Design and Implementation of the Sweble Wikitext Parser: Unlocking the Structured Data of Wikipedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Approved DITA 2.0 Proposals
DITA Technical Committee DITA 2.0 proposals DITA TC work product Page 1 of 189 Table of contents 1 Overview....................................................................................................................................................3 2 DITA 2.0: Stage two proposals.................................................................................................................. 3 2.1 Stage two: #08 <include> element.................................................................................................... 3 2.2 Stage two: #15 Relax specialization rules......................................................................................... 7 2.3 Stage two: #17 Make @outputclass universal...................................................................................9 2.4 Stage two: #18 Make audience, platform, product, otherprops into specializations........................12 2.5 Stage two: #27 Multimedia domain..................................................................................................16 2.6 Stage two: #29 Update bookmap.................................................................................................... 20 2.7 Stage two: #36 Remove deprecated elements and attributes.........................................................23 2.8 Stage two: #46: Remove @xtrf and @xtrc...................................................................................... 31 2.9 Stage 2: #73 Remove delayed conref domain.................................................................................36 -

Position Description Addenda
POSITION DESCRIPTION January 2014 Wikimedia Foundation Executive Director - Addenda The Wikimedia Foundation is a radically transparent organization, and much information can be found at www.wikimediafoundation.org . That said, certain information might be particularly useful to nominators and prospective candidates, including: Announcements pertaining to the Wikimedia Foundation Executive Director Search Kicking off the search for our next Executive Director by Former Wikimedia Foundation Board Chair Kat Walsh An announcement from Wikimedia Foundation ED Sue Gardner by Wikimedia Executive Director Sue Gardner Video Interviews on the Wikimedia Community and Foundation and Its History Some of the values and experiences of the Wikimedia Community are best described directly by those who have been intimately involved in the organization’s dramatic expansion. The following interviews are available for viewing though mOppenheim.TV . • 2013 Interview with Former Wikimedia Board Chair Kat Walsh • 2013 Interview with Wikimedia Executive Director Sue Gardner • 2009 Interview with Wikimedia Executive Director Sue Gardner Guiding Principles of the Wikimedia Foundation and the Wikimedia Community The following article by Sue Gardner, the current Executive Director of the Wikimedia Foundation, has received broad distribution and summarizes some of the core cultural values shared by Wikimedia’s staff, board and community. Topics covered include: • Freedom and open source • Serving every human being • Transparency • Accountability • Stewardship • Shared power • Internationalism • Free speech • Independence More information can be found at: https://meta.wikimedia.org/wiki/User:Sue_Gardner/Wikimedia_Foundation_Guiding_Principles Wikimedia Policies The Wikimedia Foundation has an extensive list of policies and procedures available online at: http://wikimediafoundation.org/wiki/Policies Wikimedia Projects All major projects of the Wikimedia Foundation are collaboratively developed by users around the world using the MediaWiki software. -

XRI 2.0 FAQ 1 December 2005
XRI 2.0 FAQ 1 December 2005 This document is a comprehensive FAQ on the XRI 2.0 suite of specifications, with a particular emphasis on the XRI Syntax 2.0 Committee Specification which was submitted for consideration as an OASIS Standard on November 14, 2005. 1 General..................................................................................... 3 1.1 What does the acronym XRI stand for? ................................................................3 1.2 What is the relationship of XRI to URI and IRI? ....................................................3 1.3 Why was XRI needed?..........................................................................................3 1.4 Who is involved in the XRI specification effort? ....................................................4 1.5 What is the XRI 2.0 specification suite? ................................................................4 1.6 Are there any intellectual property restrictions on XRI? ........................................4 2 Uses of XRI .............................................................................. 5 2.1 What things do XRIs identify? ...............................................................................5 2.2 What are some example uses of XRI?..................................................................5 2.3 What are some applications that use XRI? ...........................................................5 3 Features of XRI Syntax ........................................................... 6 3.1 What were some of the design requirements -

Wikibase Knowledge Graphs for Data Management & Data Science
Business and Economics Research Data Center https://www.berd-bw.de Baden-Württemberg Wikibase knowledge graphs for data management & data science Dr. Renat Shigapov 23.06.2021 @shigapov @_shigapov DATA Motivation MANAGEMENT 1. people DATA SCIENCE knowledg! 2. processes information linking 3. technology data things KNOWLEDGE GRAPHS 2 DATA Flow MANAGEMENT Definitions DATA Wikidata & Tools SCIENCE Local Wikibase Wikibase Ecosystem Summary KNOWLEDGE GRAPHS 29.10.2012 2030 2021 3 DATA Example: Named Entity Linking SCIENCE https://commons.wikimedia.org/wiki/File:Entity_Linking_-_Short_Example.png Rule#$as!d problems Machine Learning De!' Learning Learn data science at https://www.kaggle.com 4 https://commons.wikimedia.org/wiki/File:Data_visualization_process_v1.png DATA Example: general MANAGEMENT research data silos data fabric data mesh data space data marketplace data lake data swamp Research data lifecycle https://www.reading.ac.uk/research-services/research-data-management/ 5 https://www.dama.org/cpages/body-of-knowledge about-research-data-management/the-research-data-lifecycle KNOWLEDGE ONTOLOG( + GRAPH = + THINGS https://www.mediawiki.org https://www.wikiba.se ✔ “Things, not strings” by Google, 2012 + ✔ A knowledge graph links things in different datasets https://mariadb.org https://blazegraph.com ✔ A knowledge graph can link people & relational database graph database processes and enhance technologies The main example: “THE KNOWLEDGE GRAPH COOKBOOK RECIPES THAT WORK” by ANDREAS BLUMAUER & HELMUT NAGY, 2020. https://www.wikidata.org -

Wiki-Reliability: a Large Scale Dataset for Content Reliability on Wikipedia
Wiki-Reliability: A Large Scale Dataset for Content Reliability on Wikipedia KayYen Wong∗ Miriam Redi Diego Saez-Trumper Outreachy Wikimedia Foundation Wikimedia Foundation Kuala Lumpur, Malaysia London, United Kingdom Barcelona, Spain [email protected] [email protected] [email protected] ABSTRACT Wikipedia is the largest online encyclopedia, used by algorithms and web users as a central hub of reliable information on the web. The quality and reliability of Wikipedia content is maintained by a community of volunteer editors. Machine learning and information retrieval algorithms could help scale up editors’ manual efforts around Wikipedia content reliability. However, there is a lack of large-scale data to support the development of such research. To fill this gap, in this paper, we propose Wiki-Reliability, the first dataset of English Wikipedia articles annotated with a wide set of content reliability issues. To build this dataset, we rely on Wikipedia “templates”. Tem- plates are tags used by expert Wikipedia editors to indicate con- Figure 1: Example of an English Wikipedia page with several tent issues, such as the presence of “non-neutral point of view” template messages describing reliability issues. or “contradictory articles”, and serve as a strong signal for detect- ing reliability issues in a revision. We select the 10 most popular 1 INTRODUCTION reliability-related templates on Wikipedia, and propose an effective method to label almost 1M samples of Wikipedia article revisions Wikipedia is one the largest and most widely used knowledge as positive or negative with respect to each template. Each posi- repositories in the world. People use Wikipedia for studying, fact tive/negative example in the dataset comes with the full article checking and a wide set of different information needs [11]. -
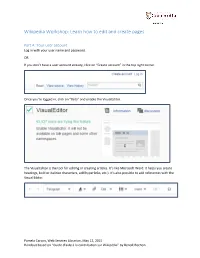
Wikipedia Workshop: Learn How to Edit and Create Pages
Wikipedia Workshop: Learn how to edit and create pages Part A: Your user account Log in with your user name and password. OR If you don’t have a user account already, click on “Create account” in the top right corner. Once you’re logged in, click on “Beta” and enable the VisualEditor. The VisualEditor is the tool for editing or creating articles. It’s like Microsoft Word: it helps you create headings, bold or italicize characters, add hyperlinks, etc.). It’s also possible to add references with the Visual Editor. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part B: Write a sentence or two about yourself Click on your username. This will lead you to your user page. The URL will be: https://en.wikipedia.org/wiki/User:[your user name] Exercise: Click on “Edit source” and write about yourself, then enter a description of your change in the “Edit summary” box and click “Save page”. Pamela Carson, Web Services Librarian, May 12, 2015 Handout based on “Guide d’aide à la contribution sur Wikipédia” by Benoît Rochon. Part C: Edit an existing article To edit a Wikipedia article, click on the tab “Edit” or “Edit source” (for more advanced users) available at the top of any page. These tabs are also available beside any section title within an article. Editing an entire page Editing just a section Need help? https://en.wikipedia.org/wiki/Wikipedia:Tutorial/Editing Exercise: Go to http://www.statcan.gc.ca/ and find a statistic that interests you. -

List of Different Digital Practices 3
Categories of Digital Poetics Practices (from the Electronic Literature Collection) http://collection.eliterature.org/1/ (Electronic Literature Collection, Vol 1) http://collection.eliterature.org/2/ (Electronic Literature Collection, Vol 2) Ambient: Work that plays by itself, meant to evoke or engage intermittent attention, as a painting or scrolling feed would; in John Cayley’s words, “a dynamic linguistic wall- hanging.” Such work does not require or particularly invite a focused reading session. Kinetic (Animated): Kinetic work is composed with moving images and/or text but is rarely an actual animated cartoon. Transclusion, Mash-Up, or Appropriation: When the supply text for a piece is not composed by the authors, but rather collected or mined from online or print sources, it is appropriated. The result of appropriation may be a “mashup,” a website or other piece of digital media that uses content from more than one source in a new configuration. Audio: Any work with an audio component, including speech, music, or sound effects. CAVE: An immersive, shared virtual reality environment created using goggles and several pairs of projectors, each pair pointing to the wall of a small room. Chatterbot/Conversational Character: A chatterbot is a computer program designed to simulate a conversation with one or more human users, usually in text. Chatterbots sometimes seem to offer intelligent responses by matching keywords in input, using statistical methods, or building models of conversation topic and emotional state. Early systems such as Eliza and Parry demonstrated that simple programs could be effective in many ways. Chatterbots may also be referred to as talk bots, chat bots, simply “bots,” or chatterboxes. -
Building a Visual Editor for Wikipedia
Building a Visual Editor for Wikipedia Trevor Parscal and Roan Kattouw Wikimania D.C. 2012 (Introduce yourself) (Introduce yourself) We’d like to talk to you about how we’ve been building a visual editor for Wikipedia Trevor Parscal Roan Kattouw Rob Moen Lead Designer and Engineer Data Model Engineer User Interface Engineer Wikimedia Wikimedia Wikimedia Inez Korczynski Christian Williams James Forrester Edit Surface Engineer Edit Surface Engineer Product Analyst Wikia Wikia Wikimedia The People Wikimania D.C. 2012 We are only 2/6ths of the VisualEditor team Our team includes 2 engineers from Wikia - they also use MediaWiki They also fight crime in their of time Parsoid Team Gabriel Wicke Subbu Sastry Lead Parser Engineer Parser Engineer Wikimedia Wikimedia The People Wikimania D.C. 2012 There’s also two remote people working on a new parser This parser makes what we are doing with the VisualEditor possible The Project Wikimania D.C. 2012 You might recognize this, it’s a Wikipedia article You should edit it! Seems simple enough, just hit the edit button and be on your way... The Complexity Problem Wikimania D.C. 2012 Or not... What is all this nonsense you may ask? Well, it’s called Wikitext! Even really smart people who have a lot to contribute to Wikipedia find it confusing The truth is, Wikitext is a lousy IQ test, and it’s holding Wikipedia back, severely Active Editors 20k 0 2001 2007 Today Growth Stagnation The Complexity Problem Wikimania D.C. 2012 The internet has normal people on it now, not just geeks and weirdoes Normal people like simple things, and simple things are growing fast We must make editing Wikipedia easier to use, not just to grow, but even just to stay alive The Complexity Problem Wikimania D.C. -

Web Boot Camp Week 1 (Custom for Liberty)
"Charting the Course ... ... to Your Success!" Web Boot Camp Week 1 (Custom for Liberty) Course Summary Description This class is designed for students that have experience with HTML5 and CSS3 and wish to learn about, JavaScript and jQuery and AngularJS. Topics Introduction to the Course Designing Responsive Web Applications Introduction to JavaScript Data Types and Assignment Operators Flow Control JavaScript Events JavaScript Objects JavaScript Arrays JavaScript Functions The JavaScript Window and Document Objects JavaScript and CSS Introduction to jQuery Introduction to jQuery UI jQuery and Ajax Introduction to AngularJS Additional AngularJS Topics The Angular $http Service AngularJS Filters AngularJS Directives AngularJS Forms Testing JavaScript Introduction to AngularJS 2 Prerequisites Prior knowledge of HTML5 and CSS3 is required. Duration Five days Due to the nature of this material, this document refers to numerous hardware and software products by their trade names. References to other companies and their products are for informational purposes only, and all trademarks are the properties of their respective companies. It is not the intent of ProTech Professional Technical Services, Inc. to use any of these names generically "Charting the Course ... ... to Your Success!" TDP Web Week 1: HTML5/CSS3/JavaScript Programming Course Outline I. Introduction to the Course O. Client-Side JavaScript Objects A. TDP Web Bootcamp Week 1, 2016 P. Embedding JavaScript in HTML B. Legal Information Q. Using the script Tag C. TDP Web Bootcamp Week 1, 2016 R. Using an External File D. Introductions S. Defining Functions E. Course Description T. Modifying Page Elements F. Course Objectives U. The Form Submission Event G. Course Logistics V. -

Autonomous Agents on the Web
Report from Dagstuhl Seminar 21072 Autonomous Agents on the Web Edited by Olivier Boissier1, Andrei Ciortea2, Andreas Harth3, and Alessandro Ricci4 1 Ecole des Mines – St. Etienne, FR, [email protected] 2 Universität St. Gallen, CH, [email protected] 3 Fraunhofer IIS – Nürnberg, DE, [email protected] 4 Università di Bologna, IT, [email protected] Abstract The World Wide Web has emerged as the middleware of choice for most distributed systems. Recent standardization efforts for the Web of Things and Linked Data are now turning hypermedia into a homogeneous information fabric that interconnects everything – devices, information resources, abstract concepts, etc. The latest standards allow clients not only to browse and query, but also to observe and act on this hypermedia fabric. Researchers and practitioners are already looking for means to build more sophisticated clients able to meet their design objectives through flexible autonomous use of this hypermedia fabric. Such autonomous agents have been studied to large extent in research on distributed artificial intelligence and, in particular, multi-agent systems. These recent developments thus motivate the need for a broader perspective that can only be achieved through a concerted effort of the research communities on the Web Architecture and the Web of Things, Semantic Web and Linked Data, and Autonomous Agents and Multi-Agent Systems. The Dagstuhl Seminar 21072 on “Autonomous Agents on the Web” brought together leading scholars and practitioners across these research areas in order to support the transfer of knowledge and results – and to discuss new opportunities for research on Web-based autonomous systems. This report documents the seminar’s program and outcomes. -

Freenet-Like Guids for Implementing Xanalogical Hypertext
Freenet-like GUIDs for Implementing Xanalogical Hypertext Tuomas J. Lukka Benja Fallenstein Hyperstructure Group Oberstufen-Kolleg Dept. of Mathematical Information Technology University of Bielefeld, PO. Box 100131 University of Jyvaskyl¨ a,¨ PO. Box 35 D-33501 Bielefeld FIN-40351 Jyvaskyl¨ a¨ Germany Finland [email protected] lukka@iki.fi ABSTRACT For example, an email quoting another email would be automati- We discuss the use of Freenet-like content hash GUIDs as a prim- cally and implicitly connected to the original via the transclusion. itive for implementing the Xanadu model in a peer-to-peer frame- Bidirectional, non-breaking external links (content linking) can be work. Our current prototype is able to display the implicit con- resolved through the same mechanism. Nelson[9] argues that con- nection (transclusion) between two different references to the same ventional software, unable to reflect such interconnectivity of doc- permanent ID. We discuss the next layers required in the implemen- uments, is unsuited to most human thinking and creative work. tation of the Xanadu model on a world-wide peer-to-peer network. In order to implement the Xanadu model, it must be possible to efficiently search for references to permanent IDs on a large scale. The original Xanadu design organized content IDs in a DNS-like Categories and Subject Descriptors hierarchical structure (tumblers), making content references arbi- H.5.4 [Information Interfaces and Presentation]: Hypertext/Hy- trary intervals (spans) in the hierarchy. Advanced tree-like data permedia—architectures; H.3.4 [Information Storage and Retrie- structures[6] were used to retrieve the content efficiently. -

Angularjs Workbook
AngularJS Workbook Exercises take you to mastery By Nicholas Johnson version 0.1.0 - beta Image credit: San Diego Air and Space Museum Archives Welcome to the Angular Workbook This little book accompanies the Angular course taught over 3 days. Each exercise builds on the last, so it's best to work through these exercises in order. We start out from the front end with templates, moving back to controllers. We'll tick off AJAX, and then get into building custom components, filters, services and directives. After covering directives in some depth we'll build a real app backed by an open API. By the end you should have a pretty decent idea of what is what and what goes where. Template Exercises The goal of this exercise is just to get some Angular running in a browser. Getting Angular We download Angular from angularjs.org Alternately we can use a CDN such as the Google Angular CDN. Activating the compiler Angular is driven by the template. This is different from other MVC frameworks where the template is driven by the app. In Angular we modify our app by modifying our template. The JavaScript we write simply supports this process. We use the ng-app attribute (directive) to tell Angular to begin compiling our DOM. We can attach this attribute to any DOM node, typically the html or body tags: 1 <body ng-app> 2 Hello! 3 </body> All the HTML5 within this directive is an Angular template and will be compiled as such. Linking from a CDN Delivering common libraries from a shared CDN can be a good idea.