A Constructive Arboricity Approximation Scheme
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
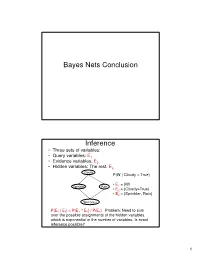
Bayes Nets Conclusion Inference
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -
Arxiv:1908.08938V1 [Cs.DS] 23 Aug 2019 U ≺ W ≺ X ≺ V (Under the Same Assumptions As Above)
Mixed Linear Layouts: Complexity, Heuristics, and Experiments Philipp de Col, Fabian Klute, and Martin N¨ollenburg Algorithms and Complexity Group, TU Wien, Vienna, Austria [email protected],ffklute,[email protected] Abstract. A k-page linear graph layout of a graph G = (V; E) draws all vertices along a line ` and each edge in one of k disjoint halfplanes called pages, which are bounded by `. We consider two types of pages. In a stack page no two edges should cross and in a queue page no edge should be nested by another edge. A crossing (nesting) in a stack (queue) page is called a conflict. The algorithmic problem is twofold and requires to compute (i) a vertex ordering and (ii) a page assignment of the edges such that the resulting layout is either conflict-free or conflict-minimal. While linear layouts with only stack or only queue pages are well-studied, mixed s-stack q-queue layouts for s; q ≥ 1 have received less attention. We show NP-completeness results on the recognition problem of certain mixed linear layouts and present a new heuristic for minimizing conflicts. In a computational experiment for the case s; q = 1 we show that the new heuristic is an improvement over previous heuristics for linear layouts. 1 Introduction Linear graph layouts, in particular book embeddings [1,11] (also known as stack layouts) and queue layouts [8,9], form a classic research topic in graph drawing with many applications beyond graph visualization as surveyed by Dujmovi´cand Wood [5]. A k-page linear layout Γ = (≺; P) of a graph G = (V; E) consists of an order ≺ on the vertex set V and a partition of E into k subsets P = fP1;:::;Pkg called pages. -

Graph Varieties Axiomatized by Semimedial, Medial, and Some Other Groupoid Identities
Discussiones Mathematicae General Algebra and Applications 40 (2020) 143–157 doi:10.7151/dmgaa.1344 GRAPH VARIETIES AXIOMATIZED BY SEMIMEDIAL, MEDIAL, AND SOME OTHER GROUPOID IDENTITIES Erkko Lehtonen Technische Universit¨at Dresden Institut f¨ur Algebra 01062 Dresden, Germany e-mail: [email protected] and Chaowat Manyuen Department of Mathematics, Faculty of Science Khon Kaen University Khon Kaen 40002, Thailand e-mail: [email protected] Abstract Directed graphs without multiple edges can be represented as algebras of type (2, 0), so-called graph algebras. A graph is said to satisfy an identity if the corresponding graph algebra does, and the set of all graphs satisfying a set of identities is called a graph variety. We describe the graph varieties axiomatized by certain groupoid identities (medial, semimedial, autodis- tributive, commutative, idempotent, unipotent, zeropotent, alternative). Keywords: graph algebra, groupoid, identities, semimediality, mediality. 2010 Mathematics Subject Classification: 05C25, 03C05. 1. Introduction Graph algebras were introduced by Shallon [10] in 1979 with the purpose of providing examples of nonfinitely based finite algebras. Let us briefly recall this concept. Given a directed graph G = (V, E) without multiple edges, the graph algebra associated with G is the algebra A(G) = (V ∪ {∞}, ◦, ∞) of type (2, 0), 144 E. Lehtonen and C. Manyuen where ∞ is an element not belonging to V and the binary operation ◦ is defined by the rule u, if (u, v) ∈ E, u ◦ v := (∞, otherwise, for all u, v ∈ V ∪ {∞}. We will denote the product u ◦ v simply by juxtaposition uv. Using this representation, we may view any algebraic property of a graph algebra as a property of the graph with which it is associated. -

Planar Graphs Have Bounded Queue-Number
2019 IEEE 60th Annual Symposium on Foundations of Computer Science (FOCS) Planar Graphs have Bounded Queue-Number Vida Dujmovic´∗, Gwenaël Joret†, Piotr Micek‡, Pat Morin§, Torsten Ueckerdt¶, David R. Wood ∗ School of Computer Science and Electrical Eng., University of Ottawa, Canada ([email protected]) † Département d’Informatique, Université Libre de Bruxelles, Brussels, Belgium ([email protected]) ‡ Faculty of Mathematics and Computer Science, Jagiellonian University, Poland ([email protected]) § School of Computer Science, Carleton University, Ottawa, Canada ([email protected]) ¶ Institute of Theoretical Informatics, Karlsruhe Institute of Technology, Germany ([email protected]) School of Mathematics, Monash University, Melbourne, Australia ([email protected]) Abstract—We show that planar graphs have bounded queue- open whether every graph has stack-number bounded by a number, thus proving a conjecture of Heath, Leighton and function of its queue-number, or whether every graph has Rosenberg from 1992. The key to the proof is a new structural queue-number bounded by a function of its stack-number tool called layered partitions, and the result that every planar graph has a vertex-partition and a layering, such that each [1,2]. part has a bounded number of vertices in each layer, and the Planar graphs are the simplest class of graphs where it is quotient graph has bounded treewidth. This result generalises unknown whether both stack and queue-number are bounded. for graphs of bounded Euler genus. Moreover, we prove that In particular, Buss and Shor [3] first proved that planar every graph in a minor-closed class has such a layered partition graphs have bounded stack-number; the best known upper if and only if the class excludes some apex graph. -

Linear K-Arboricities on Trees
Discrete Applied Mathematics 103 (2000) 281–287 View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Note Linear k-arboricities on trees Gerard J. Changa; 1, Bor-Liang Chenb, Hung-Lin Fua, Kuo-Ching Huangc; ∗;2 aDepartment of Applied Mathematics, National Chiao Tung University, Hsinchu 300, Taiwan bDepartment of Business Administration, National Taichung Institue of Commerce, Taichung 404, Taiwan cDepartment of Applied Mathematics, Providence University, Shalu 433, Taichung, Taiwan Received 31 October 1997; revised 15 November 1999; accepted 22 November 1999 Abstract For a ÿxed positive integer k, the linear k-arboricity lak (G) of a graph G is the minimum number ‘ such that the edge set E(G) can be partitioned into ‘ disjoint sets and that each induces a subgraph whose components are paths of lengths at most k. This paper studies linear k-arboricity from an algorithmic point of view. In particular, we present a linear-time algo- rithm to determine whether a tree T has lak (T)6m. ? 2000 Elsevier Science B.V. All rights reserved. Keywords: Linear forest; Linear k-forest; Linear arboricity; Linear k-arboricity; Tree; Leaf; Penultimate vertex; Algorithm; NP-complete 1. Introduction All graphs in this paper are simple, i.e., ÿnite, undirected, loopless, and without multiple edges. A linear k-forest is a graph whose components are paths of length at most k.Alinear k-forest partition of G is a partition of the edge set E(G) into linear k-forests. The linear k-arboricity of G, denoted by lak (G), is the minimum size of a linear k-forest partition of G. -

Planar Graph Theory We Say That a Graph Is Planar If It Can Be Drawn in the Plane Without Edges Crossing
Planar Graph Theory We say that a graph is planar if it can be drawn in the plane without edges crossing. We use the term plane graph to refer to a planar depiction of a planar graph. e.g. K4 is a planar graph Q1: The following is also planar. Find a plane graph version of the graph. A B F E D C A Method that sometimes works for drawing the plane graph for a planar graph: 1. Find the largest cycle in the graph. 2. The remaining edges must be drawn inside/outside the cycle so that they do not cross each other. Q2: Using the method above, find a plane graph version of the graph below. A B C D E F G H non e.g. K3,3: K5 Here are three (plane graph) depictions of the same planar graph: J N M J K J N I M K K I N M I O O L O L L A face of a plane graph is a region enclosed by the edges of the graph. There is also an unbounded face, which is the outside of the graph. Q3: For each of the plane graphs we have drawn, find: V = # of vertices of the graph E = # of edges of the graph F = # of faces of the graph Q4: Do you have a conjecture for an equation relating V, E and F for any plane graph G? Q5: Can you name the 5 Platonic Solids (i.e. regular polyhedra)? (This is a geometry question.) Q6: Find the # of vertices, # of edges and # of faces for each Platonic Solid. -

Interval Edge-Colorings of Graphs
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2016 Interval Edge-Colorings of Graphs Austin Foster University of Central Florida Part of the Mathematics Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Masters Thesis (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Foster, Austin, "Interval Edge-Colorings of Graphs" (2016). Electronic Theses and Dissertations, 2004-2019. 5133. https://stars.library.ucf.edu/etd/5133 INTERVAL EDGE-COLORINGS OF GRAPHS by AUSTIN JAMES FOSTER B.S. University of Central Florida, 2015 A thesis submitted in partial fulfilment of the requirements for the degree of Master of Science in the Department of Mathematics in the College of Sciences at the University of Central Florida Orlando, Florida Summer Term 2016 Major Professor: Zixia Song ABSTRACT A proper edge-coloring of a graph G by positive integers is called an interval edge-coloring if the colors assigned to the edges incident to any vertex in G are consecutive (i.e., those colors form an interval of integers). The notion of interval edge-colorings was first introduced by Asratian and Kamalian in 1987, motivated by the problem of finding compact school timetables. In 1992, Hansen described another scenario using interval edge-colorings to schedule parent-teacher con- ferences so that every person’s conferences occur in consecutive slots. -

David Gries, 2018 Graph Coloring A
Graph coloring A coloring of an undirected graph is an assignment of a color to each node so that adja- cent nodes have different colors. The graph to the right, taken from Wikipedia, is known as the Petersen graph, after Julius Petersen, who discussed some of its properties in 1898. It has been colored with 3 colors. It can’t be colored with one or two. The Petersen graph has both K5 and bipartite graph K3,3, so it is not planar. That’s all you have to know about the Petersen graph. But if you are at all interested in what mathemati- cians and computer scientists do, visit the Wikipedia page for Petersen graph. This discussion on graph coloring is important not so much for what it says about the four-color theorem but what it says about proofs by computers, for the proof of the four-color theorem was just about the first one to use a computer and sparked a lot of controversy. Kempe’s flawed proof that four colors suffice to color a planar graph Thoughts about graph coloring appear to have sprung up in England around 1850 when people attempted to color maps, which can be represented by planar graphs in which the nodes are countries and adjacent countries have a directed edge between them. Francis Guthrie conjectured that four colors would suffice. In 1879, Alfred Kemp, a barrister in London, published a proof in the American Journal of Mathematics that only four colors were needed to color a planar graph. Eleven years later, P.J. -

Effective and Efficient Dynamic Graph Coloring
Effective and Efficient Dynamic Graph Coloring Long Yuanx, Lu Qinz, Xuemin Linx, Lijun Changy, and Wenjie Zhangx x The University of New South Wales, Australia zCentre for Quantum Computation & Intelligent Systems, University of Technology, Sydney, Australia y The University of Sydney, Australia x{longyuan,lxue,zhangw}@cse.unsw.edu.au; [email protected]; [email protected] ABSTRACT (1) Nucleic Acid Sequence Design in Biochemical Networks. Given Graph coloring is a fundamental graph problem that is widely ap- a set of nucleic acids, a dependency graph is a graph in which each plied in a variety of applications. The aim of graph coloring is to vertex is a nucleotide and two vertices are connected if the two minimize the number of colors used to color the vertices in a graph nucleotides form a base pair in at least one of the nucleic acids. such that no two incident vertices have the same color. Existing The problem of finding a nucleic acid sequence that is compatible solutions for graph coloring mainly focus on computing a good col- with the set of nucleic acids can be modelled as a graph coloring oring for a static graph. However, since many real-world graphs are problem on a dependency graph [57]. highly dynamic, in this paper, we aim to incrementally maintain the (2) Air Traffic Flow Management. In air traffic flow management, graph coloring when the graph is dynamically updated. We target the air traffic flow can be considered as a graph in which each vertex on two goals: high effectiveness and high efficiency. -

Coloring Problems in Graph Theory Kacy Messerschmidt Iowa State University
Iowa State University Capstones, Theses and Graduate Theses and Dissertations Dissertations 2018 Coloring problems in graph theory Kacy Messerschmidt Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/etd Part of the Mathematics Commons Recommended Citation Messerschmidt, Kacy, "Coloring problems in graph theory" (2018). Graduate Theses and Dissertations. 16639. https://lib.dr.iastate.edu/etd/16639 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Graduate Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Coloring problems in graph theory by Kacy Messerschmidt A dissertation submitted to the graduate faculty in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Major: Mathematics Program of Study Committee: Bernard Lidick´y,Major Professor Steve Butler Ryan Martin James Rossmanith Michael Young The student author, whose presentation of the scholarship herein was approved by the program of study committee, is solely responsible for the content of this dissertation. The Graduate College will ensure this dissertation is globally accessible and will not permit alterations after a degree is conferred. Iowa State University Ames, Iowa 2018 Copyright c Kacy Messerschmidt, 2018. All rights reserved. TABLE OF CONTENTS LIST OF FIGURES iv ACKNOWLEDGEMENTS vi ABSTRACT vii 1. INTRODUCTION1 2. DEFINITIONS3 2.1 Basics . .3 2.2 Graph theory . .3 2.3 Graph coloring . .5 2.3.1 Packing coloring . .6 2.3.2 Improper coloring . -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R.