A Novel Approach for Untargeted Post-Translational Modification Identification Using Integer Linear Optimization and Tandem Mass Spectrometry*□S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Table S1. List of Proteins in the BAHD1 Interactome
Table S1. List of proteins in the BAHD1 interactome BAHD1 nuclear partners found in this work yeast two-hybrid screen Name Description Function Reference (a) Chromatin adapters HP1α (CBX5) chromobox homolog 5 (HP1 alpha) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins (20-23) HP1β (CBX1) chromobox homolog 1 (HP1 beta) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins HP1γ (CBX3) chromobox homolog 3 (HP1 gamma) Binds histone H3 methylated on lysine 9 and chromatin-associated proteins MBD1 methyl-CpG binding domain protein 1 Binds methylated CpG dinucleotide and chromatin-associated proteins (22, 24-26) Chromatin modification enzymes CHD1 chromodomain helicase DNA binding protein 1 ATP-dependent chromatin remodeling activity (27-28) HDAC5 histone deacetylase 5 Histone deacetylase activity (23,29,30) SETDB1 (ESET;KMT1E) SET domain, bifurcated 1 Histone-lysine N-methyltransferase activity (31-34) Transcription factors GTF3C2 general transcription factor IIIC, polypeptide 2, beta 110kDa Required for RNA polymerase III-mediated transcription HEYL (Hey3) hairy/enhancer-of-split related with YRPW motif-like DNA-binding transcription factor with basic helix-loop-helix domain (35) KLF10 (TIEG1) Kruppel-like factor 10 DNA-binding transcription factor with C2H2 zinc finger domain (36) NR2F1 (COUP-TFI) nuclear receptor subfamily 2, group F, member 1 DNA-binding transcription factor with C4 type zinc finger domain (ligand-regulated) (36) PEG3 paternally expressed 3 DNA-binding transcription factor with -

Inactive USP14 and Inactive UCHL5 Cause Accumulation of Distinct Ubiquitinated Proteins In
bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Inactive USP14 and inactive UCHL5 cause accumulation of distinct ubiquitinated proteins in mammalian cells Jayashree Chadchankar, Victoria Korboukh, Peter Doig, Steve J. Jacobsen, Nicholas J. Brandon, Stephen J. Moss, Qi Wang AstraZeneca Tufts Laboratory for Basic and Translational Neuroscience, Tufts University, Boston, MA (J.C., S.J.M.) Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA (S.J.J., N.J.B., Q.W.) Discovery Sciences, IMED Biotech Unit, AstraZeneca, Boston, MA (V.K., P.D.) Department of Neuroscience, Tufts University School of Medicine, Boston, MA (S.J.M.) Department of Neuroscience, Physiology and Pharmacology, University College, London, WC1E, 6BT, UK (S.J.M.) 1 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Running title: Effects of inactive USP14 and UCHL5 in mammalian cells Keywords: USP14, UCHL5, deubiquitinase, proteasome, ubiquitin, β‐catenin Corresponding author: Qi Wang Address: Neuroscience, IMED Biotech Unit, AstraZeneca, Boston, MA 02451 Email address: [email protected] 2 bioRxiv preprint doi: https://doi.org/10.1101/479758; this version posted November 26, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. -

MALDI-TOF/TOF MS Protocols Objectives
MALDI-TOF/TOF MS Protocols Objectives: 1. To be familiar with the basic operation of the MALDI-TOF-TOF mass spectrometer. 2. To use MALDI-TOF-TOF mass spectrometer for peptide mass fingerprinting, peptide sequencing, and in source decay sequencing of intact proteins. Protocols included: 1. Obtaining a peptide mass fingerprint with MALDI-TOF 2. ISD and T3 sequencing 3. In-gel tryptic digest 4. Sample spotting with the dried droplet method 5. Ultraflex III Operation for Obtaining a PMF Introduction: MALDI refers to the ion source, i.e., the Matrix Assists in Laser Desorption/Ionization of the analyte. The matrix, is co-crystallized with the sample, it must absorb light maximally at 337 nm (wavelength of the laser), and must participate in proton transfer with the analyte. TOF refers to the mass analyzer. The mass analyzer separates ions based on their Time Of Flight. Flight time is a function of the mass to charge ratio (m/z) of the analyte. TOF-TOF means that this is a tandem mass spectrometer, so an ion can be selected for, fragmented, and mass analyzed again. Tandem mass spectrometry, MS/MS, can provide additional information for structural elucidation of the analyte in question. The Ultraflex III is a MALDI-TOF-TOF mass spectrometer that will be used in this laboratory (Figure 1). A suite of software is used with this instrument. Acquisition of mass spectra is done in Flex Control, spectrum processing and annotation in Flex Analysis, and additional data processing and data searching is done in BioTools and Sequence Editor (Bruker). 1 Figure 1: Schematic of the Ultraflex III MALDI-TOF-TOF. -

Optimized Search Strategy to Maximize PTM Characterization and Protein Coverage in Proteome Discoverer Software
Application Note 658 Note Application Optimized Search Strategy to Maximize PTM Characterization and Protein Coverage in Proteome Discoverer Software Xiaoyue Jiang1, David Horn1, Michael Blank1, Devin Drew1, Bernard Delanghe2, Rosa Viner1, Andreas FR Huhmer1 1Thermo Fisher Scientific, San Jose, CA, USA; 2Thermo Fisher Scientific, Bremen, Germany Key Words This is probably due to the heterogeneous nature of the Protein coverage, post-translational modification (PTM), Proteome samples (heavily modified or lightly modified), acquisition Discoverer, SEQUEST, Byonic, Mascot, MaxQuant, MS Amanda, FDR methods (acquired at high resolution or low resolution), database searching parameters (mass tolerance, Goal modifications), and search filters (false discovery rate To evaluate several commonly used search algorithms to maximize (FDR)) that were used in those comparisons, all of which peptide/protein identifications and PTM signatures for different types can affect the results of the assessment. of samples. A more standardized approach, in which optimized instrument method and search parameters as well as the search filters included as part of the comparative study, Introduction must be applied so clear conclusions of the search engine New advances in mass spectrometry enable comprehensive comparison can be drawn. characterization and accurate quantitation of complete proteomes. However, complex biological questions can In this study, we evaluated several widely used search only be answered through sophisticated data processing algorithms including SEQUEST, Mascot, Byonic, and using multiple state-of-the-art proteomics search engines. MS Amanda available in Thermo Scientific™ Proteome The list of identified peptides and proteins returned from Discoverer™ 2.0 software, and the Andromeda search such search engines ultimately determines the conclusions engine in MaxQuant™ software on two representative for the whole experiment and thus high confidence in the datasets acquired on high-resolution, accurate mass results is critical. -

Proteomic and Bioinformatic Pipeline to Screen the Ligands of S
www.nature.com/scientificreports OPEN Proteomic and bioinformatic pipeline to screen the ligands of S. pneumoniae interacting Received: 15 September 2017 Accepted: 14 March 2018 with human brain microvascular Published: xx xx xxxx endothelial cells Irene Jiménez-Munguía1, Lucia Pulzova1, Evelina Kanova1, Zuzana Tomeckova1, Petra Majerova2, Katarina Bhide1, Lubos Comor1, Ivana Sirochmanova1, Andrej Kovac2 & Mangesh Bhide1,2 The mechanisms by which Streptococcus pneumoniae penetrates the blood-brain barrier (BBB), reach the CNS and causes meningitis are not fully understood. Adhesion of bacterial cells on the brain microvascular endothelial cells (BMECs), mediated through protein-protein interactions, is one of the crucial steps in translocation of bacteria across BBB. In this work, we proposed a systematic workfow for identifcation of cell wall associated ligands of pneumococcus that might adhere to the human BMECs. The proteome of S. pneumoniae was biotinylated and incubated with BMECs. Interacting proteins were recovered by afnity purifcation and identifed by data independent acquisition (DIA). A total of 44 proteins were identifed from which 22 were found to be surface-exposed. Based on the subcellular location, ontology, protein interactive analysis and literature review, fve ligands (adhesion lipoprotein, endo-β-N-acetylglucosaminidase, PhtA and two hypothetical proteins, Spr0777 and Spr1730) were selected to validate experimentally (ELISA and immunocytochemistry) the ligand- BMECs interaction. In this study, we proposed a high-throughput approach to generate a dataset of plausible bacterial ligands followed by systematic bioinformatics pipeline to categorize the protein candidates for experimental validation. The approach proposed here could contribute in the fast and reliable screening of ligands that interact with host cells. -

Identification and the Significance of Selective Proteins in Bile And
University of Arkansas, Fayetteville ScholarWorks@UARK Theses and Dissertations 12-2014 Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens Balamurugan Packialakshmi University of Arkansas, Fayetteville Follow this and additional works at: http://scholarworks.uark.edu/etd Part of the Analytical Chemistry Commons, Animal Diseases Commons, and the Poultry or Avian Science Commons Recommended Citation Packialakshmi, Balamurugan, "Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health- compromised Chickens" (2014). Theses and Dissertations. 2083. http://scholarworks.uark.edu/etd/2083 This Dissertation is brought to you for free and open access by ScholarWorks@UARK. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected], [email protected]. Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens Identification and the Significance of Selective Proteins in Bile and Plasma of Normal and Health-compromised Chickens A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cell and Molecular Biology by Balamurugan Packialakshmi Tamilnadu Agricultural University, Bachelor of Technology in Agricultural Biotechnology, 2007 Govind Ballabh Pant University of Agriculture and Technology, Master of Science in Molecular Biology and Biotechnology, 2009 December 2014 University of Arkansas This dissertation is approved for the recommendation to the graduate council. _____________________ Dr. Narayan. C. Rath Dissertation Director _____________________ _____________________ Dr. Jackson O. Lay, Jr. Dr. Robert F. Wideman, Jr. Committee member Committee member ____________________ Dr. -
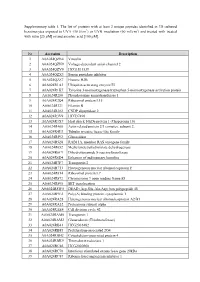
Supplementary Table 1. the List of Proteins with at Least 2 Unique
Supplementary table 1. The list of proteins with at least 2 unique peptides identified in 3D cultured keratinocytes exposed to UVA (30 J/cm2) or UVB irradiation (60 mJ/cm2) and treated with treated with rutin [25 µM] or/and ascorbic acid [100 µM]. Nr Accession Description 1 A0A024QZN4 Vinculin 2 A0A024QZN9 Voltage-dependent anion channel 2 3 A0A024QZV0 HCG1811539 4 A0A024QZX3 Serpin peptidase inhibitor 5 A0A024QZZ7 Histone H2B 6 A0A024R1A3 Ubiquitin-activating enzyme E1 7 A0A024R1K7 Tyrosine 3-monooxygenase/tryptophan 5-monooxygenase activation protein 8 A0A024R280 Phosphoserine aminotransferase 1 9 A0A024R2Q4 Ribosomal protein L15 10 A0A024R321 Filamin B 11 A0A024R382 CNDP dipeptidase 2 12 A0A024R3V9 HCG37498 13 A0A024R3X7 Heat shock 10kDa protein 1 (Chaperonin 10) 14 A0A024R408 Actin related protein 2/3 complex, subunit 2, 15 A0A024R4U3 Tubulin tyrosine ligase-like family 16 A0A024R592 Glucosidase 17 A0A024R5Z8 RAB11A, member RAS oncogene family 18 A0A024R652 Methylenetetrahydrofolate dehydrogenase 19 A0A024R6C9 Dihydrolipoamide S-succinyltransferase 20 A0A024R6D4 Enhancer of rudimentary homolog 21 A0A024R7F7 Transportin 2 22 A0A024R7T3 Heterogeneous nuclear ribonucleoprotein F 23 A0A024R814 Ribosomal protein L7 24 A0A024R872 Chromosome 9 open reading frame 88 25 A0A024R895 SET translocation 26 A0A024R8W0 DEAD (Asp-Glu-Ala-Asp) box polypeptide 48 27 A0A024R9E2 Poly(A) binding protein, cytoplasmic 1 28 A0A024RA28 Heterogeneous nuclear ribonucleoprotein A2/B1 29 A0A024RA52 Proteasome subunit alpha 30 A0A024RAE4 Cell division cycle 42 31 -

Protein Identification by Mass Spectrometry
Outline Terminology • Database search types • Mass tolerance • Peptide Mass Fingerprint • MS/MS search (PMF) • FASTA • Precursor mass-based • Sequence tag • Tandem MS • Precursor mass • Results comparison across programs • Product ion • Manual inspection of • Theoretical mass results • Experimental mass • Sequence tag • de novo sequencing Center for Mass Spectrometry and Proteomics | Phone | (612)625-2280 | (612)625-2279 Three Strategies for Protein Inference from Peptide MS or MS/MS Data Peptide Mass Peptide MS/MS DATA INPUT: List (MS1) (MS2) Peptide Mass Precursor Sequence- Search TYPE: Fingerprint Mass-based based (PMF) (historical) (de novo or 2 mass tag) 1 3 Center for Mass Spectrometry and Proteomics | Phone | (612)625-2280 | (612)625-2279 Peptide Mass Fingerprint (PMF) 1 • Historical: after 1D or 2D in-gel Digestion of single bands or spots • Current applications: limited; decreasing utility Component Description Input (Data) Peptide Mass List • Mass type (Mr or MH+) • Average or Monoisotopic Target Protein FASTA Sequence Database Search Parameters Proteolytic enzyme # Missed enzyme cleave sites Amino acid modifications Mass tolerance Center for Mass Spectrometry and Proteomics | Phone | (612)625-2280 | (612)625-2279 1 Peptide Mass Fingerprint: INPUT GLSDGEWQQVLNVWGK VEADIAGHGQEVLIR A) In gel Trypsin LFTGHPETLEK UNKNOWN PROTEIN (amino acid sequence): TEAEMK GLSDGEWQQVLNVWGKVEADIAGHGQEVLIRLFTG digestion ASEDLK HPETLEKFDKFKHLKTEAEMKASEDLKKHGTVVLT HGTVVLTALGGILK ALGGILKKKGHHEAELKPLAQSHATKHKIPIKYLE GHHEAELKPLAQSHATK FISDAIIHVLHSHPGNFGADAQGAMTKALELFRND -

Large-Scale Database Searching Using Tandem Mass Spectra: Looking up the Answer in the Back of the Book
REVIEW Large-scale database searching using tandem mass spectra: Looking up the answer in the methods back of the book Rovshan G Sadygov, Daniel Cociorva & John R Yates III .com/nature e Database searching is an essential element of large-scale proteomics. Because these .natur w methods are widely used, it is important to understand the rationale of the algorithms. Most algorithms are based on concepts first developed in SEQUEST and PeptideSearch. Four basic approaches are used to determine a match between a spectrum and http://ww sequence: descriptive, interpretative, stochastic and probability–based matching. We oup r review the basic concepts used by most search algorithms, the computational modeling G of peptide identification and current challenges and limitations of this approach for protein identification. lishing b Pu An unintended consequence of whole-genome sequenc- to matching tandem mass spectra of peptides whose ing has been the birth of large-scale proteomics. What exact sequences may not be present in the database. Nature drives proteomics is the ability to use mass spectrome- Space limitations restrict a detailed description of all try data of peptides as an ‘address’ or ‘zip code’ to locate algorithms in this rapidly expanding field. Also, some 2004 proteins in sequence databases. Two mass spectrom- algorithms are proprietary, and thus, details on how © etry methods are used to identify proteins by database they work are unknown. This review should supple- search methods. The first method uses a molecular ment and update earlier reviews on database search weight fingerprint measured from a protein digested algorithms19–24. with a site-specific protease1–5. -

Ptmap—A Sequence Alignment Software for Unrestricted, Accurate, and Full-Spectrum Identification of Post-Translational Modification Sites
PTMap—A sequence alignment software for unrestricted, accurate, and full-spectrum identification of post-translational modification sites Yue Chena,b,1, Wei Chenc, Melanie H. Cobbc, and Yingming Zhaoa,2 Departments of aBiochemistry and cPharmacology, University of Texas Southwestern Medical Center, Dallas, TX 75390; and bDepartment of Chemistry and Biochemistry, University of Texas, Arlington, TX 76019 Contributed by Melanie H. Cobb, November 20, 2008 (sent for review June 12, 2008) We present sequence alignment software, called PTMap, for the over the integers between Ϫ100 and ϩ 300, a list of 4,800 possible accurate identification of full-spectrum protein post-translational modified peptides is generated from the single peptide sequence. modifications (PTMs) and polymorphisms. The software incorpo- The exponentially increased size of the peptide pool and the high rates several features to improve searching speed and accuracy, similarity among peptide sequences derived from the full spectrum including peak selection, adjustment of inaccurate mass shifts, and of possible PTMs make it difficult to remove most of the false precise localization of PTM sites. PTMap also automates rules, positives, let alone all of them. Second, a PTM could happen at based mainly on unmatched peaks, for manual verification of several residue [e.g., protein methylation (18)], modified peptides identified peptides. To evaluate the quality of sequence alignment, with adjacent PTM sites are likely to have similar theoretical we developed a scoring system that takes into account both fragmentation patterns, and hence similar statistical scores. Third, matched and unmatched peaks in the mass spectrum. Incorpora- in silico-generated peptide sequence pools used for sequence tion of these features dramatically increased both accuracy and alignment are unlikely to include all of the peptide sequences sensitivity of the peptide- and PTM-identifications. -

Cross-Talk Between Overlap Interactions in Biomolecules: a Case Study of the Β-Turn Motif
molecules Article Cross-Talk between Overlap Interactions in Biomolecules: A Case Study of the b-Turn Motif Jayashree Nagesh Solid State and Structural Chemistry Unit, Indian Institute of Science Bangalore, Bengaluru 560012, Karnataka, India; [email protected] Abstract: Noncovalent interactions play a pivotal role in regulating protein conformation, stability and dynamics. Among the quantum mechanical (QM) overlap-based noncovalent interactions, n ! p∗ is the best understood with studies ranging from small molecules to b-turns of model proteins such as GB1. However, these investigations do not explore the interplay between multiple overlap interactions in contributing to local structure and stability. In this work, we identify and characterize all noncovalent overlap interactions in the b-turn, an important secondary structural element that facilitates the folding of a polypeptide chain. Invoking a QM framework of natural bond orbitals, we demonstrate the role of several additional interactions such as n ! s∗ and p ! p∗ that are energetically comparable to or larger than n ! p∗. We find that these interactions are sensitive to changes in the side chain of the residues in the b-turn of GB1, suggesting that the n ! p∗ may not be the only component in dictating b-turn conformation and stability. Furthermore, a database search of n ! s∗ and p ! p∗ in the PDB reveals that they are prevalent in most proteins and have significant interaction energies (∼1 kcal/mol). This indicates that all overlap interactions must be taken into account to obtain a comprehensive picture of their contributions to protein structure and energetics. Lastly, based on the extent of QM overlaps and interaction energies, we propose geometric criteria using which these additional interactions can be efficiently tracked in broad database searches. -

Biological Recognition of Graphene Nanoflakes
ARTICLE DOI: 10.1038/s41467-018-04009-x OPEN Biological recognition of graphene nanoflakes V. Castagnola1, W. Zhao1, L. Boselli1, M.C. Lo Giudice 1, F. Meder1, E. Polo 1, K.R. Paton2, C. Backes2, J.N. Coleman2 & K.A. Dawson1 The systematic study of nanoparticle–biological interactions requires particles to be repro- ducibly dispersed in relevant fluids along with further development in the identification of biologically relevant structural details at the materials–biology interface. Here, we develop a biocompatible long-term colloidally stable water dispersion of few-layered graphene nano- 1234567890():,; flakes in the biological exposure medium in which it will be studied. We also report the study of the orientation and functionality of key proteins of interest in the biolayer (corona) that are believed to mediate most of the early biological interactions. The evidence accumulated shows that graphene nanoflakes are rich in effective apolipoprotein A-I presentation, and we are able to map specific functional epitopes located in the C-terminal portion that are known to mediate the binding of high-density lipoprotein to binding sites in receptors that are abundant in the liver. This could suggest a way of connecting the materials' properties to the biological outcomes. 1 Centre for BioNano Interactions, School of Chemistry, University College Dublin, Belfield Dublin 4, Ireland. 2 School of Physics, CRANN and AMBER, Trinity College Dublin, Dublin 2, Ireland. Correspondence and requests for materials should be addressed to V.C. (email: [email protected]) or to K.A.D. (email: [email protected]) NATURE COMMUNICATIONS | (2018) 9:1577 | DOI: 10.1038/s41467-018-04009-x | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | DOI: 10.1038/s41467-018-04009-x ecent years have seen very active interest in understanding Results the factors that influence nanoparticle interactions with Graphene nanoflakes protein corona composition.