Nomoads: Effective and Efficient Cross-App Mobile Ad-Blocking
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

E Cost of Ad Blocking Pagefair and Adobe 2015 Ad Blocking Report
!e cost of ad blocking PageFair and Adobe 2015 Ad Blocking Report Introduction In the third annual ad blocking report, PageFair, with the help of Adobe, provides updated data on the scale and growth of ad blocking so"ware usage and highlights the global and regional economic impact associated with it. Additionally, this report explores the early indications surrounding the impact of ad blocking within the mobile advertising space and how mobile will change the ad blocking landscape. Table of Contents 3. Key insights 8. Effect of ad blocking by industry 13. A"erword 4. Global ad blocking growth 9. Google Chrome still the main driver of ad 14. Background 5. Usage of ad blocking so"ware in the United block growth 15. Methodology States 10. Mobile is yet to be a factor in ad blocking 16. Tables 6. Usage of ad blocking so"ware in Europe growth 17. Tables 7. !e cost of blocking ads 11. Mobile will facilitate future ad blocking growth 12. Reasons to start using an ad blocker PAGEFAIR AND ADOBE | 2015 Ad Blocking Report 2 Key Insights More consumers block ads, continuing the strong growth rates seen during 2013 and 2014. 41% YoY global growth Q2 2014 - Q2 2015 !e "ndings • Globally, the number of people using ad blocking so"ware grew by 41% year over year. • 16% of the US online population blocked ads during Q2 2015. • Ad block usage in the United States grew 48% during the past year, increasing to 45 million monthly active 45 million users (MAUs) during Q2 2015. Average MAUs in the United • Ad block usage in Europe grew by 35% during the past year, increasing to 77 million monthly active users States Q2 2015 during Q2 2015. -

The Impact of Ad-Blockers on Online Consumer Behavior
Marketing Science Institute Working Paper Series 2021 Report No. 21-119 The Impact of Ad-blockers on Online Consumer Behavior Vilma Todri “The Impact of Ad-blockers on Online Consumer Behavior” © 2021 Vilma Todri MSI Working Papers are Distributed for the benefit of MSI corporate and academic members and the general public. Reports are not to be reproduced or published in any form or by any means, electronic or mechanical, without written permission. Marketing Science Institute Working Paper Series The Impact of Ad-blockers on Online Consumer Behavior Vilma Todri Goizueta Business School, Emory University, Atlanta, GA 30322 [email protected] Digital advertising is on track to become the dominant form of advertising but ad-blocking technologies have recently emerged posing a potential threat to the online advertising ecosystem. A significant and increasing fraction of Internet users has indeed already started employing ad-blockers. However, surprisingly little is known yet about the effects of ad-blockers on consumers. This paper investigates the impact of ad- blockers on online search and purchasing behaviors by empirically analyzing a consumer-level panel dataset. Interestingly, the analyses reveal that ad-blockers have a significant effect on online purchasing behavior: online consumer spending decreases due to ad-blockers by approximately $14:2 billion a year in total. In examining the underlying mechanism of the ad-blocker effects, I find that ad-blockers significantly decrease spending for brands consumers have not experienced before, partially shifting spending towards brands they have experienced in the past. I also find that ad-blockers spur additional unintended consequences as they reduce consumers' search activities across information channels. -

Will Ad Blocking Break the Internet?
NBER WORKING PAPER SERIES WILL AD BLOCKING BREAK THE INTERNET? Ben Shiller Joel Waldfogel Johnny Ryan Working Paper 23058 http://www.nber.org/papers/w23058 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 January 2017 Johnny Ryan is an employee of PageFair, a firm that measures the extent of ad blocking and offers ad-recovery technologies that enable publishers to display ads in a manner that adblockers cannot block. Neither Shiller nor Waldfogel has received any compensation for the research in the paper. PageFair was allowed to review the paper for accuracy but did not have control over the paper's findings nor conclusions. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. NBER working papers are circulated for discussion and comment purposes. They have not been peer-reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2017 by Ben Shiller, Joel Waldfogel, and Johnny Ryan. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source. Will Ad Blocking Break the Internet? Ben Shiller, Joel Waldfogel, and Johnny Ryan NBER Working Paper No. 23058 January 2017 JEL No. L81,L82 ABSTRACT Ad blockers allow Internet users to obtain information without generating ad revenue for site owners; and by 2016 they were used by roughly a quarter of site visitors. Given the ad-supported nature of much of the web, ad blocking poses a threat to site revenue and, if revenue losses undermine investment, a possible threat to consumers' access to appealing content. -

What Are Kernel-Mode Rootkits?
www.it-ebooks.info Hacking Exposed™ Malware & Rootkits Reviews “Accessible but not dumbed-down, this latest addition to the Hacking Exposed series is a stellar example of why this series remains one of the best-selling security franchises out there. System administrators and Average Joe computer users alike need to come to grips with the sophistication and stealth of modern malware, and this book calmly and clearly explains the threat.” —Brian Krebs, Reporter for The Washington Post and author of the Security Fix Blog “A harrowing guide to where the bad guys hide, and how you can find them.” —Dan Kaminsky, Director of Penetration Testing, IOActive, Inc. “The authors tackle malware, a deep and diverse issue in computer security, with common terms and relevant examples. Malware is a cold deadly tool in hacking; the authors address it openly, showing its capabilities with direct technical insight. The result is a good read that moves quickly, filling in the gaps even for the knowledgeable reader.” —Christopher Jordan, VP, Threat Intelligence, McAfee; Principal Investigator to DHS Botnet Research “Remember the end-of-semester review sessions where the instructor would go over everything from the whole term in just enough detail so you would understand all the key points, but also leave you with enough references to dig deeper where you wanted? Hacking Exposed Malware & Rootkits resembles this! A top-notch reference for novices and security professionals alike, this book provides just enough detail to explain the topics being presented, but not too much to dissuade those new to security.” —LTC Ron Dodge, U.S. -

Understanding Ad Blockers
Understanding Ad Blockers A Major Qualifying Project Submitted to the Faculty of Worcester Polytechnic Institute In partial fulfillment of the requirements for the Degree of Bachelor of Science In Computer Science By _________________________________ Doruk Uzunoglu March 21, 2016 _______________________ Professor Craig E. Wills, Project Advisor Professor and Department Head Department of Computer Science ABSTRACT This project aims to provide useful information for users and researchers who would like to learn more about ad blocking. Three main research areas are explored in this project. The first research area provides general information about ad blocking tools and aims to explore ad blockers from a user’s perspective. The second research area provides analyses regarding thirdparty sites that appear on popular firstparty sites in order to explore the behavior of thirdparties. Finally, the third research area provides analyses regarding filter lists, which are sets of ad filtering rules used by ad blocking tools. The third research area aims to convey the differences and similarities between individual filter lists as well as sets of filter lists that form the defaults of ad blocking tools. 1 ACKNOWLEDGEMENTS I would like to thank Professor Craig Wills for advising my project, providing insight, and gathering the popular thirdparty domains data which I analyzed as part of this project. In addition, I would like to thank Jinyan Zang for sharing the thirdparty data regarding mobile apps, which they have gathered as part of their 2015 paper named “Who Knows What About Me? A Survey of Behind the Scenes Personal Data Sharing to Third Parties by Mobile Apps.” The data provided by Jinyan Zang was also analyzed as part of this project. -

Snowwall: a Visual Firewall for the Surveillance Society
Imperial College London Department of Computing SnowWall: A Visual Firewall for the Surveillance society Madalina-Ioana Sas [email protected] June 2017 Supervised by Dr. William J. Knottenbelt Submitted in part fulfillment of the requirements for the degree of Master of Engineering in Computing of Imperial College London. 2 Abstract In the past two decades we have seen a steady increase in the adoption of various technologies that fit into what can be described as a digital lifestyle. Sharing data, experiences and our most intimate thoughts has become second nature to most people connected to the Internet. And as market trends shift so did the approach that companies and governments have in regards to each individual's digital footprint. The uncharted wild west that used to be the internet of yesteryear has become a battleground where everyone is fighting over who knows the user better. Findings such as the Snowden and the Vault7 leaks have deeply shaken the status quo in privacy. This project revolves around giving the end user back insight and control over what they involuntarily share with the world. We present SnowWall: a networking tool designed to provide insights and control into the networking activity on a Windows-based system. SnowWall interacts with the operating system, intercepts every inbound and outbound connection, provides information on the connection's state, lifetime, owning process, and most importantly, remote end point, such as geolocation and ownership information. SnowWall is a powerful tool designed to be user-friendly, which allows anyone to block unwanted connections with high-level firewall rules, such as blocking by country or by owning organization name. -
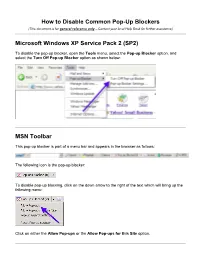
How to Disable Common Pop-Up Blockers Microsoft Windows XP
How to Disable Common Pop-Up Blockers (This document is for general reference only – Contact your local Help Desk for further assistance) Microsoft Windows XP Service Pack 2 (SP2) To disable the pop-up blocker, open the Tools menu, select the Pop-up Blocker option, and select the Turn Off Pop-up Blocker option as shown below: MSN Toolbar This pop-up blocker is part of a menu bar and appears in the browser as follows: The following icon is the pop-up blocker: To disable pop-up blocking, click on the down arrow to the right of the text which will bring up the following menu: Click on either the Allow Pop-ups or the Allow Pop-ups for this Site option. Google Toolbar The following icon is the pop-up blocker: To allow pop-ups to appear, merely click on the icon. You should now see the following: Yahoo! Toolbar The following icon is the pop-up blocker: To disable pop-up blocking, click on the down arrow beside the icon to bring up its menu, as follows: Click on the Enable Pop-Up Blocker option to remove the checkmark beside it, disabling the pop-up blocking. AOL Toolbar The following icon is the pop-up blocker: To allow pop-ups to appear, merely click on the icon. You should now see the following: Mozilla Firefox Open the Tools menu and click on Options. The following window will appear: Select the Content icon. Remove the checkmark from beside the Block pop-up windows option. Click OK to close the window. -

Consumer Views Regarding Ad Blocking Technology
Consumer Views Regarding Ad Blocking Technology March 2016 FPF research in collaboration with comScore Table of Contents Purpose/Research Objectives/ Approach/Reporting Notes 3 Executive Summary 4 General Views Toward Online Ads 8 Protecting Oneself Online 13 Ad Blocking Software 20 Additional Online Protection 30 General Views Toward Advertising 36 Appendix 39 2 Purpose, Research Objectives, Approach, Reporting Notes Purpose . Better understand consumers’ general online and privacy habits among Ad Blocker users. Better understand consumers’ views of advertising and online targeted advertising. Research . Better understand what motivates consumers to protect themselves online and the actions to do so. Examine attitudes and motivations of using Ad Blocker software. Objectives . Examine what a web site may be able to do to improve visitors’ trust in their collection, management, and use of personal data. Participants were recruited via email from the comScore Online Research Panel. A one-day (24-hour) FocusSite discussions were held February 23, 2016. A FocusSite is a threaded online discussion which allows participants to engage in a moderated discussion over the course of the day. Approach . 57 people participated in the discussion. All participants were 18+, own a PC and mobile device, are frequent internet users, and took action to protect themselves online including using an Ad Blocker. Participants committed to participate at least 90 minutes over the course of the day, returning to the discussion as new questions, probes, and other participant comments were added throughout the day. All participants reside in the USA and received $50 as an incentive for participation. Reporting . Throughout this report, participants’ comments are presented verbatim. -

War on Digital Advertising
October 1, 2015 QUICK NEWS Man Watches Burglars WAR ON DIGITAL ADVERTISING Rob His Apartment From His Phone Ad-blocks are created to prevent ads from showing up on desktops and mobile devices, which reduces screen clutter and increases loading speed. Facebook Debuts Ad- The most popular ad-blocking program is Adblock Plus, which is an open- Buying Product to Get Into More TV-Minded Budgets source content-filtering and ad blocking extension of Mozilla Firefox, Google Chrome, Internet Explorer, Opera, Safari, and Yandex Browser. Nielsen Strikes a Digital The founder of Adblock Plus, Till Faida, believes that “ad-blocking Ratings Deal with CBS to Better Measure Viewership technology puts power back into users’ hands and the advertising world needs to respond by working out how to get its messages across without 4 Ways Spotify and being annoying and intrusive.” Pandora Target Millennials Differently Ad-blocking has been on the rise with 45MM U.S. internet users using ad-blocking software, that’s 16% of all U.S. Internet users, and the vast majority using plug-ins for either Google Chrome or Mozilla Firefox. Ad-blocking software are most popular with younger users – 41% of all WHAT’S U.S. Internet users using ad-block are between A18-29. TRENDING NOW? APPS: Purify Blocker Tweetbot 4 HASHTAGS: #WorldVegetarianDay #Halloween UPCOMING EVENTS: § ITEXPO West Anaheim, CA Ad-blockers have been a largely desktop-only phenomenon until Apple October 6 – 8, 2015 revealed that the new iOS9 will be able to support ad-blockers, meaning § QCon mobile ad-blockers are expected to soon be commonplace. -

Annoyed Users: Ads and Ad-Block Usage in the Wild
Annoyed Users: Ads and Ad-Block Usage in the Wild Enric Pujol Oliver Hohlfeld Anja Feldmann TU Berlin RWTH Aachen TU Berlin [email protected] [email protected] [email protected] ABSTRACT The history of this business model goes back to the first click- Content and services which are offered for free on the Internet are able Web ads, which emerged around 1993 with the first commer- primarily monetized through online advertisement. This business cial Web sites. HotWired was among the first to sell banner ads to model relies on the implicit agreement between content providers companies such as AT&T and Coors. The first central ad servers and users where viewing ads is the price for the “free” content. emerged in 1995 to enable the management, targeting, and track- This status quo is not acceptable to all users, however, as mani- ing of users and online ads. This started the proliferation of Web fested by the rise of ad-blocking plugins which are available for ads, which brought with it an increasingly complex infrastructure all popular Web browsers. Indeed, ad-blockers have the potential to serve these advertisements. DoubleClick introduced the process to substantially disrupt the widely established business model of of online behavioral advertising in the late 1990s which used 3rd “free” content—currently one of the core elements on which the party cookies to track users across sites and present ads based on the Web is built. users’ browsing patterns. Today, online advertisement has become In this work, we shed light on how users interact with ads. -

The Legal Fate of Internet Ad-Blocking
Washington and Lee University School of Law Washington & Lee University School of Law Scholarly Commons Scholarly Articles Faculty Scholarship 2018 The Legal Fate of Internet Ad-Blocking Russell A. Miller Washington and Lee University School of Law, [email protected] Follow this and additional works at: https://scholarlycommons.law.wlu.edu/wlufac Part of the Comparative and Foreign Law Commons, Computer Law Commons, and the Litigation Commons Recommended Citation Russell A. Miller, The Legal Fate of Internet Ad-Blocking, 24 B.U. J. Sci. & Tech. L. 299 (2018). This Article is brought to you for free and open access by the Faculty Scholarship at Washington & Lee University School of Law Scholarly Commons. It has been accepted for inclusion in Scholarly Articles by an authorized administrator of Washington & Lee University School of Law Scholarly Commons. For more information, please contact [email protected]. ARTICLE THE LEGAL FATE OF INTERNET AD-BLOCKING RUSSELL A. MILLER* ABSTRACT Ad-blocking services allow individual users to avoid the obtrusive advertising that both clutters and finances most Internet publishing. Ad-blocking's im- mense-and growing-popularity suggests the depth of Internet users'frustra- tion with Internetadvertising. But its potential to disruptpublishers' traditional Internet revenue model makes ad-blocking one of the most significant recent Internetphenomena. Unsurprisingly,publishers are not inclined to accept ad- blocking without a legal fight. While publishers are threatening suits in the United States, the issues presented by ad-blocking have been extensively liti- gated in German courts where ad-blocking consistently has triumphed over claims that it represents a form of unfair competition. -

Detecting Anti Ad-Blockers in the Wild
Proceedings on Privacy Enhancing Technologies ..; .. (..):1–16 Muhammad Haris Mughees, Zhiyun Qian, and Zubair Shafiq Detecting Anti Ad-blockers in the Wild Abstract: The rise of ad-blockers is viewed as an eco- vices. Unfortunately, the economic magnetism of online nomic threat by online publishers who primarily rely on advertising has made it an attractive target for various online advertising to monetize their services. To address types of abuses. First, the online advertising ecosystem this threat, publishers have started to retaliate by em- incentivizes the widespread tracking of users across web- ploying anti ad-blockers, which scout for ad-block users sites raising privacy [25] and surveillance [34] concerns. and react to them by pushing users to whitelist the web- To show targeted ads to users, advertisers track users site or disable ad-blockers altogether. The clash between across the web using cookies, beacons, and fingerprint- ad-blockers and anti ad-blockers has resulted in a new ing [22]. Second, the online advertising ecosystem not arms race on the Web. In this paper, we present an auto- only lacks transparency but also does not provide any mated machine learning based approach to identify anti meaningful control for users to limit tracking and the ad-blockers that detect and react to ad-block users. The use of personal information. Third, hackers are increas- approach is promising with precision of 94.8% and recall ingly launching malvertising campaigns, where they use of 93.1%. Our automated approach allows us to conduct online advertising to target malware at a large number a large-scale measurement study of anti ad-blockers on of users [41].