Voice Record
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Website Specifications 20130106
Wowza Media Server® 3.6 Technical Specifications Wowza Media Server® software delivers market-leading functionality, reliability, and flexibility for streaming to any screen across a wide range of industries. Streaming Delivery Adobe Flash® RTMP Flash Player Multi-Protocol, Multi (RTMPE, RTMPT, RTMPTE, RTMPS) Adobe® AIR® Client Adobe Flash HTTP Dynamic Streaming (HDS) RTMP-compatible players HDS-compatible players Apple® HTTP Live Streaming (HLS) iPhone®, iPod®, iPad® (iOS 3.0 or later) QuickTime® Player (10.0 or later) Safari® (4.0 or later on Mac OS X version 10.6) Roku® streaming devices and other HLS-compatible players MPEG DASH DASH-264 Compatible Players Microsoft® Smooth Streaming Silverlight® 3 or later RTSP/RTP Quicktime Player VideoLAN VLC media player 3GPP-compatible mobile devices Other RTSP/RTP-compliant players MPEG2 Transport Protocol (MPEG-TS) IPTV set-top boxes Live Streaming RTMP Video: H.264, VP6, Sorenson Spark®, Screen Video v1 & v2 Compatible Encoding Audio: AAC, AAC-LC, HE-AAC, MP3, Speex, NellyMoser ASAO Inputs RTSP/RTP Video: H.264, H.263 Audio: AAC, AAC-LC, HE-AAC, MP3, Speex MPEG-TS Video: H.264 Audio: AAC, AAC-LC, HE-AAC, E-AC-3, AC-3, MP3 ICY (SHOUTcast/Icecast) Audio: AAC, AAC-LC, HE-AAC (aacPlus), v1 & v2, MP3 Support File Formats Video and Audio FLV (Flash Video - .flv) MP4 (QuickTime container - .mp4, .f4v, .mov, .m4v, .mp4a, .3gp, and .3g2) MP3 (.mp3) PIFF (.ism, .ismc, .ismv, .isma) Protocols and Payloads RTSP IETF RFC2326 RTP:H.264 IETF RFC3984, QuickTime Generic RTP Payload Format RTP:AAC IETF RFC3640, -

Wowza Media Server 2
Wowza Media Server 2 The World`s First Unified Media Server Wowza Media Server 2 is not just a high-performance, extensible and a fully interactive Flash media server - it takes the proven Wowza Pro platform beyond Flash by adding H.264support for: • Apple iPhone and iPod touch • Microsoft Silverlight • Apple QuickTime • IPTV Set-top boxes and more Wowza Media Server is the world's first platform that lets you stream from one H.264 encode simultaneously to multiple players and devices. It unifies the multi-protocol, multi-player H.264 streaming into a single workflow , eliminating the need for multiple player-specific encoders and servers. And Wowza Media Server 2 delivers all that at an unbeatable price — 75% less than the single-protocol Adobe Flash Media Interactive Server (FMIS) or Microsoft Windows Server® with IIS . Proclaimed the Best Streaming Innovation of 2009 , and hailed 'the smart choice ' by our customers and the industry, Wowza Media Server 2 makes streaming affordable for organizations of all sizes — from the smallest enterprises to hosting providers and CDNs. Our customers are using Wowza Media Server 2 in many creative ways, in a variety of applications — explore why Wowza Media Server Pro is the smart choice for you too: Industrial Strength High-performance - highly multi-threaded 64-bit architecture Reliable - built from the ground up as an infrastructure-grade server Unified - standard H.264, encoded once, delivered everywhere Scalable - multi-server scalability for live or on-demand Extensible - comprehensive API's, scripting, programming and integration Manageable - standards based, easy to deploy and integrate Cross-platform - runs on Windows, Linux, Mac OSX, Solaris, and more… Economical - unlimited multi-protocol connections at unbeatable prices 80 Finch Ave E.,Toronto, Unit 5, ON, M2N 4R3, Canada • Tel: +1 (416) 479-0480 • 1 (888) 401 3720 • Fax: +1 (416) 848-0716 • Email: [email protected] www.advanceddigital.ca Wowza Media Server 2 H.264/AAC Everywhere One Encode. -

Key Features LG and Android™ Enhancements Connectivity
LG and Android ™ Enhancements • 1080p HD Video Recording – sharing on a larger display 4 • Take Still Shots While Recording Video • Android 4.0.4 Platform (Ice Cream Sandwich) – new • Video Resolutions up to 1920 x 1080 (1280 x 720 default) user-interface and typeface, improved text input, additional security features, and more • Audio Recording – record video with or without sound • Home Screen Folders and Icons – drag and drop icons 1 Camera resolution of 640 x 480 available only on front-facing camera. 2 Available in both camera and video modes. on each other to create folders 3 Available only in video mode. • Home Screen Launch Bar – add up to five apps at a 4 Content must be shared on larger HD display for 1080p playback. time (Exclusive to LG) 2.63" 0.36" • Lock Screen – customize lock screen icons, view Convenience notifications without unlocking the phone, use Face • QuickMemo – create and share personalized memos Unlock, and more by taking screen captures and adding handwritten • Four lock screen icons (Exclusive to LG) drawings or messages • Web Browsing – change from mobile to desktop • Preloaded Apps: Amazon, Gmail ™, Google+ ™, Latitude ™, content, save sites for offline reading, find on page, Lookout ™, Maps, Messenger, Navigation, Play Music, and more Play Store, Search ™, Talk, and YouTube ™ " • Notifications – view thumbnail previews for each item ® 3 • Connect to Social Networks – Google+, Facebook , 4.5" 0 ® . and dismiss notifications one by one Twitter and more 5 • Quick Reply – reply to text messages without opening Connectivity the full Messaging application • T-Mobile 4G Network 1 • Text, Picture, Video, and Voice Messaging † • Portable Wi-Fi ® Hotspot – share a 4G data connection • Combined Inbox for Email Accounts with other compatible wireless devices 2† • Gesture Features – perform common phone functions • Wi-Fi Calling – make calls via your Wi-Fi connection in with simple gestures 4.2 oz. -
Movavi Slideshow Creator User Manual
Movavi Slideshow Creator User Manual Quick Start Guide Table of Contents Quick Start Guide ...........................................................................................................................................................................3 Installing Slideshow Creator ...........................................................................................................................................................6 Trial and Activation .........................................................................................................................................................................7 Getting an Activation Key .........................................................................................................................................................8 Online Activation .......................................................................................................................................................................9 Offline Activation .....................................................................................................................................................................10 User Interface ................................................................................................................................................................................13 Projects ..........................................................................................................................................................................................15 -

Download Spec Sheet
LG and Android ™ Improvements • Beauty Shot – smoothes and brightens skin tones 1 • Face Tracking – automatically finds & focuses on faces • Customizable Icons (including lock screen icon) – • Customizable Shot Mode ,2 Brightness, Scene Mode, ISO, use images/photos for icons ( Exclusive to LG ) White Balance, Color Effect, Timer, & Shutter Sound • Home Screen Launch Bar – add up to seven apps • Zoom: up to 3x (Exclusive to LG ) • Advanced Image Editor – rename, crop, rotate, add • Improved Voice-to-Text – dictate messages and text effects, adjust contrast and color tones, and more appears immediately on screen for verification • Full 1080p HD Video Recording • Home Screen Folders – drag and drop icons on each other to create folders • Video Resolutions: Up to 1920 x 1080, (1440 x 1080 def.) • Lock Screen – Face Unlock; view notifications • Audio Recording – record video with or without sound without unlocking 1 Available on front-facing camera only. 2 3.56" 0.33" • Notifications – view thumbnail previews; dismiss Available on rear-facing camera only. notifications one at a time • Web Browser – change from mobile to desktop Convenience & Productivity content, save sites for offline reading, and more • QuickMemo ™ – create personalized memos on display using a finger or Rubberdium ™ pen, then save or share via social networks, text message, email, and more * " Connectivity 0 5 1 • Notebook – editable book cover and templates with 5" . • Verizon 4G LTE Network 5 support for drawing, text input and multimedia clips • Mobile Hotspot – share a 4G data connection 2 (image, video, map, voice, and date attachments) with up to 10 other devices or a 3G data connection ® with up to 5 other devices † • Polaris Office - PC-like office suite app for working on documents, presentations, and spreadsheets • SmartShare – share media wirelessly to DLNA ®-enabled devices 3 • Clean View – pinch the screen to temporarily hide the icons on the home screen • Bluetooth ® Version 3.0 + HS 5.93 oz. -
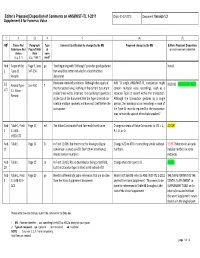
Editor's Proposed Disposition of Comments on ANSI/NIST-ITL 1
Editor’s Proposed Disposition of Comments on ANSI/NIST-ITL 1-2011 Date: 01-27-2013 Document: Version 1.2 Supplement 4 for Forensic Voice 1 2 (3) 4 5 (6) (7) MB1 Clause No./ Paragraph/ Type Comment (justification for change) by the MB Proposed change by the MB Editor’s Proposed Disposition Subclause No./ Figure/Table/ of on each comment submitted Annex Note com- (e.g. 3.1) (e.g. Table 1) ment2 Nob Scope of the Page 9, lines ge Text beginning with “Although” provides good guidance Noted 1 Type‐11 347‐356 but would be better included in a Best Practices Record document Reinstate removed sentences. Although they apply at Add “A single ANSI/NIST‐ITL transaction might SJS Record Type‐ Line 460 T DISCUSS DEFER FOR LATER the transaction level, nothing in the current document contain multiple voice recordings, each as a U/1 11: Voice makes these words incorrect. It is clarifying to point out separate Type‐11 record within the transaction. Record at the top of the document that the Type‐1 record can Although the transaction pertains to a single contain multiple speakers and does not itself define the person, the individual voice recordings in each of transaction. the Type‐11 records required for the transaction may contain the speech of multiple speakers”. Nob Table 1, Field Page 13 ed The Value Constraints P and I are each listed twice Change contents of Value Constraints to STC = U, ACCEPT 2 11.003 ‐ P, I, G, or O VRSO‐STC Nob Table 1 Page 14 Te In Field 11.006, the mnemonic for Analog to Digital Change A2D to ATD or something similar without REJECT Mnemonics already 11 conversion is listed as A2D. -

Wowza Media Server® 3
® Wowza Media Server 3 User’s Guide Copyright © 2006 - 2012 Wowza Media Systems, LLC All rights reserved. Wowza Media Server 3: User’s Guide Version: 3.1 Copyright 2006 – 2012 Wowza Media Systems, LLC http://www.wowza.com Copyright © 2006 - 2012 Wowza Media Systems, LLC All rights reserved. This document is for informational purposes only and in no way shall be interpreted or construed to create any warranties of any kind, either express or implied, regarding the information contained herein. Third Party Information This document contains links to third party websites that are not under the control of Wowza Media Systems, LLC (“Wowza”) and Wowza is not responsible for the content on any linked site. If you access a third party website mentioned in this document, then you do so at your own risk. Wowza provides these links only as a convenience, and the inclusion of any link does not imply that Wowza endorses or accepts any responsibility for the content on third party sites. This document refers to third party software that is not licensed, sold, distributed or otherwise endorsed by Wowza. Please ensure that any and all use of Wowza® software and third party software is properly licensed. Trademarks Wowza, Wowza Media Systems, Wowza Media Server and related logos are either registered trademarks or trademarks of Wowza Media System, LLC in the United States and/or other countries. Adobe and Flash are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Microsoft and Silverlight are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. -

Volume 32 September, 2009 Ttaabbllee Ooff Ccoonntteennttss Welcome from the Editor
Volume 32 September, 2009 TTaabbllee OOff CCoonntteennttss Welcome From The Editor ........................................................................ 3 KDE 4.3 vs Windows 7 Comparison ........................................................ 5 Wiki Wicket: Share A Printer With Windows Without Samba ................ 9 Secure Passwords With openssl ............................................................. 10 Through The Lens: Photo Management Software ................................. 11 How To Set Up Easy Samba File Sharing ............................................... 24 Double Take ............................................................................................... 28 GIMP Tip ..................................................................................................... 28 IRC: The Forgotten Chat Frontier ............................................................ 29 PCLinuxOS on the Acer Aspire One ........................................................ 39 Anagrams ................................................................................................... 41 Forum Foibles ........................................................................................... 42 Behind The Scenes: Neal Brooks ............................................................ 43 Computer Languages A to Z: C/C++ ........................................................ 49 Scripts-R-Us: Repo Speed Test ............................................................... 54 Video File Format Comparison ............................................................... -

Wavelab Elements 7 Help 1
Getting into the details The information in this document is subject to change without notice and does not represent a commitment on the part of Steinberg Media Technologies GmbH. The software described by this document is subject to a License Agreement and may not be copied to other media except as specifically allowed in the License Agreement. No part of this publication may be copied, reproduced or otherwise transmitted or recorded, for any purpose, without prior written permission by Steinberg Media Technologies GmbH. All product and company names are ™ or ® trademarks of their respective owners. Windows XP is a trademark of Microsoft Corporation. Windows Vista and Windows 7 are registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. The Mac logo is a trademark used under license. Macintosh and Power Macintosh are registered trademarks. MP3SURROUND and the MP3SURROUND logo are registered trademarks of Thomson SA, registered in the US and other countries, and are used under license from Thomson Licensing SAS. Release Date: November 29, 2011 © Steinberg Media Technologies GmbH, 2011. All rights reserved. Contents 1 WaveLab Elements 7 Help 1 2 Getting Help 3 2.1 Help menu ........................................ 4 3 Using the interface 5 3.1 About Tool Windows .................................. 6 3.2 Adjusting Envelopes .................................. 7 3.3 Command bars ..................................... 8 3.4 Context menus ..................................... 9 3.5 Docking windows ................................... 9 3.6 Double clicking ..................................... 11 3.7 Dragging operations .................................. 11 3.8 Playback shortcuts ................................... 14 3.9 Select-clicking ..................................... 14 3.10 Shortcut system .................................... 15 3.11 Sliders .......................................... 16 3.12 Status Bar ....................................... -

LG LG870 Specification
• Quiet Mode Sound Setting – specify times to turn Connectivity off all sounds except alarm and media • Sprint’s 4G LTE Network1 • LED Home Button – specified colored and patterned • Bluetooth® Version 4.0 with Unlimited Pairing2 light provides charging status and notifications such • Wi-Fi® Connectivity: 802.11b/g/n as alarms, calendar reminders, new messages, missed events, and others • SmartShare - beam content to other compatible devices via Wi-Fi Direct, DLNA, or Bluetooth Object • Live Zooming – zoom 5x in/out during video playback Push Profile (OPP); play media on a larger display • User-Configurable Shortcuts on the Lock Screen with DLNA, Bluetooth A2DP, or Miracast™ via one • LG Tag+ – activate preset, individual phone profiles convenient, integrated app using NFC technology tags2 • Direct/Android Beam - transfer data by NFC or an • Notebook – create multiple sharable notebooks for 2.71” 0.38” NFC initiated Wi-Fi Direct session where devices can important information with the ability to cut and paste be separated during the transfer pictures, add video, record voice, and much more • Qualcomm® Enhanced Location Service – aids in • Gesture Features – access common phone functions determining device location and helps conserve with simple gestures battery power when using location-based apps • Connect to Social Networks – Google+, Facebook,®3 1 Sprint’s 4G LTE Network not available everywhere. Twitter,®3 and more 2 Depends on device memory. • Customizable Quick Settings Menu for Notifications Panel 4.7" Entertainment • Auto App -

Streaming Copy
DMS Firestream Streaming Multi Platform SD/HD Streaming IPTV main objective to delivery content such as news, sport programs or entertainment programs to audient. Key of success is to use streaming system that supports latest technology to ensure audient coverage. Streaming system is the key to delivery your to where every audient might be. KEY FEATURE Delivery real-time live video SD-HD video quality 24 hour non-stop service with SD video quality streaming can delivered Video stream to at least 2000 concurrent audient or more than 20,000 service subscribers Video on demand deliver on demand video server over IP network to many devices such as IP set top box , Computer PC, Laptop, 3G Mobile phone even Wi Fi devices iPhone/iPad/Android Support advance H.264/AVC video streaming with multirole subsystem : Live from encoder and on demand service Support various type of IP network : MPLS, ADSL, Leased Line, IP-Satellite, GPRS, EDGE, UMTS, LAN even WLAN Optional SAS/RAID configuration for large amount capacity required when archive hours of video Optional EDGE or Load balance configuration for large scale deployment Share video/media/content database over area network using IP protocol Converage computer user support various operation system type like Windows, Mac OS and Linux Full compatibility with video encoder server SD and HD also with portable encoder and mobile encoder STRENGETH High-performance- highly multi threaded 64-bit Java server streaming performance for on demand and live streaming on standard hardware Realiable - built from the ground up as an infrastructure grade server Your objective is to stream multi-protocol media without worries. -

(12) United States Patent (10) Patent No.: US 9.226,038 B2 Mcnamee Et Al
USOO9226038B2 (12) United States Patent (10) Patent No.: US 9.226,038 B2 McNamee et al. (45) Date of Patent: Dec. 29, 2015 (54) SYSTEMS AND METHODS FOR (56) References Cited COMMUNICATING ALIVE EVENT TO USERSUSING THE INTERNET U.S. PATENT DOCUMENTS 5,729,471. A * 3/1998 Jain et al. ...................... 725,131 (71) Applicant: The Roger B and Ann K. McNamee 6,952.221 B1 * 10/2005 Holtz et al. ... 715,723 Trust U/T/A/D, Woodside, CA (US) 7,079,176 B1* 7/2006 Freeman et al. ........... 348,207.1 7,653,924 B1 1/2010 Deng et al. (72) Inventors: Roger McNamee, Menlo Park, CA 8,136,133 B2 * 3/2012 Walker et al. ................... 725/32 8,379,874 B1* 2/2013 Simon ............................. 381/82 (US); Glenn Evans, Menlo Park, CA 2002fOO53078 A1 5, 2002 Holtz et al. (US); Mark Richards Frederick, 2004f0078825 A1 4/2004 Murphy Sandy, UT (US) 2007/0288978 A1 12/2007 PZZurro et al. 2008.01.15181 A1 5/2008 Ryckman et al. (73) Assignee: Roger B. and Ann K. McNamee Trust 2009,0262137 A1* 10, 2009 Walker et al. ................. 345,629 2009, 0290024 A1* 11/2009 Larson et al. .. ... 348.159 U/T/A/D, Woodside, CA (US) 2009/0313659 A1* 12/2009 Samuels ......................... 725/78 (*) Notice: Subject to any disclaimer, the term of this 2015.0015674 A1 1/2015 Weinstock ...................... 348/48 patent is extended or adjusted under 35 * cited by examiner U.S.C. 154(b) by 205 days. (21) Appl. No.: 14/078,298 Primary Examiner — Nnenna Ekpo (74) Attorney, Agent, or Firm — Morgan, Lewis & Bockius (22) Filed: Nov.