Memorization in Overparameterized Autoencoders
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Harmless Overfitting: Using Denoising Autoencoders in Estimation of Distribution Algorithms
Journal of Machine Learning Research 21 (2020) 1-31 Submitted 10/16; Revised 4/20; Published 4/20 Harmless Overfitting: Using Denoising Autoencoders in Estimation of Distribution Algorithms Malte Probst∗ [email protected] Honda Research Institute EU Carl-Legien-Str. 30, 63073 Offenbach, Germany Franz Rothlauf [email protected] Information Systems and Business Administration Johannes Gutenberg-Universit¨atMainz Jakob-Welder-Weg 9, 55128 Mainz, Germany Editor: Francis Bach Abstract Estimation of Distribution Algorithms (EDAs) are metaheuristics where learning a model and sampling new solutions replaces the variation operators recombination and mutation used in standard Genetic Algorithms. The choice of these models as well as the correspond- ing training processes are subject to the bias/variance tradeoff, also known as under- and overfitting: simple models cannot capture complex interactions between problem variables, whereas complex models are susceptible to modeling random noise. This paper suggests using Denoising Autoencoders (DAEs) as generative models within EDAs (DAE-EDA). The resulting DAE-EDA is able to model complex probability distributions. Furthermore, overfitting is less harmful, since DAEs overfit by learning the identity function. This over- fitting behavior introduces unbiased random noise into the samples, which is no major problem for the EDA but just leads to higher population diversity. As a result, DAE-EDA runs for more generations before convergence and searches promising parts of the solution space more thoroughly. We study the performance of DAE-EDA on several combinatorial single-objective optimization problems. In comparison to the Bayesian Optimization Al- gorithm, DAE-EDA requires a similar number of evaluations of the objective function but is much faster and can be parallelized efficiently, making it the preferred choice especially for large and difficult optimization problems. -

More Perceptron
More Perceptron Instructor: Wei Xu Some slides adapted from Dan Jurfasky, Brendan O’Connor and Marine Carpuat A Biological Neuron https://www.youtube.com/watch?v=6qS83wD29PY Perceptron (an artificial neuron) inputs Perceptron Algorithm • Very similar to logistic regression • Not exactly computing gradient (simpler) vs. weighted sum of features Online Learning • Rather than making a full pass through the data, compute gradient and update parameters after each training example. Stochastic Gradient Descent • Updates (or more specially, gradients) will be less accurate, but the overall effect is to move in the right direction • Often works well and converges faster than batch learning Online Learning • update parameters for each training example Initialize weight vector w = 0 Create features Loop for K iterations Loop for all training examples x_i, y_i … update_weights(w, x_i, y_i) Perceptron Algorithm • Very similar to logistic regression • Not exactly computing gradient Initialize weight vector w = 0 Loop for K iterations Loop For all training examples x_i if sign(w * x_i) != y_i Error-driven! w += y_i * x_i Error-driven Intuition • For a given example, makes a prediction, then checks to see if this prediction is correct. - If the prediction is correct, do nothing. - If the prediction is wrong, change its parameters so that it would do better on this example next time around. Error-driven Intuition Error-driven Intuition Error-driven Intuition Exercise Perceptron (vs. LR) • Only hyperparameter is maximum number of iterations (LR also needs learning rate) • Guaranteed to converge if the data is linearly separable (LR always converge) objective function is convex What if non linearly separable? • In real-world problems, this is nearly always the case. -

Training Autoencoders by Alternating Minimization
Under review as a conference paper at ICLR 2018 TRAINING AUTOENCODERS BY ALTERNATING MINI- MIZATION Anonymous authors Paper under double-blind review ABSTRACT We present DANTE, a novel method for training neural networks, in particular autoencoders, using the alternating minimization principle. DANTE provides a distinct perspective in lieu of traditional gradient-based backpropagation techniques commonly used to train deep networks. It utilizes an adaptation of quasi-convex optimization techniques to cast autoencoder training as a bi-quasi-convex optimiza- tion problem. We show that for autoencoder configurations with both differentiable (e.g. sigmoid) and non-differentiable (e.g. ReLU) activation functions, we can perform the alternations very effectively. DANTE effortlessly extends to networks with multiple hidden layers and varying network configurations. In experiments on standard datasets, autoencoders trained using the proposed method were found to be very promising and competitive to traditional backpropagation techniques, both in terms of quality of solution, as well as training speed. 1 INTRODUCTION For much of the recent march of deep learning, gradient-based backpropagation methods, e.g. Stochastic Gradient Descent (SGD) and its variants, have been the mainstay of practitioners. The use of these methods, especially on vast amounts of data, has led to unprecedented progress in several areas of artificial intelligence. On one hand, the intense focus on these techniques has led to an intimate understanding of hardware requirements and code optimizations needed to execute these routines on large datasets in a scalable manner. Today, myriad off-the-shelf and highly optimized packages exist that can churn reasonably large datasets on GPU architectures with relatively mild human involvement and little bootstrap effort. -

Q-Learning in Continuous State and Action Spaces
-Learning in Continuous Q State and Action Spaces Chris Gaskett, David Wettergreen, and Alexander Zelinsky Robotic Systems Laboratory Department of Systems Engineering Research School of Information Sciences and Engineering The Australian National University Canberra, ACT 0200 Australia [cg dsw alex]@syseng.anu.edu.au j j Abstract. -learning can be used to learn a control policy that max- imises a scalarQ reward through interaction with the environment. - learning is commonly applied to problems with discrete states and ac-Q tions. We describe a method suitable for control tasks which require con- tinuous actions, in response to continuous states. The system consists of a neural network coupled with a novel interpolator. Simulation results are presented for a non-holonomic control task. Advantage Learning, a variation of -learning, is shown enhance learning speed and reliability for this task.Q 1 Introduction Reinforcement learning systems learn by trial-and-error which actions are most valuable in which situations (states) [1]. Feedback is provided in the form of a scalar reward signal which may be delayed. The reward signal is defined in relation to the task to be achieved; reward is given when the system is successfully achieving the task. The value is updated incrementally with experience and is defined as a discounted sum of expected future reward. The learning systems choice of actions in response to states is called its policy. Reinforcement learning lies between the extremes of supervised learning, where the policy is taught by an expert, and unsupervised learning, where no feedback is given and the task is to find structure in data. -

Measuring Overfitting and Mispecification in Nonlinear Models
WP 11/25 Measuring overfitting and mispecification in nonlinear models Marcel Bilger Willard G. Manning August 2011 york.ac.uk/res/herc/hedgwp Measuring overfitting and mispecification in nonlinear models Marcel Bilger, Willard G. Manning The Harris School of Public Policy Studies, University of Chicago, USA Abstract We start by proposing a new measure of overfitting expressed on the untransformed scale of the dependent variable, which is generally the scale of interest to the analyst. We then show that with nonlinear models shrinkage due to overfitting gets confounded by shrinkage—or expansion— arising from model misspecification. Out-of-sample predictive calibration can in fact be expressed as in-sample calibration times 1 minus this new measure of overfitting. We finally argue that re-calibration should be performed on the scale of interest and provide both a simulation study and a real-data illustration based on health care expenditure data. JEL classification: C21, C52, C53, I11 Keywords: overfitting, shrinkage, misspecification, forecasting, health care expenditure 1. Introduction When fitting a model, it is well-known that we pick up part of the idiosyncratic char- acteristics of the data as well as the systematic relationship between a dependent and explanatory variables. This phenomenon is known as overfitting and generally occurs when a model is excessively complex relative to the amount of data available. Overfit- ting is a major threat to regression analysis in terms of both inference and prediction. When models greatly over-explain the data at hand they can even show relations which reflect chance only. Consequently, overfitting casts doubt on the true statistical signif- icance of the effects found by the analyst as well as the magnitude of the response. -

Over-Fitting in Model Selection with Gaussian Process Regression
Over-Fitting in Model Selection with Gaussian Process Regression Rekar O. Mohammed and Gavin C. Cawley University of East Anglia, Norwich, UK [email protected], [email protected] http://theoval.cmp.uea.ac.uk/ Abstract. Model selection in Gaussian Process Regression (GPR) seeks to determine the optimal values of the hyper-parameters governing the covariance function, which allows flexible customization of the GP to the problem at hand. An oft-overlooked issue that is often encountered in the model process is over-fitting the model selection criterion, typi- cally the marginal likelihood. The over-fitting in machine learning refers to the fitting of random noise present in the model selection criterion in addition to features improving the generalisation performance of the statistical model. In this paper, we construct several Gaussian process regression models for a range of high-dimensional datasets from the UCI machine learning repository. Afterwards, we compare both MSE on the test dataset and the negative log marginal likelihood (nlZ), used as the model selection criteria, to find whether the problem of overfitting in model selection also affects GPR. We found that the squared exponential covariance function with Automatic Relevance Determination (SEard) is better than other kernels including squared exponential covariance func- tion with isotropic distance measure (SEiso) according to the nLZ, but it is clearly not the best according to MSE on the test data, and this is an indication of over-fitting problem in model selection. Keywords: Gaussian process · Regression · Covariance function · Model selection · Over-fitting 1 Introduction Supervised learning tasks can be divided into two main types, namely classifi- cation and regression problems. -

On Overfitting and Asymptotic Bias in Batch Reinforcement Learning With
Journal of Artificial Intelligence Research 65 (2019) 1-30 Submitted 06/2018; published 05/2019 On Overfitting and Asymptotic Bias in Batch Reinforcement Learning with Partial Observability Vincent François-Lavet [email protected] Guillaume Rabusseau [email protected] Joelle Pineau [email protected] School of Computer Science, McGill University University Street 3480, Montreal, QC, H3A 2A7, Canada Damien Ernst [email protected] Raphael Fonteneau [email protected] Montefiore Institute, University of Liege Allée de la découverte 10, 4000 Liège, Belgium Abstract This paper provides an analysis of the tradeoff between asymptotic bias (suboptimality with unlimited data) and overfitting (additional suboptimality due to limited data) in the context of reinforcement learning with partial observability. Our theoretical analysis formally characterizes that while potentially increasing the asymptotic bias, a smaller state representation decreases the risk of overfitting. This analysis relies on expressing the quality of a state representation by bounding L1 error terms of the associated belief states. Theoretical results are empirically illustrated when the state representation is a truncated history of observations, both on synthetic POMDPs and on a large-scale POMDP in the context of smartgrids, with real-world data. Finally, similarly to known results in the fully observable setting, we also briefly discuss and empirically illustrate how using function approximators and adapting the discount factor may enhance the tradeoff between asymptotic bias and overfitting in the partially observable context. 1. Introduction This paper studies sequential decision-making problems that may be modeled as Markov Decision Processes (MDP) but for which the state is partially observable. -

Overfitting Princeton University COS 495 Instructor: Yingyu Liang Review: Machine Learning Basics Math Formulation
Machine Learning Basics Lecture 6: Overfitting Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation • Given training data 푥푖, 푦푖 : 1 ≤ 푖 ≤ 푛 i.i.d. from distribution 퐷 1 • Find 푦 = 푓(푥) ∈ 퓗 that minimizes 퐿 푓 = σ푛 푙(푓, 푥 , 푦 ) 푛 푖=1 푖 푖 • s.t. the expected loss is small 퐿 푓 = 피 푥,푦 ~퐷[푙(푓, 푥, 푦)] Machine learning 1-2-3 • Collect data and extract features • Build model: choose hypothesis class 퓗 and loss function 푙 • Optimization: minimize the empirical loss Machine learning 1-2-3 Feature mapping Maximum Likelihood • Collect data and extract features • Build model: choose hypothesis class 퓗 and loss function 푙 • Optimization: minimize the empirical loss Occam’s razor Gradient descent; convex optimization Overfitting Linear vs nonlinear models 2 푥1 2 푥2 푥1 2푥1푥2 푦 = sign(푤푇휙(푥) + 푏) 2푐푥1 푥2 2푐푥2 푐 Polynomial kernel Linear vs nonlinear models • Linear model: 푓 푥 = 푎0 + 푎1푥 2 3 푀 • Nonlinear model: 푓 푥 = 푎0 + 푎1푥 + 푎2푥 + 푎3푥 + … + 푎푀 푥 • Linear model ⊆ Nonlinear model (since can always set 푎푖 = 0 (푖 > 1)) • Looks like nonlinear model can always achieve same/smaller error • Why one use Occam’s razor (choose a smaller hypothesis class)? Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Figure from Machine Learning and Pattern Recognition, Bishop Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Regression using polynomial of degree M Figure from Machine Learning and Pattern Recognition, Bishop Example: regression using polynomial curve 푡 = sin 2휋푥 + 휖 Figure from Machine Learning -

Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting
water Article Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting Halit Apaydin 1 , Hajar Feizi 2 , Mohammad Taghi Sattari 1,2,* , Muslume Sevba Colak 1 , Shahaboddin Shamshirband 3,4,* and Kwok-Wing Chau 5 1 Department of Agricultural Engineering, Faculty of Agriculture, Ankara University, Ankara 06110, Turkey; [email protected] (H.A.); [email protected] (M.S.C.) 2 Department of Water Engineering, Agriculture Faculty, University of Tabriz, Tabriz 51666, Iran; [email protected] 3 Department for Management of Science and Technology Development, Ton Duc Thang University, Ho Chi Minh City, Vietnam 4 Faculty of Information Technology, Ton Duc Thang University, Ho Chi Minh City, Vietnam 5 Department of Civil and Environmental Engineering, Hong Kong Polytechnic University, Hong Kong, China; [email protected] * Correspondence: [email protected] or [email protected] (M.T.S.); [email protected] (S.S.) Received: 1 April 2020; Accepted: 21 May 2020; Published: 24 May 2020 Abstract: Due to the stochastic nature and complexity of flow, as well as the existence of hydrological uncertainties, predicting streamflow in dam reservoirs, especially in semi-arid and arid areas, is essential for the optimal and timely use of surface water resources. In this research, daily streamflow to the Ermenek hydroelectric dam reservoir located in Turkey is simulated using deep recurrent neural network (RNN) architectures, including bidirectional long short-term memory (Bi-LSTM), gated recurrent unit (GRU), long short-term memory (LSTM), and simple recurrent neural networks (simple RNN). For this purpose, daily observational flow data are used during the period 2012–2018, and all models are coded in Python software programming language. -

Training Deep Networks Without Learning Rates Through Coin Betting
Training Deep Networks without Learning Rates Through Coin Betting Francesco Orabona∗ Tatiana Tommasi∗ Department of Computer Science Department of Computer, Control, and Stony Brook University Management Engineering Stony Brook, NY Sapienza, Rome University, Italy [email protected] [email protected] Abstract Deep learning methods achieve state-of-the-art performance in many application scenarios. Yet, these methods require a significant amount of hyperparameters tuning in order to achieve the best results. In particular, tuning the learning rates in the stochastic optimization process is still one of the main bottlenecks. In this paper, we propose a new stochastic gradient descent procedure for deep networks that does not require any learning rate setting. Contrary to previous methods, we do not adapt the learning rates nor we make use of the assumed curvature of the objective function. Instead, we reduce the optimization process to a game of betting on a coin and propose a learning-rate-free optimal algorithm for this scenario. Theoretical convergence is proven for convex and quasi-convex functions and empirical evidence shows the advantage of our algorithm over popular stochastic gradient algorithms. 1 Introduction In the last years deep learning has demonstrated a great success in a large number of fields and has attracted the attention of various research communities with the consequent development of multiple coding frameworks (e.g., Caffe [Jia et al., 2014], TensorFlow [Abadi et al., 2015]), the diffusion of blogs, online tutorials, books, and dedicated courses. Besides reaching out scientists with different backgrounds, the need of all these supportive tools originates also from the nature of deep learning: it is a methodology that involves many structural details as well as several hyperparameters whose importance has been growing with the recent trend of designing deeper and multi-branches networks. -

The Perceptron
The Perceptron Volker Tresp Summer 2019 1 Elements in Learning Tasks • Collection, cleaning and preprocessing of training data • Definition of a class of learning models. Often defined by the free model parameters in a learning model with a fixed structure (e.g., a Perceptron) (model structure learning: search about model structure) • Selection of a cost function which is a function of the data and the free parameters (e.g., a score related to the number of misclassifications in the training data as a function of the model parameters); a good model has a low cost • Optimizing the cost function via a learning rule to find the best model in the class of learning models under consideration. Typically this means the learning of the optimal parameters in a model with a fixed structure 2 Prototypical Learning Task • Classification of printed or handwritten digits • Application: automatic reading of postal codes • More general: OCR (optical character recognition) 3 Transformation of the Raw Data (2-D) into Pattern Vectors (1-D), which are then the Rows in a Learning Matrix 4 Binary Classification for Digit \5" 5 Data Matrix for Supervised Learning 6 M number of inputs (input attributes) Mp number of free parameters N number of training patterns T xi = (xi;0; : : : ; xi;M ) input vector for the i-th pattern xi;j j-th component of xi T X = (x1;:::; xN ) (design matrix) yi target for the i-th pattern T y = (y1; : : : ; yN ) vector of targets y^i model prediction for xi T di = (xi;0; : : : ; xi;M ; yi) i-th pattern D = fd1;:::; dN g (training data) T x = (x0; x1; : : : ; xM ) , generic (test) input y target for x y^ model estimate fw(x) a model function with parameters w f(x) the\true"but unknown function that generated the data Fine Details on the Notation • x is a generic input and xj is its j-th component. -
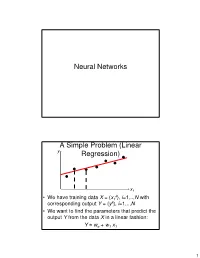
Neural Networks a Simple Problem (Linear Regression)
Neural Networks A Simple Problem (Linear y Regression) x1 k • We have training data X = { x1 }, i=1,.., N with corresponding output Y = { yk}, i=1,.., N • We want to find the parameters that predict the output Y from the data X in a linear fashion: Y ≈ wo + w1 x1 1 A Simple Problem (Linear y Notations:Regression) Superscript: Index of the data point in the training data set; k = kth training data point Subscript: Coordinate of the data point; k x1 = coordinate 1 of data point k. x1 k • We have training data X = { x1 }, k=1,.., N with corresponding output Y = { yk}, k=1,.., N • We want to find the parameters that predict the output Y from the data X in a linear fashion: k k y ≈ wo + w1 x1 A Simple Problem (Linear y Regression) x1 • It is convenient to define an additional “fake” attribute for the input data: xo = 1 • We want to find the parameters that predict the output Y from the data X in a linear fashion: k k k y ≈ woxo + w1 x1 2 More convenient notations y x • Vector of attributes for each training data point:1 k k k x = [ xo ,.., xM ] • We seek a vector of parameters: w = [ wo,.., wM] • Such that we have a linear relation between prediction Y and attributes X: M k k k k k k y ≈ wo xo + w1x1 +L+ wM xM = ∑wi xi = w ⋅ x i =0 More convenient notations y By definition: The dot product between vectors w and xk is: M k k w ⋅ x = ∑wi xi i =0 x • Vector of attributes for each training data point:1 i i i x = [ xo ,.., xM ] • We seek a vector of parameters: w = [ wo,.., wM] • Such that we have a linear relation between prediction Y and attributes X: M k k k k k k y ≈ wo xo + w1x1 +L+ wM xM = ∑wi xi = w ⋅ x i =0 3 Neural Network: Linear Perceptron xo w o Output prediction M wi w x = w ⋅ x x ∑ i i i i =0 w M Input attribute values xM Neural Network: Linear Perceptron Note: This input unit corresponds to the “fake” attribute xo = 1.