Announcements Hidden Markov Models Filtering in HMM Discrete
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Fusion Localization Method Based on a Robust Extended Kalman Filter and Track-Quality for Wireless Sensor Networks
sensors Article A Fusion Localization Method based on a Robust Extended Kalman Filter and Track-Quality for Wireless Sensor Networks Yan Wang *, Huihui Jie and Long Cheng * Department of Computer and Communication Engineering, Northeastern University, Qinhuangdao 066004, Hebei Province, China * Correspondence: [email protected] (Y.W.); [email protected] (L.C.); Tel.: +86-188-9491-9683 (Y.W.) Received: 11 July 2019; Accepted: 19 August 2019; Published: 21 August 2019 Abstract: As one of the most essential technologies, wireless sensor networks (WSNs) integrate sensor technology, embedded computing technology, and modern network and communication technology, which have become research hotspots in recent years. The localization technique, one of the key techniques for WSN research, determines the application prospects of WSNs to a great extent. The positioning errors of wireless sensor networks are mainly caused by the non-line of sight (NLOS) propagation, occurring in complicated channel environments such as the indoor conditions. Traditional techniques such as the extended Kalman filter (EKF) perform unsatisfactorily in the case of NLOS. In contrast, the robust extended Kalman filter (REKF) acquires accurate position estimates by applying the robust techniques to the EKF in NLOS environments while losing efficiency in LOS. Therefore it is very hard to achieve high performance with a single filter in both LOS and NLOS environments. In this paper, a localization method using a robust extended Kalman filter and track-quality-based (REKF-TQ) fusion algorithm is proposed to mitigate the effect of NLOS errors. Firstly, the EKF and REKF are used in parallel to obtain the location estimates of mobile nodes. -

An Ensemble Kalman Filter for Feature-Based SLAM with Unknown Associations
An Ensemble Kalman Filter for Feature-Based SLAM with Unknown Associations Fabian Sigges, Christoph Rauterberg and Marcus Baum Uwe D. Hanebeck Institute of Computer Science Intelligent Sensor-Actuator-Systems Laboratory (ISAS) University of Goettingen, Germany Institute for Anthropomatics and Robotics Email: ffabian.sigges, [email protected] Karlsruhe Institute of Technology (KIT), Germany [email protected] Email: [email protected] Abstract—In this paper, we present a new approach for solving step of the filter, the posterior is then obtained using the the SLAM problem using the Ensemble Kalman Filter (EnKF). ensemble mean and an estimate of the sample covariance from In contrast to other Kalman filter based approaches, the EnKF the ensemble members. uses a small set of ensemble members to represent the state, thus circumventing the computation of the large covariance matrix Although being established in the geoscientific community, traditionally used with Kalman filters, making this approach a the EnKF has only recently received attention from the track- viable application in high-dimensional state spaces. Our approach ing community [3], [4]. In the case of SLAM, the EnKF is adapts techniques from the geoscientific community such as mostly just applied to specific parts of the whole problem. localization to the SLAM problem domain as well as using For example, in [5] the EnKF is used to generate a suitable the Optimal Subpattern Assignment (OSPA) metric for data association. We then compare the results of our algorithm with an proposal distribution for FastSLAM or in [6] the EnKF realizes extended Kalman filter (EKF) and FastSLAM, showing that our the merging operation on two approximate transformations. -

MASTER's THESIS Performance Comparison of Extended and Unscented Kalman Filter Implementation in INS-GPS Integration
2009:095 MASTER'S THESIS Performance comparison of Extended and Unscented Kalman Filter implementation in INS-GPS integration Joshy Madathiparambil Jose Luleå University of Technology Master Thesis, Continuation Courses Space Science and Technology Department of Space Science, Kiruna 2009:095 - ISSN: 1653-0187 - ISRN: LTU-PB-EX--09/095--SE Lulea University of Technology Performance comparison of Extended and Unscented Kalman Filter implementation in INS-GPS integration Erasmus Mundus Programme SpaceMaster Czech Technical University in Prague Prague,2009 Author: Joshy Madathiparambil Jose Acknowledgements I would like to thank my LTU supervisor Andreas Johanson for his helps and comments. I would like also to thank my supervisors Martin Hromcik at CTU and Martin Orejas, Honeywell Brno for their advice and timely help for completion of this thesis. i Abstract The objective of this thesis is to implement an unscented kalman filter for integrating INS with GPS and to analyze and compare the results with the extended kalman filter approach. In a loosely coupled integrated INS/GPS system, inertial measurements from an IMU (angular velocities and acceler- ations in body frame) are integrated by the INS to obtain a complete navi- gation solution and the GPS measurements are used to correct for the errors and avoid the inherent drift of the pure INS system. The standard approach is to use an extended kalman filter in complementary form to model the er- rors of the INS states and use the GPS measurements to estimate corrections for these errors which are then feedback to the INS. Although the unscented kalman filter is more computational intensive, it is supposed to outperform the extended kalman filter and be more robust to initial errors. -

A More Robust Unscented Transform
A more robust unscented transform James R. Van Zandta aMITRE Corporation, MS-M210, 202 Burlington Road, Bedford MA 01730, USA ABSTRACT The unscented transformation is extended to use extra test points beyond the minimum necessary to determine the second moments of a multivariate normal distribution. The additional test points can improve the estimated mean and variance of the transformed distribution when the transforming function or its derivatives have discontinuities. Keywords: unscented transform, extended Kalman Filter, unscented filter, discontinuous functions, uncertainty distribution 1. INTRODUCTION The representation and estimation of uncertainty is an important part of any tracking application. For linear systems, the Kalman filter1 (KF) maintains a consistent estimate of the first two moments of the state distribution:the mean and the variance. Twice each update, it must estimate the statistics of a random variable that has undergone a transformation—once to predict the future state of the system from the current state (using the process model) and once to predict the observation from the predicted state (using the observation model). The Extended Kalman Filter (EKF)2 allows the Kalman filter machinery to be applied to nonlinear systems. In the EKF, the state distribution is approximated by a Gaussian random variable, and is propagated analytically through the first-order linearization (a Taylor series expansion truncated at the first order) of the nonlinear function. This can introduce substantial errors in the estimates of the mean and covariance of the transformed distribution, which can lead to sub-optimal performance and even divergence of the filter. Julier and Uhlmann have described the unscented transformation (UT) which approximates a probability distri- bution using a small number of carefully chosen test points.3 These test points are propagated through the true nonlinear system, and allow estimation of the posterior mean and covariance accurate to the third order for any nonlinearity. -
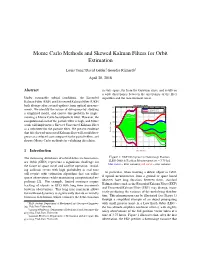
Monte Carlo Methods and Skewed Kalman Filters for Orbit Estimation
Monte Carlo Methods and Skewed Kalman Filters for Orbit Estimation Louis Tonc,∗ David Geller,y Geordie Richardsz April 20, 2018 Abstract in state space, far from the Gaussian class, and results in a wide discrepancy between the uncertainty of the filter Under reasonable orbital conditions, the Extended algorithm and the measurement noise. Kalman Filter (EKF) and Unscented Kalman Filter (UKF) both diverge after several updates from optical measure- POSITION (LVLH) 400 ments. We identify the source of divergence by studying Downrange (filter) a simplified model, and correct this problem by imple- 300 Downrange (monte carlo) menting a Monte Carlo based particle filter. However, the 200 computational cost of the particle filter is high, and future 100 work will implement a Skewed Unscented Kalman Filter 0 as a substitute for the particle filter. We present evidence that this skewed unscented Kalman filter will avoid diver- Position (km) -100 gence at a reduced cost compared to the particle filter, and -200 discuss Monte Carlo methods for validating this claim. -300 -400 0 1 2 3 4 5 6 7 8 9 1 Introduction Time (hours) The increasing abundance of orbital debris in Geostation- Figure 1: EKF Divergence in Downrange Position ary Orbit (GEO) represents a significant challenge for [LEO Orbit & Position Measurement at t = 3.75 hr] blue curve = filter variance, red curve = true variance the future of space travel and satellite operation. Avoid- ing collision events with high probability in real time will require orbit estimation algorithms that can utilize In particular, when tracking a debris object in GEO, sparse observations while maintaining computational ex- if optical measurements from a ground or space based pediency [2]. -

Extended Particle-Aided Unscented Kalman Filter Based on Self-Driving Car Localization
applied sciences Review Extended Particle-Aided Unscented Kalman Filter Based on Self-Driving Car Localization Ming Lin and Byeongwoo Kim * Department of Electrical Engineering, University of Ulsan, 93 Daehak-ro, Nam-gu, Ulsan 44610, Korea; fl[email protected] * Correspondence: [email protected] Received: 8 June 2020; Accepted: 20 July 2020; Published: 22 July 2020 Abstract: The location of the vehicle is a basic parameter for self-driving cars. The key problem of localization is the noise of the sensors. In previous research, we proposed a particle-aided unscented Kalman filter (PAUKF) to handle the localization problem in non-Gaussian noise environments. However, the previous basic PAUKF only considers the infrastructures in two dimensions (2D). This previous PAUKF 2D limitation rendered it inoperable in the real world, which is full of three-dimensional (3D) features. In this paper, we have extended the previous basic PAUKF’s particle weighting process based on the multivariable normal distribution for handling 3D features. The extended PAUKF also raises the feasibility of fusing multisource perception data into the PAUKF framework. The simulation results show that the extended PAUKF has better real-world applicability than the previous basic PAUKF. Keywords: particle-aided unscented Kalman filter; non-Gaussian; sensor fusion; localization; unscented Kalman filter 1. Introduction In recent years, the self-driving car has become the hottest topic in the automotive industry [1–4]. To make a self-driving car drive conveniently and safely, accurate identification of the vehicle’s position is one of the most important parameters. Only if the self-driving car knows where it is can it execute the next decision. -

Constrained State Estimation
1 Constrained State Estimation - A Review Nesrine Amor, Ghulam Rasool and Nidhal C. Bouaynaya . Abstract—Increasingly for many real-world applications in The parametric techniques are based on the extended Kalman signal processing, nonlinearity, non-Gaussianity, and additional filter, unscented Kalman filter, ensemble Kalman filter and constraints are considered while handling dynamic state esti- moving horizon estimation. The non-parametric techniques are mation problems. This paper provides a critical review of the state of the art in constrained Bayesian state estimation for based on Sequential Monte Carlo as known particle filtering. linear and nonlinear state-space systems. Specifically, we provide This paper provides a critical review of constrained a review of unconstrained estimation using Kalman filters for Bayesian state estimation methods, i.e, Kalman filter, extended the linear system, and their extensions for nonlinear state-space Kalman filter, unscented Kalman filter, ensemble Kalman filter, system including extended Kalman filters, unscented Kalman moving horizon estimation and particles filters. filters and ensemble Kalman filters. In addition, we present the particle filters for non linear state space systems and discuss The paper is organized as follows: Section II presents recent advances. Next, we review constrained state estimation the problem statement. Section III reviews the unconstrained using all these filters where we highlighted the advantages and Bayesian state estimation framework. Section IV presents disadvantages of the different recent approaches. the literature available in constrained state estimation using Kalman filter, extended Kalman filter, unscented Kalman fil- I. INTRODUCTION ter, ensemble Kalman filter and moving horizon estimation. Due to physical laws, technological limitations, kinematic Section V introduces a large critical review of the constrained constraints, geometric considerations of many systems, such as particle filtering. -

Adaptive Filter Based on Monte Carlo Method to Improve the Target Tracking in Radar Systems
Adaptive lter based on Monte Carlo method to improve the target tracking in radar systems Khaireddine Zarai ( [email protected] ) Universite de Tunis El Manar Cherif Adnane Universite de Tunis El Manar Research Keywords: Radar, Monte Carlo, Extended KALMAN Filter, Tracking, PF, Random target Posted Date: February 28th, 2020 DOI: https://doi.org/10.21203/rs.2.24844/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Adaptive filter based on Monte Carlo method to improve the target tracking in radar systems Zarai Khaireddine1, Cherif Adnane2 1,2Analysis and signal processing of electrical and energetic systems. Faculty of sciences of Tunis .Tunisia [email protected] , [email protected], [email protected] Abstract The state estimation and tracking of random target is an attractive research problem in radar system. The information received in the radar receiver was reflected by the target, that it is received with many white and Gaussian noise due to the characteristics of the transmission channel and the radar environment. After detection and location scenarios, the radar system must track the target in real time. We aim to improve the state estimation process for too random target at the given instant in order to converge to the true target state and smooth their true path for a long time, it simplifies the process of real-time tracking. In this framework, we propose a new approach based on the numerical methods presented by MONTE CARLO (MC) counterpart the method conventionally used named Extended KALMAN Filter (EKF), we showed that the first are more successful. -

The Iterated Extended Kalman Particle Filter
The Iterated Extended Kalman Particle Filter Li Liang-qun, Ji Hong-bing,Luo Jun-hui School of Electronic Engineering, Xidian University ,Xi’an 710071, China Email: [email protected] Abstract— Particle filtering shows great promise in addressing Simulation results are given in Section 5.Conclusions are a wide variety of non-linear and /or non-Gaussian problem. A presented in Section 6. crucial issue in particle filtering is the selection of the importance proposal distribution. In this paper, the iterated extended 2. PARTICLE FILTER kalman filter (IEKF) is used to generate the proposal distribution. The proposal distribution integrates the latest 2.1 Modeling Assumption observation into system state transition density, so it can match Consider the nonlinear discrete time dynamic system: the posteriori density well. The simulation results show that the new particle filter superiors to the standard particle filter and xkk= fx( k−1,vk−1) (1) the other filters such as the unscented particle filter (UPF), the extended kalman particle filter (PF -EKF), the EKF. zhkk= ( xk,ek) (2) where f :ℜnnxv×ℜ →ℜnxand h :ℜ×nnxeℜ→ℜnz represent the 1. INTRODUCTION k k system evolution function and the measurement model Nonlinear filtering problems arise in many fields n n function. x is the system state at time , z is including statistical signal processing, economics, statistics, xk ∈ℜ k zk ∈ℜ biostatistics, and engineering such as communications, radar n m the measurement vector at time k . vk −1 ∈ Rand eRk ∈ tracking, sonar ranging, target tracking, and satellite represent the process noise and the measurement noise navigation [1-7]. -

Non-Linear State Error Based Extended Kalman Filters with Applications to Navigation Axel Barrau
Non-linear state error based extended Kalman filters with applications to navigation Axel Barrau To cite this version: Axel Barrau. Non-linear state error based extended Kalman filters with applications to navigation. Automatic. Mines Paristech, 2015. English. tel-01247723 HAL Id: tel-01247723 https://hal.archives-ouvertes.fr/tel-01247723 Submitted on 22 Dec 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. INSTITUT DES SCIENCES ET TECHNOLOGIES École doctorale nO84: Sciences et technologies de l’information et de la communication Doctorat européen ParisTech THÈSE pour obtenir le grade de docteur délivré par l’École nationale supérieure des mines de Paris Spécialité “Informatique temps-réel, robotique et automatique” présentée et soutenue publiquement par Axel BARRAU le 15 septembre 2015 Non-linear state error based extended Kalman filters with applications to navigation Directeur de thèse: Silvère BONNABEL Co-encadrement de la thèse: Xavier BISSUEL Jury Brigitte d’ANDREA-NOVEL, Professeur, MINES ParisTech Examinateur Xavier BISSUEL, Expert en navigation inertielle, SAGEM Examinateur Silvère BONNABEL, Professeur, MINES Paristech Examinateur Jay FARRELL, Professeur, UC Riverside Examinateur Pascal MORIN, Professeur, Université Pierre et Marie Curie Rapporteur Christophe PRIEUR, Directeur de recherche, Gipsa-lab, CNRS Rapporteur T Pierre ROUCHON, Professeur, MINES Paristech Président du jury H MINES ParisTech Centre de Robotique È 60 bd Saint-Michel, 75006 Paris, France S E 1 Contents 1 Introduction 5 1.1 Estimating the state of a dynamical system . -

Kalman Filtering and Friends: Inference in Time Series Models
Kalman filtering and friends: Inference in time series models Herke van Hoof slides mostly by Michael Rubinstein Problem overview • Goal – Estimate most probable state at time k using measurement up to time k’ k’<k: prediction k’=k: filtering k’>k: smoothing • Input – (Noisy) Sensor measurements – Known or learned system model (see last lecture) • Many problems require estimation of the state of systems that change over time using noisy measurements on the system Applications • Ballistics • Robotics – Robot localization • Tracking hands/cars/… • Econometrics – Stock prediction • Navigation • Many more… Example: noisy localization Position at t=0 https://img.clipartfest.com Measurement at t=1 t=2 t=3 t=4 t=5 t=6 Example: noisy localization Position at t=0 https://img.clipartfest.com Measurement at t=1 t=2 Smoothing: where was I in the past t=3 t=4 t=5 t=6 Example: noisy localization Position at t=0 https://img.clipartfest.com Measurement at t=1 t=2 Smoothing: where was I in the past t=3 t=4 t=5 Filtering: where am I now t=6 Example: noisy localization Position at t=0 https://img.clipartfest.com Measurement at t=1 t=2 Smoothing: where was I in the past t=3 t=4 t=5 Filtering: where am I now t=6 Prediction: where will I be in the future Today’s lecture • Fundamentals • Formalizing time series models • Recursive filtering • Two cases with optimal solutions • Linear Gaussian models • Discrete systems • Suboptimal solutions Stochastic Processes • Stochastic process – Collection of random variables indexed by some set – Ie. -

1D Kalman Filtering) to Solve This…
Temporal inference and SLAM 16-385 Computer Vision http://www.cs.cmu.edu/~16385/ Spring 2018, Lecture 25 Course announcements • Homework 7 will be posted and will be due on Sunday 6th. - You can use all of your remaining late days for it. • RI Seminar this week: Vladlen Koltun, “Learning to drive”, Friday 3:30-4:30pm. - Very exciting speaker, you should all attend. - Make sure to go early as the room will be packed. - Do you want me to move my office hours so that you can make it to the talk? Overview of today’s lecture • Temporal state models. • Temporal inference. • Kalman filtering. • Extended Kalman filtering. • Mono SLAM. Slide credits Most of these slides were adapted from: • Kris Kitani (16-385, Spring 2017). Temporal state models Represent the ‘world’ as a set of random variables location on the ground plane position in the 3D world position and velocity position, velocity and location of landmarks Object tracking (localization) e.g., location on the ground plane Object location and world landmarks (localization and mapping) e.g., position and velocity of robot and location of landmarks The state of the world changes over time The state of the world changes over time So we use a sequence of random variables: The state of the world changes over time So we use a sequence of random variables: The state of the world is usually uncertain so we think in terms of a distribution How big is the space of this distribution? If the state space is the location on the ground plane is the probability over all possible trajectories through a