Design, Implementation, and Applications of Peer-To-Peer Virtual Private Networks from Grids to Social Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

N2N: a Layer Two Peer-To-Peer VPN
N2N: A Layer Two Peer-to-Peer VPN Luca Deri1, Richard Andrews2 ntop.org, Pisa, Italy1 Symstream Technologies, Melbourne, Australia2 {deri, andrews}@ntop.org Abstract. The Internet was originally designed as a flat data network delivering a multitude of protocols and services between equal peers. Currently, after an explosive growth fostered by enormous and heterogeneous economic interests, it has become a constrained network severely enforcing client-server communication where addressing plans, packet routing, security policies and users’ reachability are almost entirely managed and limited by access providers. From the user’s perspective, the Internet is not an open transport system, but rather a telephony-like communication medium for content consumption. This paper describes the design and implementation of a new type of peer-to- peer virtual private network that can allow users to overcome some of these limitations. N2N users can create and manage their own secure and geographically distributed overlay network without the need for central administration, typical of most virtual private network systems. Keywords: Virtual private network, peer-to-peer, network overlay. 1. Motivation and Scope of Work Irony pervades many pages of history, and computing history is no exception. Once personal computing had won the market battle against mainframe-based computing, the commercial evolution of the Internet in the nineties stepped the computing world back to a substantially rigid client-server scheme. While it is true that the today’s Internet serves as a good transport system for supplying a plethora of data interchange services, virtually all of them are delivered by a client-server model, whether they are centralised or distributed, pay-per-use or virtually free [1]. -
NAT Traversal About
NAT Traversal About Some difficulties have been encountered with devices that have poor NAT support. FreeSWITCH goes to great lengths to repair broken NAT support in phones and gateway devices. In order to aid FreeSWITCH in traversing NAT please see the External profile page. Some routers offer an Application Layer Gateway feature which can prevent FreeSWITCH NAT traversal from working. See the ALG page for more information, including how to disable it. Using STUN to aid in NAT Traversal STUN is a method to allow an end host (i.e. phone) to discover its public IP address if it is located behind a NAT . Using this method requires a STUN server on the public internet and a client on the phone. The phone's STUN client queries the STUN server for it's own public IP and transmits the information it has received in it's connection information in the SIP packets it sends to the SIP server. Enable and configure STUN settings on your phone in order correctly to report your phone's contact information to FreeSWITCH when registering. Unfortunately, not all phones have a properly working STUN client. STUN servers This site contains a list of public STUN servers: https://gist.github.com/zziuni/3741933 stun.freeswitch.org is never guaranteed to be up and running so use it in production at your own risk. There are several open source projects to run your own STUN server, e.g. STUNTMAN Using FreeSWITCH built-in methods to aid in NAT Traversal nat-options-ping This parameter causes FreeSWITCH to regularly (every 20 - 40s) send an OPTIONS packet to NATed registered endpoints in order to keep the port on the clients firewall open. -

NAT and NAT Traversal Lecturer: Andreas Müller [email protected]
NAT and NAT Traversal lecturer: Andreas Müller [email protected] NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 39 NAT: Network Address Translation Problem: shortage of IPv4 addresses . more and more devices . only 32bit address field Idea: local network uses just one IP address as far as outside world is concerned: . range of addresses not needed from ISP: just one IP address for all devices . can change addresses of devices in local network without notifying outside world . can change ISP without changing addresses of devices in local network . devices inside local net not explicitly addressable, visible by outside world (a security plus). NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 40 NAT: Network Address (and Port) Translation rest of local network Internet (e.g., home network) 10.0.0/24 10.0.0.1 10.0.0.4 10.0.0.2 138.76.29.7 10.0.0.3 All datagrams leaving local Datagrams with source or network have same single source destination in this network NAT IP address: 138.76.29.7, have 10.0.0/24 address for different source port numbers source, destination (as usual) NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 41 NAT: Network Address Translation Implementation: NAT router must: . outgoing datagrams: replace (source IP address, port #) of every outgoing datagram to (NAT IP address, new port #) . remote clients/servers will respond using (NAT IP address, new port #) as destination addr. remember (in NAT translation table) every (source IP address, port #) to (NAT IP address, new port #) translation pair -> we have to maintain a state in the NAT . -

19 Internet Activity
1 Practical Paranoia: macOS 10.13 Security Essentials Author: Marc Mintz Copyright © 2016, 2017 by The Practical Paranoid, LLC. Notice of Rights: All rights reserved. No part of this document may be reproduced or transmitted in any form by any means without the prior written permission of the author. For information on obtaining permission for reprints and excerpts, contact the author at [email protected], +1 888.504.5591. Notice of Liability: The information in this document is presented on an As Is basis, without warranty. While every precaution has been taken in the preparation of this document, the author shall have no liability to any person or entity with respect to any loss or damage caused by or alleged to be caused directly or indirectly by the instructions contained in this document, or by the software and hardware products described within it. It is provided with the understanding that no professional relationship exists and no professional security or Information Technology services have been offered between the author or the publisher and the reader. If security or Information Technology expert assistance is required, the services of a professional person should be sought. Trademarks: Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the author was aware of a trademark claim, the designations appear as requested by the owner of the trademark. All other product names and services identified in this document are used in editorial fashion only and for the benefit of such companies with no intention of infringement of trademark. -

Microsoft Free Download Vpn Connect to Servers from 79+ Countries
microsoft free download vpn Connect to servers from 79+ countries. ZenMate Ultimate has about 3500 servers from over 79 different countries for you to choose from. Select the country you want and stay 100% anonymous online. No-Logs Policy. ZenMate VPN never records any of our users' online activity. Make sure you're truly anonymous when you're surfing the web with our free browser extension. Stay Protected on Multiple Devices. 1 ZenMate Ultimate subscription covers an unlimited number of devices. This way you can keep all your gadgets safe when surfing the web. Military-Grade Encryption. ZenMate uses AES-256 encryption, the military standard. This way your data and connection are impossible to hack. Unblock Websites. Bypass governmental restrictions and unblock websites that aren't available in your location by connecting to one of our remote servers. Trusted by Over 47 Million Users. Over 47 million people choose ZenMate VPN to keep all their sensitive information private and to bypass geo-restrictions. Here’s What Our Users Have to Say. Choose the Plan That's Right for You. 1 Month. 1 Year. 6 Months. Frequently Asked Questions. To use ZenMate VPN on Microsoft Edge, simply add the extension from the Microsoft Edge Store. Create and verify your account. Then you'll see the ZenMate icon next to your search bar. Click on it and in the lower left corner of the pop-up window you'll see a button to turn ZenMate on. To download the best Edge VPN available simply visit the Microsoft Edge Store and add ZenMate VPN to your browser. -

Xmind ZEN 9.1.3 Crack FREE Download
1 / 4 XMind ZEN 9.1.3 Crack FREE Download Download XMind ZEN 9.2.1 Build Windows / 9.1.3 macOS for free at ... Version 9.2.1 is cracked, then install the program and click Skip in the Login window.. Adobe Premiere Pro CC 2019 13.1.2 – For macOS Cracked With Serial Number.. Free Download XMind ZEN 9.1.3 Build. 201812101752 Win / macOS Cracked .... 3 Crack + Serial Key Free Download. Malwarebytes 4.2.3 Crack Real-time safety of all threats very effectively. This is a .... ZW3D 2019 SP2 Download 32-64 Bit For Windows. The Powerful engineering ... XMind ZEN 9.1.3 Download. Free Download Keysight .... With this app, you can download online maps, digital maps and even ... Tableau Desktop Pro 2019.4.0 Win + Crack · XMind ZEN 9.2.0 Build .... Download Free XMind: ZEN 9.1.3 Build 201812101752 for Mac on Mac Torrent Download. XMind: ZEN 9.1.3 Build 201812101752 is a .... XMind 8 Pro 3 7 6 Mac Crack Full version free download is the latest version of the most advanced and Popular Mind ... XMind ZEN for Mac 9.1.3 Serial Key ... Download Nero KnowHow for PC - free download Nero KnowHow for ... The full version comes in single user and a family variant with the former costing ... Download XMind ZEN 9.2.1 Build Windows / 9.1.3 macOS for free at .... XMind ZEN Crack 10.3.0 With Keygen Full Torrent Download 2021 For PC · XMind Crack 9.1.3 With Keygen Full Torrent Download 2019 For PC. -
Peer-To-Peer NAT-Traversal for Ipsec
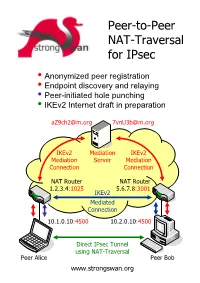
Peer-to-Peer NAT-Traversal for IPsec y Anonymized peer registration y Endpoint discovery and relaying y Peer-initiated hole punching y IKEv2 Internet draft in preparation [email protected] [email protected] IKEv2 Mediation IKEv2 Mediation Server Mediation Connection Connection NAT Router NAT Router 1.2.3.4:1025 5.6.7.8:3001 IKEv2 Mediated Connection 10.1.0.10:4500 10.2.0.10:4500 Direct IPsec Tunnel using NAT-Traversal Peer Alice Peer Bob www.strongswan.org The double NAT case - where punching holes counts! ● You are selling automation systems all over the world. In order to save on travel expenses you want to remotely diagnose and update your deployed systems via the Internet. But security counts – thus IPsec is a must! Unfortunately both you and your customer are behind NAT routers so that no direct VPN connection is possible. You are helplessly blocked! ● You own an apartment at home, in the mountains or even abroad. You want to remotely control the heating or your sophisticated intrusion detection system via ADSL or Cable access. But since you and your apartment are separated by two NAT routers your are helplessly blocked. How it works! ● Two peers want to set up a direct IPsec tunnel using the established NAT traversal mechanism of encapsulating ESP packets in UDP datagrams. Unfortunately they cannot achieve this by themselves because neither host is seen from the Internet under the standard IKE NAT-T port 4500. Therefore both peers need to set up a mediation connection with an IKEv2 mediation server. In order to prevent unsolicited connection attempts by foreign peers, the mediation connections use randomized pseudonyms as IKE peer identities. -

Problems of Ipsec in Combination with NAT and Their Solutions
Problems of IPsec in Combination with NAT and Their Solutions Alexander Heinlein Abstract As the Internet becomes more and more a part of our daily life it also evolves as an at- tractive target for security attacks, often countered by Internet Protocol Security (IPsec) to establish virtual private networks (VPNs), if secure data communication is a primary objective. Then again, to provide Internet access for hosts inside Local Area Networks, a public IP address shared among all peers is often used, achieved by Network Address Translation (NAT) deployment. IPsec, however, is incompatible with NAT, leading to a variety of problems when using both in combination. Connection establishments origi- nating from the outside are blocked and NAT, as it modifies the outer IP header, breaks IPsec’s security mechanisms. In the following we analyze problems of NAT in combination with IPsec and multiple approaches to solve them. 1 Introduction The current TCP/IP protocols originate from a time where security was not a great concern. As the traditional Internet Protocol (IP) does not provide any guarantees on delivery, the receiver cannot detect whether the sender is the same one as recorded in the protocol header or if the packet was modified during transport. Moreover an attacker may also easily replay IP packets or read sensitive information out of them. In contrast, today, as the Internet becomes more and more a part of our everyday life, a more security aware protocol is needed. To fill this gap the Internet Engineering Task Force (IETF) worked on a new standard for securing IP, called Internet Protocol Security (IPsec). -

The Impact of Network Address Translation on Peer-To-Peer Live Video Streaming Systems
The Impact of Network Address Translation on Peer-to-Peer Live Video Streaming Systems by Zhonghua Wei M.Sc., University of London, 2006 B.Eng., Beijing Univ. of Posts and Telecommunications, 2005 A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE in the Department of Computer Science c Zhonghua Wei, 2011 University of Victoria All rights reserved. This thesis may not be reproduced in whole or in part, by photocopying or other means, without the permission of the author. ii The Impact of Network Address Translation on Peer-to-Peer Live Video Streaming Systems by Zhonghua Wei M.Sc., University of London, 2006 B.Eng., Beijing Univ. of Posts and Telecommunications, 2005 Supervisory Committee Dr. Jianping Pan, Supervisor (Department of Computer Science) Dr. Kui Wu, Departmental Member (Department of Computer Science) iii Supervisory Committee Dr. Jianping Pan, Supervisor (Department of Computer Science) Dr. Kui Wu, Departmental Member (Department of Computer Science) ABSTRACT Video streaming over the Internet can be very difficult under the traditional client-server model. Peer-to-peer (P2P) systems, in which each participating peer contributes its upload bandwidth to other peers while it downloads data, have been successful in file-sharing applications, and they appear to be promising in delivering video contents, too. However, the existence of network address translation (NAT) is always considered as a challenge to peer-to-peer systems. NAT has been a practical solution to the Internet Protocol version 4 (IPv4) address exhaustion problem, as it reduces the usage of IP addresses by allowing multiple private hosts to share a single public IP address, but NAT can degrade the performance of a peer-to-peer system as it limits the direction of connectivity. -

On the Design and Implementation of IP-Over-P2P Overlay Virtual Private
DOI:10.1587/transcom.2019CPI0001 Publicized:2019/08/05 This article has been accepted and published on J-STAGE in advance of copyediting. Content is final as presented. 1 Invited Paper On the Design and Implementation of IP-over-P2P Overlay Virtual Private Networks Kensworth Subratie†, Saumitra Aditya†, Vahid Daneshmand†, Kohei Ichikawa††, and Renato Figueiredo† SUMMARY The success and scale of the Internet and its protocol IP has protocols (e.g. TLS [2], [3]). As a result, distributed spurred emergent distributed technologies such as fog/edge computing and applications that run across the Internet often must deal with new application models based on distributed containerized microservices. The Internet of Things and Connected Communities are poised to build on devices without public IPv4 addresses that are behind these technologies and models and to benefit from the ability to various NAT and firewall middleboxes and must create communicate in a peer-to-peer (P2P) fashion. Ubiquitous sensing, actuating secure transport sessions for communication. While these and computing implies a scale that breaks the centralized cloud computing issues are relatively easy to handle with client-server model. Challenges stemming from limited IPv4 public addresses, the need applications, they place a burden to applications where peer- for transport layer authentication, confidentiality and integrity become a burden on developing new middleware and applications designed for the to-peer communication is needed. network’s edge. One approach - not reliant on the slow adoption of IPv6 - Emerging distributed applications in edge/fog [4], [5] is the use of virtualized overlay networks, which abstract the complexities computing are poised to benefit from the ability for IoT and of the underlying heterogeneous networks that span the components of edge nodes to communicate in a peer-to-peer fashion. -

Comparison of Virtual Networks Solutions for Community Clouds
KTH Royal Institute of Technology Bachelor Thesis Comparison of Virtual Networks Solutions for Community Clouds Examiner: Vladimir Vlassov Author: Albert Avellana Supervisors: Paris Carbone, Hooman Peiro Information and Communication Technology School February 2014 KTH Royal Institute of Technology Abstract Information and Communication Technology School Bachelor Thesis Comparison of Virtual Networks Solutions for Community Clouds by Albert Avellana Cloud computing has a huge importance and big impact nowadays on the IT world. The idea of community clouds has emerged recently in order to satisfy several user expectations. Clommunity is a European project that aims to provide a design and implementation of a self-configured, fully distributed, decentralized, scalable and robust cloud for a community of users across a commmunity network. One of the aspects to analyze in this design is which kind of Virtual Private Network (VPN) is going to be used to interconnect the nodes of the community members interested in access cloud services. In this thesis we will study, compare and analyze the possibility of using Tinc, IPOP or SDN-based solutions such as OpenFlow to establish such a VPN. Acknowledgements I would like to express my gratitude to all those who gave me the possibility to do this thesis in KTH. Firstly, I would like to thank Vlad for the opportunity he gave me to do this thesis and for his support. Secondly, thanks to my thesis supervisors: Paris Carbone and Hooman Peiro, who guided me through the research, helped me and gave me recommendations during this period. Also, I would like to thank F´elixFreitag and Leandro Navarro from Universitat Polit`ecnica de Catalunya for supporting me from Barcelona and make this stay in Stockholm possi- ble.