NAT Traversal Techniques and UDP Keep-Alive Interval Optimization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

N2N: a Layer Two Peer-To-Peer VPN
N2N: A Layer Two Peer-to-Peer VPN Luca Deri1, Richard Andrews2 ntop.org, Pisa, Italy1 Symstream Technologies, Melbourne, Australia2 {deri, andrews}@ntop.org Abstract. The Internet was originally designed as a flat data network delivering a multitude of protocols and services between equal peers. Currently, after an explosive growth fostered by enormous and heterogeneous economic interests, it has become a constrained network severely enforcing client-server communication where addressing plans, packet routing, security policies and users’ reachability are almost entirely managed and limited by access providers. From the user’s perspective, the Internet is not an open transport system, but rather a telephony-like communication medium for content consumption. This paper describes the design and implementation of a new type of peer-to- peer virtual private network that can allow users to overcome some of these limitations. N2N users can create and manage their own secure and geographically distributed overlay network without the need for central administration, typical of most virtual private network systems. Keywords: Virtual private network, peer-to-peer, network overlay. 1. Motivation and Scope of Work Irony pervades many pages of history, and computing history is no exception. Once personal computing had won the market battle against mainframe-based computing, the commercial evolution of the Internet in the nineties stepped the computing world back to a substantially rigid client-server scheme. While it is true that the today’s Internet serves as a good transport system for supplying a plethora of data interchange services, virtually all of them are delivered by a client-server model, whether they are centralised or distributed, pay-per-use or virtually free [1]. -

Distributed Deep Learning in Open Collaborations
Distributed Deep Learning In Open Collaborations Michael Diskin∗y~ Alexey Bukhtiyarov∗| Max Ryabinin∗y~ Lucile Saulnierz Quentin Lhoestz Anton Sinitsiny~ Dmitry Popovy~ Dmitry Pyrkin~ Maxim Kashirin~ Alexander Borzunovy~ Albert Villanova del Moralz Denis Mazur| Ilia Kobelevy| Yacine Jernitez Thomas Wolfz Gennady Pekhimenko♦♠ y Yandex, Russia z Hugging Face, USA ~ HSE University, Russia | Moscow Institute of Physics and Technology, Russia } University of Toronto, Canada ♠ Vector Institute, Canada Abstract Modern deep learning applications require increasingly more compute to train state-of-the-art models. To address this demand, large corporations and institutions use dedicated High-Performance Computing clusters, whose construction and maintenance are both environmentally costly and well beyond the budget of most organizations. As a result, some research directions become the exclusive domain of a few large industrial and even fewer academic actors. To alleviate this disparity, smaller groups may pool their computational resources and run collaborative experiments that benefit all participants. This paradigm, known as grid- or volunteer computing, has seen successful applications in numerous scientific areas. However, using this approach for machine learning is difficult due to high latency, asymmetric bandwidth, and several challenges unique to volunteer computing. In this work, we carefully analyze these constraints and propose a novel algorithmic framework designed specifically for collaborative training. We demonstrate the effectiveness of our approach for SwAV and ALBERT pretraining in realistic conditions and achieve performance comparable to traditional setups at a fraction of the cost. arXiv:2106.10207v1 [cs.LG] 18 Jun 2021 Finally, we provide a detailed report of successful collaborative language model pretraining with 40 participants. 1 Introduction The deep learning community is becoming increasingly more reliant on transfer learning. -

User Datagram Protocol - Wikipedia, the Free Encyclopedia Página 1 De 6
User Datagram Protocol - Wikipedia, the free encyclopedia Página 1 de 6 User Datagram Protocol From Wikipedia, the free encyclopedia The five-layer TCP/IP model User Datagram Protocol (UDP) is one of the core 5. Application layer protocols of the Internet protocol suite. Using UDP, programs on networked computers can send short DHCP · DNS · FTP · Gopher · HTTP · messages sometimes known as datagrams (using IMAP4 · IRC · NNTP · XMPP · POP3 · Datagram Sockets) to one another. UDP is sometimes SIP · SMTP · SNMP · SSH · TELNET · called the Universal Datagram Protocol. RPC · RTCP · RTSP · TLS · SDP · UDP does not guarantee reliability or ordering in the SOAP · GTP · STUN · NTP · (more) way that TCP does. Datagrams may arrive out of order, 4. Transport layer appear duplicated, or go missing without notice. TCP · UDP · DCCP · SCTP · RTP · Avoiding the overhead of checking whether every RSVP · IGMP · (more) packet actually arrived makes UDP faster and more 3. Network/Internet layer efficient, at least for applications that do not need IP (IPv4 · IPv6) · OSPF · IS-IS · BGP · guaranteed delivery. Time-sensitive applications often IPsec · ARP · RARP · RIP · ICMP · use UDP because dropped packets are preferable to ICMPv6 · (more) delayed packets. UDP's stateless nature is also useful 2. Data link layer for servers that answer small queries from huge 802.11 · 802.16 · Wi-Fi · WiMAX · numbers of clients. Unlike TCP, UDP supports packet ATM · DTM · Token ring · Ethernet · broadcast (sending to all on local network) and FDDI · Frame Relay · GPRS · EVDO · multicasting (send to all subscribers). HSPA · HDLC · PPP · PPTP · L2TP · ISDN · (more) Common network applications that use UDP include 1. -
NAT Traversal About
NAT Traversal About Some difficulties have been encountered with devices that have poor NAT support. FreeSWITCH goes to great lengths to repair broken NAT support in phones and gateway devices. In order to aid FreeSWITCH in traversing NAT please see the External profile page. Some routers offer an Application Layer Gateway feature which can prevent FreeSWITCH NAT traversal from working. See the ALG page for more information, including how to disable it. Using STUN to aid in NAT Traversal STUN is a method to allow an end host (i.e. phone) to discover its public IP address if it is located behind a NAT . Using this method requires a STUN server on the public internet and a client on the phone. The phone's STUN client queries the STUN server for it's own public IP and transmits the information it has received in it's connection information in the SIP packets it sends to the SIP server. Enable and configure STUN settings on your phone in order correctly to report your phone's contact information to FreeSWITCH when registering. Unfortunately, not all phones have a properly working STUN client. STUN servers This site contains a list of public STUN servers: https://gist.github.com/zziuni/3741933 stun.freeswitch.org is never guaranteed to be up and running so use it in production at your own risk. There are several open source projects to run your own STUN server, e.g. STUNTMAN Using FreeSWITCH built-in methods to aid in NAT Traversal nat-options-ping This parameter causes FreeSWITCH to regularly (every 20 - 40s) send an OPTIONS packet to NATed registered endpoints in order to keep the port on the clients firewall open. -

NAT and NAT Traversal Lecturer: Andreas Müller [email protected]
NAT and NAT Traversal lecturer: Andreas Müller [email protected] NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 39 NAT: Network Address Translation Problem: shortage of IPv4 addresses . more and more devices . only 32bit address field Idea: local network uses just one IP address as far as outside world is concerned: . range of addresses not needed from ISP: just one IP address for all devices . can change addresses of devices in local network without notifying outside world . can change ISP without changing addresses of devices in local network . devices inside local net not explicitly addressable, visible by outside world (a security plus). NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 40 NAT: Network Address (and Port) Translation rest of local network Internet (e.g., home network) 10.0.0/24 10.0.0.1 10.0.0.4 10.0.0.2 138.76.29.7 10.0.0.3 All datagrams leaving local Datagrams with source or network have same single source destination in this network NAT IP address: 138.76.29.7, have 10.0.0/24 address for different source port numbers source, destination (as usual) NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 41 NAT: Network Address Translation Implementation: NAT router must: . outgoing datagrams: replace (source IP address, port #) of every outgoing datagram to (NAT IP address, new port #) . remote clients/servers will respond using (NAT IP address, new port #) as destination addr. remember (in NAT translation table) every (source IP address, port #) to (NAT IP address, new port #) translation pair -> we have to maintain a state in the NAT . -

Routing Loop Attacks Using Ipv6 Tunnels
Routing Loop Attacks using IPv6 Tunnels Gabi Nakibly Michael Arov National EW Research & Simulation Center Rafael – Advanced Defense Systems Haifa, Israel {gabin,marov}@rafael.co.il Abstract—IPv6 is the future network layer protocol for A tunnel in which the end points’ routing tables need the Internet. Since it is not compatible with its prede- to be explicitly configured is called a configured tunnel. cessor, some interoperability mechanisms were designed. Tunnels of this type do not scale well, since every end An important category of these mechanisms is automatic tunnels, which enable IPv6 communication over an IPv4 point must be reconfigured as peers join or leave the tun- network without prior configuration. This category includes nel. To alleviate this scalability problem, another type of ISATAP, 6to4 and Teredo. We present a novel class of tunnels was introduced – automatic tunnels. In automatic attacks that exploit vulnerabilities in these tunnels. These tunnels the egress entity’s IPv4 address is computationally attacks take advantage of inconsistencies between a tunnel’s derived from the destination IPv6 address. This feature overlay IPv6 routing state and the native IPv6 routing state. The attacks form routing loops which can be abused as a eliminates the need to keep an explicit routing table at vehicle for traffic amplification to facilitate DoS attacks. the tunnel’s end points. In particular, the end points do We exhibit five attacks of this class. One of the presented not have to be updated as peers join and leave the tunnel. attacks can DoS a Teredo server using a single packet. The In fact, the end points of an automatic tunnel do not exploited vulnerabilities are embedded in the design of the know which other end points are currently part of the tunnels; hence any implementation of these tunnels may be vulnerable. -

CS 638 Lab 6: Transport Control Protocol (TCP)
CS 638 Lab 6: Transport Control Protocol (TCP) Joe Chabarek and Paul Barford University of Wisconsin –Madison jpchaba,[email protected] The transport layer of the network protocol stack 1 Overview and Objectives (layer 4) sits between applications (layers 5-7) and Unlike prior labs, the focus of lab #6 is is on the network (layer 3 and below). The most basic learning more about experimental tools and on ob- capability that is enabled by transport is multiplex- serving the behavior of the various mechanisms that ing the network between multiple applications that are part of TCP. The reason for this is because in wish to communicate with remote hosts. Similar to moving from layer 3 to layer 4, we are moving away other layers of the network protocol stack, transport from the network per se, and into end hosts. Further- protocols encapsulate packets with their own header more, network administrators usually don’t spend a before passing them down to layer 3 and decapsulate lot of time messing around with TCP since there is packets before passing them up to applications. no programming or management interface to TCP The most simple transport protocol is the User on end hosts. The exception is content providers Datagram Protocol (UDP). UDP provides a mul- who may make tweaks in an attempt to get better tiplexing/demultiplexing capability for applications performance on large file transfers. but not much more. Most significantly, UDP pro- In terms of experimental tools, a focus of this vides no guarantees for reliability, which is unac- lab is on learning about traffic generation. -
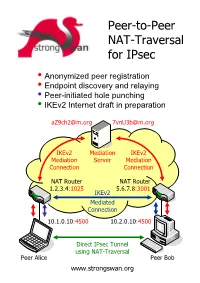
Peer-To-Peer NAT-Traversal for Ipsec
Peer-to-Peer NAT-Traversal for IPsec y Anonymized peer registration y Endpoint discovery and relaying y Peer-initiated hole punching y IKEv2 Internet draft in preparation [email protected] [email protected] IKEv2 Mediation IKEv2 Mediation Server Mediation Connection Connection NAT Router NAT Router 1.2.3.4:1025 5.6.7.8:3001 IKEv2 Mediated Connection 10.1.0.10:4500 10.2.0.10:4500 Direct IPsec Tunnel using NAT-Traversal Peer Alice Peer Bob www.strongswan.org The double NAT case - where punching holes counts! ● You are selling automation systems all over the world. In order to save on travel expenses you want to remotely diagnose and update your deployed systems via the Internet. But security counts – thus IPsec is a must! Unfortunately both you and your customer are behind NAT routers so that no direct VPN connection is possible. You are helplessly blocked! ● You own an apartment at home, in the mountains or even abroad. You want to remotely control the heating or your sophisticated intrusion detection system via ADSL or Cable access. But since you and your apartment are separated by two NAT routers your are helplessly blocked. How it works! ● Two peers want to set up a direct IPsec tunnel using the established NAT traversal mechanism of encapsulating ESP packets in UDP datagrams. Unfortunately they cannot achieve this by themselves because neither host is seen from the Internet under the standard IKE NAT-T port 4500. Therefore both peers need to set up a mediation connection with an IKEv2 mediation server. In order to prevent unsolicited connection attempts by foreign peers, the mediation connections use randomized pseudonyms as IKE peer identities. -

Problems of Ipsec in Combination with NAT and Their Solutions
Problems of IPsec in Combination with NAT and Their Solutions Alexander Heinlein Abstract As the Internet becomes more and more a part of our daily life it also evolves as an at- tractive target for security attacks, often countered by Internet Protocol Security (IPsec) to establish virtual private networks (VPNs), if secure data communication is a primary objective. Then again, to provide Internet access for hosts inside Local Area Networks, a public IP address shared among all peers is often used, achieved by Network Address Translation (NAT) deployment. IPsec, however, is incompatible with NAT, leading to a variety of problems when using both in combination. Connection establishments origi- nating from the outside are blocked and NAT, as it modifies the outer IP header, breaks IPsec’s security mechanisms. In the following we analyze problems of NAT in combination with IPsec and multiple approaches to solve them. 1 Introduction The current TCP/IP protocols originate from a time where security was not a great concern. As the traditional Internet Protocol (IP) does not provide any guarantees on delivery, the receiver cannot detect whether the sender is the same one as recorded in the protocol header or if the packet was modified during transport. Moreover an attacker may also easily replay IP packets or read sensitive information out of them. In contrast, today, as the Internet becomes more and more a part of our everyday life, a more security aware protocol is needed. To fill this gap the Internet Engineering Task Force (IETF) worked on a new standard for securing IP, called Internet Protocol Security (IPsec). -

Developing P2P Protocols Across NAT Girish Venkatachalam
Developing P2P Protocols across NAT Girish Venkatachalam Abstract Hole punching is a possible solution to solving the NAT problem for P2P protocols. Network address translators (NATs) are something every software engineer has heard of, not to mention networking professionals. NAT has become as ubiquitous as the Cisco router in networking terms. Fundamentally, a NAT device allows multiple machines to communicate with the Internet using a single globally unique IP address, effectively solving the scarce IPv4 address space problem. Though not a long-term solution, as originally envisaged in 1994, for better or worse, NAT technology is here to stay, even when IPv6 addresses become common. This is partly because IPv6 has to coexist with IPv4, and one of the ways to achieve that is by using NAT technology. This article is not so much a description of how a NAT works. There already is an excellent article on this subject by Geoff Huston (see the on-line Resources). It is quite comprehensive, though plenty of other resources are available on the Internet as well. This article discusses a possible solution to solving the NAT problem for P2P protocols. What Is Wrong with NAT? NAT breaks the Internet more than it makes it. I may sound harsh here, but ask any peer-to-peer application developer, especially the VoIP folks, and they will tell you why. For instance, you never can do Web hosting behind a NAT device. At least, not without sufficient tweaking. Not only that, you cannot run any service such as FTP or rsync or any public service through a NAT device. -

Serial/IP COM Port Redirector User Guide
Navigation: »No topics above this level« Serial/IP® COM Port Redirector User Guide OEM Edition Quick Start Guide Version 4.9 Serial/IP is a registered trademark of Tactical Software, LLC. Tactical Software is a registered trademark of Tactical Software, LLC. Copyright © 2016 Tactical Software, LLC. www.tacticalsoftware.com This Quick Start Guide describes how to install and configure the Serial/IP Redirector so that the Windows applications can use virtual COM ports to access networked serial devices. Configure the Serial Device Server Make sure that the serial server makes its devices available on a TCP port. Install the Serial/IP Software · Log in as Administrator. · Run the Serial/IP setup program. · Use all default choices. · The Serial/IP Redirector will begin running. Windows will not need to be restarted. Create Virtual COM Ports In the Select Ports window, select one or more virtual COM ports, and then click OK. The Serial/IP Select Ports window Configure a Virtual COM Port Enter the IP Address of the serial device server. Enter the TCP Port Number that it is listening on. If the server requires a login, then select the Use Credentials From checkbox. Then in the drop-down list, select Use Credentials Below and enter the Username and Password. The Serial/IP Control Panel Run Auto Configure Click Auto Configure. In the Auto Configure window, click Start. When it completes, click Use Settings. The correct setting will be made for Connection Protocol. The Serial/IP Auto Configure window Ensure that Firewall Software Permits Connections The Serial/IP setup program will add an exception for Serial/IP in the Microsoft Windows Firewall. -

Hybrid ATA with FXS and FXO Ports
Hybrid ATA with FXS and FXO ports HT813 The HT813 is an analog telephone adapter that features 1 analog telephone FXS port and 1 PSTN line FXO port in order to offer backup lifeline support using a PSTN line. The integration of a FXO and FXS port enables this hybrid ATA to support remote calling to and from the PSTN line. For added flexibility, the FXS port extends VoIP service to one analog device. Users can convert their analog technology to VoIP thanks to the HT813’s ultra-compact size, HD voice quality, advanced VoIP functionality, high-end security protection and multiple auto provisioning options. These advanced features also allow service providers to offer high quality IP service to customers looking to upgrade to VoIP. Supports 2 SIP Dual 100Mbps LAN Lifeline support (FXS 3-way voice profiles through 1 and WAN ports port will be hard- conferencing per FXS port and 1 FXO relayed to FXO port) port port in case of power outage Automated & secure Supports T.38 Fax Failover SIP server Strong AES encryption provisioning options for reliable Fax- automatically with security using TR069 over-IP switches to certificate per unit secondary server if main server loses connection www.grandstream.com Telephone Interfaces One (1) RJ11 FXS port, One (1) RJ11 FXO PSTN line port with lifeline support Network Interface Two (2) 10/100Mbps ports (RJ45) with integrated NAT router LED Indicators POWER, LAN, WAN, FXS, FXO Factory Reset Button Yes Voice, Fax, Modem Caller ID display or block, call waiting, flash, blind or attended transfer, forward,