A Domain Specific Language Based Approach for Developing Complex Cloud Computing Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nedlite User's Manual
United States Department of Agriculture NEDLite User’s Manual Forest Service Forest Inventory for Palm OS Northeastern Research Station Handheld Computers General Technical Report NE-340 Peter D. Knopp Mark J. Twery Abstract A user’s manual for NEDLite, software that enables collection of forest inventory data on Palm OS handheld computers, with the option of transferring data into NED software for analysis and subsequent prescription development. NEDLite software is included. The Authors PETER D. KNOPP is an information technology specialist with the Northeastern Research Station of the USDA Forest Service. He is stationed in Delaware, OH, and works with the research unit Integrating Social and Biophysical Sciences for Natural Resource Management, located in Burlington, VT. MARK J. TWERY is a supervisory research forester with the Northeastern Research Station of the USDA Forest Service, and Project Leader of the work unit Integrating Social and Biophysical Sciences for Natural Resource Management, located in Burlington, VT. NEDLite was developed by the USDA Forest Service, Northeastern Research Station, and is provided free of charge. Copies may be obtained from the USDA Forest Service, Northeastern Research Station, P.O. Box 968, Burlington, VT 05402-0968. Every effort is made to provide accurate and useful information. However, the U.S. Department of Agriculture, the Forest Service, and their employees and contractors assume no legal liability for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed herein. Neither the U.S. Department of Agriculture, the Forest Service, nor their employees and contractors makes any warranty, express or implied, including the warranties of merchantability and fitness for a particular purpose with respect to NEDLite software or documentation. -

Smartphones 5 V1
Sydney PC User Group HTC’s Smartphones SIG Desire Google’s Nexus One Aug Mtg John Shiel Apple’s iPhone4 Nokia 6710 Nvgtr Agenda Last Mtg History & Current status External Keyboards 6:50pm Coffee break Colour-coded real-time traffic • Green > 80kph • Red < 40kph • Red/Black – very slow, stop/start Latest smartphones 2 1 In Jul Operating Systems • Timeline How Mobile Phones Work Usability – importance Adv mobile applications • Mapping • Music 6:50pm Coffee break Downloadable applications • Monitoring resource usage (to extend battery life) Phone review • HTC Desire • Others 3 1973 - Motorola’s Martin Cooper invents the mobile phone http://www.maximumpc.com/mobile_phone_breakthroughs?page=0,1 4 2 Operating System Timeline 5 Global Smartphone Market Share http://en.wikipedia.org/wiki/Smartphone http://www.gartner.com/it/page.jsp?id=1421013 Smartphone • Has advanced capabilities beyond a typical mobile phone. • Runs complete operating system software that provides a standardized interface and platform for application developers. • Distinct from PDA-based devices running operating systems such as Palm OS or Windows Mobile for Pocket PCs. • Smartphones usually have a standard phone keypad for input, not just a touch-screen for pen input like a PDA. Smartphones usually have larger displays and more Gartner - Android overtaking Apple powerful processors. in 2010 Q2 smartphone sales 6 3 Phones can almost replace a PC Ext. Keyboard is missing piece of puzzle Processor is fast enough Presentation device that plugs into a data projector -
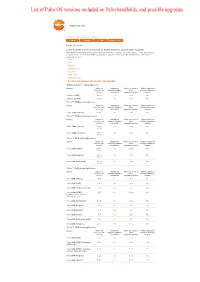
List of Palm OS Versions Included on Palm Handhelds, and Possible Upgrades
List of Palm OS versions included on Palm handhelds, and possible upgrades www.palm.com < Home < Support < Knowledge Library Article ID: 10714 List of Palm OS versions included on Palm handhelds, and possible upgrades Palm OS® is the operating system that drives Palm devices. In some cases, it may be possible to update your device with ROM upgrades or patches. Find your device below to see what's available for you: Centro Treo LifeDrive Tungsten, T|X Zire, Z22 Palm (older) Handspring Visor Questions & Answers about Palm OS upgrades Palm Centro™ smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Centro (AT&T) 5.4.9 No N/A No Centro (Sprint) 5.4.9 No N/A No Treo™ 755p smartphone Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 755p (Sprint) 5.4.9 No N/A No Treo™ 700p smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 700p (Sprint) Garnet Yes N/A No 5.4.9 Treo 700p (Verizon) Garnet No N/A No 5.4.9 Treo™ 680 smartphones Device Palm OS Handheld Palm OS version Palm Desktop & version (out- Upgrade/Update after HotSync Manager of-box) available? upgrade/update update Treo 680 (AT&T) Garnet Yes 5.4.9 No 5.4.9 Treo 680 (Rogers) Garnet No N/A No 5.4.9 Treo 680 (Unlocked) Garnet No N/A No 5.4.9 Treo™ 650 smartphones Device Palm OS -

User Guide Mobile Device Setup
USER GUIDE MOBILE DEVICE SETUP Merit Network, Inc. 1000 Oakbrook Drive, Suite 200, Ann Arbor, Michigan 48104-6794 Phone: (734) 527-5700 Fax: (734) 527-5790 E-mail: [email protected] TABLE OF CONTENTS - MERITMAIL, MOBILE DEVICE SETUP MeritMail Mobile Overview 3 Configuring a Windows Mobile 5 device 4 Configuring a Windows Mobile 6 device 5 Resetting your device 5-6 Why is a full resync necessary Performing a full resync Windows Mobile Palm devices (Versamail) Nokia symbian devices Other devices Setup for specific devices 7-13 Motorola Q Phone Nokia E51 Nokia E61 Nokia E62 Nokia E65 Nokia E90 Palm Treo 650 Palm Treo 680 Palm Treo 700w Palm TX Sony Ericsson P910i Sony Ericsson P990i Cingular 8525 Qtek A9100 Limitations 14 2 MeritMail Mobile Overview MeritMail Mobile is the MeritMail synchronization program that provides ‘over-the-air’ mobile data access (email, contacts, calendar) to devices using the native software / UI installed on the device. It works with Symbian S60/S80, Windows® Mobile (WM5), and Palm smartphones. Devices listed below can be configured to work with MeritMail Mobile out of the box. Many more devices work with MeritMail Mobile natively but a sync plug-in is not bundled with the device (plug-in is available via a 3rd party - DataViz). You enable MeritMail Mobile in the ZCS COS or for individual Accounts. Users configure the device’s soft- ware for MeritMail Mobile similarly to how they configure the device to sync against Microsoft® Exchange. The following may need to be configured: . Server address. Type the fully qualified hostname of the user’s MeritMail Collaboration Suite mailbox server. -

44 43% 25% 37% 14
MobileDevices Q Creating Cases Cases as of 7/1/2010 Total from Last Week Cases Created, Year Ago to Date Average Per Day Now Year Ago Change this week 4.3 1.6 173% last 3 months 2.4 1.4 74% last 12 months 2.2 1.9 16% 118 44 Actual Per Day, Last Week vs Qtrly Average 72 76 10 64 70 70 70 6 58 57 58 8 7 44 47 48 49 Last Week 6 4 3 3 Avg This Q 2 0 09 10 10 09 10 09 09 09 09 09 10 10 09 10 - - - - - - - - - - - - Mon Tue Wed Thu Fri Jul Oct Apr Jun- Jan Jun- Mar Feb Nov Dec Aug Sep May May * latest month is month-to-date The Queue Calendar Age of Open Cases Currently Pending Last 12 Months Last 3 months Last Week 100 100 100 14 50 50 50 11 10 4 2 1 1 1 1 1 2 2 more 10 7 4 1 13 11 9 7 5 3 1 7 6 5 4 3 2 1 months ago weeks ago days ago Time Since Last Activity of Any Kind, in Cases that are currently Open Last 12 Months Last 3 months Last Week 100 100 100 50 50 50 14 14 9 1 4 more 10 7 4 1 13 11 9 7 5 3 1 7 6 5 4 3 2 1 months ago weeks ago days ago Closing Cases Estimated Pending Queue over the last six months more than 7 days 80 70 43% 60 3 to 7 days 50 40 25% 30 < 3 days 20 10 37% 0 (over the last six weeks) 1/7 1/21 2/4 2/18 3/4 3/18 4/1 4/15 4/29 5/13 5/27 6/10 6/24 Net change in Q over six months: -4 Prepared by Rob Smyser 7/1/2010 Page 1 MobileDevices Q Cases as of 7/1/2010 Time Worked SyncML This Month SyncML Cases Created TimeWorked on SyncML cases 4.5 4 SyncML cases are software distributions to end-users. -

Navigate by Phone? Fi, and Bluetooth
E LECTRONICS IR, USB, Wi-Fi, and Blue- tooth. Price: $600-$800. • Palm PDA Palm TX OS: This touchscreen almP device was tested with Palm OS 5.4. Its 16-bit TFT dis- HTC Touch HD Palm Treo 680 Palm TX Garmin play measures 3.9 inches HP iPAQ hx4705 Oregon 400C and has a 320x420-pixel resolution. Interface op- tions include IR, USB, Wi- Navigate by Phone? Fi, and Bluetooth. Price: $100-$200. Navigation software is a big part of Yes, it is possible, with some important caveats. any digital charting system. To examine the functionality of Pocket Navigation ith the hopes of answering viable marine navigation software for charting software, we tested: Wreaders’ questions about the Blackberry and Symbian OS phones. • Active Captain MobileSource: viability of using a “smart phone” or Mac lovers, be patient. The iPhone, Compatible with Windows Mobile and Personal Digital Assistant (PDA) and and all its many sailing applications (in- Palm software, this free software uses the requisite charts and software for cluding navigation) will be the subject modified NOAA raster charts at a cost marine navigation, Practical Sailor of a future article. of $20 per region or $50 for full U.S. recently test-drove a sampling of soft- This technology moves fast, with new coverage. The Active Captain website ware and mobile devices. phones, like Motorola’s Droid, and new features a series of in-depth articles on Pocket devices can be used for on- software appearing on an almost daily the art of phone navigation. board navigation in two different ways. -

Pendragon Forms Version 5.1 Copyright Information Copyright © 2005-2007 Pendragon Software Corporation
Pendragon Forms Version 5.1 Copyright Information Copyright © 2005-2007 Pendragon Software Corporation. All rights reserved. This documentation may be printed by licensee for personal use. Except for the foregoing, no part of this documentation may be reproduced or transmitted in any form by any means, electronic or mechanical, including photocopying or recording on any information storage and retrieval system, without prior written permission from Pendragon Software Corporation. Pendragon Software Pendragon is a registered trademark, and the dragon logo is a trademark of Pendragon Software Corporation. Palm Palm is a registered trademark, and Treo and Zire are trademarks of Palm Inc. PalmSource PalmSource, Inc., PalmSource, Palm OS, Palm Powered, Graffiti, HotSync and certain other trademarks and logos appearing herein, are trademarks or registered trademarks of PalmSource, Inc. or its affiliates or of its licensor, Palm Trademark Holding Company, in the United States, France, Germany, Japan, the United Kingdom, and other countries. All other brands and product names may be trademarks or registered trademarks of their respective holders. Contents 1. Getting Started.................................................................1 Installing Pendragon Forms ...........................................................................................1 Installing Pendragon Forms on a Palm OS Handheld....................................................6 Setting up a Wireless Palm OS Handheld......................................................................7 -

Noviiremote Deluxe for Palm OS ®, Ver 3.5 User's Guide
__________________________________________________________ For Palm OS Devices NoviiRemote turns your handheld computer into a Universal Learning Remote Control! You can control all of your home entertainment equipment with one easy-to-use program. Table of Contents Introduction ...............................................................................................................................2 1. Getting Started......................................................................................................................2 2. Install NoviiRemote Deluxe...................................................................................................3 3. Setup Form ...........................................................................................................................4 4. Remote Screen Form............................................................................................................5 5. Add New Device Wizard .......................................................................................................7 6. Learning IR Codes................................................................................................................8 7. Hot Buttons Form................................................................................................................10 8. Hard Buttons Form .............................................................................................................12 9. Preferences for Multiple Rooms..........................................................................................14 -

Acer Airis Alcatel Alltel Amoi Amoisonic Anextek Apple Arima
Acer 1 n10 1 1 n311 1 1 S100 Liquid 1 1 X960 1 Airis 1 T480 1 Alcatel 1 ELLE No 1 1 1 ELLE No 3 1 1 One Touch 355 1 1 One Touch 556 1 1 One Touch 557 1 1 One Touch 565 1 1 One Touch 708 1 1 One Touch 735i 1 1 One Touch 756 1 1 One Touch 757 1 1 One Touch 800 1 1 One Touch C551 1 1 One Touch C552 1 1 One Touch C635 1 1 One Touch C651 1 1 One Touch C652 1 1 One Touch C750 1 1 One Touch S853 1 1 One Touch V670 1 Alltel 1 PPC-6800 1 Amoi 1 A310 1 1 D85 1 1 D89 1 1 E72 1 1 F8 1 1 F90 1 1 H9 1 1 M636 1 1 N810 1 1 WP-S1 Skypephone 1 Amoisonic 1 9201 1 AnexTek 1 SP230 1 Apple 1 iPad 1 1 iPhone 1 1 iPod Touch 1 Arima 1 2850 1 Asus 1 1210 1 1 Galaxy II 1 1 Galaxy Mini 1 1 J100 1 1 J101 1 1 J102 1 1 M303 1 1 M530w 1 1 M930 1 1 P320 1 1 P505 1 1 P525 1 1 P526 1 1 P527 1 1 P550 1 1 P552 1 1 P735 1 1 P750 1 1 V80 1 AT&T 1 8900 Tilt 1 1 8925 Tilt 1 Audiovox 1 CDM-8450 1 1 CDM-8450SP 1 1 CDM-8455 1 1 CDM-8615 1 1 CDM-8900 1 1 CDM-8910 1 1 CDM-8912 1 1 CDM-8915 1 1 CDM-8920 1 1 CDM-8930 1 1 PM-8912 1 1 PM-8920 1 1 PPC-6600 / PPC-6601 1 1 PPC-6700 1 1 SMT-5600 1 1 VI600 1 BenQ 1 A500 1 1 A5001 1 1 A520 1 1 CL71 1 1 E72 1 1 E81 1 1 M315 1 1 M350 1 1 M580A 1 1 Morpheus 1 1 P30 1 1 P50 1 1 S660C 1 1 S668C 1 1 S670C 1 1 S680C 1 1 S700 1 1 S7001 1 1 S82 1 1 S830C 1 1 U700 1 1 Z2 1 BenQ-Siemens 1 C81 1 1 C81F 1 1 E71 1 1 EF51 1 1 EF81 1 1 EF91 1 1 EL71 1 1 M81 1 1 P51 1 1 S68 1 1 S80 1 1 S81 1 Bird 1 D660 1 1 E810 1 1 S689 1 1 SC01 1 1 SC24 1 1 V007 1 BlackBerry 1 7100g 1 1 7100i 1 1 7100r 1 1 7100t 1 1 7100v 1 1 7100x 1 1 7105t 1 1 7130c 1 1 7130e 1 1 7130g -

Palm- Und Palmos History
Palm- und PalmOS History Palm m100 Palm m105 Palm m125 Palm m130 Palm ZIRE Palm III Palm IIIe Palm IIIx Palm IIIxe Palm IIIc Palm V Palm Vx Palm m500 Palm m505 Palm m515 Palm- und PalmOS History Palm ZIRE 21 Palm ZIRE 31 Palm ZIRE 71 Palm ZIRE 72 Palmone Treo 600 Palm Tungsten T Palm Tungsten C Palm Tungsten T2 Palm Tungsten T3 Palm Tungsten E Palm Livedrive Palm T5 Palm Treo 650 Palm TX Treo 700 – hier W Palm- und PalmOS History Palm und Palm OS History: Hier findet sich eine Übersicht der mit Palm OS ausgestatteten PDAs von den Anfängen bis heute. Markteinführung Handheld 1996 (2. Quartal): Palm Pilot 1000 Der erste Handheld mit Palm OS wurde vom Hersteller US Robotics Anfang 1996 vorgestellt und ab dem 2. Quartal verkauft. In Deutschland war der Pilot 1000 allerdings nicht erhältlich. Die Abteilung "Palm Computing" wurde im Juni 1997 von 3Com übernommen und machte sich im März 2000 selbständig. 1996 (2. Quartal): Palm Pilot 5000 Der Pilot 5000 war der erste in Deutschland verkaufte Palm. Als Hersteller firmierte auch hier US Robotics mit der Palm Computing Abteilung. Im Unterschied zum Pilot 1000 brachte dieses Modell immerhin einen Speicher von 512 kB mit. 1997 (1. Quartal): Palm Pilot Personal US Robotics spendierte dem Nachfolger des Palmpilot 5000 das neue Betriebssystem Palm OS 2. 1997 (1. Quartal): Palm Pilot Professional Im Vergleich zum Pilot Personal bringt der Professional TCP/IP Unterstützung, Mailfunktion und mehr Speicher (1 MB RAM) mit. Zudem war das Modell mit einer Hintergrundbeleuchtung ausgestattet. 1997 (3. Quartal): IBM Workpad (10u) IBM beginnt mit dem Verkauf von Palms unter eigenem Label. -

Anexo D. Codificación De Los Paquetes Snmp
ESCUELA POLITÉCNICA NACIONAL FACULTAD DE INGENIERÍA ELÉCTRICA Y ELECTRÓNICA ESTUDIO, DISEÑO Y DESARROLLO DE UN SOFTWARE DE MONITORIZACIÓN DE RED EN DISPOSITIVOS INALÁMBRICOS (PDA) PARA LA ADMINISTRACIÓN Y GESTIÓN DE RED PROYECTO PREVIO A LA OBTENCIÓN DEL TÍTULO DE INGENIERO EN ELECTRÓNICA Y REDES DE INFORMACIÓN FLORES MEZA JOSÉ ALEJANDRO ([email protected]) JIMÉNEZ HEREDIA JUAN PABLO ([email protected]) DIRECTOR: ING. XAVIER CALDERÓN, MSC. Quito, Julio 2008 DECLARACIÓN Nosotros, FLORES MEZA JOSÉ ALEJANDRO Y JIMÉNEZ HEREDIA JUAN PABLO, declaramos que el trabajo aquí descrito es de nuestra autoría; que no ha sido previamente presentada para ningún grado o calificación profesional; y, que hemos consultado las referencias bibliográficas que se incluyen en este documento. La Escuela Politécnica Nacional, puede hacer uso de los derechos correspondientes a este trabajo, según lo establecido por la Ley de Propiedad Intelectual, por su Reglamento y por la normatividad institucional vigente. _______________________ _______________________ Flores Meza José Alejandro Jiménez Heredia Juan Pablo CERTIFICACIÓN Certifico que el presente trabajo fue desarrollado por Flores Meza José Alejandro y Jiménez Heredia Juan Pablo, bajo mi supervisión. ________________________ Ing. Xavier Calderón, Msc DIRECTOR DEL PROYECTO DEDICATORIA El presente proyecto de titulación se lo dedico a Dios por guiarme y ayudarme en cada instante de mi vida. A mis padres, hermanas y amigos por su incondicional apoyo y orientación. José Flores. DEDICATORIA El presente proyecto de titulación lo dedico a mis padres que con su apoyo esfuerzo y comprensión me supieron llevar siempre adelante. A mi hija que con su llegada a este mundo supo llenarme de amor y fortaleza. Juan Pablo Jiménez AGRADECIMIENTOS Nuestro mas grande agradecimiento a Dios sobre todas las cosas, por darnos vida, salud y entendimiento para desarrollar y concretar satisfactoriamente éste proyecto de titulación. -

IBM Lotus Easysync Pro 4.2.4 Includes New Choices on How Much of Your Personal Information You Access
Software Announcement September 5, 2006 IBM Lotus EasySync Pro 4.2.4 includes new choices on how much of your personal information you access Overview • Choosing how you want to synchronize At a glance With an ever increasing mobile • Reading, replying to, and workforce, it has become more IBM Lotus EasySync Pro 4.2.4 adds: managing your e-mail while away important to meet the productivity from your PC • needs of mobile employees. IBM Broader device support Lotus EasySync Pro is meant to do • Synchronizing your IBM Lotus • Microsoft Windows Mobile 5.0 just that with the help of the new Notes e-mail, calendar, tasks, • features: contacts, and journal with your Pocket PC PDA • Microsoft Windows Mobile 5.0 • Smartphone support with expanded support to • Palm OS 5 devices include Smartphone edition Key prerequisites • Synchronization logic • Refer to Hardware requirements and Palm OS 5 device support improvements Software requirements for the IBM • Synchronization logic Lotus EasySync Pro 4.2.4 • Multi-user install of Lotus Notes improvements prerequisites. V7 support • MSI installer For ordering, contact: • Numerous fixes in data Planned availability dates Your IBM representative, an IBM Business Partner, or the Americas Call Centers at Benefits of IBM Lotus EasySync Pro • September 5, 2006: Electronic 800-IBM-CALL Reference: YE001 include: software delivery • Choosing which information you • September 29, 2006: Media and want to upload to your Lotus documentation Notes desktop and download to your personal data assistants (PDA) This announcement is provided for your information only. For additional information, contact your IBM representative, call 800-IBM-4YOU, or visit the IBM home page at: http://www.ibm.com.