Deep Learning for Astronomical Object Classification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 3: Familiarizing Yourself with the Night Sky
Chapter 3: Familiarizing Yourself With the Night Sky Introduction People of ancient cultures viewed the sky as the inaccessible home of the gods. They observed the daily motion of the stars, and grouped them into patterns and images. They assigned stories to the stars, relating to themselves and their gods. They believed that human events and cycles were part of larger cosmic events and cycles. The night sky was part of the cycle. The steady progression of star patterns across the sky was related to the ebb and flow of the seasons, the cyclical migration of herds and hibernation of bears, the correct times to plant or harvest crops. Everywhere on Earth people watched and recorded this orderly and majestic celestial procession with writings and paintings, rock art, and rock and stone monuments or alignments. When the Great Pyramid in Egypt was constructed around 2650 BC, two shafts were built into it at an angle, running from the outside into the interior of the pyramid. The shafts coincide with the North-South passage of two stars important to the Egyptians: Thuban, the star closest to the North Pole at that time, and one of the stars of Orion’s belt. Orion was The Ishango Bone, thought to be a 20,000 year old associated with Osiris, one of the Egyptian gods of the lunar calendar underworld. The Bighorn Medicine Wheel in Wyoming, built by Plains Indians, consists of rocks in the shape of a large circle, with lines radiating from a central hub like the spokes of a bicycle wheel. -

Messier Objects
Messier Objects From the Stocker Astroscience Center at Florida International University Miami Florida The Messier Project Main contributors: • Daniel Puentes • Steven Revesz • Bobby Martinez Charles Messier • Gabriel Salazar • Riya Gandhi • Dr. James Webb – Director, Stocker Astroscience center • All images reduced and combined using MIRA image processing software. (Mirametrics) What are Messier Objects? • Messier objects are a list of astronomical sources compiled by Charles Messier, an 18th and early 19th century astronomer. He created a list of distracting objects to avoid while comet hunting. This list now contains over 110 objects, many of which are the most famous astronomical bodies known. The list contains planetary nebula, star clusters, and other galaxies. - Bobby Martinez The Telescope The telescope used to take these images is an Astronomical Consultants and Equipment (ACE) 24- inch (0.61-meter) Ritchey-Chretien reflecting telescope. It has a focal ratio of F6.2 and is supported on a structure independent of the building that houses it. It is equipped with a Finger Lakes 1kx1k CCD camera cooled to -30o C at the Cassegrain focus. It is equipped with dual filter wheels, the first containing UBVRI scientific filters and the second RGBL color filters. Messier 1 Found 6,500 light years away in the constellation of Taurus, the Crab Nebula (known as M1) is a supernova remnant. The original supernova that formed the crab nebula was observed by Chinese, Japanese and Arab astronomers in 1054 AD as an incredibly bright “Guest star” which was visible for over twenty-two months. The supernova that produced the Crab Nebula is thought to have been an evolved star roughly ten times more massive than the Sun. -

A Bibliometric Perspective Survey of Astronomical Object Tracking System
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Library Philosophy and Practice (e-journal) Libraries at University of Nebraska-Lincoln 2-15-2021 A Bibliometric Perspective Survey of Astronomical Object Tracking System Mariyam Ashai Symbiosis Institute of Technology (SIT), Symbiosis International (Deemed University), Pune, India, [email protected] Rhea Gautam Mukherjee Symbiosis Institute of Technology (SIT), Symbiosis International (Deemed University), Pune, India, [email protected] Sanjana Mundharikar Symbiosis Institute of Technology (SIT), Symbiosis International (Deemed University), Pune, India, [email protected] Vinayak Dev Kuanr Symbiosis Institute of Technology (SIT), Symbiosis International (Deemed University), Pune, India, [email protected] Shivali Amit Wagle Symbiosis Institute of Technology (SIT), Symbiosis International (Deemed University), Pune, India, [email protected] See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/libphilprac Part of the Library and Information Science Commons, and the Other Aerospace Engineering Commons Ashai, Mariyam; Mukherjee, Rhea Gautam; Mundharikar, Sanjana; Kuanr, Vinayak Dev; Wagle, Shivali Amit; and R, Harikrishnan, "A Bibliometric Perspective Survey of Astronomical Object Tracking System" (2021). Library Philosophy and Practice (e-journal). 5151. https://digitalcommons.unl.edu/libphilprac/5151 Authors Mariyam Ashai, Rhea Gautam Mukherjee, Sanjana Mundharikar, -

Appendix: Spectroscopy of Variable Stars
Appendix: Spectroscopy of Variable Stars As amateur astronomers gain ever-increasing access to professional tools, the science of spectroscopy of variable stars is now within reach of the experienced variable star observer. In this section we shall examine the basic tools used to perform spectroscopy and how to use the data collected in ways that augment our understanding of variable stars. Naturally, this section cannot cover every aspect of this vast subject, and we will concentrate just on the basics of this field so that the observer can come to grips with it. It will be noticed by experienced observers that variable stars often alter their spectral characteristics as they vary in light output. Cepheid variable stars can change from G types to F types during their periods of oscillation, and young variables can change from A to B types or vice versa. Spec troscopy enables observers to monitor these changes if their instrumentation is sensitive enough. However, this is not an easy field of study. It requires patience and dedication and access to resources that most amateurs do not possess. Nevertheless, it is an emerging field, and should the reader wish to get involved with this type of observation know that there are some excellent guides to variable star spectroscopy via the BAA and the AAVSO. Some of the workshops run by Robin Leadbeater of the BAA Variable Star section and others such as Christian Buil are a very good introduction to the field. © Springer Nature Switzerland AG 2018 M. Griffiths, Observer’s Guide to Variable Stars, The Patrick Moore 291 Practical Astronomy Series, https://doi.org/10.1007/978-3-030-00904-5 292 Appendix: Spectroscopy of Variable Stars Spectra, Spectroscopes and Image Acquisition What are spectra, and how are they observed? The spectra we see from stars is the result of the complete output in visible light of the star (in simple terms). -

1 Overview of the Solar System 2 Astronomical Coordinate Systems
General Astronomy (29:61) Fall 2013 Lecture 1 Notes , August 26, 2013 1 Overview of the Solar System The scale of the Solar System The astronomical unit AU is the average distance between the Earth and the Sun, and is 1:496 × 1011 meters, = 1:496 × 108 kilometers. Instead of the term average distance between a planet and the Sun, we will use (an apparently hopelessly more complicated) term semimajor axis of the orbit of a planet. The reason for this choice will become clear later. The two concepts are equivalent. 2 Astronomical Coordinate Systems Astronomical coordinate systems allow us to express, in numbers, one of the most basic things about an astronomical object: where it is. We will start with two of the main coordinates systems. 1. the Horizon Coordinate System, fixed with respect to you. 2. the Equatorial Coordinate System, fixed with respect to the stars. Think of the sky as a big hemisphere over us at a given time. The full interior of this imaginary sphere is called the celestial sphere. 2.1 The Horizon Coordinate System We use two angles to specify the location of an astronomical object, the azimuth angle and the altitude angle. Look at Figure 1.3 for a definition of these angles. An important concept in the horizon coordinate system is the meridian . It is an imaginary line on the sky starting due north, going through the zenith, and ending up due south. The meridian divides the sky into two halves. An astronomical object transits when it moves through the meridian from east to west. -

Why Pluto Is Not a Planet Anymore Or How Astronomical Objects Get Named
3 Why Pluto Is Not a Planet Anymore or How Astronomical Objects Get Named Sethanne Howard USNO retired Abstract Everywhere I go people ask me why Pluto was kicked out of the Solar System. Poor Pluto, 76 years a planet and then summarily dismissed. The answer is not too complicated. It starts with the question how are astronomical objects named or classified; asks who is responsible for this; and ends with international treaties. Ultimately we learn that it makes sense to demote Pluto. Catalogs and Names WHO IS RESPONSIBLE for naming and classifying astronomical objects? The answer varies slightly with the object, and history plays an important part. Let us start with the stars. Most of the bright stars visible to the naked eye were named centuries ago. They generally have kept their old- fashioned names. Betelgeuse is just such an example. It is the eighth brightest star in the northern sky. The star’s name is thought to be derived ,”Yad al-Jauzā' meaning “the Hand of al-Jauzā يد الجوزاء from the Arabic i.e., Orion, with mistransliteration into Medieval Latin leading to the first character y being misread as a b. Betelgeuse is its historical name. The star is also known by its Bayer designation − ∝ Orionis. A Bayeri designation is a stellar designation in which a specific star is identified by a Greek letter followed by the genitive form of its parent constellation’s Latin name. The original list of Bayer designations contained 1,564 stars. The Bayer designation typically assigns the letter alpha to the brightest star in the constellation and moves through the Greek alphabet, with each letter representing the next fainter star. -

THE MAGELLANIC CLOUDS NEWSLETTER an Electronic Publication Dedicated to the Magellanic Clouds, and Astrophysical Phenomena Therein
THE MAGELLANIC CLOUDS NEWSLETTER An electronic publication dedicated to the Magellanic Clouds, and astrophysical phenomena therein No. 131 — 1 October 2014 http://www.astro.keele.ac.uk/MCnews Editor: Jacco van Loon Editorial Dear Colleagues, It is my pleasure to present you the 131st issue of the Magellanic Clouds Newsletter. Enjoy! Want your results on the front cover of the newsletter? Just send a picture (preferably postscript format) and brief description to [email protected]. The next issue is planned to be distributed on the 1st of December. Editorially Yours, Jacco van Loon 1 Refereed Journal Papers OGLE-LMC-ECL-11893: The discovery of a long-period eclipsing binary with a circumstellar disk Subo Dong1, Boaz Katz2,11, Jos´eL. Prieto3,12, Andrzej Udalski4,13, Szymon KozÃlowski4,13, R.A. Street5,14, D.M. Bramich6,14, Y. Tsapras5,7,14, M. Hundertmark8,14, C. Snodgrass9,14, K. Horne8,14, M. Dominik8,14,15 and R. Figuera Jaimes8,10,14 1Kavli Institute for Astronomy and Astrophysics, Peking University, China 2Institute for Advanced Study, USA 3Department of Astrophysical Sciences, Princeton University, USA 4Warsaw University Observatory, Poland 5Las Cumbres Observatory Global Telescope Network, USA 6Qatar Environment and Energy Research Institute, Qatar Foundation, Qatar 7School of Physics and Astronomy, Queen Mary University of London, UK 8SUPA, School of Physics and Astronomy, University of St. Andrews, UK 9Max Planck Institute for Solar System Research, Germany 10European Southern Observatory, Germany 11John N. Bahcall Fellow 12Carnegie–Princeton Fellow 13The OGLE Collaboration 14The RoboNet Collaboration 15Royal Society University Research Fellow We report the serendipitous discovery of a disk-eclipse system OGLE-LMC-ECL-11893. -
The Astronomical Zoo: Discovery and Classification
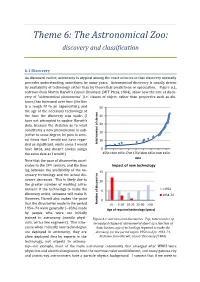
Theme 6: The Astronomical Zoo: discovery and classification 6.1 Discovery As discussed earlier, astronomy is atypical among the exact sciences in that discovery normally precedes understanding, sometimes by many years. Astronomical discovery is usually driven by availability of technology rather than by theoretical predictions or speculation. Figure 6.1, redrawn from Martin Harwit’s Cosmic Discovery (MIT Press, 1984), show how the rate of disco- very of “astronomical phenomena” (i.e. classes of object, rather than properties such as dis- tance) has increased over time (the line is a rough fit to an exponential), and 50 the age of the necessary technology at the time the discovery was made. (I 40 have not attempted to update Harwit’s data, because the decision as to what 30 constitutes a new phenomenon is sub- 20 jective to some degree; he puts in seve- ral items that I would not have regar- 10 ded as significant, omits some I would total numberof classes have listed, and doesn’t always assign 0 the same date as I would.) 1550 1600 1650 1700 1750 1800 1850 1900 1950 date Note that the pace of discoveries accel- erates in the 20th century, and the time Impact of new technology lag between the availability of the ne- 15 cessary technology and the actual dis- covery decreases. This is likely due to 10 the greater number of working astro- <1954 nomers: if the technology to make the 5 discovery exists, someone will make it. 1954-74 However, Harwit also makes the point 0 that the discoveries made in the period Numberof discoveries <5 5-10 10-25 25-50 >50 1954−74 were generally (~85%) made Age of required technology (years) by people who were not initially trained in astronomy (mostly physi- Figure 6.1: astronomical discoveries. -

Astronomy 113 Laboratory Manual
UNIVERSITY OF WISCONSIN - MADISON Department of Astronomy Astronomy 113 Laboratory Manual Fall 2011 Professor: Snezana Stanimirovic 4514 Sterling Hall [email protected] TA: Natalie Gosnell 6283B Chamberlin Hall [email protected] 1 2 Contents Introduction 1 Celestial Rhythms: An Introduction to the Sky 2 The Moons of Jupiter 3 Telescopes 4 The Distances to the Stars 5 The Sun 6 Spectral Classification 7 The Universe circa 1900 8 The Expansion of the Universe 3 ASTRONOMY 113 Laboratory Introduction Astronomy 113 is a hands-on tour of the visible universe through computer simulated and experimental exploration. During the 14 lab sessions, we will encounter objects located in our own solar system, stars filling the Milky Way, and objects located much further away in the far reaches of space. Astronomy is an observational science, as opposed to most of the rest of physics, which is experimental in nature. Astronomers cannot create a star in the lab and study it, walk around it, change it, or explode it. Astronomers can only observe the sky as it is, and from their observations deduce models of the universe and its contents. They cannot ever repeat the same experiment twice with exactly the same parameters and conditions. Remember this as the universe is laid out before you in Astronomy 113 – the story always begins with only points of light in the sky. From this perspective, our understanding of the universe is truly one of the greatest intellectual challenges and achievements of mankind. The exploration of the universe is also a lot of fun, an experience that is largely missed sitting in a lecture hall or doing homework. -

Activity Book Level 4
Space Place Education Team Activity booklet Level 4 This booklet contains: Teacher’s notes for Level 4 Level 4 assessment points Classroom activities Curriculum links Classroom Activities: Use these flexible activities to develop students awareness of abstract scientific concepts. Survival on the Moon Solar System Scale Model How Can We Navigate by the Sky? Seeing Clearly with Binoculars How to take Astronomical Measurements How do we Measure the Brightness of Stars and Planets? Curriculum Links: Use these ideas to link this science topic with Literacy, Mathematics and Craft sessions. Notes for Teachers Level 4 includes Exploring the Solar System, Telescopes and Hunting for Asteroids. These cover more about how seasons happen and if this could happen on other objects in space, features and affects of the Sun and builds on the knowledge of our galaxy and beyond as well as how to find asteroids. Our Solar System The Solar System is made up of the Sun and its planetary system of eight planets, their moons, and other non-stellar objects like comets and asteroids. It formed approximately 4.6 billion years ago from the gravitational collapse of a massive molecular cloud. Most of the System's mass is in the Sun, with the rest of the remaining mass mostly contained within Jupiter. The four smaller inner planets, Mercury, Venus, Earth and Mars, are also called terrestrial planets; are primarily made of metal and rock. The four outer planets, called the gas giants, are significantly more massive than the terrestrials. The two largest, Jupiter and Saturn, are made mainly of hydrogen and helium. -

19 6 9Apj. . .157.13950 the Astrophysical Journal, Vol. 157
The Astrophysical Journal, Vol. 157, September 1969 .157.13950 . (c) 1969 The University of Chicago All rights reserved Printed in U S A 9ApJ. 6 19 ON THE NATURE OF PULSARS. I. THEORY J. P. OSTRIKER AND J. E. GUNN Princeton University Observatory Received June 9, 1969 ABSTRACT We present in this paper the initial installment of a quantitative exploration of one particular pulsar model. We first make plausible and then assume that the seat of the pulsar phenomenon is a rotating neutron star having a dipolar magnetic field which is not parallel to the rotation axis. We then show that such stars may be expected to emit large amounts (1050-1052 ergs) of magnetic-dipole and gravitational- quadrupole radiation, that these energy losses are inevitably associated with losses of angular momentum and increases in the rotation periods, and that the emitted low-frequency magnetic-dipole radiation is extremely efficient at accelerating charged particles to relativistic energies. An explicit expression for the period as a function of time allows us to calculate the age of the Crab Nebula (with »20 percent accuracy) and to predict the so far unobserved second derivative of the period {d2P/dP). We also de- termine the luminosity of the nebula and the highest-energy electrons presently being injected into it— both numbers found to be in good agreement with independent observations. In extreme cases the ac- 2 2 l z 21 celeration mechanism can produce protons with energies up to mpc {e /Gm^) l or 10 eV, which is somewhat in excess of the most energetic cosmic rays yet observed. -

Astronomical Observations: a Guide for Allied Researchers
Astronomical observations: a guide for allied researchers P. Barmby Department of Physics & Astronomy University of Western Ontario London, Canada N6A 3K7 March 13, 2019 Abstract Observational astrophysics uses sophisticated technology to collect and measure electro- magnetic and other radiation from beyond the Earth. Modern observatories produce large, complex datasets and extracting the maximum possible information from them requires the expertise of specialists in many fields beyond physics and astronomy, from civil engineers to statisticians and software engineers. This article introduces the essentials of professional astronomical observations to colleagues in allied fields, to provide context and relevant back- ground for both facility construction and data analysis. It covers the path of electromagnetic radiation through telescopes, optics, detectors, and instruments, its transformation through processing into measurements and information, and the use of that information to improve our understanding of the physics of the cosmos and its history. 1 What do astronomers do? Everyone knows that astronomers study the sky. But what sorts of measurements do they make, and how do these translate into data that can be analyzed to understand the universe? This article introduces astronomical observations to colleagues in related fields (e.g., engineering, statistics, computer science) who are assumed to be familiar with quantitative measurements and computing but not necessarily with astronomy itself.1 Specialized terms which may be unfamiliar to the reader are italicized on first use. The references in this article include a mix of technical papers and less- technical descriptive works. Shorter introductions to astronomical observations, data and statistics are given by [29, 33]. Comprehensive technical introductions to astronomical observations are found in several recent textbooks [12, 45, 50].