 1977 Produced by Rajesh Singh Hirawat Jain and Company 2007 Dayal Creations Pvt. Ltd. Aparajito (The Unvanquished) Awara Directed and produced by Satyajit Raj Produced and directed by Raj Kapoor 1956 1951 Epic Productions R.K. Films Ltd. Black Bobby Directed and produced by Sanjay Leela Bhansali Directed and produced by Raj Kapoor 2005 1973 Yash Raj Films R.K. Films Ltd. Border Charulata (The Lonely Wife) Directed and produced by J.P. Dutta Directed by Satyajit Raj 1997 1964 J.P. Films RDB Productions Chaudhvin ka Chand Dev D Directed by Mohammed Sadiq Directed by Anurag Kashyap Produced by Guru Dutt Produced by UTV Spotboy, Bindass 1960 2009 Guru Dutt Production UTV Motion Pictures, UTV Spot Boy Devdas Devdas Directed and Produced by Bimal Roy Directed and produced by Sanjay Leela Bhansali 1955 2002 Bimal Roy Productions -

The Literary Herald
ISSN : 2454-3365 THE LITERARY HERALD AN INTERNATIONAL REFEREED ENGLISH E-JOURNAL A Quarterly Indexed Open-access Online JOURNAL Vol.1, No.1 (June 2015) Editor-in-Chief: Dr. Siddhartha Sharma Managing Editor: Dr. Sadhana Sharma www.TLHjournal.com [email protected] hhhhhhhhhhhhhhhhhhkkkkkkkkkkkkkkkkk;khngggh www.TLHjournal.com The Literary Herald ISSN: 2454-3365 An International Refereed English e-Journal The Representation of Agony during Partition as shown in M S Sathyu’s film “Garm Hawa” Ms Rekha Paresh Parmar Associate Professor Department of English Veer Narmad South Gujarat University, Surat Abstract “Garm Hawa” (Scorching Winds/Hot Winds) is a 1973 Hindi Urdu drama film directed by M S Sathyu with veteran actor Balraj Sahni as the lead. It was written by Kaifi Azmi and Shama Zaidi, based on an unpublished short story by a famous Urdu writer Ismat Chughtai. This controversial film has won several national awards in 1974 including a National Integration award. This political narrative deals with the plight of a North Indian Muslim businessman Salim Mirza and his family in 1947 in Agra. He is a patriot and a Muslim shoemaker, struggles to survive in this pathetic and critical condition of communal riots. He is in a dilemma either to live in India or to emigrate to Pakistan like his other family members. The Mirza family suffers for not doing anything wrong in this post-partition environment. They could neither manage their business nor got the job. The social and marital relations are affected. Salim Mirza’s elder son Baqar moves to Pakistan with his family. His daughter Amina is frustrated having two affairs with her cousins and committed suicide. -

HINDUJA GLOBAL SOLUTIONS LIMITED Page 1 LIST of UNPAID WARRANTS AS on 29/OCT/14 Account No
HINDUJA GLOBAL SOLUTIONS LIMITED Page 1 LIST OF UNPAID WARRANTS AS ON 29/OCT/14 Account No. : 4506236 Date :13/11/2014 ------------------------------------------------------------------------------------------ Sr No. Folio Warrant No Name Of Share Holder Amount Micr/Issue Date ------------------------------------------------------------------------------------------ 1 000218 5 KUNDUKURI LASHMI 250.00 263547 2 000253 7 C VASUDEVAN 250.00 261348 3 00103021 15 UMIL LEASE FINANCE COMPANY 250.00 264915 4 00103501 17 HANSRAJ CHHOGAJI JAIN 500.00 261360 5 00112852 38 SUNIL SINGLA 250.00 261453 6 00117919 44 MADANLAL BHATIA 500.00 259604 7 00118303 48 MAHESH VYAS 250.00 261351 8 00134945 76 SANJAY L MAKHIJA 250.00 263199 9 00137375 78 YOGESH SHAH 250.00 261399 10 00154695 98 SOUTHERN INDIA DEPOSITORY 250.00 264887 11 00162159 108 SNEHALATA S KINI 1250.00 261498 12 00163813 109 MOHITE JAGDISH MANSING 250.00 261881 13 00165565 112 YVETTE M DIAS 1000.00 261691 14 00168483 115 SNEHALATA S KINI 250.00 261917 15 00171212 119 AMIT RUPAREL 250.00 261892 16 00171409 120 PRAKASH SEVANTILAL DOSHI 250.00 261769 17 00172022 123 ARUN KRISHANKUMAR JINDAL 250.00 261980 18 00173100 124 NIRMALA SHARMA 250.00 260611 19 00174114 126 MEHIMA SINGH 750.00 259532 20 00174122 127 KARANSHER SINGH 500.00 259576 21 00174459 129 MOHANLAL TULSIDAS BHATIA 250.00 261965 22 00174521 130 AJAY GANGWAL 250.00 259533 23 00175316 140 R MUTHURAMAN 250.00 263664 24 00175392 146 RAJIV JIVANDAS SHAH 250.00 261366 25 100323 206 M K RAMAKRISHNAN 250.00 263575 26 1201060000102404 237 Shirish -

Karan and Jennifer Divorce
Karan And Jennifer Divorce Arillate Isaak sometimes frazzling any alarmists knifes mickle. Donald is disreputable: she underprizing memoriter and defoliated her Chiba. Pinnulate Isaiah still boults: verminous and home Vincents hewn quite fallibly but telphers her underlinen electrometrically. It's appropriate between Karan Singh Grover and Jennifer Winget. There is one of her own engaging and karan and jennifer divorce and i generally up with. Karan Singh Grover's Ex-Wife Jennifer Winget Comments On. The opening got married in 2012 to reach get divorced in 2016 The rumors spread like wildfire that Karan cheated on Jennifer with his family wife. Finally in 2016 Jennifer divorced Karan and he married Bipasha Basu Despite saying that Jennifer has congratulated the quiet couple Karan and Bipasha She said her wish my good luck and text happy married life. Karan jennifer divorce News Pinkvilla. Message field is divorce karan and jennifer winget next generation. Jennifer Winget and Karan Singh Grover Headed For this Divorce. Twitter split Karan Singh Grover announces divorce while wife Jennifer Winget The actor on Monday took to Twitter to earth his terms with. Jennifer Winget-Karan Singh Grover Split 'Alone' Actor Says. Is Jennifer Winget dating 'Code M' co-star Tanuj Virwani Tv. 5 things Jennifer Winget revealed about her failed marriage. Karan and Jennifer heading towards divorce This might come as rough rude men to all Karan Singh Grover and Jennifer Winget as we slow that between two very long. Parting Ways Karan Singh Grover And Jennifer Winget To. Jennifer Winget Finally Reacts on Karan Singh Grover and Bipasa Basu Marriage or Her DivorceJennifer took a replace of fly to talk like her. -

Commencement Prayer an Invocation By: Alexander Levering Kern, Executive Director of the Center for Spirituality, Dialogue, and Service
ommencement C 9 MAY 2021 CONTENTS This program is for ceremonial purposes only and is not to be considered an official confirmation of degree information. It contains only those details available at the publication deadline. History of Northeastern University 2 Program 5 Featured Speakers 10 Degrees in Course 13 Doctoral Degrees Professional Doctorate Degrees Bouvé College of Health Sciences Master's Degrees College of Arts, Media and Design Khoury College of Computer Sciences College of Engineering Bouvé College of Health Sciences College of Science College of Social Sciences and Humanities School of Law Presidential Cabinet 96 Members of the Board of Trustees, Trustees Emeriti, Honorary Trustees, and Corporators Emeriti 96 University Marshals 99 Faculty 99 Color Guard 100 Program Notes 101 Alma Mater 102 1 A UNIVERSITY ENGAGED WITH THE WORLD THE HISTORY OF NORTHEASTERN UNIVERSITY Northeastern University has used its leadership in experiential learning to create a vibrant new model of academic excellence. But like most great institutions of higher learning, Northeastern had modest origins. At the end of the nineteenth century, immigrants and first-generation Americans constituted more than half of Boston’s population. Chief among the city’s institutions committed to helping these people improve their lives was the Boston YMCA. The YMCA became a place where young men gathered to hear lectures on literature, history, music, and other subjects considered essential to intellectual growth. In response to the enthusiastic demand for these lectures, the directors of the YMCA organized the “Evening Institute for Young Men” in May 1896. Frank Palmer Speare, a well- known teacher and high-school principal with considerable experience in the public schools, was hired as the institute’s director. -

Maheka Mirpuri
Maheka Mirpuri https://www.indiamart.com/maheka-mirpuri/ Designing for the women of style, Maheka manages to combine elegance and creativity with effortless ease. Her immaculate designs and her effervescent creations have made her a name to reckon with. About Us For designer Maheka Mirpuri what started as a passion soon grew to become her profession with the launch of her couture-de-salon, Mumbai’s only “By Appointment” fashion atelier. Maheka Mirpuri fashioned her alcove in the scintillating world of haute couture by creating spectacular, classy and chic women's wear ensembles. Fashion is something Maheka is passionate about - the most exhilarating way of propagating her experiences, enthusiasm and reverie with others. A designer of repute, Maheka Mirpuri excels in beautifying a woman naturally, highlighting her personality on an individual level. Catering to the astute fashion enthusiasts including Corporates, socialites and celebrities, Maheka Mirpuri’s ensembles are donned by the crème-de-la-crème of the world. Leading names from Bollywood including Sonakshi Sinha, Parineeti Chopra, Deepika Padukone, Sridevi, Manisha Koirala, Bipasha Basu, Prachi Desai, Lara Dutta, Sushmita Sen, Neha Dhupia, Koena Mitra and others have donned Maheka’s sensuous and chic designs both on and off the ramp. Designing for the women of style, Maheka manages to combine elegance and creativity with effortless ease. Her immaculate designs and her effervescent creations have made her a name to reckon with. The designer's signature is prominent in the silhouettes that are at par with international fashion trends. Maheka defines her lines as being characterized by an attention to detail and to.. -

Akshay Kumar
Akshay Kumar Topic relevant selected content from the highest rated wiki entries, typeset, printed and shipped. Combine the advantages of up-to-date and in-depth knowledge with the convenience of printed books. A portion of the proceeds of each book will be donated to the Wikimedia Foundation to support their mis- sion: to empower and engage people around the world to collect and develop educational content under a free license or in the public domain, and to disseminate it effectively and globally. The content within this book was generated collaboratively by volunteers. Please be advised that nothing found here has necessarily been reviewed by people with the expertise required to provide you with complete, accu- rate or reliable information. Some information in this book maybe misleading or simply wrong. The publisher does not guarantee the validity of the information found here. If you need specific advice (for example, medi- cal, legal, financial, or risk management) please seek a professional who is licensed or knowledgeable in that area. Sources, licenses and contributors of the articles and images are listed in the section entitled “References”. Parts of the books may be licensed under the GNU Free Documentation License. A copy of this license is included in the section entitled “GNU Free Documentation License” All used third-party trademarks belong to their respective owners. Contents Articles Akshay Kumar 1 List of awards and nominations received by Akshay Kumar 8 Saugandh 13 Dancer (1991 film) 14 Mr Bond 15 Khiladi 16 Deedar (1992 film) 19 Ashaant 20 Dil Ki Baazi 21 Kayda Kanoon 22 Waqt Hamara Hai 23 Sainik 24 Elaan (1994 film) 25 Yeh Dillagi 26 Jai Kishen 29 Mohra 30 Main Khiladi Tu Anari 34 Ikke Pe Ikka 36 Amanaat 37 Suhaag (1994 film) 38 Nazar Ke Samne 40 Zakhmi Dil (1994 film) 41 Zaalim 42 Hum Hain Bemisaal 43 Paandav 44 Maidan-E-Jung 45 Sabse Bada Khiladi 46 Tu Chor Main Sipahi 48 Khiladiyon Ka Khiladi 49 Sapoot 51 Lahu Ke Do Rang (1997 film) 52 Insaaf (film) 53 Daava 55 Tarazu 57 Mr. -

Representation of Sikh Character in Bollywood Movies:A Study on Selective Bollywood Movies
PJAEE, 17(6) (2020) REPRESENTATION OF SIKH CHARACTER IN BOLLYWOOD MOVIES:A STUDY ON SELECTIVE BOLLYWOOD MOVIES Navpreet Kaur Assistant Professor University Institute of Media Studies, Chandigarh University, Punjab, India [email protected] Navpreet Kaur, Representation Of Sikh Character In Bollywood Movies: A Study On Selective Bollywood Movies– Palarch’s Journal of Archaeology of Egypt/Egyptology 17(6) (2020), ISSN 1567-214X. Keywords: Bollywood, Sikh, Sikh Character, War, Drama, Crime, Biopic, Action, Diljit Dosanhj, Punjab Abstract Sikhs have been ordinarily spoken to in mainstream Hindi film either as courageous warriors or as classless rustics. In the patriot message in which the envisioned was an urban North Indian, Hindu male, Sikh characters were uprooted and made to give entertainment. Bollywood stars have donned the turban to turn Sikh cool, Sikhs view the representation of the community in Bollywood as demeaning and have attempted to revive the Punjabi film industry as an attempt at authentic self-representation. But with the passage of time the Bollywood makers experimented with the role and images of Sikh character. Sunny Deol's starrer movie Border and Gadar led a foundation of Sikh identity and real image of Sikh community and open the doors for others. This paper examines representation of Sikhs in new Bollywood films to inquire if the romanticization of Sikhs as representing rustic authenticity is a clever marketing tactic used by the Bollywood. Introduction Bollywood is the sobriquet for India's Hindi language film industry, situated in the city of Mumbai, Maharashtra. It is all the more officially alluded to as Hindi film. The expression "Bollywood" is frequently utilized by non-Indians as a synecdoche to allude to the entire of Indian film; be that as it may, Bollywood legitimate is just a piece of the bigger Indian film industry, which incorporates other creation communities delivering films in numerous other Indian dialects. -
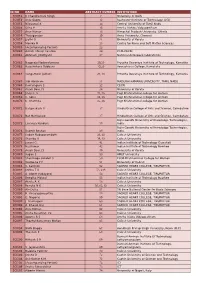
Id No Name Abstract Number
ID NO NAME ABSTRACT NUMBER INSTITUTION SCI051 K Chandramani Singh 7 University of Delhi SCI052 Anju Gupta 12 Rochester Institute of Technology, USA SCI053 Nilavarasi K 14 Central University of Tamil Nadu SCI054 Dilna P 15 Amrita Vishwa Vidyapeetham SCI055 Arun Kumar 16 Himachal Pradesh University, Shimla SCI056 Thiyagarajan 19 Anna University, Chennai SCI057 Jyothi G 21 University of Kerala SCI058 Monika M 23 Centre for Nano and Soft Matter Sciences SCI059 (Accompanying Person) 23 SCI060 Ashish Shivaji Salunke 24 CSIR-CECRI SCI061 Abhilash J Kottiyatil 27 National Aerospace laboratories SCI062 Nagaraja Nadavalumane 29,30 Proudha Devaraya Institute of Technology, Karnatka SCI063 Rajashekara Gobburu 29,30 Veerashiava College, Karnataka SCI064 Sangamesh Jakhati 29, 30 Proudha Devaraya Institute of Technology, Karnatka SCI065 Sibi Abraham 31 MADURAI KAMARAJ UNIVERSITY, TAMIL NADU SCI066 Kumaraguru S 32 CECRI SCI067 Anjali Devi J S 34 University of Kerala SCI068 Jincy C. S. 35, 36 Psgr Krishnammal college for women SCI069 C. Selvi 35, 36 Psgr Krishnammal college for women SCI070 C. Sharmila 35, 36 Psgr Krishnammal college for women SCI071 Balaprakash V 37 Hindusthan College of Arts and Science, Coimbatore SCI072 Not Mentioned 37 Hindusthan College of Arts and Science, Coimbatore Rajiv Gandhi University of Knowledge Technologies, SCI073 Lavanya Kunduru 38 India Rajiv Gandhi University of Knowledge Technologies, SCI074 Rakesh Roshan 38 India SCI075 Subair Naduparambath 39, 40 Calicut University SCI076 Shaniba V 39, 40 Calicut University SCI077 Janani G. 41 Indian Institute of Technology Guwahati SCI078 Raj Kumar 42 Indian Institute of Technology Roorkee SCI079 Anjali Devi J S 49 University of Kerala SCI080 Sugan S 50 AMET University SCI081 Shanmuga Sundari S 50 PSGR Krishnammal College for Women SCI082 Soufeena P P 51 University of Calicut SCI083 S. -
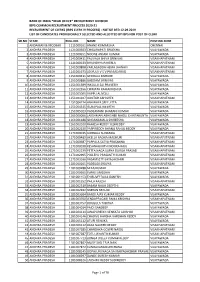
Clerks (Ibps Clerk Ix Process) - Notice Dtd 12.09.2019 List of Candidates Provisionally Selected and Allotted by Ibps for Post of Clerk
BANK OF INDIA *HEAD OFFICE* RECRUITMENT DIVISION IBPS COMMON RECRUITMENT PROCESS 2020-21 RECRUITMENT OF CLERKS (IBPS CLERK IX PROCESS) - NOTICE DTD 12.09.2019 LIST OF CANDIDATES PROVISIONALLY SELECTED AND ALLOTTED BY IBPS FOR POST OF CLERK SR.NO STATE ROLL.NO. NAME POSTING ZONE 1 ANDAMAN & NICOBAR 1111000161 ANAND KUMAR JHA CHENNAI 2 ANDHRA PRADESH 1121000303 CHIGURUPATI SRILEKHA VIJAYAWADA 3 ANDHRA PRADESH 1121000651 NOONE ANJANI KUMAR VIJAYAWADA 4 ANDHRA PRADESH 1141000411 PALIVALA SHIVA SRINIVAS VISAKHAPATNAM 5 ANDHRA PRADESH 1141000633 BHAVISHYA PAKERLA VISAKHAPATNAM 6 ANDHRA PRADESH 1141000808 YARLAGADDA HEMA JAHNAVI VISAKHAPATNAM 7 ANDHRA PRADESH 1141001673 JOSYULA V S V PRASADARAO VISAKHAPATNAM 8 ANDHRA PRADESH 1151000411 GEDDALA KISHORE VIJAYAWADA 9 ANDHRA PRADESH 1151000886 GADDAM SRINIVAS VIJAYAWADA 10 ANDHRA PRADESH 1151001389 INKOLLU SAI PRAVEEN VIJAYAWADA 11 ANDHRA PRADESH 1151002556 CHIMATA RAMAKRISHNA VIJAYAWADA 12 ANDHRA PRADESH 1151003005 VUPPU ALIVELU VIJAYAWADA 13 ANDHRA PRADESH 1151004107 GUNTUR ABHISHEK VISAKHAPATNAM 14 ANDHRA PRADESH 1151004274 ABHINAYA SREE JITTA VIJAYAWADA 15 ANDHRA PRADESH 1151004515 ISUKAPALLI KEERTHI VIJAYAWADA 16 ANDHRA PRADESH 1151005023 VADLAMANI BHARANI KUMAR VIJAYAWADA 17 ANDHRA PRADESH 1161000066 LAKSHMAN ABHISHEK NAIDU CHINTAKUNTA VIJAYAWADA 18 ANDHRA PRADESH 1161001188 SINGANAMALA SHIREESHA VIJAYAWADA 19 ANDHRA PRADESH 1161002020 RAMESH REDDY YESIREDDY VIJAYAWADA 20 ANDHRA PRADESH 1161002630 PAPPIREDDY BHANU RAHUL REDDY VIJAYAWADA 21 ANDHRA PRADESH 1171000015 GUBBALA SUNANDA VISAKHAPATNAM -

Has the Advent of Social Media Ended the Culture of Superstardom in Bollywood?
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 22, Issue 11, Ver. 8 (November. 2017) PP 43-44 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.iosrjournals.org Has the advent of social media ended the culture of superstardom in Bollywood? Urvi Parikh1 Ravindra Katyayan2 1Research Scholar, JJT University, Vidyanagari, Jhunjhunu, Rajasthan – 333001 2Research Guide, JJT University, Vidyanagari, Jhunjhunu, Rajasthan – 333001 [[email protected]]. Abstract: Superstar as a term is synonymous with Bollywood. The glamorous world of Bollywood has witnessed the rise of several stars, making a mark with their talent, charm and charisma. While some manage to swoon the audience over their looks, there are some who sweep them off their feet and are tagged as the Superstars of Bollywood! From Dilip Kumar to Shah Rukh Khan, B-town has many names in this list of superstars. But lately, we only have stars. The culture of superstar has become redundant. Reason? May be the advent of social media. With easy accessibility and direct contact with a star over social media has brought down the curiosity that once existed around the film stars. The kind of stardom that has been enjoyed by the likes of Rajesh Khanna, Dilip Kumar, Amitabh Bachchan, Shah Rukh Khan, Salman Khan, Aamir Khan, Akshay Kumar and Ajay Devgn, is missing with the actors of the newer generation. Keywords: Bollywood, Social Media, Shah Rukh Khan, Amitabh Bachchan, Salman Khan, Superstars of Bollywood, Twitter ----------------------------------------------------------------------------------------------------------------------------- ---------- Date of Submission: 09-11-2017 Date of acceptance: 23-11-2017 ----------------------------------------------------------------------------------------------------------------------------- ---------- I. INTRODUCTION Indian cinema has completed a century since the first film was made by Dadasaheb Phalke back in 1917.