Heteroskedasticity in Multiple Regression Analysis: What It Is, How to Detect It and How to Solve It with Applications in R and SPSS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Publishing and Promotion in Economics: the Curse of the Top Five
Publishing and Promotion in Economics: The Curse of the Top Five James J. Heckman 2017 AEA Annual Meeting Chicago, IL January 7th, 2017 Heckman Curse of the Top Five Top 5 Influential, But Far From Sole Source of Influence or Outlet for Creativity Heckman Curse of the Top Five Table 1: Ranking of 2, 5 and 10 Year Impact Factors as of 2015 Rank 2 Years 5 Years 10 Years 1. JEL JEL JEL 2. QJE QJE QJE 3. JOF JOF JOF 4. JEP JEP JPE 5. ReStud JPE JEP 6. ECMA AEJae ECMA 7. AEJae ECMA AER 8. AER AER ReStud 9. JPE ReStud JOLE 10. JOLE AEJma EJ 11. AEJep AEJep JHR 12. AEJma EJ JOE 13. JME JOLE JME 14. EJ JHR HE 15. HE JME RED 16. JHR HE EER 17. JOE JOE - 18. AEJmi AEJmi - 19. RED RED - 20. EER EER - Note: Definition of abbreviated names: JEL - Journal of Economic Literature, JOF - Journal of Finance, JEP - Journal of Economic Perspectives, AEJae-American Economic Journal Applied Economics, AER - American Economic Review, JOLE-Journal of Labor Economics, AEJep-American Economic Journal Economic Policy, AEJma-American Economic Journal Macroeconomics, JME-Journal of Monetary Economics, EJ-Economic Journal, HE-Health Economics, JHR-Journal of Human Resources, JOE-Journal of Econometrics, AEJmi-American Economic Journal Microeconomics, RED-Review of Economic Dynamics, EER-European Economic Review; Source: Journal Citation Reports (Thomson Reuters, 2016). Heckman Curse of the Top Five Figure 1: Articles Published in Last 10 years by RePEc's T10 Authors (Last 10 Years Ranking) (a) T10 Authors (Unadjusted) (b) T10 Authors (Adjusted) Prop. -

Fast Computation of the Deviance Information Criterion for Latent Variable Models
Crawford School of Public Policy CAMA Centre for Applied Macroeconomic Analysis Fast Computation of the Deviance Information Criterion for Latent Variable Models CAMA Working Paper 9/2014 January 2014 Joshua C.C. Chan Research School of Economics, ANU and Centre for Applied Macroeconomic Analysis Angelia L. Grant Centre for Applied Macroeconomic Analysis Abstract The deviance information criterion (DIC) has been widely used for Bayesian model comparison. However, recent studies have cautioned against the use of the DIC for comparing latent variable models. In particular, the DIC calculated using the conditional likelihood (obtained by conditioning on the latent variables) is found to be inappropriate, whereas the DIC computed using the integrated likelihood (obtained by integrating out the latent variables) seems to perform well. In view of this, we propose fast algorithms for computing the DIC based on the integrated likelihood for a variety of high- dimensional latent variable models. Through three empirical applications we show that the DICs based on the integrated likelihoods have much smaller numerical standard errors compared to the DICs based on the conditional likelihoods. THE AUSTRALIAN NATIONAL UNIVERSITY Keywords Bayesian model comparison, state space, factor model, vector autoregression, semiparametric JEL Classification C11, C15, C32, C52 Address for correspondence: (E) [email protected] The Centre for Applied Macroeconomic Analysis in the Crawford School of Public Policy has been established to build strong links between professional macroeconomists. It provides a forum for quality macroeconomic research and discussion of policy issues between academia, government and the private sector. The Crawford School of Public Policy is the Australian National University’s public policy school, serving and influencing Australia, Asia and the Pacific through advanced policy research, graduate and executive education, and policy impact. -

Analysis of Imbalance Strategies Recommendation Using a Meta-Learning Approach
7th ICML Workshop on Automated Machine Learning (2020) Analysis of Imbalance Strategies Recommendation using a Meta-Learning Approach Afonso Jos´eCosta [email protected] CISUC, Department of Informatics Engineering, University of Coimbra, Portugal Miriam Seoane Santos [email protected] CISUC, Department of Informatics Engineering, University of Coimbra, Portugal Carlos Soares [email protected] Fraunhofer AICOS and LIACC, Faculty of Engineering, University of Porto, Portugal Pedro Henriques Abreu [email protected] CISUC, Department of Informatics Engineering, University of Coimbra, Portugal Abstract Class imbalance is known to degrade the performance of classifiers. To address this is- sue, imbalance strategies, such as oversampling or undersampling, are often employed to balance the class distribution of datasets. However, although several strategies have been proposed throughout the years, there is no one-fits-all solution for imbalanced datasets. In this context, meta-learning arises a way to recommend proper strategies to handle class imbalance, based on data characteristics. Nonetheless, in related work, recommendation- based systems do not focus on how the recommendation process is conducted, thus lacking interpretable knowledge. In this paper, several meta-characteristics are identified in order to provide interpretable knowledge to guide the selection of imbalance strategies, using Ex- ceptional Preferences Mining. The experimental setup considers 163 real-world imbalanced datasets, preprocessed with 9 well-known resampling algorithms. Our findings elaborate on the identification of meta-characteristics that demonstrate when using preprocessing algo- rithms is advantageous for the problem and when maintaining the original dataset benefits classification performance. 1. Introduction Class imbalance is known to severely affect the data quality. -

Particle Filtering-Based Maximum Likelihood Estimation for Financial Parameter Estimation
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Spiral - Imperial College Digital Repository Particle Filtering-based Maximum Likelihood Estimation for Financial Parameter Estimation Jinzhe Yang Binghuan Lin Wayne Luk Terence Nahar Imperial College & SWIP Techila Technologies Ltd Imperial College SWIP London & Edinburgh, UK Tampere University of Technology London, UK London, UK [email protected] Tampere, Finland [email protected] [email protected] [email protected] Abstract—This paper presents a novel method for estimating result, which cannot meet runtime requirement in practice. In parameters of financial models with jump diffusions. It is a addition, high performance computing (HPC) technologies are Particle Filter based Maximum Likelihood Estimation process, still new to the finance industry. We provide a PF based MLE which uses particle streams to enable efficient evaluation of con- straints and weights. We also provide a CPU-FPGA collaborative solution to estimate parameters of jump diffusion models, and design for parameter estimation of Stochastic Volatility with we utilise HPC technology to speedup the estimation scheme Correlated and Contemporaneous Jumps model as a case study. so that it would be acceptable for practical use. The result is evaluated by comparing with a CPU and a cloud This paper presents the algorithm development, as well computing platform. We show 14 times speed up for the FPGA as the pipeline design solution in FPGA technology, of PF design compared with the CPU, and similar speedup but better convergence compared with an alternative parallelisation scheme based MLE for parameter estimation of Stochastic Volatility using Techila Middleware on a multi-CPU environment. -

Alberto Abadie
ALBERTO ABADIE Office Address Massachusetts Institute of Technology Department of Economics 50 Memorial Drive Building E52, Room 546 Cambridge, MA 02142 E-mail: [email protected] Academic Positions Massachusetts Institute of Technology Cambridge, MA Professor of Economics, 2016-present IDSS Associate Director, 2016-present Harvard University Cambridge, MA Professor of Public Policy, 2005-2016 Visiting Professor of Economics, 2013-2014 Associate Professor of Public Policy, 2004-2005 Assistant Professor of Public Policy, 1999-2004 University of Chicago Chicago, IL Visiting Assistant Professor of Economics, 2002-2003 National Bureau of Economic Research (NBER) Cambridge, MA Research Associate (Labor Studies), 2009-present Faculty Research Fellow (Labor Studies), 2002-2009 Non-Academic Positions Amazon.com, Inc. Seattle, WA Academic Research Consultant, 2020-present Education Massachusetts Institute of Technology Cambridge, MA Ph.D. in Economics, 1995-1999 Thesis title: \Semiparametric Instrumental Variable Methods for Causal Response Mod- els." Centro de Estudios Monetarios y Financieros (CEMFI) Madrid, Spain M.A. in Economics, 1993-1995 Masters Thesis title: \Changes in Spanish Labor Income Structure during the 1980's: A Quantile Regression Approach." 1 Universidad del Pa´ıs Vasco Bilbao, Spain B.A. in Economics, 1987-1992 Specialization Areas: Mathematical Economics and Econometrics. Honors and Awards Elected Fellow of the Econometric Society, 2016. NSF grant SES-1756692, \A General Synthetic Control Framework of Estimation and Inference," 2018-2021. NSF grant SES-0961707, \A General Theory of Matching Estimation," with G. Imbens, 2010-2012. NSF grant SES-0617810, \The Economic Impact of Terrorism: Lessons from the Real Estate Office Markets of New York and Chicago," with S. Dermisi, 2006-2008. -

Rankings of Economics Journals and Departments in India
WP-2010-021 Rankings of Economics Journals and Departments in India Tilak Mukhopadhyay and Subrata Sarkar Indira Gandhi Institute of Development Research, Mumbai October 2010 http://www.igidr.ac.in/pdf/publication/WP-2010-021.pdf Rankings of Economics Journals and Departments in India Tilak Mukhopadhyay and Subrata Sarkar Indira Gandhi Institute of Development Research (IGIDR) General Arun Kumar Vaidya Marg Goregaon (E), Mumbai- 400065, INDIA Email (corresponding author): [email protected] Abstract This paper is the first attempt to rank economics departments of Indian Institutions based on their research output. Two rankings, one based on publications in international journals, and the other based on publications in domestic journals are derived. The rankings based on publications in international journals are obtained using the impact values of 159 journals found in Kalaitzidakis et al. (2003). Rankings based on publications in domestic journals are based on impact values of 20 journals. Since there are no published studies on ranking of domestic journals, we derived the rankings of domestic journals by using the iterative method suggested in Kalaitzidakis et al. (2003). The department rankings are constructed using two approaches namely, the ‘flow approach’ and the ‘stock approach’. Under the ‘flow approach’ the rankings are based on the total output produced by a particular department over a period of time while under the ‘stock approach’ the rankings are based on the publication history of existing faculty members in an institution. From these rankings the trend of research work and the growth of the department of a university are studied. Keywords: Departments,Economics, Journals, Rankings JEL Code: A10, A14 Acknowledgements: The auhtors would like to thank the seminar participants at Indira Gandhi Institute of Development Research. -

A Generalized Linear Model for Binomial Response Data
A Generalized Linear Model for Binomial Response Data Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 1 / 46 Now suppose that instead of a Bernoulli response, we have a binomial response for each unit in an experiment or an observational study. As an example, consider the trout data set discussed on page 669 of The Statistical Sleuth, 3rd edition, by Ramsey and Schafer. Five doses of toxic substance were assigned to a total of 20 fish tanks using a completely randomized design with four tanks per dose. Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 2 / 46 For each tank, the total number of fish and the number of fish that developed liver tumors were recorded. d=read.delim("http://dnett.github.io/S510/Trout.txt") d dose tumor total 1 0.010 9 87 2 0.010 5 86 3 0.010 2 89 4 0.010 9 85 5 0.025 30 86 6 0.025 41 86 7 0.025 27 86 8 0.025 34 88 9 0.050 54 89 10 0.050 53 86 11 0.050 64 90 12 0.050 55 88 13 0.100 71 88 14 0.100 73 89 15 0.100 65 88 16 0.100 72 90 17 0.250 66 86 18 0.250 75 82 19 0.250 72 81 20 0.250 73 89 Copyright c 2017 Dan Nettleton (Iowa State University) Statistics 510 3 / 46 One way to analyze this dataset would be to convert the binomial counts and totals into Bernoulli responses. -

The Detection of Heteroscedasticity in Regression Models for Psychological Data
Psychological Test and Assessment Modeling, Volume 58, 2016 (4), 567-592 The detection of heteroscedasticity in regression models for psychological data Andreas G. Klein1, Carla Gerhard2, Rebecca D. Büchner2, Stefan Diestel3 & Karin Schermelleh-Engel2 Abstract One assumption of multiple regression analysis is homoscedasticity of errors. Heteroscedasticity, as often found in psychological or behavioral data, may result from misspecification due to overlooked nonlinear predictor terms or to unobserved predictors not included in the model. Although methods exist to test for heteroscedasticity, they require a parametric model for specifying the structure of heteroscedasticity. The aim of this article is to propose a simple measure of heteroscedasticity, which does not need a parametric model and is able to detect omitted nonlinear terms. This measure utilizes the dispersion of the squared regression residuals. Simulation studies show that the measure performs satisfactorily with regard to Type I error rates and power when sample size and effect size are large enough. It outperforms the Breusch-Pagan test when a nonlinear term is omitted in the analysis model. We also demonstrate the performance of the measure using a data set from industrial psychology. Keywords: Heteroscedasticity, Monte Carlo study, regression, interaction effect, quadratic effect 1Correspondence concerning this article should be addressed to: Prof. Dr. Andreas G. Klein, Department of Psychology, Goethe University Frankfurt, Theodor-W.-Adorno-Platz 6, 60629 Frankfurt; email: [email protected] 2Goethe University Frankfurt 3International School of Management Dortmund Leipniz-Research Centre for Working Environment and Human Factors 568 A. G. Klein, C. Gerhard, R. D. Büchner, S. Diestel & K. Schermelleh-Engel Introduction One of the standard assumptions underlying a linear model is that the errors are inde- pendently identically distributed (i.i.d.). -

Resampling Hypothesis Tests for Autocorrelated Fields
JANUARY 1997 WILKS 65 Resampling Hypothesis Tests for Autocorrelated Fields D. S. WILKS Department of Soil, Crop and Atmospheric Sciences, Cornell University, Ithaca, New York (Manuscript received 5 March 1996, in ®nal form 10 May 1996) ABSTRACT Presently employed hypothesis tests for multivariate geophysical data (e.g., climatic ®elds) require the as- sumption that either the data are serially uncorrelated, or spatially uncorrelated, or both. Good methods have been developed to deal with temporal correlation, but generalization of these methods to multivariate problems involving spatial correlation has been problematic, particularly when (as is often the case) sample sizes are small relative to the dimension of the data vectors. Spatial correlation has been handled successfully by resampling methods when the temporal correlation can be neglected, at least according to the null hypothesis. This paper describes the construction of resampling tests for differences of means that account simultaneously for temporal and spatial correlation. First, univariate tests are derived that respect temporal correlation in the data, using the relatively new concept of ``moving blocks'' bootstrap resampling. These tests perform accurately for small samples and are nearly as powerful as existing alternatives. Simultaneous application of these univariate resam- pling tests to elements of data vectors (or ®elds) yields a powerful (i.e., sensitive) multivariate test in which the cross correlation between elements of the data vectors is successfully captured by the resampling, rather than through explicit modeling and estimation. 1. Introduction dle portion of Fig. 1. First, standard tests, including the t test, rest on the assumption that the underlying data It is often of interest to compare two datasets for are composed of independent samples from their parent differences with respect to particular attributes. -

Comparison of Some Chemometric Tools for Metabonomics Biomarker Identification ⁎ Réjane Rousseau A, , Bernadette Govaerts A, Michel Verleysen A,B, Bruno Boulanger C
Available online at www.sciencedirect.com Chemometrics and Intelligent Laboratory Systems 91 (2008) 54–66 www.elsevier.com/locate/chemolab Comparison of some chemometric tools for metabonomics biomarker identification ⁎ Réjane Rousseau a, , Bernadette Govaerts a, Michel Verleysen a,b, Bruno Boulanger c a Université Catholique de Louvain, Institut de Statistique, Voie du Roman Pays 20, B-1348 Louvain-la-Neuve, Belgium b Université Catholique de Louvain, Machine Learning Group - DICE, Belgium c Eli Lilly, European Early Phase Statistics, Belgium Received 29 December 2006; received in revised form 15 June 2007; accepted 22 June 2007 Available online 29 June 2007 Abstract NMR-based metabonomics discovery approaches require statistical methods to extract, from large and complex spectral databases, biomarkers or biologically significant variables that best represent defined biological conditions. This paper explores the respective effectiveness of six multivariate methods: multiple hypotheses testing, supervised extensions of principal (PCA) and independent components analysis (ICA), discriminant partial least squares, linear logistic regression and classification trees. Each method has been adapted in order to provide a biomarker score for each zone of the spectrum. These scores aim at giving to the biologist indications on which metabolites of the analyzed biofluid are potentially affected by a stressor factor of interest (e.g. toxicity of a drug, presence of a given disease or therapeutic effect of a drug). The applications of the six methods to samples of 60 and 200 spectra issued from a semi-artificial database allowed to evaluate their respective properties. In particular, their sensitivities and false discovery rates (FDR) are illustrated through receiver operating characteristics curves (ROC) and the resulting identifications are used to show their specificities and relative advantages.The paper recommends to discard two methods for biomarker identification: the PCA showing a general low efficiency and the CART which is very sensitive to noise. -
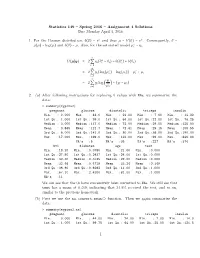
Statistics 149 – Spring 2016 – Assignment 4 Solutions Due Monday April 4, 2016 1. for the Poisson Distribution, B(Θ) =
Statistics 149 { Spring 2016 { Assignment 4 Solutions Due Monday April 4, 2016 1. For the Poisson distribution, b(θ) = eθ and thus µ = b′(θ) = eθ. Consequently, θ = ∗ g(µ) = log(µ) and b(θ) = µ. Also, for the saturated model µi = yi. n ∗ ∗ D(µSy) = 2 Q yi(θi − θi) − b(θi ) + b(θi) i=1 n ∗ ∗ = 2 Q yi(log(µi ) − log(µi)) − µi + µi i=1 n yi = 2 Q yi log − (yi − µi) i=1 µi 2. (a) After following instructions for replacing 0 values with NAs, we summarize the data: > summary(mypima2) pregnant glucose diastolic triceps insulin Min. : 0.000 Min. : 44.0 Min. : 24.00 Min. : 7.00 Min. : 14.00 1st Qu.: 1.000 1st Qu.: 99.0 1st Qu.: 64.00 1st Qu.:22.00 1st Qu.: 76.25 Median : 3.000 Median :117.0 Median : 72.00 Median :29.00 Median :125.00 Mean : 3.845 Mean :121.7 Mean : 72.41 Mean :29.15 Mean :155.55 3rd Qu.: 6.000 3rd Qu.:141.0 3rd Qu.: 80.00 3rd Qu.:36.00 3rd Qu.:190.00 Max. :17.000 Max. :199.0 Max. :122.00 Max. :99.00 Max. :846.00 NA's :5 NA's :35 NA's :227 NA's :374 bmi diabetes age test Min. :18.20 Min. :0.0780 Min. :21.00 Min. :0.000 1st Qu.:27.50 1st Qu.:0.2437 1st Qu.:24.00 1st Qu.:0.000 Median :32.30 Median :0.3725 Median :29.00 Median :0.000 Mean :32.46 Mean :0.4719 Mean :33.24 Mean :0.349 3rd Qu.:36.60 3rd Qu.:0.6262 3rd Qu.:41.00 3rd Qu.:1.000 Max. -

Sampling and Resampling
Sampling and Resampling Thomas Lumley Biostatistics 2005-11-3 Basic Problem (Frequentist) statistics is based on the sampling distribution of statistics: Given a statistic Tn and a true data distribution, what is the distribution of Tn • The mean of samples of size 10 from an Exponential • The median of samples of size 20 from a Cauchy • The difference in Pearson’s coefficient of skewness ((X¯ − m)/s) between two samples of size 40 from a Weibull(3,7). This is easy: you have written programs to do it. In 512-3 you learn how to do it analytically in some cases. But... We really want to know: What is the distribution of Tn in sampling from the true data distribution But we don’t know the true data distribution. Empirical distribution On the other hand, we do have an estimate of the true data distribution. It should look like the sample data distribution. (we write Fn for the sample data distribution and F for the true data distribution). The Glivenko–Cantelli theorem says that the cumulative distribution function of the sample converges uniformly to the true cumulative distribution. We can work out the sampling distribution of Tn(Fn) by simulation, and hope that this is close to that of Tn(F ). Simulating from Fn just involves taking a sample, with replace- ment, from the observed data. This is called the bootstrap. We ∗ write Fn for the data distribution of a resample. Too good to be true? There are obviously some limits to this • It requires large enough samples for Fn to be close to F .