Running Linux on a DSP? Exploiting the Computational Resources of a Programmable DSP Micro-Processor with Uclinux
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Module Introduction
Module Introduction PURPOSE: The intent of this module is to provide an overview of the MPC5200. OBJECTIVES: - Identify the MPC5200 Block Diagram - Identify the MPC5200 Target Markets - Describe HiP7 Technology - Describe Core Features - Describe System Level Features CONTENT: - 28 pages - 5 questions LEARNING TIME: - 55 minutes The intent of this module is to provide you with an overview of the MPC5200 microcontroller. You will become familiar with the MPC5200 and its target markets. You will also learn about the composition of the MPC5200 by studying its block diagram. Finally, you will explore the core and system level features of the of the MPC5200. 1 MPC5200 Overview Designed with automotive/telematics applications in mind Runs at higher clock, bus, and CPU speeds Handles a tremendous range of applications Welcome to the MPC5200. This processor provides very high performance in automotive and other embedded environments. This device has been designed with automotive and telematics applications in mind. What is new about the MPC5200? Generally, automotive class processors have not run at the clock speeds seen in the MPC5200. The external bus speeds of this device are up to 132 MHz and the internal execution speed for the CPU is up to 400 MHz. This provides the horsepower to do voice recognition, graphics processing and wireless communications. The MPC5200 is not just for automotive applications. In fact, this device will handle a tremendous range of applications. This is mainly due to the wide range of communications peripherals and timers, as well as the processing power provided by the 603 G2_LE core that uses the PowerPCTM instruction set. -

Ebook - Informations About Operating Systems Version: August 15, 2006 | Download
eBook - Informations about Operating Systems Version: August 15, 2006 | Download: www.operating-system.org AIX Internet: AIX AmigaOS Internet: AmigaOS AtheOS Internet: AtheOS BeIA Internet: BeIA BeOS Internet: BeOS BSDi Internet: BSDi CP/M Internet: CP/M Darwin Internet: Darwin EPOC Internet: EPOC FreeBSD Internet: FreeBSD HP-UX Internet: HP-UX Hurd Internet: Hurd Inferno Internet: Inferno IRIX Internet: IRIX JavaOS Internet: JavaOS LFS Internet: LFS Linspire Internet: Linspire Linux Internet: Linux MacOS Internet: MacOS Minix Internet: Minix MorphOS Internet: MorphOS MS-DOS Internet: MS-DOS MVS Internet: MVS NetBSD Internet: NetBSD NetWare Internet: NetWare Newdeal Internet: Newdeal NEXTSTEP Internet: NEXTSTEP OpenBSD Internet: OpenBSD OS/2 Internet: OS/2 Further operating systems Internet: Further operating systems PalmOS Internet: PalmOS Plan9 Internet: Plan9 QNX Internet: QNX RiscOS Internet: RiscOS Solaris Internet: Solaris SuSE Linux Internet: SuSE Linux Unicos Internet: Unicos Unix Internet: Unix Unixware Internet: Unixware Windows 2000 Internet: Windows 2000 Windows 3.11 Internet: Windows 3.11 Windows 95 Internet: Windows 95 Windows 98 Internet: Windows 98 Windows CE Internet: Windows CE Windows Family Internet: Windows Family Windows ME Internet: Windows ME Seite 1 von 138 eBook - Informations about Operating Systems Version: August 15, 2006 | Download: www.operating-system.org Windows NT 3.1 Internet: Windows NT 3.1 Windows NT 4.0 Internet: Windows NT 4.0 Windows Server 2003 Internet: Windows Server 2003 Windows Vista Internet: Windows Vista Windows XP Internet: Windows XP Apple - Company Internet: Apple - Company AT&T - Company Internet: AT&T - Company Be Inc. - Company Internet: Be Inc. - Company BSD Family Internet: BSD Family Cray Inc. -

Goodforkbadfork-Lineo.Pdf
Good Fork, Bad Fork Examining the Limits of Open Source Software in the Embedded Market Tim Bird Chief Technology Officer www.lineo.com Start with 2 Definitions Definition of open source What are it’s key attributes Definition of network effects Importance of network effects for open source software What is Open Source Software? Examples Linux Apache gcc (GNU compiler) Key Attributes of Open Source Software Access to the source code Freedom to make modifications AND distribute them (free = freedom : think free speech, not free beer) Licenses that provide these attributes Availability of source is NOT enough Source Availability != Open Source QNX now has source availability For lots of money, you can buy source code to VxWorks Microsoft may ship Windows CE source code But that's NOT Open Source Key Attributes of Open Source Software Communities develop The "Linux community" This generates "network effects" What are “Network Effects”? When the value of something increases with the number of items Classic example: the telephone Two phones have limited value Whole network of phones gives each one its value Other “Network Effect” Examples Classic example: VHS videocassette tapes Once a standard develops, it pushes other formats out Market for Applications Windows APIs OS More Popularity Applications Network Effects and Linux Every feature of Linux makes it more valuable to developers Every Linux developer makes Linux have more features Virtuous cycle Open Source Network Effects (Business Benefits) Popularity Availability of engineering resources Info Skilled manpower Engineer enthusiasm Commercial effects Multi-vendor OS Competition to produce rapid development Test organizations Linux is Not Just One Community Separate communities for networking, file systems, Web servers, graphic layers, desktops, etc. -

May 10, 2002 Embedix SDK Lineo 1.07
May 10, 2002 Embedix SDK Lineo 1.07 Embedix SDK 2.4 Getting Started May 10, 2002 Embedix SDK Lineo 1.07 Disclaimer, Trademarks, and Copyright Information Disclaimer Lineo, Inc. makes no representations or warranties with respect to the contents or use of this manual, and specifically disclaims any express or implied warranties of merchantability or fitness for any particular purpose. Lineo, Inc. reserves the right to revise this publication and to make changes to its content, at any time, without obligation to notify any person or entity of such revisions or changes. Lineo, Inc. makes no representations or warranties with respect to any Lineo software, and specifically disclaims any express or implied warranties of merchantability or fitness for any particular purpose. Lineo, Inc. reserves the right to make changes to any and all parts of Lineo software, at any time, without any obligation to notify any person or entity of such changes. Trademarks Lineo and Embedix are registered trademarks of Lineo, Inc. The stylized Lineo logo is a trademark of Lineo, Inc. Other product and company names mentioned in this document may be the trademarks or registered trademarks of their respective owners. Copyright Copyright © 2002 Lineo, Inc. All rights reserved. No part of this publication may be reproduced, photocopied, stored on a retrieval system, or transmitted without the express written consent of the publisher. Lineo, Inc. 588 West 400 South Suite 150 Lindon, UT 84042 USA http://www.lineo.com Embedix SDK 2.4 Getting Started Part Number: EMBD-SDK-GS-0502 May 2002 May 10, 2002 Embedix SDK Lineo 1.07 Contents P R E F A C E About This Guide............................................................................... -

DR DOS for the Zfx86
DR DOS for the ZFx86 Cost Effective, Reliable, Rapid Deployment of Embedded Systems w DR DOS on the ZFx86 gets products to market quickly at the lowest development and ownership cost. w Thousands of compatible applications, drivers and utilities available free or at minimal cost. w Full documentation available. DR DOS 7.03 Key Features of DR DOS Online Manual - DRDOS is supplied with a complete The ideal embedded DOS system, online manual that contains detailed information about all designed for out-of-the-box of the features of the operating system including the basic implementation into ROM or Flash commands, and the advanced utilities. It also has online ROM with tools and associated help available for all its commands. documents available in the DRDOS Memory Management - Memory management features OEM Documentation Kit. include a set of device drivers and commands that enable w 100% MS-DOS 6.22 compatible.. you to manage memory efficiently and make as much memory as possible available to your applications. w Comprehensive DOS utility set DOS Protected Mode Services - DOS Protected Mode w Multitasking, with API for developers Services (DPMS) interface allows specially-implemented w DPMS memory manager in addition to DPMI device drivers and TSRs to operate in extended memory. w Stacker disk compression This makes more memory within the first megabyte w NWCACHE - disk caching program available to applications and other conventionally-written drivers and TSRs. Both Stacker* (the disk compression w EMM386 memory manager program), and NWCACHE (the disk cache) use DPMS. w DOS Protected Mode Services (DPMS) Disk Compression - The disk compression component w Multitasking enables you to store more information by compressing the w DR-DOS provides a full multitasking environment data. -
Non Unix Family Tree and Timeline Version 0.3.2
Non Unix family tree and Timeline Version 0.3.2 1958 FMS SOS 1958 Late 1950's Late 1950's 1960 1960 IBM 1410/1710 OS Early 1960's CTSS 1961-1962 1962 IBSYS PDP-1 OS 1962 Early 1960's 1962 SABRE 1962-64 EXEC I 1964 Tops-10 1.4 1964 1964 Early 1960's OS/360 Multics TOS (BOS, TOS,DOS) 1965 1965 EXEC II Early 1960's DOS CP-40 1966 (CP-67) Tops-10 1.9 MS/8 1966 1966 1966 1966 CAL BPS/360 CP/CMS Tops-10 2.18 Late 1960's ITS WAITS EXEC 3 Late 1960's 1967 1967 1967 1967 Late 1960's DOS/VSE 1968 PARS Tops-10 3.27 1968 1968 SCOPE TDOS 1968 Late 1960's EXEC 4 Late 1960's Late 1960's VMOS ACP v4 EXEC 8 OS/MFT Tops-10 4.50 ACP TENEX Unix Late 1960's 1969 1969 1969 1969 MSS 4.0 1969 Late 1960's Tops-10 4.72 10/1969 1969 MSS 5.0 1970 12/1969 1970 Tops-10 5.01 DOS/Batch 11 MSS 6.0 1970 1970 3/1970 MSS 7.0 3/1970 MSS 8.0 6/1970 1971 RSTS-11 1971 1971 Tops-10 5.02 Tape Scope 2 KRONOS 1971 OS/8 Early 1970's Early 1970's VS/9 Chios 1971 VM/CMS Earl 1970's Early 1970's 1972 OS/VS1 Tops-10 5.03 BKY 1972 1972 1972 Early 1970's Tops-10 5.04 5/1972? KI-TELNEX Tops-10 5.05 mid 1972 7/1972? Tops-10 5.06 1973 11/1972 1973 VSE RSX-11D 5/1973 RT-11 OS/12 Alto 7/1973 1973 OS/VS2 r1 1974 1974 MSS 22.0 1974 RSX-11M 1/1974 1974 Tops-10 5.07 Tops-10 6.01 MR 1.0 CP/M 1.0 5/1974 5/1974 6/1974 1974 OS/VS2 r2 7/1974 1975 1975 OS/VS2 MVS r3 3/1975 Tops-10 5.07A Tops-10 6.01A 5/1975 5/1975 CP/M 1.3 1976 Tops-10 6.02 1975 RSX-11M Plus 1976 Tops-20 1 MSS 28.0 1976 2/1976 2/1976 Tops-20 1A 4/1976 Tops-20 1B 10/1976 Tops-20 101B 12/1976 1977 1977 Tops-10 6.03 p-System I.0 3/1977 -

Module Introduction
Module Introduction PURPOSE: The intent of this module is to provide an overview of the MPC5200. OBJECTIVES: - Identify the MPC5200 Block Diagram - Identify the MPC5200 Target Markets - Describe HiP7 Technology - Describe Core Features - Describe System Level Features CONTENT: - 28 pages - 5 questions LEARNING TIME: - 55 minutes The intent of this module is to provide you with an overview of the MPC5200 microcontroller. You will become familiar with the MPC5200 and its target markets. You will also learn about the composition of the MPC5200 by studying its block diagram. Finally, you will explore the core and system level features of the of the MPC5200. 1 MPC5200 Overview Designed with automotive/telematics applications in mind Runs at higher clock, bus, and CPU speeds Handles a tremendous range of applications Welcome to the MPC5200. This processor provides very high performance in automotive and other embedded environments. This device has been designed with automotive and telematics applications in mind. What is new about the MPC5200? Generally, automotive class processors have not run at the clock speeds seen in the MPC5200. The external bus speeds of this device are up to 132 MHz and the internal execution speed for the CPU is up to 400 MHz. This provides the horsepower to do voice recognition, graphics processing and wireless communications. The MPC5200 is not just for automotive applications. In fact, this device will handle a tremendous range of applications. This is mainly due to the wide range of communications peripherals and timers, as well as the processing power provided by the 603 G2_LE core that uses the PowerPCTM instruction set. -

Embedded Operating Systems and Linux
Embedded Operating Systems and Linux Amir Hossein Payberah [email protected] 1 Agenda ➲ Embedded Systems ➲ Real Time Systems ➲ Who Are The Players? ➲ Linux As An Embedded OS ➲ Kernel 2.4 vs. 2.6 ➲ Applications And Products ➲ The Embedded OS Market 2 Embedded Systems 3 What is an Embedded OS? ➲ An "embedded system" is any computer sys- tem or computing device that performs a ded- icated function or is designed for use with a specific embedded software application. ➲ Embedded systems may use a ROM-based op- erating system or they may use a disk-based system, like a PC. But an embedded system is not usable as a general purpose computers or devices. 4 What makes a good Embedded OS? ➲ Modular ➲ Scalable ➲ Configurable ➲ Small footprint ➲ Device drivers ➲ etc, etc, etc... 5 Real Time Systems 6 What is Real Time? “A real time system is one in which the correct- ness of the computations not only depends upon the logical correctness of the computation but also upon the time at which the result is produced. If the timing constraints of the sys- tem are not met, system failure is said to have occurred.” Donald Gillies 7 What is Real Time? “Real time in operating systems: The ability of the operating system to provide a required level of service in a bounded re- sponse time.” POSIX Standard 1003.1 8 Hard vs. Soft Real Time ➲ Hard ● Absolute deadlines that must be met ● Example: Braking system controller ➲ Soft ● Time tolerance within which an event can occur ● Example: Multimedia streaming 9 What makes a good Real Time OS? ➲ Multi-threaded and pre-emptible -

Licensing Information User Manual Oracle® ILOM
Licensing Information User Manual ® Oracle ILOM Firmware Release 3.2.x October 2018 Part No: E62005-12 October 2018 Licensing Information User Manual Oracle ILOM Firmware Release 3.2.x Part No: E62005-12 Copyright © 2016, 2018, Oracle and/or its affiliates. License Restrictions Warranty/Consequential Damages Disclaimer This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. Warranty Disclaimer The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. Restricted Rights Notice If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government -
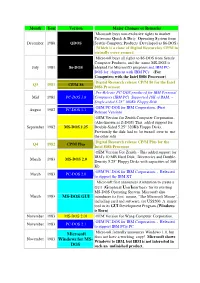
Microsoft Windows for MS
Month Year Version Major Changes or Remarks Microsoft buys non-exclusive rights to market Pattersons Quick & Dirty Operating System from December 1980 QDOS Seattle Computer Products (Developed as 86-DOS) (Which is a clone of Digital Researches C P/M in virtually every respect) Microsoft buys all rights to 86-DOS from Seattle Computer Products, and the name MS-DOS is July 1981 86-DOS adopted for Microsoft's purposes and IBM PC- DOS for shipment with IBM PCs (For Computers with the Intel 8086 Processor) Digital Research release CP/M 86 for the Intel Q3 1981 CP/M 86 8086 Processer Pre-Release PC-DOS produced for IBM Personal Mid 1981 PC-DOS 1.0 Computers (IBM PC) Supported 16K of RAM, ~ Single-sided 5.25" 160Kb Floppy Disk OEM PC-DOS for IBM Corporation. (First August 1982 PC-DOS 1.1 Release Version) OEM Version for Zenith Computer Corporation.. (Also known as Z-DOS) This added support for September 1982 MS-DOS 1.25 Double-Sided 5.25" 320Kb Floppy Disks. Previously the disk had to be turned over to use the other side Digital Research release CP/M Plus for the Q4 1982 CP/M Plus Intel 8086 Processer OEM Version For Zenith - This added support for IBM's 10 MB Hard Disk, Directories and Double- March 1983 MS-DOS 2.0 Density 5.25" Floppy Disks with capacities of 360 Kb OEM PC-DOS for IBM Corporation. - Released March 1983 PC-DOS 2.0 to support the IBM XT Microsoft first announces it intention to create a GUI (Graphical User Interface) for its existing MS-DOS Operating System. -

Kennismanagement Door Middel Van Zoekmachines Pagina 4 Van 69 - 1
WORDT NIET UITGELEEND SCRIPTIE hid INFORMATICA KENNISMANAGEMENT DOORMIDDEL VAN ZOEKMACHINES SIEP DE VRIES KENNISMANAGEMENT DOOR MIDDEI. VAN ZOEKMACHINES PAGINA 2 VAN 69 - org.r "QmaatIcaI Larwtr. INHOUDSOPGAVE 16 'jj INHOUDSOPGAVE 1. VooRwooRD 5 2. KENNISMANAGEMENT 7 2.1. Inleiding 7 2.2.Wat is kennis? 7 2.2.1. Informatie is geen kennis 8 2.3.Methoden van kennismanagement 8 2.3.1. Management van informatie 8 2.3.2. Management van mensen 9 2.4. Evermind en Kennismanagement 10 2.4.1. Waar is op dit momentde kennis van Evermind te vinden') 10 2.4.2. Hoe zoeken Everminders op dit moment naar kennis? 11 2.4.3. Wat zijn nu de mogelijkheden om kennismanagement toe te passen voor Evermind 12 2.5.Opdrachtomschrijving 13 3.ZOEKMACHINESEN HOE ZE WERKEN 15 3.1. Inleiding 15 3.2. Globale werking van zoekmachines 15 3.2.1. De Spider 16 3.2.2. Delndexer 19 3.2.3. De Query engine 22 3.3.Hoe wordt de kwaliteit van een zoekmachine beoordeeld 25 4. BESCHRIJVINGVAN BEKEKEN ZOEKMACHINES 27 4.1.Inleiding 27 4.2.Beschrijving Harvest 27 4.3. Beschrijvinght://Dig 29 4.4. BeschrijvingAlkaline 30 4.5.Mijnkeuze 32 5. BESCHRIJVINGVAN HARVEST 33 5.1. Inleiding 33 5.2. Architectuur 33 5.2.1. Gatherer 34 5.2.2. Broker 36 5.2.3. Glimpse 37 5.3. Testvan Harvest door MP3 files te indexeren 38 5.4. Conclusie 41 6. META DATA 42 6.1. Inleiding 42 6.2. Metadata in HTML 42 6.2.1. Meta Tag 42 6.3. -

Porting Linux to the Powerpc MPC7451
Freescale Semiconductor Document Number: AN2145 Application Note Rev. 2, 10/2006 Porting Linux to the PowerPC™ MPC7451 by Maurie Ommerman CPD Application Freescale Semiconductor, Inc. Austin, TX This document describes porting Montavista’s Hardhat™ Contents Linux from a sandpoint 2 platform with the MPC8240PMC, 1 Terminology . .1 2 Development Environment . .2 the MPC755PMC, or the MPC7400PMC to the 3 Installing Montavista CDK 1.2 . .3 MPC7450/MPC7451. It explains how to set up the 4 CDK RPMs . 3 development environment and how to compile, load, and run 5 Mandrake CD RPMs . 4 6 Building the Kernel . .5 the resultant Hardhat Linux on the sandpoint MPC7450 7 Dependencies . .10 platform. (If building Linux for sandpoint 3, refer to 8 Source Code Changes . .10 Appendix A, “Sandpoint 3 Platform.”) 9 Executable Images . .13 10 Installing an Updated Kernel Source . .13 The MPC7451 has the same functionality as the MPC7450, 11 Untar the Source . .14 and any differences in data regarding bus timing, signal 12 Additional Required Files . 14 behavior, and AC, DC, and thermal characteristics are 13 Sandpoint Setup . .15 14 Hard Drive for Linux OS . .15 detailed in the hardware specifications. Note that because the 15 fdisk Commands . .16 MPC7450 and MPC7451 have the same functionality, they 16 Partition Configuration . .16 are used interchangeably throughout the documentation and 17 Making a ramdisk Linux OS . .17 18 make menuconfig . .17 code. 19 genromfs . .17 20 Downloading the Executable . .19 21 Terminal Emulators . .20 1 Terminology 22 Minicom . .20 23 DINK32 Booting the MPC7450 Linux: Example . .22 The following terms are used in this document.