Practice and Experience Volume 17, Number 4
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

What Are the Problems with Embedded Linux?
What Are the Problems with Embedded Linux? Every Operating System Has Benefits and Drawbacks Linux is ubiquitous. It runs most internet servers, is inside Android* smartphones, and is used on millions of embedded systems that, in the past, ran Real-Time Operating Systems (RTOSes). Linux can (and should) be used were possible for embedded projects, but while it gives you extreme choice, it also presents the risk of extreme complexity. What, then, are the trade-offs between embedded Linux and an RTOS? In this article, we cover some key considerations when evaluating Linux for a new development: ■ Design your system architecture first ■ What is Linux? ■ Linux vs. RTOSes ■ Free software is about liberty—not price ■ How much does Embedded Linux cost? ■ Why pay for Embedded Linux? ■ Should you buy Embedded Linux or roll-your-own (RYO)? ■ To fork or not to fork? ■ Software patching ■ Open source licensing ■ Making an informed decision The important thing is not whether Linux or an RTOS is “the best,” but whether either operating system—or both together—makes the most technical and financial sense for your project. We hope this article helps you make an informed decision. Design Your System Architecture First It is important to design your system architecture first—before choosing either Linux or an RTOS—because both choices can limit architectural freedom. You may discover that aspects of your design require neither Linux nor an RTOS, making your design a strong candidate for a heterogeneous approach that includes one or more bare-metal environments (with possibly a Linux and/or RTOS environment as well). -

C-Style Strings
Introduction to printf and scanf A conceptual model of a C-string String handling functions in the C standard library String parsing functions Stuff to learn on your own C-Style Strings Mike Closson Dept of Computing Science University of Alberta Small modifications: Michael Buro Feb.2006 22nd February 2006 Mike Closson C-Style Strings Introduction to printf and scanf A conceptual model of a C-string String handling functions in the C standard library String parsing functions Stuff to learn on your own Introduction to printf, fprintf. Printing Strings: /* Print to standard output */ printf( "Hello, World!\n" ); /* Print to file associated with filepointer fp */ fprintf( fp, "Hello, World!\n" ); Mike Closson C-Style Strings Introduction to printf and scanf A conceptual model of a C-string String handling functions in the C standard library String parsing functions Stuff to learn on your own Flushing an I/O stream with fflush. For performance reasons, data written with the stream functions (fwrite, printf, fprintf) may not always appear on the terminal or file after the printf function returns. To force the data to be written, use the fflush function. printf("Enter your password: "); fflush( stdout ); Usually, fflush is not needed. Mike Closson C-Style Strings Introduction to printf and scanf A conceptual model of a C-string String handling functions in the C standard library String parsing functions Stuff to learn on your own Reading data with scanf. Data is written with printf, and data is read with scanf. char password[100]; printf( "Enter your password: " ); fflush( stdout ); if (scanf( "%99s", password ) != 1) // Error .. -

Cheat Sheets of the C Standard Library
Cheat Sheets of the C standard library Version 1.06 Last updated: 2012-11-28 About This document is a set of quick reference sheets (or ‘cheat sheets’) of the ANSI C standard library. It contains function and macro declarations in every header of the library, as well as notes about their usage. This document covers C++, but does not cover the C99 or C11 standard. A few non-ANSI-standard functions, if they are interesting enough, are also included. Style used in this document Function names, prototypes and their parameters are in monospace. Remarks of functions and parameters are marked italic and enclosed in ‘/*’ and ‘*/’ like C comments. Data types, whether they are built-in types or provided by the C standard library, are also marked in monospace. Types of parameters and return types are in bold. Type modifiers, like ‘const’ and ‘unsigned’, have smaller font sizes in order to save space. Macro constants are marked using proportional typeface, uppercase, and no italics, LIKE_THIS_ONE. One exception is L_tmpnum, which is the constant that uses lowercase letters. Example: int system ( const char * command ); /* system: The value returned depends on the running environment. Usually 0 when executing successfully. If command == NULL, system returns whether the command processor exists (0 if not). */ License Copyright © 2011 Kang-Che “Explorer” Sung (宋岡哲 <explorer09 @ gmail.com>) This work is licensed under the Creative Commons Attribution 3.0 Unported License. http://creativecommons.org/licenses/by/3.0/ . When copying and distributing this document, I advise you to keep this notice and the references section below with your copies, as a way to acknowledging all the sources I referenced. -

Confine: Automated System Call Policy Generation for Container
Confine: Automated System Call Policy Generation for Container Attack Surface Reduction Seyedhamed Ghavamnia Tapti Palit Azzedine Benameur Stony Brook University Stony Brook University Cloudhawk.io Michalis Polychronakis Stony Brook University Abstract The performance gains of containers, however, come to the Reducing the attack surface of the OS kernel is a promising expense of weaker isolation compared to VMs. Isolation be- defense-in-depth approach for mitigating the fragile isola- tween containers running on the same host is enforced purely in tion guarantees of container environments. In contrast to software by the underlying OS kernel. Therefore, adversaries hypervisor-based systems, malicious containers can exploit who have access to a container on a third-party host can exploit vulnerabilities in the underlying kernel to fully compromise kernel vulnerabilities to escalate their privileges and fully com- the host and all other containers running on it. Previous con- promise the host (and all the other containers running on it). tainer attack surface reduction efforts have relied on dynamic The trusted computing base in container environments analysis and training using realistic workloads to limit the essentially comprises the entire kernel, and thus all its set of system calls exposed to containers. These approaches, entry points become part of the attack surface exposed to however, do not capture exhaustively all the code that can potentially malicious containers. Despite the use of strict potentially be needed by future workloads or rare runtime software isolation mechanisms provided by the OS, such as conditions, and are thus not appropriate as a generic solution. capabilities [1] and namespaces [18], a malicious tenant can Aiming to provide a practical solution for the protection leverage kernel vulnerabilities to bypass them. -

C Programming
C PROGRAMMING 6996 Columbia Gateway Drive Suite 100 Columbia, MD 21046 Tel: 443-692-6600 http://www.umbctraining.com C PROGRAMMING Course # TCPRG3000 Rev. 10/14/2016 ©2016 UMBC Training Centers 1 C PROGRAMMING This Page Intentionally Left Blank ©2016 UMBC Training Centers 2 C PROGRAMMING Course Objectives ● At the conclusion of this course, students will be able to: ⏵ Write non-trivial C programs. ⏵ Use data types appropriate to specific programming problems. ⏵ Utilize the modular features of the C languages. ⏵ Demonstrate efficiency and readability. ⏵ Use the various control flow constructs. ⏵ Create and traverse arrays. ⏵ Utilize pointers to efficiently solve problems. ⏵ Create and use structures to implement new data types. ⏵ Use functions from the C runtime library. ©2016 UMBC Training Centers 3 C PROGRAMMING This Page Intentionally Left Blank ©2016 UMBC Training Centers 4 C PROGRAMMING Table of Contents Chapter 1: Getting Started..............................................................................................9 What is C?..................................................................................................................10 Sample Program.........................................................................................................11 Components of a C Program......................................................................................13 Data Types.................................................................................................................14 Variables.....................................................................................................................16 -

C Programming Tutorial
C Programming Tutorial C PROGRAMMING TUTORIAL Simply Easy Learning by tutorialspoint.com tutorialspoint.com i COPYRIGHT & DISCLAIMER NOTICE All the content and graphics on this tutorial are the property of tutorialspoint.com. Any content from tutorialspoint.com or this tutorial may not be redistributed or reproduced in any way, shape, or form without the written permission of tutorialspoint.com. Failure to do so is a violation of copyright laws. This tutorial may contain inaccuracies or errors and tutorialspoint provides no guarantee regarding the accuracy of the site or its contents including this tutorial. If you discover that the tutorialspoint.com site or this tutorial content contains some errors, please contact us at [email protected] ii Table of Contents C Language Overview .............................................................. 1 Facts about C ............................................................................................... 1 Why to use C ? ............................................................................................. 2 C Programs .................................................................................................. 2 C Environment Setup ............................................................... 3 Text Editor ................................................................................................... 3 The C Compiler ............................................................................................ 3 Installation on Unix/Linux ............................................................................ -

Choosing System C Library
Choosing System C library Khem Raj Comcast Embedded Linux Conference Europe 2014 Düsseldorf Germany Introduction “God defined C standard library everything else is creation of man” Introduction • Standard library for C language • Provides primitives for OS service • Hosted/freestanding • String manipulations • Types • I/O • Memory • APIs Linux Implementations • GNU C library (glibc) • uClibc • eglibc – Now merged into glibc • Dietlibc • Klibc • Musl • bionic Multiple C library FAQs • Can I have multiple C libraries side by side ? • Can programs compiled with glibc run on uclibc or vice versa ? • Are they functional compatible ? • Do I need to choose one over other if I am doing real time Linux? • I have a baremetal application what libc options do I have ? Posix Compliance • Posix specifies more than ISO C • Varying degree of compliance What matters to you ? • Code Size • Functionality • Interoperability • Licensing • Backward Compatibility • Variety of architecture support • Dynamic Linking • Build system Codesize • Dietlibc/klibc – Used in really small setup e.g. initramfs • Bionic – Small linked into every process • uClibc – Configurable • Size can be really small at the expense of functionality • Eglibc – Has option groups can be ( < 1M ) License • Bionic – BSD/Apache-2.0 • Musl - MIT • Uclibc – LGPL-2.1 • Eglibc/Glibc – LGPL-2.1 Assigned to FSF • Dietlibc – GPLv2 • Klibc – GPLv2 • Newlib – some parts are GPLv3 Compliance • Musl strives for ISO/C and POSIX compliance No-mmu • uClibc supported No-mmu Distributions • Glibc is used in -

The Book of C Release 2018.01
The Book of C Release 2018.01 Joel Sommers Sep 16, 2018 CONTENTS 1 Introduction: The C Language3 2 Getting your feet wet in the C5 2.1 Hello, somebody............................................5 2.2 Hello, clang ...............................................7 3 Basic Types and Operators 11 3.1 Integer types.............................................. 11 3.2 Floating point types.......................................... 14 3.3 Boolean type.............................................. 15 3.4 Basic syntactic elements........................................ 15 4 Control Structures 23 4.1 if Statement.............................................. 23 4.2 The conditional expression (ternary operator)........................... 24 4.3 switch statement............................................ 24 4.4 while loop................................................ 25 4.5 do-while loop............................................. 25 4.6 for loop................................................. 26 5 Arrays and Strings 29 5.1 Arrays.................................................. 29 5.2 Multidimensional Arrays....................................... 32 5.3 C Strings................................................. 32 6 Aggregate Data Structures 39 6.1 The C struct .............................................. 39 7 Functions 43 7.1 Function syntax............................................. 43 7.2 Data types for parameters and return values............................ 45 7.3 Storage classes, the stack and the heap.............................. -
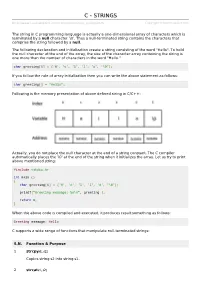
Strings in C
CC -- SSTTRRIINNGGSS http://www.tutorialspoint.com/cprogramming/c_strings.htm Copyright © tutorialspoint.com The string in C programming language is actually a one-dimensional array of characters which is terminated by a null character '\0'. Thus a null-terminated string contains the characters that comprise the string followed by a null. The following declaration and initialization create a string consisting of the word "Hello". To hold the null character at the end of the array, the size of the character array containing the string is one more than the number of characters in the word "Hello." char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'}; If you follow the rule of array initialization then you can write the above statement as follows: char greeting[] = "Hello"; Following is the memory presentation of above defined string in C/C++: Actually, you do not place the null character at the end of a string constant. The C compiler automatically places the '\0' at the end of the string when it initializes the array. Let us try to print above mentioned string: #include <stdio.h> int main () { char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'}; printf("Greeting message: %s\n", greeting ); return 0; } When the above code is compiled and executed, it produces result something as follows: Greeting message: Hello C supports a wide range of functions that manipulate null-terminated strings: S.N. Function & Purpose 1 strcpys1, s2; Copies string s2 into string s1. 2 strcats1, s2; Concatenates string s2 onto the end of string s1. 3 strlens1; Returns the length of string s1. -

Intel® Software Guard Extensions (Intel® SGX) SDK for Linux* OS
Intel® Software Guard Extensions (Intel® SGX) SDK for Linux* OS Developer Reference Intel(R) Software Guard Extensions Developer Reference for Linux* OS Legal Information No license (express or implied, by estoppel or otherwise) to any intellectual prop- erty rights is granted by this document. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non- infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, spe- cifications and roadmaps. The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request. Intel technologies features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at Intel.com, or from the OEM or retailer. Copies of documents which have an order number and are referenced in this doc- ument may be obtained by calling 1-800-548-4725 or by visiting www.in- tel.com/design/literature.htm. Intel, the Intel logo, VTune, Xeon, and Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. Optimization Notice Intel's compilers may or may not optimize to the same degree for non-Intel micro- processors for optimizations that are not unique to Intel microprocessors. -

Function Pointer and C Standard Library
Function Pointer and C Standard Library 魏恒峰 [email protected] 2017 年 11 月 24 日 . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 1 / 22 Function Pointer . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 2 / 22 sort_ints sort_floats sort_strings sort_persons ··· Compare & Swap Sort . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 3 / 22 sort_ints sort_floats sort_strings sort_persons ··· Sort Compare & Swap . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 3 / 22 sort_ints sort_floats sort_strings sort_persons ··· Sort for any types Compare & Swap . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 3 / 22 Sort for any types Compare & Swap sort_ints sort_floats sort_strings sort_persons ··· . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 3 / 22 Sort for any types Compare & Swap sort_ints sort_floats sort_strings sort_persons ··· . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 3 / 22 (compare.c) (#include <stdlib.h>) void qsort (void *base, size_t num, size_t size, int (*compar)(const void*, const void*)); . Hengfeng Wei ([email protected]) Function Pointer and C Standard Library 2017 年 11 月 24 日 4 / 22 (#include <stdlib.h>) void qsort (void *base, size_t num, size_t size, int (*compar)(const void*, const void*)); (compare.c) . -

C++17 Standard Library Quick Reference
C++17 Standard Library Quick Reference A Pocket Guide to Data Structures, Algorithms, and Functions Second Edition Peter Van Weert Marc Gregoire C++17 Standard Library Quick Reference: A Pocket Guide to Data Structures, Algorithms, and Functions Peter Van Weert Marc Gregoire Kessel-Lo, Belgium Meldert, Belgium ISBN-13 (pbk): 978-1-4842-4922-2 ISBN-13 (electronic): 978-1-4842-4923-9 https://doi.org/10.1007/978-1-4842-4923-9 Copyright © 2019 by Peter Van Weert and Marc Gregoire This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. Trademarked names, logos, and images may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, logo, or image we use the names, logos, and images only in an editorial fashion and to the benefit of the trademark owner, with no inten- tion of infringement of the trademark. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. While the advice and information in this book are believed to be true and accurate at the date of publication, neither the authors nor the editors nor the publisher can accept any legal responsibil- ity for any errors or omissions that may be made.