Author Identification in Novels
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LUDLUM, Robert Geboren: New York City, 25 Mei 1927
LUDLUM, Robert Geboren: New York City, 25 mei 1927. Overleden: Naples, Florida, USA, 12 maart 2001 Pseudoniemen: Jonathan Ryder; Michael Shepherd Opleiding: Rectory School, Pomfret, Connecticut; Kent School, Connecticut; Cheshire Academy, Connecticut; Wesleyan University, Middletown, Connecticut, B.A. Fine Arts, 1951. Carrière: Toneel- en televisieacteur vanaf 1952; producer, North Jersey Playhouse, Fort Lee, 1957-1960 en Playhouse-on-the-Mall, Paramus, New Jersey, 1960-1969; freelance schrijver vanaf 1969. Militaire dienst: U.S. Marine Corps, 1945-1947. Familie: getrouwd met Mary Ryducha, 1951; 2 zoons en 1 dochter (foto: Fantastic Fiction) website: www.ludlumbooks.com Detective: Jason Bourne ; Sherlock Holmes; Covert-One , het persoonlijke, supergeheime bureau van de president van Amerika, in de persoon van Jon Smith De latere Poema pockets verschenen zonder ondertitels Jason Bourne: 1. The Bourne Identity 1980 Het Bourne bedrog 1980 Veen ot: Roman van een sinistere misleiding ook verschenen odt: Het Bourne bedrog 2001 Poema Jason Bourne 1 2. The Bourne Supremacy 1986 Het Jason dubbelspel 1986 Luitingh ot: Roman van een verbijsterende intrige ook verschenen odts: Het Jason dubbelspel 2001 Poema Jason Bourne 2 ook verschenen met omslagtitel: The Bourne Supremacy 2004 Luitingh~Sijthoff The Bourne Supremacy met als omslagondertitel: Het Jason dubbelspel 2009 Poema Pocket Jason Bourne 2 Het Bourne dubbelspel 2013 Luitingh~Sijthoff 3. The Bourne Ultimatum 1990 Het Medusa ultimatum 1990 Luitingh~Sijthoff ot: Roman van een strategisch meesterplan ook verschenen odts: Het Medusa ultimatum 2001 Poema Pocket Jason Bourne 3 The Bourne Ultimatum 2009 Poema Pocket Jason Bourne 3 Jason Bourne (door Eric Van Lustbader): 4. The Bourne Legacy 2004 Robert Ludlum’s Het Bourne Testament 2005 Luitingh volledige titel: ook verschenen odt: Robert Ludlum’s Jason Bourne Robert Ludlum’s The Bourne Legacy in The Bourne Legacy (Het Bourne Testament) 2012 Luitingh~Sijthoff 5. -

Star Channels Guide, Nov. 26 – Dec. 2
NOVEMBER 26 - DECEMBER 2, 2017 staradvertiser.com WAVES APART The sons of Ragnar are at war, putting the gains of their father into jeopardy as the unity of the Vikings is fractured. With Floki (Gustaf Skarsgård) now letting the gods guide him, and Lagertha (Katheryn Winnick) dealing with civil unrest and a looming prophecy, it’s understandable why fans are anxious with anticipation for the season 5 premiere of Vikings. Airing Wednesday, Nov. 29, on History. WE’RE LOOKING FOR PEOPLE WHO HAVE SOMETHING TO SAY. Are you passionate about an issue? An event? A cause? R= olelo.org Begin now at olelo.org. ON THE COVER | VIKINGS SEASON 5 A family fractured Ragnar’s sons come to blows quired more land, another wife and increased Mediterranean this season, with trailers his lineage, and now five key sons are set to hinting that a desert storm or two lurks in his in season 5 of ‘Vikings’ become prominent figures in the future. future. The quest to expand is never easy, and Another Viking is also off to explore, though By Kat Mulligan season 4 proved this. Predictions came to he has chosen to let himself be led by the TV Media pass, battle lines were drawn and the leader- gods. Floki’s destiny awaits him on some ship of the Viking people was once again left foreign shore, as early clips show that he will here is a call, a pull deep within that longs fractured, the unity Ragnar sought to achieve make contact with land, though where he’ll for a time of exploration and expansion, knocked asunder. -

The Tristan Betrayal the Tristan Betrayal by Robert Ludlum Synopsis
The Tristan Betrayal The Tristan Betrayal By Robert Ludlum synopsis: Preliminary rating: 4.7Q Two wars, two secrets, one man. 1940: the Nazis are at the height of their power -France is occupied, Britain is enduring the Blitz and is under threat of invasion, America is neutral and Russia is in an uneasy alliance with Germany. Stephen Metcalfe, the youngest son of a prominent American family, is a well-known man about town in occupied Paris. He's also a minor asset in the US's secret intelligence forces in Europe. Through a wild twist of fate, it falls to Metcalfe to instigate a bold plan that may be the only hope for what remains of the free world. Now he must travel to wartime' Moscow to find, and possibly betray, a former lover a fiery ballerina whose own loyalties are in question -in a delicate dance that could destroy all he loves and honours. 1991: the Communist empire is on the verge of collapse. President Gorbachev is a virtual prisoner of his military, and a coup to return to Russia the glories of her past is being hatched by a powerful new cabal. Stephen Metcalfe, now a retired Ambassador, must return to Moscow and finally reveal a secret that has haunted him for the forty years since the fall of Berlin. A secret that might just avert World War III... Also by Robert Ludlum The Janson Directive The Sigma Protocol The Prometheus Deception The Matarese Countdown The Cry of the Halidon The Apocalypse Watch The Road to Omaha The Scorpio Illusion The Bourne Ultimatum The Icarus Agenda The Bourne Supremacy The Aquitaine Progression The Parsifal Mosaic The Bourne Identity The Matarese Circle The Gemini Contenders The Holcroft Covenant The Chancellor Manuscript Page 1 The Tristan Betrayal The Road to Gandolfo The Rhinemann Exchange Trevayne The Matlock Paper The Osterman Weekend The Scarlatti Inheritance THE TRISTAN BETRAYAL ROBERT LUDLU ORION Copyright 2003 by Myn Pyn, LLC All rights reserved The right of Robert Ludlum to be identified as the author of this work has been asserted by him in accordance with the Copyright, Designs and Patents Act, 1988. -
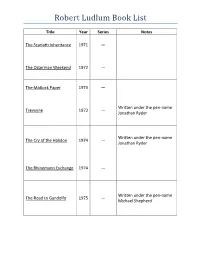
Robert Ludlum Book List
Robert Ludlum Book List Title Year Series Notes The Scarlatti Inheritance 1971 — The Osterman Weekend 1972 — The Matlock Paper 1973 — Written under the pen-name Trevayne 1973 — Jonathan Ryder Written under the pen-name The Cry of the Halidon 1974 — Jonathan Ryder The Rhinemann Exchange 1974 — Written under the pen-name The Road to Gandolfo 1975 — Michael Shepherd Robert Ludlum Book List The Gemini Contenders 1976 — The Chancellor 1977 — Manuscript The Holcroft Covenant 1978 — The Matarese Circle 1979 — Jason The Bourne Identity 1980 Bourne The Parsifal Mosaic 1982 — The Aquitaine Progression 1984 — Jason The Bourne Supremacy 1986 Bourne The Icarus Agenda 1988 — Jason The Bourne Ultimatum 1990 Bourne Robert Ludlum Book List Sequel to The Road to The Road to Omaha 1992 — Gandolfo The Scorpio Illusion 1993 — The Apocalypse Watch 1995 — The Matarese Countdown 1997 — Sequel to The Matarese Circle The Hades Factor 2000 Covert-One Written with Gayle Lynds The Prometheus 2000 — Deception The Cassandra Compact 2001 Covert-One Written with Philip Shelby The Sigma Protocol 2001 — The Paris Option 2002 Covert-One Written with Gayle Lynds The Janson Directive 2002 Paul Janson Robert Ludlum Book List The Altman Code 2003 Covert-One Written by Gayle Lynds The Tristan Betrayal 2003 — Jason The Bourne Legacy 2004 Written by Eric Van Lustbader Bourne The Lazarus Vendetta 2004 Covert-One Written by Patrick Larkin The Moscow Vector 2005 Covert-One Written by Patrick Larkin The Ambler Warning 2005 — The Bancroft Strategy 2006 — Jason The Bourne Betrayal 2007 Written by Eric Van Lustbader Bourne The Arctic Event 2007 Covert-One Written by James H. -

Ebook Download the Gemini Contenders Ebook, Epub
THE GEMINI CONTENDERS PDF, EPUB, EBOOK Robert Ludlum | 411 pages | 01 Apr 1993 | Bantam Doubleday Dell Publishing Group Inc | 9780553282092 | English | New York, United States The Gemini Contenders PDF Book Adrian eventually ends up with the documents. We spend a lot of time on the activities of the father during the war although it has little to do with the main story; then we switch to the twin brothers, one of which starts out as a stiff military type who wants to stop corruption in the army and turns into a bloody murderer in just a few pages. David Lowther. Just as Vittorio arrives, a group of Germans appear and massacre the entire family, Savarone, his other sons, their wives and children. A parchment was taken from a Roman prison cell in the year 65 A. I enjoyed the first half of the Gemini Contenders, the second half, not as much - it totally changed gears. The road straightened and widened and became one with a clearing that stretched perhaps a hundred yards from forest to forest. There are more than million of his books in print, and they have been translated into thirty-two languages. Novels by Robert Ludlum. The action never stops for a second. In the end, it kept dragging on and on and I wished it would end. Books by Robert Ludlum. On the cover of the paperback a NYT reviewer called this book Ludlum's "most ambitious" novel. Father Petride turned to his brother. All Rights Reserved. Aug 27, William rated it it was ok. The Scorpio Illusion. -

Robert Ludlums the Arctic Event: a Covert-One Novel Free
FREE ROBERT LUDLUMS THE ARCTIC EVENT: A COVERT-ONE NOVEL PDF Robert Ludlum,James Cobb | 432 pages | 02 Sep 2010 | Orion Publishing Co | 9781409119920 | English | London, United Kingdom The Arctic Event (Covert-One, #7) by James H. Cobb Robert Ludlum — was an American author of twenty-seven novels between andthe last being issued five years after his death. Ludlum also created the Covert-One series, overseeing the first three novels with Gayle Lynds and Philip Shelby before his death. Robert Ludlum's Robert Ludlums The Arctic Event: A Covert-one Novel Bourne Dominion. Sincepublishing rights in the United States have been held by G. Putnam's Sonstaking over from Grand Central Publishing who held the rights from to The second novel in the Treadstone series, The Treadstone Exileis scheduled for release in February From Wikipedia, the free encyclopedia. Hachette book Group. Archived from the original on Retrieved The New York Times. The Associated Press. Robert Ludlum: A Critical Companion. Westport, Connecticut: Greenwood Press. Chicago Tribune. Fantastic Fiction. Novels by Robert Ludlum. Covert-One series. Categories : Bibliographies by writer Robert Ludlum. Hidden categories: Articles with short description Short description matches Wikidata. Namespaces Article Talk. Views Read Edit View history. Help Learn to edit Community portal Recent changes Upload file. Download as PDF Printable version. Add links. The Scarlatti Inheritance. World Publishing Company. The Osterman Weekend. The Matlock Paper. The Cry of the Halidon. The Rhinemann Exchange. The Road to Gandolfo. The Gemini Contenders. The Chancellor Manuscript. The Holcroft Covenant. Marek Publishers. The Matarese Circle. The Bourne Identity. Jason Bourne 1. The Parsifal Mosaic. -

Newark's Literary Lights
Newark’s Literary Lights Newark’s Literary Lights The Newark Public Library 2016 Edition by Catharine Longendyck Published to mark the 350th Anniversary of the Founding of the City of Newark, NJ 2008 Edition by Sandra L. West 2002 Edition by April L. Kane Originally published on the occasion of the designation of the Newark Public Library as a New Jersey Literary Landmark by the New Jersey Center for the Book on October 2, 2002. Copyright © 2002, 2008, 2016 by The Newark Public Library Introduction ewark has different connotations to different people. America’s N third oldest major city evokes images of a 17th century Puritan settlement, an 18th century farm town, a 19th century industrial and commercial center and a 20th century metropolis dealing with all the complexities of a modern and changing world. Newark has hosted a dozen major immigrant ethnic groups and contributed outstanding men and women to varied fields of endeavor. Its sons and daughters have helped weave part of the American mosaic. From its very beginning Newark has valued the printed word. Robert Treat carried books with him up the Passaic River to that tiny settlement long ago, and a variety of mercantile libraries preceded the 19th century Newark Library Association. The present Newark Public Library was established in 1888 and opened its present structure as one of the City’s first important public buildings in 1901. Soon it was filled with a wealth of information for both the curious and the serious. The purpose of this publication is to bring to you some names of writers associated with Newark who have produced books, short stories, plays, monographs, and poetry as well as periodicals and newspaper columns and articles.