A Comprehensive Survey on Parallelization and Elasticity in Stream Processing
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Parallel Patterns for Adaptive Data Stream Processing
Università degli Studi di Pisa Dipartimento di Informatica Dottorato di Ricerca in Informatica Ph.D. Thesis Parallel Patterns for Adaptive Data Stream Processing Tiziano De Matteis Supervisor Supervisor Marco Danelutto Marco Vanneschi Abstract In recent years our ability to produce information has been growing steadily, driven by an ever increasing computing power, communication rates, hardware and software sensors diffusion. is data is often available in the form of continuous streams and the ability to gather and analyze it to extract insights and detect patterns is a valu- able opportunity for many businesses and scientific applications. e topic of Data Stream Processing (DaSP) is a recent and highly active research area dealing with the processing of this streaming data. e development of DaSP applications poses several challenges, from efficient algorithms for the computation to programming and runtime systems to support their execution. In this thesis two main problems will be tackled: • need for high performance: high throughput and low latency are critical re- quirements for DaSP problems. Applications necessitate taking advantage of parallel hardware and distributed systems, such as multi/manycores or cluster of multicores, in an effective way; • dynamicity: due to their long running nature (24hr/7d), DaSP applications are affected by highly variable arrival rates and changes in their workload charac- teristics. Adaptivity is a fundamental feature in this context: applications must be able to autonomously scale the used resources to accommodate dynamic requirements and workload while maintaining the desired Quality of Service (QoS) in a cost-effective manner. In the current approaches to the development of DaSP applications are still miss- ing efficient exploitation of intra-operator parallelism as well as adaptations strategies with well known properties of stability, QoS assurance and cost awareness. -

A Middleware for Efficient Stream Processing in CUDA
Noname manuscript No. (will be inserted by the editor) A Middleware for E±cient Stream Processing in CUDA Shinta Nakagawa ¢ Fumihiko Ino ¢ Kenichi Hagihara Received: date / Accepted: date Abstract This paper presents a middleware capable of which are expressed as kernels. On the other hand, in- out-of-order execution of kernels and data transfers for put/output data is organized as streams, namely se- e±cient stream processing in the compute uni¯ed de- quences of similar data records. Input streams are then vice architecture (CUDA). Our middleware runs on the passed through the chain of kernels in a pipelined fash- CUDA-compatible graphics processing unit (GPU). Us- ion, producing output streams. One advantage of stream ing the middleware, application developers are allowed processing is that it can exploit the parallelism inherent to easily overlap kernel computation with data trans- in the pipeline. For example, the execution of the stages fer between the main memory and the video memory. can be overlapped with each other to exploit task par- To maximize the e±ciency of this overlap, our middle- allelism. Furthermore, di®erent stream elements can be ware performs out-of-order execution of commands such simultaneously processed to exploit data parallelism. as kernel invocations and data transfers. This run-time One of the stream architecture that bene¯t from capability can be used by just replacing the original the advantages mentioned above is the graphics pro- CUDA API calls with our API calls. We have applied cessing unit (GPU), originally designed for acceleration the middleware to a practical application to understand of graphics applications. -

AMD Accelerated Parallel Processing Opencl Programming Guide
AMD Accelerated Parallel Processing OpenCL Programming Guide November 2013 rev2.7 © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Accelerated Parallel Processing, the AMD Accelerated Parallel Processing logo, ATI, the ATI logo, Radeon, FireStream, FirePro, Catalyst, and combinations thereof are trade- marks of Advanced Micro Devices, Inc. Microsoft, Visual Studio, Windows, and Windows Vista are registered trademarks of Microsoft Corporation in the U.S. and/or other jurisdic- tions. Other names are for informational purposes only and may be trademarks of their respective owners. OpenCL and the OpenCL logo are trademarks of Apple Inc. used by permission by Khronos. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (“AMD”) products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel or other- wise, to any intellectual property rights is granted by this publication. Except as set forth in AMD’s Standard Terms and Conditions of Sale, AMD assumes no liability whatsoever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD’s products are not designed, intended, authorized or warranted for use as compo- nents in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD’s product could create a situation where personal injury, death, or severe property or envi- ronmental damage may occur. -

Eakta Jain A. Professional Preparation: B. Appointments: C. Publications
Eakta Jain Department of Computer and Information Science and Engineering University of Florida Phone: (352) 562-3979 E-mail: [email protected] Webpage: jainlab.cise.ufl.edu A. Professional Preparation: Indian Institute of Technology Kanpur, India B.Tech. (Electrical Engineering) 2006 Carnegie Mellon University M.S. (Robotics) 2010 Carnegie Mellon University Ph.D. (Robotics) 2012 B. Appointments: 02/14 – present Assistant Professor, Department of Computer and Information Science and Engi- neering, University of Florida, Gainesville, FL 12/12-02/14 Member of Technical Staff, Texas Instruments Embedded Signal Processing Lab, Computer Vision Branch, Dallas, TX 07/12-12/12 Systems Software Engineer, Natural User Interfaces Team, Texas Instruments, Dallas, TX 09/11-01/12 Lab Associate, Disney Research Pittsburgh, PA 06/10-08/10 Lab Associate, Disney Research Pittsburgh, PA 06/08-08/08 Lab Associate, Disney Research Pittsburgh, PA 06/07-08/07 Walt Disney Animation Studios, Burbank, CA C. Publications: Is the Motion of a Child Perceivably Different from the Motion of an Adult? Jain, E., Anthony, L., Aloba, A., Castonguay, A., Cuba, I., Shaw, A. and Woodward, J. (2016). ACM Transactions on Applied Percep- tion (TAP), 13(4), Article 22. DOI: 10.1145/2947616 Decoupling Light Reflex from Pupillary Dilation to Measure Emotional Arousal in Videos, Rai- turkar, P., Kleinsmith, A., Keil, A., Banerjee, A., and Jain, E. (2016), ACM Symposium on Ap- plied Perception (SAP), 89-96. Gaze-driven Video Re-editing, Jain, E., Sheikh, Y., Shamir, A. and Hodgins, J., (2015), ACM Transac- tions on Graphics (TOG) (34, p21:1-p21:12). DOI: 10.1145/2699644 3D Saliency from Eye Tracking with Tomography, Ma, B., Jain, E., and Entezari, A. -

Fine-Grained Window-Based Stream Processing on CPU-GPU Integrated
FineStream: Fine-Grained Window-Based Stream Processing on CPU-GPU Integrated Architectures Feng Zhang and Lin Yang, Renmin University of China; Shuhao Zhang, Technische Universität Berlin and National University of Singapore; Bingsheng He, National University of Singapore; Wei Lu and Xiaoyong Du, Renmin University of China https://www.usenix.org/conference/atc20/presentation/zhang-feng This paper is included in the Proceedings of the 2020 USENIX Annual Technical Conference. July 15–17, 2020 978-1-939133-14-4 Open access to the Proceedings of the 2020 USENIX Annual Technical Conference is sponsored by USENIX. FineStream: Fine-Grained Window-Based Stream Processing on CPU-GPU Integrated Architectures Feng Zhang1, Lin Yang1, Shuhao Zhang2;3, Bingsheng He3, Wei Lu1, Xiaoyong Du1 1Key Laboratory of Data Engineering and Knowledge Engineering (MOE), and School of Information, Renmin University of China 2DIMA, Technische Universität Berlin 3School of Computing, National University of Singapore [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract GPU memory via PCI-e before GPU processing, but the low Accelerating SQL queries on stream processing by utilizing bandwidth of PCI-e limits the performance of stream process- heterogeneous coprocessors, such as GPUs, has shown to be ing on GPUs. Hence, stream processing on GPUs needs to be an effective approach. Most works show that heterogeneous carefully designed to hide the PCI-e overhead. For example, coprocessors bring significant performance improvement be- prior works have explored pipelining the computation and cause of their high parallelism and computation capacity. -

Lightsaber: Efficient Window Aggregation on Multi-Core Processors
Research 28: Stream Processing SIGMOD ’20, June 14–19, 2020, Portland, OR, USA LightSaber: Efficient Window Aggregation on Multi-core Processors Georgios Theodorakis Alexandros Koliousis∗ Peter Pietzuch Imperial College London Graphcore Research Holger Pirk [email protected] [email protected] [email protected] [email protected] Imperial College London Abstract Invertible Aggregation (Sum) Non-Invertible Aggregation (Min) 200 Window aggregation queries are a core part of streaming ap- 140 150 Multiple TwoStacks 120 tuples/s) Multiple TwoStacks plications. To support window aggregation efficiently, stream 6 Multiple SoE 100 SlickDeque SlickDeque 80 100 SlideSide SlideSide processing engines face a trade-off between exploiting par- 60 allelism (at the instruction/multi-core levels) and incremen- 50 40 20 tal computation (across overlapping windows and queries). 0 0 Throughput (10 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10 Existing engines implement ad-hoc aggregation and par- # Queries # Queries allelization strategies. As a result, they only achieve high Figure 1: Evaluating window aggregation queries performance for specific queries depending on the window definition and the type of aggregation function. an order of magnitude higher throughput compared to ex- We describe a general model for the design space of win- isting systems—on a 16-core server, it processes 470 million dow aggregation strategies. Based on this, we introduce records/s with 132 µs average latency. LightSaber, a new stream processing engine that balances parallelism and incremental processing when executing win- CCS Concepts dow aggregation queries on multi-core CPUs. -

Efficient Pattern Matching Over Event Streams
Efficient Pattern Matching over Event Streams ∗ Jagrati Agrawal, Yanlei Diao, Daniel Gyllstrom, and Neil Immerman Department of Computer Science University of Massachusetts Amherst Amherst, MA, USA fjagrati, yanlei, dpg, [email protected] ABSTRACT against complex patterns and the events used to match each Pattern matching over event streams is increasingly being pattern are transformed into new events for output. Re- employed in many areas including financial services, RFID- cently, such pattern matching over streams has aroused sig- based inventory management, click stream analysis, and elec- nificant interest in industry [28, 30, 29, 9] due to its wide tronic health systems. While regular expression matching applicability in areas such as financial services [10], RFID- is well studied, pattern matching over streams presents two based inventory management [31], click stream analysis [26], new challenges: Languages for pattern matching over streams and electronic health systems [16]. In financial services, for are significantly richer than languages for regular expression instance, a brokerage customer may be interested in a se- matching. Furthermore, efficient evaluation of these pattern quence of stock trading events that represent a new market queries over streams requires new algorithms and optimiza- trend. In RFID-based tracking and monitoring, applica- tions: the conventional wisdom for stream query processing tions may want to track valid paths of shipments and detect (i.e., using selection-join-aggregation) is inadequate. anomalies such as food contamination in supply chains. In this paper, we present a formal evaluation model that While regular expression matching is a well studied com- offers precise semantics for this new class of queries and a puter science problem [17], pattern matching over streams query evaluation framework permitting optimizations in a presents two new challenges: principled way. -

Parallel Stream Processing with MPI for Video Analytics and Data Visualization
Parallel Stream Processing with MPI for Video Analytics and Data Visualization Adriano Vogel1 [0000−0003−3299−2641], Cassiano Rista1, Gabriel Justo1, Endrius Ewald1, Dalvan Griebler1;3[0000−0002−4690−3964], Gabriele Mencagli2, and Luiz Gustavo Fernandes1[0000−0002−7506−3685] 1 School of Technology, Pontifical Catholic University of Rio Grande do Sul, Porto Alegre - Brazil [email protected] 2 Department of Computer Science, University of Pisa, Pisa - Italy 3 Laboratory of Advanced Research on Cloud Computing (LARCC), Tr^esde Maio Faculty (SETREM), Tr^esde Maio - Brazil Abstract. The amount of data generated is increasing exponentially. However, processing data and producing fast results is a technological challenge. Parallel stream processing can be implemented for handling high frequency and big data flows. The MPI parallel programming model offers low-level and flexible mechanisms for dealing with distributed ar- chitectures such as clusters. This paper aims to use it to accelerate video analytics and data visualization applications so that insight can be ob- tained as soon as the data arrives. Experiments were conducted with a Domain-Specific Language for Geospatial Data Visualization and a Person Recognizer video application. We applied the same stream par- allelism strategy and two task distribution strategies. The dynamic task distribution achieved better performance than the static distribution in the HPC cluster. The data visualization achieved lower throughput with respect to the video analytics due to the I/O intensive operations. Also, the MPI programming model shows promising performance outcomes for stream processing applications. Keywords: parallel programming, stream parallelism, distributed pro- cessing, cluster 1 Introduction Nowadays, we are assisting to an explosion of devices producing data in the form of unbounded data streams that must be collected, stored, and processed in real-time [12]. -

Department of Computer Science and Engineering
Department of Computer Science and Engineering Journals SJR Title ISSN SJR Quartile Country Molecular Systems Biology ISSN 17444292 8.87 Q1 United Kingdom IEEE Transactions on Pattern Analysis and Machine Intelligence ISSN 01628828 7.653 Q1 United States MIS Quarterly: Management Information Systems ISSN 02767783 6.984 Q1 United States Wiley Interdisciplinary Reviews: Computational Molecular Science ISSN 17590884, 17590876 6.715 Q1 United States Foundations and Trends in Machine Learning ISSN 19358237 6.194 Q1 United States IEEE Transactions on Fuzzy Systems ISSN 10636706 5.8 Q1 United States International Journal of Computer Vision ISSN 09205691 5.633 Q1 Netherlands Journal of Supply Chain Management ISSN 15232409 5.343 Q1 United Kingdom Journal of Operations Management ISSN 02726963 5.052 Q1 Netherlands IEEE Transactions on Smart Grid ISSN 19493053 4.784 Q1 United States Bioinformatics ISSN 13674811, 13674803 4.643 Q1 United Kingdom Information Systems Research ISSN 15265536, 10477047 4.397 Q1 United States IEEE Transactions on Evolutionary Computation ISSN 1089778X 4.308 Q1 United States IEEE Transactions on Automatic Control ISSN 00189286 4.238 Q1 United States International Journal of Robotics Research ISSN 02783649 4.184 Q1 United States Briefings in Bioinformatics ISSN 14774054, 14675463 4.086 Q1 United Kingdom SIAM Journal on Optimization ISSN 10526234, 10957189 3.943 Q1 United States IEEE Transactions on Systems, Man and Cybernetics Part B: Cybernetics ISSN 10834419 3.921 Q1 United States Internet and Higher Education ISSN 10967516 -
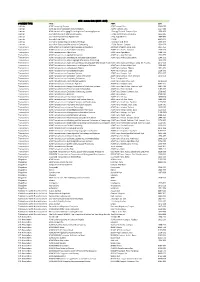
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -
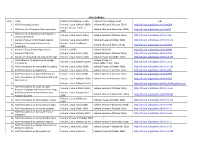
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Cayuga: a General Purpose Event Monitoring System
Cayuga: A General Purpose Event Monitoring System Alan Demers1, Johannes Gehrke1, Biswanath Panda1 ∗ † Mirek Riedewald1, Varun Sharma2 , and Walker White1 1Department of Computer Science, Cornell University 2Computer Science and Engineering, Indian Institute of Technology Delhi ABSTRACT number of concurrent queries registered in the event processing We describe the design and implementation of the Cornell Cayuga system. This is similar to the workload of publish/subscribe sys- System for scalable event processing. We present a query language tems. In comparison, data stream management systems are usually based on Cayuga Algebra for naturally expressing complex event less scalable in the number of queries, capable of supporting only patterns. We also describe several novel system design and im- a small number of concurrent queries. plementation issues, focusing on Cayuga’s query processor, its in- We have designed and built Cayuga, a general-purpose system dexing approach, how Cayuga handles simultaneous events, and its for processing complex events on a large scale [8]. Cayuga supports specialized garbage collector. on-line detection of a large number of complex patterns in event streams. Event patterns are written in a query language based on operators which have well-defined formal semantics. This enables 1. INTRODUCTION Cayuga to perform query-rewrite optimizations. All operators are A large class of both well-established and emerging applications composable, allowing Cayuga to build up complex patterns from can best be described as