Extending Behavior Trees with Classical Planning
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Interstellar Marines Nodvd Di MAXAGENT
Interstellar Marines noDVD di MAXAGENT Informazioni sul gioco Interstellar Marines is an immersive tactical sci-fi First Person Simulator in the making, offering a unique blend of tactical gameplay, dynamic environments and non- scripted AI. Play Singleplayer or Co-op/PvP on servers around the world. Interstellar Marines is inspired by movies such as Aliens, Starship Troopers and Saving Private Ryan; and games such as Half-Life, Deus Ex, System Shock 2, and Rainbow Six 3: Raven Shield. Interstellar Marines is all about evolving the FPS recipe with the inspirations we've assimilated since the birth of the genre. Our goal is an evolutionary leap forward driven by our compulsive interest in science fiction, role-playing, military realism, and respect for first person immersion. Interstellar Warfare InitiativeIt is the dawn of the 22nd century, a time of great hopes and expectations. The discovery of a new and inexhaustible well of power known as Zero Point Energy has revolutionized space travel. Man has escaped the confines of Mother Earth, and gone on to colonize the solar system. But far away from public awareness an ambitious military project has already taken Man beyond the final frontier, and into the regions of the stars. The powerful Interplanetary Treaty Organization, ITO, is secretly constructing the first human settlement in another star system. You are a special forces soldier training to join the Interstellar Marines, a > 9 Unique Multiplayer Maps Across 3 Game ModesTake your friends out in Deadlock, Deathmatch, and Team Deathmatch on maps featuring dynamic environment effects such as time of day, rain, thunder and lightning, emergency lighting, fire alarms, moving platforms etc. -

925 År Navn Platform Udvikler Udgiver Har KB Spillet?
Danskudviklede computerspil Denne liste indeholder oplysninger om alle de danskudviklede computerspil, som er kendte af Det Kongelige Bibliotek, samt oplysninger om, hvorvidt materialerne indgår i bibliotekets samlinger. Listen er i det store hele identisk med oversigten DKGames (https://docs.google.com/spreadsheet/ccc?key=0AqarukOuwoNKdEg5U1E0Z3VXb3BlNERHWm5XMWYweEE&authkey=CIWlorkK&hl=da) , der blev startet af Bo Abrahamsen og nu føres videre hos spiludvikling.dk Hvis du kan bidrage, enten med tips om nye spil til listen eller med donationer af spil, som Det Kongelige Bibliotek ikke er i besiddelse af endnu, er du meget velkommen til at henvende dig til Det Kongelige Bibliotek på [email protected] Listen er senest opdateret fredag den 11/4 2014 Vær opmærksom på, at beholdningsoplysningerne ikke er fuldstændig opdaterede for spil, der er under 1 år gamle. Det skyldes bibliotekets periodiske leveringsfrister for hhv. pligtafleverede og nethøstede computerspil. Bemærk også, at det ikke er alle spil, som kan fremsøges i KBs søgesystem REX. Det skyldes bl.a. at nethøstede materialer ikke katalogiseres selvstændigt. Bemærk også, at de fleste af manglerne skyldes tre forhold: Spillet er ældre end 1998 og falder dermed udenfor pligtafleveringsloven eller spillet er udgivet online eller som app på en måde, der umuliggør indsamling via nethøstning eller på anden vis. Antal: 925 år navn platform udvikler udgiver Har KB spillet? 1981 Kaptajn Kaper i Kattegat PC Peter Ole Frederiksen Peter Ole Frederiksen 1 1983 Pacman, 3D ZX Spectrum Freddy Kristiansen Freddy Kristiansen 0 1983 Interpide ZX Spectrum Rolf Østergaard ZX Power 0 1983 Black Jack ZX Spectrum ZX Data 0 1984 Crackers revenge C64 Sodan Flying Crackers 1 1983 Tumler ZX Spectrum Viking Software 0 1984 Kalaha ZX Spectrum ZX Data 0 1984 Osten ZX Spectrum JC Jumbo Data 0 1985 Citadel BBC Micro Superior 0 1984 Zenon c64 Supersoft 0 1985 Black Adder c64 HaMa Software 0 1985 Skabet ZX Spectrum Erik Reiss, Maz H. -

Unity Game Engine
UNITY GAME ENGINE Overview Will Goldstone & Christopher Pope London Unity User Group 15th April 2011 http://unity3d.com What’s all the fuss about? ★ Multi Platform Engine ★ Rapid Learning Curve & Usability ★ Used by everyone from hobbyists to large studios ★ Build Once, Deploy Everywhere ★ Versatile Environment == Wide range of digital content London Unity User Group 15th April 2011 http://unity3d.com Multi-Platform Engine ★ Desktop - PC and Mac ★ Web - All modern browsers via Unity plugin ★ Flash via Molehill... very soon. ★ iOS - iPhone, iPad & iPod Touch ★ Google Android ★ Nintendo Wii ★ Playstation 3 ★ Xbox 360 ★ Xperia Play & Other Devices via Union London Unity User Group 15th April 2011 http://unity3d.com Rapid Learning Curve & Usability ★ Visual Approach to game design ★ Game Object > Component approach ★ Automatic Asset Update Pipeline ★ Immediate JIT based testing ★ One click deployment London Unity User Group 15th April 2011 http://unity3d.com Diverse Userbase ★ Users from 10 to 100 ★ Hobbyists posting to Kongregate & other portals ★ Students learning game dev for a career ★ Mid-level studios making mobile and web content ★ Large studios making triple A titles London Unity User Group 15th April 2011 http://unity3d.com Build Once, Deploy Everywhere. ★ Designed for Scalability ★ Quality Settings to help you profile ★ Simple platform switching ★ Reach more players London Unity User Group 15th April 2011 http://unity3d.com Versatile Environment ★ Console and Desktop Games Interstellar Marines (PC/Mac) Rochard (PS3) Crasher (PC/Mac) -
7 Sins Pc Game Patch
7 sins pc game patch click here to download 7 Sins Cheat Codes, Trainers, Patch Updates, Demos, Downloads, Cheats Trainer, Tweaks & Game Patch Fixes are featured on this page. The biggest totally free game fix & trainer library online for PC Games 7 Sins va +5 TRAINER; 7 Sins CHEAT; 7 Sins v +6 TRAINER; 7 Sins SAVEGAME Sins v [SPANISH] No · Sins v [FRENCH] No · Sins v [GERMAN] No. 7 Sins Game Fixes, No-CD Game Fixes, No-CD Patches, No-CD Files, PC Game Fixes to enable you to play your PC Games without the CD in the drive. 7 Sins PC Game Nude Patch Very Funny 18 [img] 7 Sins PC Game Nude Patch | MB And what do we have here? After the mass popularity. 7 Sins +6 Trainerfree full download. www.doorway.ru Size: KB Downloads: 8, Show advanced download options. In-Game Videos (4). Latest Updates. 7 Sins +6 Trainer. DEMOS. PATCHES - CHEATS. REVIEWS. GAME VIDEOS. Euro Truck Simulator 2 v1. Download Sin - Update now from the world's largest gaming download This is the patch to update the original retail v to 7 sins pc game patch. slt je voudrai savoir commen on pe telecharger 7 sins gratuitement sur un ordi sous vista. 7 sins pc game patch. Downloads zum Strategiespiel 7 Sins auf www.doorway.ru Spielen Sie 7 Sins mit der Demo kostenlos. Außerdem Patches und Mods in der Übersicht. More 7 Sins Fixes. ZoneOfGames Backup CD 7 Sins v RUS · 7 Sins v ENG · 7 Sins v GER · 7 Sins v FRA · 7 Sins v RUS. -

XCOM: Enemy Unknown Civilization: Beyond Earth
GAMING ON LINUX GAMING ON LINUX The tastiest brain candy to relax those tired neurons OPEN UP XCOM: Enemy Unknown The invasion has begun! COM: Enemy Unknown, a high-profile reboot of Not your traditional base building. Xthe XCOM series has been released on Linux to great fanfare. XCOM: Enemy Unknown mixes base building, research Liam Dawe is our Games Editor and the founder of gamingonlinux.com, and turn-based combat in one the home of Tux gaming on the web. absolutely beautiful package and just goes to show how far ou might expect us to say Linux has come in developers’ this, but opening up the and publishers’ minds for us to source code of a game can Y get such a high-profile game. better for everyone. It’s a hot topic and one that has been talked about The original XCOM is one about it. There’s a pack more. We highly recommend for years, but it seems that bigger of the best strategy games available for it called “Enemy taking a look at this one, as the developers still don’t quite ever made and this reboot Within”, which adds a ton of importance of games like this understand that they can still sell really does it justice. It takes new content including new on Linux cannot be overstated. their game even if the source code is the original and amplifies multiplayer maps, new types http://store.steampowered. available for free. The first thing to note is that for a everything that was good of aliens and much much com/app/200510 game to be open source it doesn’t mean that the media needs to be. -

TESIS DOCTORAL La Iluminación Como Recurso Expresivo Para Guiar
TESIS DOCTORAL La iluminación como recurso expresivo para guiar las interacciones en los videojuegos tridimensionales Autor: Marta Fernández Ruiz Director/es: Juan Carlos Ibáñez Fernández Manuel Armenteros Gallardo DEPARTAMENTO DE PERIODISMO Y COMUNICACIÓN AUDIOVISUAL Getafe, Mayo, 2013 TESIS DOCTORAL LA ILUMINACIÓN COMO RECURSO EXPRESIVO PARA GUIAR LAS INTERACCIONES EN LOS VIDEOJUEGOS TRIDIMENSIONALES Autor: Marta Fernández Ruiz Director/es: Juan Carlos Ibáñez Fernández Manuel Armenteros Gallardo Firma del Tribunal Calificador: Firma Presidente: Vocal: Secretario: Calificación: Leganés/Getafe, de de AGRADECIMIENTOS La realización de esta tesis doctoral ha requerido de un gran esfuerzo y motivación personal por parte de la autora, pero su finalización no hubiese sido posible sin la cooperación desinteresada de todas y cada una de las personas que me han apoyado durante este tiempo. En primer lugar, quisiera agradecer este trabajo a Juan Carlos Ibáñez, co- director de la tesis, por las repetidas lecturas que ha realizado del texto y las valiosas ideas que ha aportado y de las que tanto provecho he sacado. Mis más sinceros agradecimientos también a Manuel Armenteros, segundo co-director de este trabajo, por la confianza depositada en mí durante ya cinco años en los que me ha orientado con ilusión, constancia y ánimos. Gracias por el tiempo y el gran esfuerzo dedicado a la finalización de esta tesis, y por permitirme crecer como investigadora, como profesional y como persona. Asimismo me complace agradecerle al grupo de investigación TECMERIN, del Departamento de Periodismo y Comunicación Audiovisual de la Universidad Carlos III de Madrid, su acogida y sus invitaciones a participar en diferentes reuniones en las que he podido conocer diferentes perspectivas desde las que se puede trabajar en el ámbito de la Comunicación Audiovisual. -

PC Peter Ole Frederiksen Peter Ole Frederiksen 1 ZX Spectrum Fredd
Danskudviklede computerspil Denne liste indeholder oplysninger om alle de danskudviklede computerspil, som er kendte af Det Kongelige Bibliotek, samt oplysninger om, hvorvidt materialerne indgår i bibliotekets samlinger. Listen er i det store hele identisk med oversigten DKGames (https://docs.google.com/spreadsheet/ccc?key=0AqarukOuwoNKdEg5U1E0Z3VXb3BlNERHWm5XMWYweEE&authkey=CIWlorkK&hl=da) , der blev startet af Bo Abrahamsen og nu føres videre hos spiludvikling.dk Hvis du kan bidrage, enten med tips om nye spil til listen eller med donationer af spil, som Det Kongelige Bibliotek ikke er i besiddelse af endnu, er du meget velkommen til at henvende dig til Det Kongelige Bibliotek på [email protected] Listen er senest opdateret mandag 3/9 2012 Vær opmærksom på, at beholdningsoplysningerne ikke er fuldstændig opdaterede for spil, der er under 1 år gamle. Det skyldes bibliotekets periodiske leveringsfrister for hhv. pligtafleverede og nethøstede computerspil. Bemærk også, at det ikke er alle spil, som kan fremsøges i KBs søgesystem REX. Det skyldes bl.a. at nethøstede materialer ikke katalogiseres selvstændigt. Bemærk også, at de fleste af manglerne skyldes tre forhold: Spillet er ældre end 1998 og falder dermed udenfor pligtafleveringsloven, spillet er udgivet til mobile devices (iOS og Android) som p.t. af tekniske årsager ikke indsamles eller spillet er udgivet online på en måde, der umuliggør indsamling via nethøstning. Antal: 570 år navn platform udvikler udgiver Har KB spillet? 1981 Kaptajn Kaper i Kattegat PC Peter Ole Frederiksen Peter Ole Frederiksen 1 1983 Pacman, 3D ZX Spectrum Freddy Kristiansen Freddy Kristiansen 0 1983 Interpide ZX Spectrum Rolf Østergaard ZX Power 0 1983 Black Jack ZX Spectrum ZX Data 0 1983 Tumler ZX Spectrum Viking Software 0 1984 Crackers revenge C64 Sodan Flying Crackers 1 1984 Kalaha ZX Spectrum ZX Data 0 1984 Osten ZX Spectrum JC Jumbo Data 0 1984 Zenon c64 Supersoft 0 1985 Skabet ZX Spectrum Erik Reiss, Maz H. -
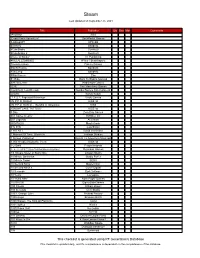
This Checklist Is Generated Using RF Generation's Database This Checklist Is Updated Daily, and It's Completeness Is Dependent on the Completeness of the Database
Steam Last Updated on September 25, 2021 Title Publisher Qty Box Man Comments !AnyWay! SGS !Dead Pixels Adventure! DackPostal Games !LABrpgUP! UPandQ #Archery Bandello #CuteSnake Sunrise9 #CuteSnake 2 Sunrise9 #Have A Sticker VT Publishing #KILLALLZOMBIES 8Floor / Beatshapers #monstercakes Paleno Games #SelfieTennis Bandello #SkiJump Bandello #WarGames Eko $1 Ride Back To Basics Gaming √Letter Kadokawa Games .EXE Two Man Army Games .hack//G.U. Last Recode Bandai Namco Entertainment .projekt Kyrylo Kuzyk .T.E.S.T: Expected Behaviour Veslo Games //N.P.P.D. RUSH// KISS ltd //N.P.P.D. RUSH// - The Milk of Ultraviolet KISS //SNOWFLAKE TATTOO// KISS ltd 0 Day Zero Day Games 001 Game Creator SoftWeir Inc 007 Legends Activision 0RBITALIS Mastertronic 0°N 0°W Colorfiction 1 HIT KILL David Vecchione 1 Moment Of Time: Silentville Jetdogs Studios 1 Screen Platformer Return To Adventure Mountain 1,000 Heads Among the Trees KISS ltd 1-2-Swift Pitaya Network 1... 2... 3... KICK IT! (Drop That Beat Like an Ugly Baby) Dejobaan Games 1/4 Square Meter of Starry Sky Lingtan Studio 10 Minute Barbarian Studio Puffer 10 Minute Tower SEGA 10 Second Ninja Mastertronic 10 Second Ninja X Curve Digital 10 Seconds Zynk Software 10 Years Lionsgate 10 Years After Rock Paper Games 10,000,000 EightyEightGames 100 Chests William Brown 100 Seconds Cien Studio 100% Orange Juice Fruitbat Factory 1000 Amps Brandon Brizzi 1000 Stages: The King Of Platforms ltaoist 1001 Spikes Nicalis 100ft Robot Golf No Goblin 100nya .M.Y.W. 101 Secrets Devolver Digital Films 101 Ways to Die 4 Door Lemon Vision 1 1010 WalkBoy Studio 103 Dystopia Interactive 10k Dynamoid This checklist is generated using RF Generation's Database This checklist is updated daily, and it's completeness is dependent on the completeness of the database. -

Embedding 3D Web Based Content For
Embedded 3D Web Based Content for the Creation of an Interactive Medical Browser NEIL JON GALLAGHER Submitted to the University of Hertfordshire in partial fulfilment of the requirements of the degree of MA by Research September 2015 1 i. Abstract The research project set out to examine the possibility of presenting 3D medical visualisations through a web browser to help suffers and their families understand their conditions. Explaining complex medical subjects and communicating them simply and clearly to non-specialists is a continuing problem in modern medical practice. The study set out to complement current methods of health communication via pamphlets, posters, books, magazines, 2D & 3D animations and text based websites as all of these have disadvantages which an interactive 3D system might be able to overcome. The reason a Web Browser approach was adopted was due to the wide availability of browsers for a large number of users. Additionally modern web based 3D content delivery methods negate the need to continually download and install additional software, at the same time allowing for a high quality user experience associated with traditional 3D interactive software. To help answer the research questions, a prototype artefact focused on Asthma was produced which was then tested and validated through user testing with a small group of Asthma suffers and evaluated by medical professionals. The study concluded that effective communication of medical information to sufferers and their families using 3D browser based systems is possible -

IND13 ISSUE-FOUR.Pdf
Save the sheep from a horde of wolves by building a fence around them, in this increasingly difficult new puzzler from McPeppergames www.mcpeppergames.com 2 ind13.com EDITORIAL Introduction we are Hello and welcome to IND13 (Indie), the magazine sound effect artistry to retro arcades – we’ll take a that champions independent games. look at anything that grabs our interest. Maybe you’re a developer, or a hardcore gamer, We’re a small core team of just six members – so or someone new to the concept of indie games we’re always looking for new angles and fresh wanting to learn more – we’ve got something for writing. If you think you’ve got something that’ll you all. make indie game developers step away from their consoles for a few minutes, get in touch by emailing Just like the games we love, we’re independent: us at [email protected]. this means no editorial agenda except good, solid reporting on all aspects of indie gaming. From Enjoy, veteran developers to crowdfunding campaigns, ind13 Who we are... IND13 is a games magazine dedicated to independent games placements in the magazine. development. The team is made up of voluntary contributors from different areas of independent games development. We also give pro bono ad placements to the companies the team work for, in exchange for our time spent contributing to the We’ve created a magazine which discusses topics we think magazine and to keep our employers happy. are important to, and cater to the fans of, independent games development. We hope you enjoyed the magazine and please do get in touch with questions and comments.