Bibliographic Classification in the Digital Age: Current Trends And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
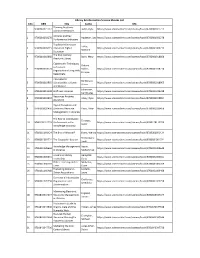
Library N Info SCI Ebooks
Library & Information Science Ebooks List S.No ISBN Title Author URL Planning Academic 1 9780081021712 Bailin, Kylie https://www.sciencedirect.com/science/book/9780081021712 Library Orientations Libraries and Key 2 9780081002278 Appleton, Leo https://www.sciencedirect.com/science/book/9780081002278 Performance Indicators Teaching Information Lokse, 3 9780081009215 Literacy in Higher https://www.sciencedirect.com/science/book/9780081009215 Mariann Education The 21st Century 4 9780081018668 Bolin, Mary https://www.sciencedirect.com/science/book/9780081018668 Academic Library Cybermetric Techniques Orduna- to Evaluate 5 9780081018774 Malea, https://www.sciencedirect.com/science/book/9780081018774 Organizations Using Web- Enrique Based Data International Bordonaro, 6 9780081018965 Librarianship at Home https://www.sciencedirect.com/science/book/9780081018965 Karen and Abroad Johanssen, 7 9780081019238 Staff-Less Libraries https://www.sciencedirect.com/science/book/9780081019238 Carl Gustav Resources Anytime, 8 9780081019894 Litsey, Ryan https://www.sciencedirect.com/science/book/9780081019894 Anywhere Digital Disruption and 9 9780081020456 Electronic Resource Patra, Nihar https://www.sciencedirect.com/science/book/9780081020456 Management in Libraries The Role of Information Tarango, 10 9780128112229 Professionals in the https://www.sciencedirect.com/science/book/9780128112229 Javier Knowledge Economy 11 9780081001424 The End of Wisdom? Evans, Wendy https://www.sciencedirect.com/science/book/9780081001424 Frederiksen, 12 9780081001721 The -

Strategies for Collecting Electronic Resources on the Qur’Anic Researches
International Journal on Quranic Research (IJQR) © 2013 Centre of Quranic Research Vol.3, No. 4, June 2013, Pp. 57-78 (CQR), University of Malaya, Malaysia STRATEGIES FOR COLLECTING ELECTRONIC RESOURCES ON THE QUR’ANIC RESEARCHES Amar Arbaoui, Yasser M. Alginahi & Mohamed Menacer ABSTRACT Electronic dissemination of digital information has benefited from recent advancements in Information and Communication Technologies (ICTs) and dissemination of Islamic digital content in different formats has taken advantage of this rapid progress in technology. Information is available in many formats and on many different applications and devices. However, the online availability of such resources on Qur’an and its sciences is very limited. In this work, digital Qur’an resources available from authentic sources will be used to formulate strategies on how to extract, format, present and make these resources available for researchers in a centralized knowledgebase. The methodology starts with collecting these authentic electronic Islamic resources. Next, resources are classified into their main categories, sub-categories and related categories. Then, the list of metadata for each type of resource is developed. Following this, strategies for efficient dissemination for the different types of digital resources are developed; depending on the format of the files, the metadata is extracted automatically, if possible, otherwise data is entered manually into the knowledgebase. Therefore, the manual entry of data into the knowledgebase for resources having poor or lacking metadata would efficiently help researchers to easily locate the resources they are searching for. Developing these strategies for each type of format could efficiently help in the search process. From the data collected so far, the amount of data gathered shows that books contribute to the highest number of resources available in this area followed by post graduate dissertations, conference papers and journal papers respectively. -

Catalogue and Index
ISSN 2399-9667 Catalogue and Index Periodical of the Cataloguing and Indexing Group, a Special Interest Group of CILIP, the Library and Information Association Editorial September 2017, Issue 188 Contents 3-10 Deborah Lee & Classification is the theme of this bumper issue of Catalogue and Index. Anastasia Kerameos There was a tremendous response to the call for papers, illustrating the importance and interest in classification to the U.K. cataloguing and 11-16 John Akeroyd & metadata community. The classification discussed in this issue comes in many flavours, including the usage of classification schemes, digital tools Aida Slavic for classification, the theory of classification, reclassification, and much 17-20 Vanda Broughton more besides. 21-26 Sean Goddard & The issue starts by exploring the usage of classification schemes. Deborah Lee and Anastasia Kerameos outline the results of a survey Tim Haillay into U.K. classification practices, linked to the recent CILIP CIG workshop “Thinking about classification”. John Ackeroyd and Aida Slavic 27-29 Jane Del-Pizzo discuss how UDC is used, including survey results relating to the U.K. 30-33 Marcin Trzmielewski, and the use of UDC in repositories and as part of catalogue records. Vanda Broughton discusses classification theory and how classification Claudio Gnoli, Marco (and classification schemes) are still a critical part of organizing Lardera, Gaia Heidi information. Pallestrini & Matea Sipic Reclassification is another significant part of cataloguing and 34-37 Nicky Ransom classification life, and this issue is a rich source of information about 38-42 Penny Doulgeris various reclassification projects. Sean Goddard and Tim Haillay describe a reclassification project at the University of Sussex, specifically 43-45 Mary Mitchell focussed on language and literature. -

Theory and Practice. Drexel Univ., Philadelphia, Pa. Graduate
DOCUMENT RESUME F 680 IR 002 925 AUTHOR Painter, Ann F., Ed. TITLE Classification: Theory and Practice. INSTITUTION Drexel Univ., Philadelphia, Pa. Graduate Schoolof Library Science. PUB DATE Oct 74 NOTE 125p. JOURNAL CIT Drexel Library Quarterly; v10 n4 Oct 74 EDRS PRICE MF-$0.76 HC-$5.70 Plus Postage DESCRIPTORS *Classification; Cluster Grouping; Futures (of Society); Information Retrieval; *Library Automation; *Library Science; Library Technical Processes IDENTIFIERS Dewey Decimal Classification; Library of Congress Classification; Universal Decimal Classification ABSTRACT In response to recent trends towards automated bibliographic control, this issue of "Drexel LibraryQuarterly" discusses present day bibliographic classificationschemes and offers some insight into the future. Thisvolume contains essays which: (1) define "classification";(2) provide historical ,background; (3) examine the Dewey Decimal System, the Library of Congress Classification, and the Universal Decimal Classification;(4) discuss research and development of automated systems; and(5) make predictions for the future. (EMH) *********************************************************************** Documents acquired by ERIC include manyinformal unpublished * materials not available from other sources.ERIC makes every effort * * to obtain the best copy available.Nevertheless, items of marginal * * reproducibility are often encounteredand this affects the quality * * of the microfiche and hardcopyreproductions ERIC makes available * * via the ERIC Document ReproductionService -

Reconsidering Library of Congress Classification in US Law Libraries
LAW LIBRARY JOURNAL Vol. 106:1 [2014-5] It’s All Enumerative: Reconsidering Library of Congress Classification in U.S. Law Libraries* Kristen M. Hallows** Ms. Hallows investigates the widespread use of the Library of Congress Classification system in U.S. law libraries and the difficulties it can present in some circumstances. To address these problems, she proposes that smaller law libraries that do not par- ticipate in a bibliographic utility may benefit from an in-house classification scheme. Introduction ¶1 At its most basic level, the human impulse to classify emerges from our strong desire to know what to expect. New things that resemble familiar things need little or no further examination. Quite simply, “we know what to expect of a dog or a banana, since they are similar to dogs and bananas we already know.”1 ¶2 Classification also provides a means of organization. One of the most fun- damental concepts learned in a library and information science program is that we organize to retrieve; therefore, classification is not only helpful but also necessary if we are to benefit from the information we acquire and produce. Further, we may also classify to facilitate browsing and therefore discovery—even in an online envi- ronment such as the library catalog,2 though physical collections are the focus of this article. ¶3 In an increasingly digital world, classification may seem like a quaint notion from the past. In a database, it is unnecessary to store records using any particular system, as long as those records relevant to a search are displayed or sorted in a useful way. -

The Effects of Classification Systems on Management and Access in Selected Elementary School Libraries" (1986)
Old Dominion University ODU Digital Commons Theses and Dissertations in Urban Services - Urban College of Education & Professional Studies Education (Darden) Summer 1986 The ffecE ts of Classification Systems on Management and Access in Selected Elementary School Libraries Ellen L. Miller Old Dominion University Follow this and additional works at: https://digitalcommons.odu.edu/ urbanservices_education_etds Recommended Citation Miller, Ellen L.. "The Effects of Classification Systems on Management and Access in Selected Elementary School Libraries" (1986). Doctor of Philosophy (PhD), dissertation, , Old Dominion University, DOI: 10.25777/2ewx-2p03 https://digitalcommons.odu.edu/urbanservices_education_etds/3 This Dissertation is brought to you for free and open access by the College of Education & Professional Studies (Darden) at ODU Digital Commons. It has been accepted for inclusion in Theses and Dissertations in Urban Services - Urban Education by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. THE EFFECTS OF CLASSIFICATION SYSTEMS ON MANAGEMENT AND ACCESS IN SELECTED ELEMENTARY SCHOOL LIBRARIES by Ellen L. Miller B.S. January 1973, Old Dominion University M.S. August 1976, Old Dominion University A Dissertation Submitted to the Faculty of Old Dominion University in Partial Fulfillment of the Requirements for the Degree of DOCTOR OF PHILOSOPHY URBAN SERVICES OLD DOMINION UNIVERSITY August, 1986 Executive Director ther Chairperson Concentration Director Dean of the Darde Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. ABSTRACT THE EFFECTS OF CLASSIFICATION SYSTEMS ON MANAGEMENT AND ACCESS IN SELECTED ELEMENTARY SCHOOL LIBRARIES Ellen Lowe Miller Old Dominion University, 1986 Director: Dr. Katherine T. Bucher Without an adequate access and delivery system for "easy" books, young children are locked out of the vast literary resources of elementary school libraries. -

Universal Decimal Classification and Colon Classification: Their Mutual Impact
Annals of Library and Information Studies Vol. 62, December 2015, pp. 226-230 Universal Decimal Classification and Colon Classification: Their mutual impact Amitabha Chatterjee Retired Professor & Head, Department of Library & Information Science, Jadavpur University, Kolkata 700032, Email: [email protected] Universal Decimal Classification (UDC), being a predecessor of Colon Classification (CC), had impacts on CC in various ways – directly as well as indirectly. But surprisingly CC too made an impact on UDC in various ways during its revision process. The paper discusses how these two classification schemes have influenced each other in different spheres. Keywords: Universal Decimal Classification; Colon Classification; Faceted Classification; Generalia Class; Indicator digit; Notation; Common isolate; Phase relation; Agglomerate Introduction Ranganathan, however, made continuous efforts over Ranganathan traced the development of several decades to remove rigidities of different kinds bibliographic classification schemes in three that the scheme was suffering from and finally it major periods, viz., Pre-Facet Period (1876-1896), became a freely faceted classification scheme. Transition-to-Facet Period (1897-1932) and Facet Evidently, UDC being a predecessor of CC, had Period (1933-1975). The main achievements of the impacts on CC – both directly as well as indirectly. Transition-to-Facet Period, according to him were: But surprisingly, CC too made an impact on UDC in (1) Venture into the work of arranging in a helpful various ways during its revision process. Mcllwaine sequence the main entries in periodicals – micro has observed that “the scheme (i.e. UDC) exerted a documents embodying micro thought as we call strong influence ….. upon the Colon Classification” them; and that “for some years Ranganathan worked on the (2) Venture into pulling out of some of the subjects UDC while he was living in Switzerland after the certain facets such as Time Facet and Space Second World War, so it was a two-way process”2. -

A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel University of Pennsylvania, [email protected]
University of Pennsylvania ScholarlyCommons Departmental Papers (ASC) Annenberg School for Communication 2018 A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/asc_papers Part of the Communication Commons Recommended Citation Lingel, J. (2018). A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility. Public Culture, 30 (2), 305-327. https://doi.org/10.1215/08992363-4310942 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/asc_papers/707 For more information, please contact [email protected]. A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Disciplines Communication | Social and Behavioral Sciences This journal article is available at ScholarlyCommons: https://repository.upenn.edu/asc_papers/707 A Bookmobile Critique of Institutions, Infrastructure, and Precarious Mobility Jessa Lingel There is a mismatch between what libraries do and how they are perceived, between how they are used by local patrons and how they are used as punch lines in conversations about civic resources and technological change. In the United States, public libraries have been woven into the social and spatial fabric of neighborhood life, whether urban, suburban, or rural, and they enjoy immense popularity: According to a 2014 study from the Pew Research Center (2014), 54 percent of people in the United States use a public library each year, 72 percent of people live in a household with a regular library user, and libraries are viewed as important community resources by 91 percent of people. As library historian Wayne Wiegand (2011) has repeatedly pointed out, there are more public libraries in the United States than there are McDonald’s. -

The Colon Classification: a Few Considerations on Its Future
Annals of Library and Information Studies Vol. 62, December 2015, pp. 231-238 The Colon Classification: A few considerations on its future K. S. Raghavan Visiting Scientist, Centre for Knowledge Analytics & Ontological Engineering (KAnOE), PES University, Bangalore, and Member-Secretary, Sarada Ranganathan Endowment for Library Science, E-mail: [email protected] The article highlights the efforts and plans of Sarada Ranganathan Endowment for Library Science for revival of CC. Presents a brief history of the Scheme and explains is features. Discusses areas needing revamping for continual revision and existence of CC. Also seeks feedback from LIS professionals on the revision of the Scheme. Keywords: Colon Classification; Isolate ideas Introduction Prolegomena was published in 1957 which was hailed Among the several seminal contributions of by Berwick Sayers as the “most precise, theoretical, Dr. S. R. Ranganathan, Colon Classification , first practical and comparative exposition of classification published in 1933, and the Prolegomena stand out. theory …. intensely original”. 1 A third edition of The origins of the Colon Classification scheme lay in Prolegomena has also been published. The Ranganathan’s dissatisfaction with the library development of CC has been based on the theory classification schemes of the times when he was a expounded in the Prolegomena . student at the University of London. Ranganathan found that the structure of Dewey Decimal Editions of CC Classification was not flexible enough for expansion During the life time of Ranganathan, CC saw six and for accommodating new developments in the editions, a rate of revision matched by no other universe of ideas / subjects. He hit upon the idea of general classification scheme except Dewey Decimal structuring subjects ‘bottom-up ’ within each Basic Classification (DDC). -

How to Cite Complete Issue More Information About This
Transinformação ISSN: 2318-0889 Pontifícia Universidade Católica de Campinas FERREIRA, Ana Carolina; MACULAN, Benildes Coura Moreira dos Santos; NAVES, Madalena Martins Lopes Ranganathan and the faceted classification theory1 Transinformação, vol. 29, no. 3, 2017, September-December, pp. 279-295 Pontifícia Universidade Católica de Campinas DOI: 10.1590/2318-08892017000300006 Available in: http://www.redalyc.org/articulo.oa?id=384357586006 How to cite Complete issue Scientific Information System Redalyc More information about this article Network of Scientific Journals from Latin America and the Caribbean, Spain and Journal's webpage in redalyc.org Portugal Project academic non-profit, developed under the open access initiative ORIGINAL 279 Ranganathan and the faceted classification theory1 THEORY CLASSIFICATION THE FACETED AND RANGANATHAN ORIGINAL Ranganathan e a teoria da classificação facetada Ana Carolina FERREIRA2 Benildes Coura Moreira dos Santos MACULAN2 Madalena Martins Lopes NAVES3 Abstract The present study contextualizes Ranganathan’s main theoretical contributions to the classification theory and addresses the Five Laws of Library Science. The major milestones in philosophical and bibliographic classifications are presented to show that the classification system has evolved from purely philosophical schemes, which were focused on the systematization of knowledge, into modern bibliographic classification systems. Facet analysis is considered a contribution to the classification process since it allows the use of an approach that encompasses different points of view of the same subject, as opposed to the enumerative systems. This article also discusses Ranganathan’s five fundamental categories, known as Personality, Matter, Energy, Space and Time, and points out to criticism of this form of categorization in the literature. The Spiral of Scientific Method and the Spiral Model of Development of subjects are presented; the latter is the meta-model of the former. -

Libraries in Secondary Schools
Australian Council for Educational Research (ACER) ACEReSearch Information Management Cunningham Library 1945 Libraries in secondary schools: a report on the libraries of secondary schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian Institute of Librarians (Victorian Branch) Frank G. Kirby Follow this and additional works at: https://research.acer.edu.au/information_management Part of the Educational Assessment, Evaluation, and Research Commons, Library and Information Science Commons, and the Secondary Education Commons Recommended Citation Kirby, Frank G. (1945). Libraries in secondary schools: a report on the libraries of secondary schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian Institute of Librarians (Victorian Branch) This Book is brought to you by the Cunningham Library at ACEReSearch. It has been accepted for inclusion in Information Management by an authorized administrator of ACEReSearch. For more information, please contact [email protected]. LIBRARIES IN SECONDARY SCHOOLS A Report on the Libraries of Secondary Schools in Victoria, with suggestions for a post-war plan for school libraries prepared for the Australian lnstitutp of Librarians ( Victorian Branch) by FRANK G. KIRBY, M.A. (Librarian, Scotch College, Melbourne; Member of the A.l.L.; formerly of the Public Library. of Victoria.) MELBOURNE UNIVERSITY PRESS 1945 Publication of this Report was made possible by a grant from the Australian Council for Educational Research From, the collection of Emeritus Professor Bill Connell was a leader in building educational studies in Australian universities during the twentieth century. Margaret Connell worked closely with Bill on a wide range of educational projects over a period of sixty years. -

Guidelines for Subject Access in National Bibliographies Draft 2011, May
IFLA CLASS Guidelines for Subject Access in National Bibliographies Draft 2011, May Guidelines for Subject Access in National Bibliographies IFLA Working Group on Guidelines for Subject Access by National Bibliographic Agencies Draft May 2011 for Worldwide Review 1 IFLA CLASS Guidelines for Subject Access in National Bibliographies Draft 2011, May Contents Preface 1. Introduction 1.1 Subject access in national bibliographies 1.2 IFLA’s Working Group on Guidelines for Subject Access by National Bibliographic Agencies 1.3 Outline of the Guidelines 2. Users of national bibliographies and subject access 2.1 Users of national bibliographies 2.2 Use of subject access in national bibliographies 2.3 Outcome of this review 3. Subject access standards and tools 3.1 Controlled and natural language indexing 3.2 Features of controlled indexing languages 3.3 Importance of standard indexing tools 3.4 Verbal indexing schemes 3.4.1 Subject heading lists 3.4.2 Thesauri 3.4.3 Pre-coordination and post-coordination 3.5 Classification schemes 3.5.1 Dewey Decimal Classification 3.5.2 Universal Decimal Classification 3.5.3 Library of Congress Classification 3.6 Automatic indexing 3.7 Other subject access tools 4. Functionality and interface of national bibliographies 4.1 Presentation of national bibliographies 4.2 General recommendations 4.3 Recommendations for online catalogue functionalities 4.4 Recommendations for online catalogue interfaces 4.5 Recommendations for query 4.6 Recommendations for other features 5. Application scenarios (indexing / access levels) 5.1 Different levels of subject access 5.2 Criteria to decide subject access levels 5.2.1 Characteristics of materials 5.2.2 Users 5.2.3 Other considerations 5.3 Decision matrix 6.