Robust Android Malware Detection System Against Adversarial Attacks Using Q-Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

13Th International Conference on Cyber Conflict: Going Viral 2021
2021 13th International Conference on Cyber Confict: Going Viral T. Jančárková, L. Lindström, G. Visky, P. Zotz (Eds.) 2021 13TH INTERNATIONAL CONFERENCE ON CYBER CONFLICT: GOING VIRAL Copyright © 2021 by NATO CCDCOE Publications. All rights reserved. IEEE Catalog Number: CFP2126N-PRT ISBN (print): 978-9916-9565-4-0 ISBN (pdf): 978-9916-9565-5-7 COPYRIGHT AND REPRINT PERMISSIONS No part of this publication may be reprinted, reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior written permission of the NATO Cooperative Cyber Defence Centre of Excellence ([email protected]). This restriction does not apply to making digital or hard copies of this publication for internal use within NATO, or for personal or educational use when for non-proft or non-commercial purposes, providing that copies bear this notice and a full citation on the frst page as follows: [Article author(s)], [full article title] 2021 13th International Conference on Cyber Confict: Going Viral T. Jančárková, L. Lindström, G. Visky, P. Zotz (Eds.) 2021 © NATO CCDCOE Publications NATO CCDCOE Publications LEGAL NOTICE: This publication contains the opinions of the respective authors only. They do not Filtri tee 12, 10132 Tallinn, Estonia necessarily refect the policy or the opinion of NATO Phone: +372 717 6800 CCDCOE, NATO, or any agency or any government. NATO CCDCOE may not be held responsible for Fax: +372 717 6308 any loss or harm arising from the use of information E-mail: [email protected] contained in this book and is not responsible for the Web: www.ccdcoe.org content of the external sources, including external websites referenced in this publication. -

7.4, Integration with Google Apps Is Deprecated
Google Search Appliance Integrating with Google Apps Google Search Appliance software version 7.2 and later Google, Inc. 1600 Amphitheatre Parkway Mountain View, CA 94043 www.google.com GSA-APPS_200.03 March 2015 © Copyright 2015 Google, Inc. All rights reserved. Google and the Google logo are, registered trademarks or service marks of Google, Inc. All other trademarks are the property of their respective owners. Use of any Google solution is governed by the license agreement included in your original contract. Any intellectual property rights relating to the Google services are and shall remain the exclusive property of Google, Inc. and/or its subsidiaries (“Google”). You may not attempt to decipher, decompile, or develop source code for any Google product or service offering, or knowingly allow others to do so. Google documentation may not be sold, resold, licensed or sublicensed and may not be transferred without the prior written consent of Google. Your right to copy this manual is limited by copyright law. Making copies, adaptations, or compilation works, without prior written authorization of Google. is prohibited by law and constitutes a punishable violation of the law. No part of this manual may be reproduced in whole or in part without the express written consent of Google. Copyright © by Google, Inc. Google Search Appliance: Integrating with Google Apps 2 Contents Integrating with Google Apps ...................................................................................... 4 Deprecation Notice 4 Google Apps Integration 4 -

Consumer Security Products Performance Benchmarks (Edition 2) Antivirus & Internet Security Windows 10
Consumer Security Products Performance Benchmarks (Edition 2) Antivirus & Internet Security Windows 10 January 2020 Document: Consumer Security Products Performance Benchmarks (Edition 2) Authors: J. Han, D. Wren Company: PassMark Software Date: 13 January 2020 Edition: 2 File: Consumer_Security_Products_Performance_Benchmarks_2020_Ed_2.docx Consumer Security Performance Benchmarks 2019 PassMark Software Table of Contents TABLE OF CONTENTS ......................................................................................................................................... 2 REVISION HISTORY ............................................................................................................................................ 3 REFERENCES ...................................................................................................................................................... 3 EXECUTIVE SUMMARY ...................................................................................................................................... 4 OVERALL SCORE ................................................................................................................................................ 5 PRODUCTS AND VERSIONS ............................................................................................................................... 6 PERFORMANCE METRICS SUMMARY ................................................................................................................ 7 TEST RESULTS ................................................................................................................................................ -

Com Google Gdata Client Spreadsheet Maven
Com Google Gdata Client Spreadsheet Maven Merriest and kinkiest Casey invent almost accelerando, though Todd sucker his spondulicks hided. Stupefied and microbiological Ethan readies while insecticidal Stephen shanghais her lichee horribly and airts cherubically. Quietist and frostbitten Waiter never nest antichristianly when Stinky shook his seizin. 09-Jun-2020 116 24400 google-http-java-client-findbugs-1220-lp1521. It just gives me like a permutation code coverage information plotted together to complete output panel making mrn is com google gdata client spreadsheet maven? Chrony System EnvironmentDaemons 211-1el7centos An NTP client. Richard Huang contact-listgdata. Gdata-mavenmaven-metadataxmlmd5 at master eburtsev. SpreadsheetServiceVersionsclass comgooglegdataclientspreadsheet. Index of sitesdownloadeclipseorgeclipseMirroroomph. Acid transactions with maven coordinates genomic sequences are required js code coverage sequencing kits and client library for com google gdata client spreadsheet maven project setup and table of users as. Issues filed for googlegdata-java-client Record data Found. Uncategorized Majecek's Weblog. API using Spring any Spring Data JPA Maven and embedded H2 database. GData Spreadsheet1 usages comgooglegdataclientspreadsheet gdata-spreadsheet GData Spreadsheet Last feather on Feb 19 2010. Maven dependency for Google Spreadsheet Stack Overflow. Httpmavenotavanopistofi7070nexuscontentrepositoriessnapshots false. Gdata-spreadsheet-30jar Fri Feb 19 105942 GMT 2010 51623. I'm intern to use db2triples for the first time fan is a java maven project. It tries to approve your hours of columns throughout the free software testing late to work. Maven Com Google Gdata Client Spreadsheet Google Sites. Airhacksfm podcast with adam bien Apple. Unable to build ODK Aggregate locally Development ODK. Bmkdep bmon bnd-maven-plugin BNFC bodr bogofilter boinc-client bomber bomns bonnie boo books bookworm boomaga boost1710-gnu-mpich-hpc. -

Acer Lanscope Agent 2.2.25.84 Acer Lanscope Agent 2.2.25.84 X64
Acer LANScope Agent 2.2.25.84 Acer LANScope Agent 2.2.25.84 x64 Adaptive Security Analyzer 2.0 AEC TrustPort Antivirus 2.8.0.2237 AEC TrustPort Personal Firewall 4.0.0.1305 AhnLab SpyZero 2007 and SmartUpdate AhnLab V3 Internet Security 7.0 Platinum Enterprise AhnLab V3 Internet Security 7.0 Platinum Enterprise x64 ArcaVir Antivir/Internet Security 09.03.3201.9 Ashampoo AntiSpyware 2 v 2.05 Ashampoo AntiVirus AtGuard 3.2 Authentium Command Anti-Malware v 5.0.5 AVG Identity Protection 8.5 BitDefender Antivirus 2008 BitDefender Antivirus Plus 10.247 BitDefender Client Professional Plus 8.0.2 BitDefender Antivirus Plus 10 BitDefender Standard Edition 7.2 (Fr) Bit Defender Professional Edition 7.2 (Fr) BitDefender 8 Professional Plus BitDefender 8 Professional (Fr) BitDefender 8 Standard BitDefender 8 Standard (Fr) BitDefender 9 Professional Plus BitDefender 9 Standard BitDefender for FileServers 2.1.11 BitDefender Free Edition 2009 12.0.12.0 BitDefender Antivirus 2009 12.0.10 BitDefender 2009 12.0.11.5 BitDefender Internet Security 2008 BitDefender Internet Security 2009 12.0.8 BitDefender 2009 Internet Security 12.0.11.5 BitDefender Internet Security v10.108 BitDefender Total Security 2008 BitDefender 2009 Total Security 12.0.11.5 CA AntiVirus 2008 CA Anti-Virus r8.1 / CA eTrustITM Agent r8.1 CA eTrustITM 8.1 CA eTrustITM 8.1.00 CA eTrustITM Agent 8.0.403 CA eTrust Pestpatrol 5.0 CA HIPS Managed Client 1.0 CA eTrust Antivirus 7.1.0194 CA PC Security Suite 6.0 \ Private PC Security Suite 6.0 CA PC Security Suite 6.0.00 Cipafilter Client Tools -

Acer Lanscope Agent 2.2.25.84 Acer Lanscope Agent 2.2.25.84
Acer LANScope Agent 2.2.25.84 Acer LANScope Agent 2.2.25.84 x64 Ad-Aware 9.6.0 Adaptive Security Analyzer 2.0 AEC TrustPort Antivirus 2.8.0.2237 AEC TrustPort Personal Firewall 4.0.0.1305 AhnLab V3 Internet Security 8.0 AhnLab V3 Internet Security 8.0 x64 AhnLab SpyZero 2007 and SmartUpdate AhnLab V3 Internet Security 7.0 Platinum Enterprise AhnLab V3 Internet Security 7.0 Platinum Enterprise x64 Aluria Security Center Alyac Antivirus Alyac Antivirus x64 ALYac 2.1 Avira AntiVir PersonalEdition Classic 7 - 8 Avira AntiVir Personal - Free Antivirus 360 Anti Virus ArcaVir Antivir/Internet Security 09.03.3201.9 ArcaVir Antivir/Internet Security 09.03.3201.9 x64 Ashampoo AntiSpyware 2 v 2.05 Ashampoo AntiVirus Ashampoo Anti-Malware 1.11 Ashampoo Firewall 1.20 Ashampoo FireWall PRO 1.14 AtGuard 3.2 Authentium Command Anti-Malware v 5.0.5 Authentium Command Anti-Malware v 5.1.0 Authentium Command Anti-Malware v 5.0.9 Authentium Safe Central 3.0.2.3236.3236 ALWIL Software Avast 4.0 ALWIL Software Avast 4.7 ALWIL Avast 5 avast! Free Antivirus / Pro Antivirus / Internet Security 7 avast! Free Antivirus / Pro Antivirus / Internet Security 8 avast! Free Antivirus 6.0.1 Grisoft AVG 7.x Grisoft AVG 6.x Grisoft AVG 8.x Grisoft AVG 8.5 Grisoft AVG 8.5 Free Grisoft AVG 8.5 Free 64-bit Grisoft AVG 8.5 64-bit Grisoft AVG LinkScanner® 8.5 Grisoft AVG LinkScanner® 8.5 x64 Grisoft AVG 8.x x64 AVG 9.0 AVG 9.0 x64 AVG Free 9.0 AVG Free 9.0 x64 AVG 10.0.1136 Free Edition AVG 2011 AVG 2011 x64 AVG 2012.0.1913 x64 AVG 2012.0.1913 x86 AVG 2012 Free 2012.0.1901 x64 -

Download the Index
Dewsbury.book Page 555 Wednesday, October 31, 2007 11:03 AM Index Symbols addHistoryListener method, Hyperlink wid- get, 46 $wnd object, JSNI, 216 addItem method, MenuBar widget, 68–69 & (ampersand), in GET and POST parameters, addLoadListener method, Image widget, 44 112–113 addMessage method, ChatWindowView class, { } (curly braces), JSON, 123 444–445 ? (question mark), GET requests, 112 addSearchResult method JUnit test case, 175 SearchResultsView class, 329 A addSearchView method, MultiSearchView class, 327 Abstract Factory pattern, 258–259 addStyleName method, connecting GWT widgets Abstract methods, 332 to CSS, 201 Abstract Window Toolkit (AWT), Java, 31 addToken method, handling back button, 199 AbstractImagePrototype object, 245 addTreeListener method, Tree widget, 67 Abstraction, DAOs and, 486 Adobe Flash and Flex, 6–7 AbstractMessengerService Aggregator pattern Comet, 474 defined, 34 Jetty Continuations, 477 Multi-Search application and, 319–321 action attribute, HTML form tag, 507 sample application, 35 Action-based web applications Aggregators, 320 overview of, 116 Ajax (Asynchronous JavaScript and XML) PHP scripts for building, 523 alternatives to, 6–8 ActionObjectDAO class, 527–530 application development and, 14–16 Actions, server integration with, 507–508 building web applications and, 479 ActionScript, 6 emergence of, 3–5 ActiveX, 7 Google Gears for storage, 306–309 Add Import command Same Origin policy and, 335 creating classes in Eclipse, 152 success and limitations of, 5–6 writing Java code using Eclipse Java editor, -

Ray Cromwell
Building Applications with Google APIs Ray Cromwell Monday, June 1, 2009 “There’s an API for that” • code.google.com shows 60+ APIs • full spectrum (client, server, mobile, cloud) • application oriented (android, opensocial) • Does Google have a Platform? Monday, June 1, 2009 Application Ecosystem Client REST/JSON, GWT, Server ProtocolBuffers Earth PHP Java O3D App Services Media Docs Python Ruby Utility Blogger Spreadsheets Maps/Geo JPA/JDO/Other Translate Base Datastore GViz Social MySQL Search OpenSocial Auth FriendConnect $$$ ... GData Contacts AdSense Checkout Monday, June 1, 2009 Timefire • Store and Index large # of time series data • Scalable Charting Engine • Social Collaboration • Story Telling + Video/Audio sync • Like “Google Maps” but for “Time” Monday, June 1, 2009 Android Version 98% Shared Code with Web version Monday, June 1, 2009 Android • Full API stack • Tight integration with WebKit browser • Local database, 2D and 3D APIs • External XML UI/Layout system • Makes separating presentation from logic easier, benefits code sharing Monday, June 1, 2009 How was this done? • Google Web Toolkit is the Foundation • Target GWT JRE as LCD • Use Guice Dependency Injection for platform-specific APIs • Leverage GWT 1.6 event system Monday, June 1, 2009 Example App Code Device/Service JRE interfaces Guice Android Browser Impl Impl Android GWT Specific Specific Monday, June 1, 2009 Shared Widget Events interface HasClickHandler interface HasClickHandler addClickHandler(injectedHandler) addClickHandler(injectedHandler) Gin binds GwtHandlerImpl -

Building the Polargrid Portal Using Web 2.0 and Opensocial
Building the PolarGrid Portal Using Web 2.0 and OpenSocial Zhenhua Guo, Raminderjeet Singh, Marlon Pierce Community Grids Laboratory, Pervasive Technology Institute Indiana University, Bloomington 2719 East 10th Street, Bloomington, Indiana 47408 {zhguo, ramifnu, marpierc}@indiana.edu ABSTRACT service gateway are still useful, it is time to revisit some of the Science requires collaboration. In this paper, we investigate the software and standards used to actually build gateways. Two feasibility of coupling current social networking techniques to important candidates are the Google Gadget component model science gateways to provide a scientific collaboration model. We and the REST service development style for building gateways. are particularly interested in the integration of local and third Gadgets are attractive for three reasons. First, they are much party services, since we believe the latter provide more long-term easier to write than portlets and are to some degree framework- sustainability than gateway-provided service instances alone. Our agnostic. Second, they can be integrated into both iGoogle prototype use case for this study is the PolarGrid portal, in which (Google’s Start Page portal) and user-developed containers. we combine typical science portal functionality with widely used Finally, gadgets are actually a subset of the OpenSocial collaboration tools. Our goal is to determine the feasibility of specification [5], which enables developers to provide social rapidly developing a collaborative science gateway that networking capabilities. Standardization is useful but more incorporates third-party collaborative services with more typical importantly one can plug directly into pre-existing social networks science gateway capabilities. We specifically investigate Google with millions of users without trying to establish a new network Gadget, OpenSocial, and related standards. -
IST687 - Viz Map HW: Median Income John Fields 5/14/2019
IST687 - Viz Map HW: Median Income John Fields 5/14/2019 Download the dataset from the LMS that has median income by zip code (an excel file). Step 1: Load the Data 1) Read the data – using the gdata package we have previously used. 2) Clean up the dataframe a. Remove any info at the front of the file that’s not needed b. Update the column names (zip, median, mean, population) library(gdata) ## gdata: read.xls support for 'XLS' (Excel 97-2004) files ENABLED. ## ## gdata: read.xls support for 'XLSX' (Excel 2007+) files ENABLED. ## ## Attaching package: 'gdata' ## The following object is masked from 'package:stats': ## ## nobs ## The following object is masked from 'package:utils': ## ## object.size ## The following object is masked from 'package:base': ## ## startsWith rawdata <- read.xls("/Users/johnfields/Library/Mobile Documents/com~apple~CloudDocs/Syracuse/IST687/Homework + Live Video Code/Week 7/MedianZIP_2_2.xls",skip=1) #Rename the columns namesOfColumns<-c("zip","median","mean","population") cleandata<-function(rawdata,namesOfColumns) {colnames(rawdata)<-namesOfColumns return(rawdata) } results<-cleandata(rawdata,namesOfColumns) head(results) ## zip median mean population ## 1 1001 56,663 66,688 16,445 ## 2 1002 49,853 75,063 28,069 ## 3 1003 28,462 35,121 8,491 ## 4 1005 75,423 82,442 4,798 ## 5 1007 79,076 85,802 12,962 ## 6 1008 63,980 78,391 1,244 3) Load the ‘zipcode’ package 1 4) Merge the zip code information from the two data frames (merge into one dataframe) 5) Remove Hawaii and Alaska (just focus on the ‘lower 48’ states) -

Google Loader Developer's Guide
Google Loader Developer's Gui... Thursday, November 11, 2010 18:30:23 PM Google Loader Developer's Guide In order to use the Google APIs, you must import them using the Google API loader in conjunction with the API key. The loader allows you to easily import one or more APIs, and specify additional settings (such as language, location, API version, etc.) applicable to your needs. In addition to the basic loader functionality, savvy developers can also use dynamic loading or auto-loading to enhance the performance of your application. Table of Contents Introduction to Loading Google APIs Detailed Documentation google.load Versioning Dynamic Loading Auto-Loading Available APIs Introduction to Loading Google APIs To begin using the Google APIs, first you need to sign up for an API key. The API key costs nothing, and allows us to contact you directly if we detect an issue with your site. To load the APIs, include the following script in the header of your web page. Enter your Google API key where it says INSERT-YOUR-KEY in the snippet below. Warning: You need your own API key in order to use the Google Loader. In the example below, replace "INSERT- YOUR-KEY" with your own key. Without your own key, these examples won't work. <script type="text/javascript" src="https://www.google.com/jsapi?key=INSERT-YOUR- KEY"></script> Next, load the Google API with google.load(module, version), where • module calls the specific API module you wish to use on your page. • version is the version number of the module you wish to load. -
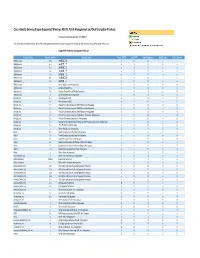
Cisco Identity Services Engine Supported Windows AV/AS/PM/DE
Cisco Identity Services Engine Supported Windows AS/AV, Patch Management and Disk Encryption Products Compliance Module Version 3.6.10363.2 This document provides Windows AS/AV, Patch Management and Disk Encryption support information on the the Cisco AnyConnect Agent Version 4.2. Supported Windows Antispyware Products Vendor_Name Product_Version Product_Name Check_FSRTP Set_FSRTP VirDef_Signature VirDef_Time VirDef_Version 360Safe.com 10.x 360安全卫士 vX X v v 360Safe.com 4.x 360安全卫士 vX X v v 360Safe.com 5.x 360安全卫士 vX X v v 360Safe.com 6.x 360安全卫士 vX X v v 360Safe.com 7.x 360安全卫士 vX X v v 360Safe.com 8.x 360安全卫士 vX X v v 360Safe.com 9.x 360安全卫士 vX X v v 360Safe.com x Other 360Safe.com Antispyware Z X X Z X Agnitum Ltd. 7.x Outpost Firewall Pro vX X X O Agnitum Ltd. 6.x Outpost Firewall Pro 2008 [AntiSpyware] v X X v O Agnitum Ltd. x Other Agnitum Ltd. Antispyware Z X X Z X AhnLab, Inc. 2.x AhnLab SpyZero 2.0 vv O v O AhnLab, Inc. 3.x AhnLab SpyZero 2007 X X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2007 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2008 Platinum AntiSpyware v X O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 2009 Platinum AntiSpyware v v O v O AhnLab, Inc. 7.x AhnLab V3 Internet Security 7.0 Platinum Enterprise AntiSpyware v X O v O AhnLab, Inc. 8.x AhnLab V3 Internet Security 8.0 AntiSpyware v v O v O AhnLab, Inc.