ZHOU-THESIS-2018.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

14 Augmenting Data Structures
14 Augmenting Data Structures Some engineering situations require no more than a “textbook” data struc- ture—such as a doubly linked list, a hash table, or a binary search tree—but many others require a dash of creativity. Only in rare situations will you need to cre- ate an entirely new type of data structure, though. More often, it will suffice to augment a textbook data structure by storing additional information in it. You can then program new operations for the data structure to support the desired applica- tion. Augmenting a data structure is not always straightforward, however, since the added information must be updated and maintained by the ordinary operations on the data structure. This chapter discusses two data structures that we construct by augmenting red- black trees. Section 14.1 describes a data structure that supports general order- statistic operations on a dynamic set. We can then quickly find the ith smallest number in a set or the rank of a given element in the total ordering of the set. Section 14.2 abstracts the process of augmenting a data structure and provides a theorem that can simplify the process of augmenting red-black trees. Section 14.3 uses this theorem to help design a data structure for maintaining a dynamic set of intervals, such as time intervals. Given a query interval, we can then quickly find an interval in the set that overlaps it. 14.1 Dynamic order statistics Chapter 9 introduced the notion of an order statistic. Specifically, the ith order statistic of a set of n elements, where i 2 f1;2;:::;ng, is simply the element in the set with the ith smallest key. -

Augmentation
TB Schardl 6.046J/18.410J October 02, 2009 Recitation 4 Augmentation The idea of augmentation is to add information to parts of a standard data structure to allow it to perform more complex tasks. You’ve practiced this concept already on Problem set 2, in order to allow skip lists to support O(log n) time RANK and SELECT methods. We’ll look at a similar prob- lem of creating “order statistic trees” by augmenting 2-3-4 trees to support RANK and SELECT. (The same methodology works for augmenting BSTs.) Order Statistic Trees Problem: Augment an ordinary 2-3-4 tree to support efficient RANK and SELECT-RANK methods without hurting the asymptotic performance of the normal tree operations. Idea: In each node, store the rank of the node in its subtree. An example order statistic tree is shown in Figure 1. 30 8 10 17 37 45 77 3 5 2 4 6 3 7 14 20 24 33 42 50 84 1 2 1 1 2 1 1 1 1 Figure 1: An example order statistic tree. The original values stored in the tree are shown in the top box in a darker gray, while their associated rank values are shown in the bottom box in a lighter gray. RANK,SELECT: We will examine SELECT, noting that the procedure for RANK is similar. Suppose we are searching for the ith order statistic. Starting from the root of the tree, look at the rank associated with the current node, n. If n.rank = i, return n. If n.rank > i, recursively SELECT the ith order statistic from the left child of n. -

Introduction to Algorithms, 3Rd
Thomas H. Cormen Charles E. Leiserson Ronald L. Rivest Clifford Stein Introduction to Algorithms Third Edition The MIT Press Cambridge, Massachusetts London, England c 2009 Massachusetts Institute of Technology All rights reserved. No part of this book may be reproduced in any form or by any electronic or mechanical means (including photocopying, recording, or information storage and retrieval) without permission in writing from the publisher. For information about special quantity discounts, please email special [email protected]. This book was set in Times Roman and Mathtime Pro 2 by the authors. Printed and bound in the United States of America. Library of Congress Cataloging-in-Publication Data Introduction to algorithms / Thomas H. Cormen ...[etal.].—3rded. p. cm. Includes bibliographical references and index. ISBN 978-0-262-03384-8 (hardcover : alk. paper)—ISBN 978-0-262-53305-8 (pbk. : alk. paper) 1. Computer programming. 2. Computer algorithms. I. Cormen, Thomas H. QA76.6.I5858 2009 005.1—dc22 2009008593 10987654321 Index This index uses the following conventions. Numbers are alphabetized as if spelled out; for example, “2-3-4 tree” is indexed as if it were “two-three-four tree.” When an entry refers to a place other than the main text, the page number is followed by a tag: ex. for exercise, pr. for problem, fig. for figure, and n. for footnote. A tagged page number often indicates the first page of an exercise or problem, which is not necessarily the page on which the reference actually appears. ˛.n/, 574 (set difference), 1159 (golden ratio), 59, 108 pr. jj y (conjugate of the golden ratio), 59 (flow value), 710 .n/ (Euler’s phi function), 943 (length of a string), 986 .n/-approximation algorithm, 1106, 1123 (set cardinality), 1161 o-notation, 50–51, 64 O-notation, 45 fig., 47–48, 64 (Cartesian product), 1162 O0-notation, 62 pr. -
Questions for Computer Algorithms
www.YoYoBrain.com - Accelerators for Memory and Learning Questions for computer algorithms Category: Default - (246 questions) Define: symmetric key encryption also known as secret-key encryption, is a cryptography technique that uses a single secret key to both encrypt and decrypt data. Define: cipher text encrypted text Define: asymmetric encryption also known as public-key encryption, relies on key pairs. In a key pair, there is one public key and one private key. Define: hash is a checksum that is unique to a specific file or piece of data. Can be used to verify that a file has not been modified after the hash was generated. Algorithms: describe insertion sort algorithm Start with empty hand and cards face down on the table. Remove one card at a time from the table and insert it into the correct position in left hand. To find the correct position for a card, we compare it with each of the cards already in the hand, from right to left. Algorithms: loop invariant A loop is a statement which allows code to be repeatedly executed;an invariant of a loop is a property that holds before (and after) each repetition Algorithms: selection sort algorithm Sorting n numbers stored in array A by first finding the smallest element of A and exchanging it with A[1], then the second smallest and exchanging it with A[2], etc. Algorithms: merge sort Recursive formula1.) Divide the n-element sequence into 2 sub sequences on n/2 elements each2.) Conquer - sort the 2 sub sequences using merge sort3.) Combine - merge the 2 sorted sub sequences to produce sorted answer. -
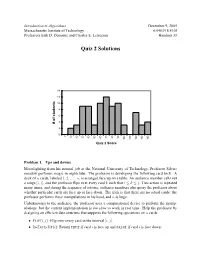
Quiz 2 Solutions
Introduction to Algorithms December 9, 2005 Massachusetts Institute of Technology 6.046J/18.410J Professors Erik D. Demaine and Charles E. Leiserson Handout 33 Quiz 2 Solutions 14 12 s t 10 n e 8 d u t s 6 f o 4 # 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 1 1 1 1 1 Quiz 2 Score Problem 1. Ups and downs Moonlighting from his normal job at the National University of Technology, Professor Silver- meadow performs magic in nightclubs. The professor is developing the following card trick. A deck of n cards, labeled 1; 2; : : : ; n, is arranged face up on a table. An audience member calls out a range [i; j], and the professor flips over every card k such that i ← k ← j. This action is repeated many times, and during the sequence of actions, audience members also query the professor about whether particular cards are face up or face down. The trick is that there are no actual cards: the professor performs these manipulations in his head, and n is huge. Unbeknownst to the audience, the professor uses a computational device to perform the manip ulations, but the current implementation is too slow to work in real time. Help the professor by designing an efficient data structure that supports the following operations on n cards: • FLIP(i; j): Flip over every card in the interval [i; j]. • IS-FACE-UP (i): Return TRUE if card i is face up and FALSE if card i is face down. -

210 Section Handout 6.Pdf
CS106B Handout #21 Spring 2012 May 21, 2012 Section Handout 6 _________________________________________________________________________________________________________ Based on handouts by Jerry Cain Problem One: Listing Words in a Trie Suppose that you have the following struct representing a node in a trie: struct Node { bool isWord; Node* children[26]; }; In class, we saw how to determine whether a given word exists within a trie. What would we do if we wanted to list off all the words in a trie? Write a function void allWordsIn(Node* root, Vector<string>& result); that accepts as input a pointer to the root node of a trie, then populates the Vector argument with a list of all strings contained within the trie. Problem Two: Trie Merging Suppose that you have two tries, each storing some set of words. You are interested in constructing one new trie containing all of the words stored collectively within those two tries. One way to do this would be to use the above allWordsIn function to compute the set of all words in both of the tries, then to insert those words one at a time into a new trie. While this approach works correctly, it is not particularly efficient. A better approach would be to take the two existing tries and rewire the nodes within those tries to combine them together into one single trie. For example, given these two tries: B D L B C L E O O I E A I S G T N N T V T E D E We could splice the nodes together as follows to produce a new trie: - 1 - B C D L I E A O O N V N S T G T D T E E Write a function Node* mergeTries(Node* first, Node* second); that accepts as input pointers to two different tries, merges those tries together, then returns a pointer to the root of the new trie. -

Helios: Huffman Coding Based Lightweight Encryption Scheme for Data Transmission Mazharul Islam1, Novia Nurain2, Mohammad Kaykobad3, Sriram Chellappan4, A
HEliOS: Huffman Coding Based Lightweight Encryption Scheme for Data Transmission Mazharul Islam1, Novia Nurain2, Mohammad Kaykobad3, Sriram Chellappan4, A. B. M. Alim Al Islam5 Bangladesh University of Engineering and Technology, Dhaka, Bangladesh1, 2, 3, 5 University of South Florida, FL, USA4 {mazharul, novia}@cse.uiu.ac.bd1, 2, {kaykobad, alim_razi}@cse.buet.ac.bd3, 5, [email protected] Abstract 1 Introduction Demand for fast data sharing among smart devices is rapidly in- Recent proliferation in data connectivity along with low pricing of creasing. This trend creates challenges towards ensuring essential hardware devices have enabled smart devices with many applica- security for online shared data while maintaining the resource tions. These applications tend to stay coherently synced to a cloud usage at a reasonable level. Existing research studies attempt to server, and enable sharing a diverse range of multimedia and textual leverage compression based encryption for enabling such secure data covering audio, video, emails, sensor data (from environment and fast data transmission replacing the traditional resource-heavy and infrastructure such as rail lines), health data (such as heart rate, encryption schemes. Current compression-based encryption meth- body movements, sleep-wake time and body temperature) etc. Most ods mainly focus on error insensitive digital data formats and prone digital data today are highly sensitive as well as confidential. These to be vulnerable to different attacks. Therefore, in this paper, we pro- applications demand fast and energy efficient security mechanisms pose and implement a new Huffman compression based Encryption to protect their data. scheme using lightweight dynamic Order Statistic tree (HEliOS) In order to implement security mechanisms for shared data, for digital data transmission. -

Minkowski Sum Selection and Finding
Minkowski Sum Selection and Finding Cheng-Wei Luo1, Hsiao-Fei Liu1, Peng-An Chen1, and Kun-Mao Chao1,2,3 1Department of Computer Science and Information Engineering 2Graduate Institute of Biomedical Electronics and Bioinformatics 3Graduate Institute of Networking and Multimedia National Taiwan University, Taipei, Taiwan 106 November 3, 2018 Abstract Let P,Q R2 be two n-point multisets and Ar b be a set of λ inequalities on x and y, where Rλ×2 ⊆ x Rλ ≥ A , r = [y ], and b . Define the constrained Minkowski sum (P Q)Ar≥b as the multiset (p∈+ q) p P, q Q, A(p∈+ q) b . Given P , Q, Ar b, an objective function⊕ f : R2 R, and a{ positive| integer∈ ∈k, the Minkowski≥ } Sum Selection≥problem is to find the kth largest→ objective value among all objective values of points in (P Q)Ar≥b. Given P , Q, Ar b, an objective function f : R2 R, and a real number δ, the Minkowski⊕ Sum Finding problem≥ is to find a point (x∗,y∗) → ∗ ∗ in (P Q)Ar≥b such that f(x ,y ) δ is minimized. For the Minkowski Sum Selection problem⊕ with linear objective| functions,− | we obtain the following results: (1) optimal O(n log n) 2 time algorithms for λ = 1; (2) O(n log n) time deterministic algorithms and expected O(n log n) time randomized algorithms for any fixed λ> 1. For the Minkowski Sum Finding problem with by linear objective functions or objective functions of the form f(x, y) = ax , we construct optimal O(n log n) time algorithms for any fixed λ 1. -

Lecture Notes: Augmenting Data Structures 1 Introduction 2 Dynamic
csce750 — Analysis of Algorithms Fall 2020 — Lecture Notes: Augmenting Data Structures This document contains slides from the lecture, formatted to be suitable for printing or individ- ual reading, and with some supplemental explanations added. It is intended as a supplement to, rather than a replacement for, the lectures themselves — you should not expect the notes to be self-contained or complete on their own. 1 Introduction CLRS 14 In many cases, we can use existing data structures in unexpected ways by augmenting the data they store. Basic steps: 1. Choose an underlying data structure. 2. Determine additional information to maintain in that data structure. 3. Modify the operations of that data structure to maintain that information. 4. Develop new operations using that information. This approach is much more common than “starting from scratch” with a new data structure. Many examples are based on balanced search trees. 2 Dynamic order statistics Suppose we want a data structure that supports these operations: • INSERT(k) • SEARCH(k) • DELETE(k) th • SELECT(i) — find the i smallest element • RANK(v) — how many elements are smaller than the one at node v? This differs from the standard selection problem, because the set is dynamic — elements may be added or deleted. We can form a data structure that supports these operations by augmenting your favorite rotation- based balanced binary search tree data structure. csce750 Lecture Notes: Augmenting Data Structures 1 of 3 3 Order statistic trees In addition to the usual attributes (key, left, right, parent), add a new attribute: • Store the number of nodes in the subtree rooted at v as v.size. -

Instructor's Manual Introduction to Algorithms
Instructor’s Manual by Thomas H. Cormen Clara Lee Erica Lin to Accompany Introduction to Algorithms Second Edition by Thomas H. Cormen Charles E. Leiserson Ronald L. Rivest Clifford Stein The MIT Press Cambridge, Massachusetts London, England McGraw-Hill Book Company Boston Burr Ridge, IL Dubuque, IA Madison, WI New York San Francisco St. Louis Montr´eal Toronto Instructor’s Manual by Thomas H. Cormen, Clara Lee, and Erica Lin to Accompany Introduction to Algorithms, Second Edition by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein Published by The MIT Press and McGraw-Hill Higher Education, an imprint of The McGraw-Hill Companies, Inc., 1221 Avenue of the Americas, New York, NY 10020. Copyright c 2002 by The Massachusetts Institute of Technology and The McGraw-Hill Companies, Inc. All rights reserved. No part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written consent of The MIT Press or The McGraw-Hill Companies, Inc., in- cluding, but not limited to, network or other electronic storage or transmission, or broadcast for distance learning. Contents Revision History R-1 Preface P-1 Chapter 2: Getting Started Lecture Notes 2-1 Solutions 2-16 Chapter 3: Growth of Functions Lecture Notes 3-1 Solutions 3-7 Chapter 4: Recurrences Lecture Notes 4-1 Solutions 4-8 Chapter 5: Probabilistic Analysis and Randomized Algorithms Lecture Notes 5-1 Solutions 5-8 Chapter 6: Heapsort Lecture Notes 6-1 Solutions 6-10 Chapter 7: -

Sorting (1997)
Lecture 8: Sorting (1997) Steven Skiena Department of Computer Science State University of New York Stony Brook, NY 11794–4400 http://www.cs.sunysb.edu/∼skiena Show that any n-node tree can be transformed to any other using O(n) rotations (hint: convert to a right going chain). I will start by showing weaker bounds - that O(n2) and O(n log n) rotations suffice - because that is how I proceeded when I first saw the problem. First, observe that creating a right-going, for t2 path from t1 ¡ and reversing the same construction gives a path from t1 to t2. Note that it will take at most n rotations to make the lowest valued key the root. Once it is root, all keys are to the right of it, so no more rotations need go through it to create a right- going chain. Repeating with the second lowest key, third, etc. gives that O(n2) rotations suffice. Now that if we try to create a completely balanced tree instead. To get the n/2 key to the root takes at most n rotations. Now each subtree has half the nodes and we can recur... N N/2 N/2 N/4 N/4 N/4 N/4 To get a linear algorithm, we must beware of trees like: 7 5 8 6 4 1 9 7 3 2 10 8 2 3 11 9 4 12 1 5 6 The correct answer is that n − 1 rotations suffice to get to a rightmost chain. By picking the lowest node on the rightmost chain which has a left ancestor, we can add one node per rotation to the right most chain! y zz zz y x z x z Initially, the rightmost chain contained at least 1 node, so after n − 1 rotations it contains all n. -

AUGUST 2011 NOTE: • Please Write Your Roll No
ROLL NO . ___________________ ALCCS – NEW SCHEME Code: CT42 Subject: DESIGN AND ANALYSIS OF ALGORITHMS Time: 3 Hours Max. Marks: 100 AUGUST 2011 NOTE: • Please write your Roll No. at the space provided on each page immediately after receiving the Question Paper. • Question 1 is compulsory and carries 28 marks. Answer any FOUR questions from the rest. Marks are indicated against each question. • Parts of a question should be answered at the same place. Q.1 (7 × 4) a. Explain Priority queues. What data structure is used for its implementation? b. Discuss strongly connected components of a graph with example. c. What do you mean by NP complete and NP hard problem? d. Define Undirected Graph with example. e. What is the difference between Internal sorting and External sorting? f. Define AVL Tree with example. g. Define Binary search tree with example. Q.2 a. Give the worst case time and the best case time for the following algorithm “ABC(n)”: ABC(n) { for (i=2 to n/2) { if (n % i ==0) break; } } (6) b. What is the running time of Quick Sort when elements of array A have same value? (4) c. Illustrate the operation of Bucket Sort on array A. A = (0.79,0.13, 0.16, 0.64, 0.39) (8) Q.3 a. Beginning with an empty red black tree insert in succession the following keys (10, 20, 30, 40, 50, 60, 70) (9) b. Augment the above red black tree to support operation on order statistic tree and obtain an element of second rank. Give the algorithm for the same.