Improving Pronunciation Accuracy of Proper Names with Language Origin Classes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hamilton County (Ohio) Naturalization Records – Surname A
Hamilton County Naturalization Records – Surname A Applicant Age Country of Origin Departure Date Departure Port Arrive Date Entry Port Declaration Dec Date Vol Page Folder Naturalization Naturalization Date Restored Date Aarnink, Geert 33 Hanover Bremen New Orleans T 11/07/1855 13 190 F F Aaron, Louis 37 Russia Hamburg New York T 04/17/1891 T F Abbato, Frank 30 Italy Havre New York T 08/31/1894 21 71 F F Abel, Frederick 27 Brunswick Bremen New Orleans T 04/19/1860 27 69 F F Abel, Jacob 38 England Liverpool New York T 10/11/1882 T F Abel, Jacob 30 England Antwerp New York T 10/14/1895 T F Abel, Joseph 38 Germany Havre New York T 01/10/1883 F F Abel, Michael 25 Prussia Hamburg New York T 07/02/1857 15 122 F F Abeling, Henry 24 Oldenburg Bremen Baltimore T 09/13/1852 25 60 F F Abeling, John Bernard 24 Germany Amsterdam New York T 12/27/1888 T F Abeling, John Clement 22 Germany Amsterdam New York T 12/27/1888 T F Abelowitz, Harris 41 Russia Hamburg New York T 10/12/1892 T F Abig, Philipp 28 Russia Hamburg New York T 10/29/1900 T F Abraham, Albert 41 Germany Hamburg New York F ? T T 10/29/1887 Abraham, David 74 Germany Havre New Orleans F ??/??/1852 28 70 F T 09/??/1854 10/12/1893 Abraham, Emanuel 6 England ? New York F T T 10/11/1888 Abraham, Isidor 30 Germany Hamburg New York T 10/26/1889 T F Abraham, John 17 England ? New York F T T 10/12/1888 Abraham, Joseph 24 Syria Bayruth New York T 07/16/1892 T F Abraham, Morris 47 Germany Bremen New York T 03/06/1897 T F Abraham, Samuel 8 England ? New York F T T 10/23/1886 Abrahart, William 50 England Liverpool New York T 03/02/1886 T F Abrams, Evan 23 Wales Liverpool Philadelphia T 02/24/1853 7 230 F F Abrams, Jacob 57 Poland London New York T 10/20/1888 T F 08/16/1890 Abromovicz, Jacob Romania ? 1/19/1901 ? T 8/24/1903 T F Abt, Christoph 44 Prussia ? New York T 11/16/1887 T F Achtzehn, Chas. -

Kenneth A. Merique Genealogical and Historical Collection BOOK NO
Kenneth A. Merique Genealogical and Historical Collection SUBJECT OR SUB-HEADING OF SOURCE OF BOOK NO. DATE TITLE OF DOCUMENT DOCUMENT DOCUMENT BG no date Merique Family Documents Prayer Cards, Poem by Christopher Merique Ken Merique Family BG 10-Jan-1981 Polish Genealogical Society sets Jan 17 program Genealogical Reflections Lark Lemanski Merique Polish Daily News BG 15-Jan-1981 Merique speaks on genealogy Jan 17 2pm Explorers Room Detroit Public Library Grosse Pointe News BG 12-Feb-1981 How One Man Traced His Ancestry Kenneth Merique's mission for 23 years NE Detroiter HW Herald BG 16-Apr-1982 One the Macomb Scene Polish Queen Miss Polish Festival 1982 contest Macomb Daily BG no date Publications on Parental Responsibilities of Raising Children Responsibilities of a Sunday School E.T.T.A. BG 1976 1981 General Outline of the New Testament Rulers of Palestine during Jesus Life, Times Acts Moody Bible Inst. Chicago BG 15-29 May 1982 In Memory of Assumption Grotto Church 150th Anniversary Pilgrimage to Italy Joannes Paulus PP II BG Spring 1985 Edmund Szoka Memorial Card unknown BG no date Copy of Genesis 3.21 - 4.6 Adam Eve Cain Abel Holy Bible BG no date Copy of Genesis 4.7- 4.25 First Civilization Holy Bible BG no date Copy of Genesis 4.26 - 5.30 Family of Seth Holy Bible BG no date Copy of Genesis 5.31 - 6.14 Flood Cainites Sethites antediluvian civilization Holy Bible BG no date Copy of Genesis 9.8 - 10.2 Noah, Shem, Ham, Japheth, Ham father of Canaan Holy Bible BG no date Copy of Genesis 10.3 - 11.3 Sons of Gomer, Sons of Javan, Sons -
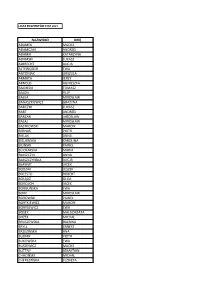
Nazwisko Imię Adamek Maciej Adamczak Andrzej Adamik
LISTA EKSPERTÓW PISF 2021 NAZWISKO IMIĘ ADAMEK MACIEJ ADAMCZAK ANDRZEJ ADAMIK KATARZYNA ADAMSKI ŁUKASZ ALBRECHT ALICJA ALTEWĘGIER EWA ANTONIAK URSZULA ARMATA JERZY ARNOLD AGNIESZKA BAGIŃSKI TOMASZ BAJON FILIP BAŁKA MIROSŁAW BANASZKIEWICZ GRAŻYNA BARCZYK ŁUKASZ BART ANDRZEJ BARZAN JAROSŁAW BASAJ MIROSŁAW BASTKOWSKI MARCIN BERNAŚ PIOTR BIELAK ANNA BIELAWSKA KAROLINA BILIŃSKI PAWEŁ BLICHARSKA MARIA BŁASZCZYK ANNA BŁASZCZYŃSKA ALICJA BŁAWUT JACEK BODZAK LESZEK BOLESTO ROBERT BOŁĄDŹ OLGA BORCUCH JACEK BORGUŃSKA EWA BORK MIROSŁAW BOROWSKI PAWEŁ BORTKIEWICZ MARCIN BORYSEWICZ EWA BOSEK MAŁGORZATA BOŻEK MICHAŁ BRUSZEWSKA BALBINA BRYLL ERNEST BRZEZIŃSKA ANA BUDNIK PIOTR BUKOWSKA EWA BUSZEWICZ MACIEJ BUTTNY SEBASTIAN CHACIŃSKI MICHAŁ CHEREZIŃSKA ELŻBIETA CHMIEL MACIEJ CHOJECKI MIROSŁAW CHRZAN PIOTR CHUDOLIŃSKI MICHAŁ CHUTNIK SYLWIA CIAŁOWICZ ANNA CISSOWSKI ADAM CIUNELIS MARIA CUMAN JAKUB CUSKE MACIEJ CYGANIAK OLGA CYRWUS PIOTR CZACZKOWSKA EWA CZAPLA ZBIGNIEW CZARNECKI MICHAŁ CZERNIEC MICHAŁ CZECH JANUSZ CZECH PAULINA CZEKAJ JAKUB CZERNIAKOWSKA ALINA CZUBAK KACPER DAKOWICZ PRZEMYSŁAW DANOWSKI WOJCIECH DAWID LESZEK DĄBROWSKA DIANA DEMBIŃSKI MIROSŁAW DESKUR MARIA DĘBSKA KINGA DIKTI DARIUSZ DŁUGOSZ LESZEK DŁUŻEWSKA MARIA DOBROWOLSKA ANNA DOKOWICZ LECH DOLISTOWSKI ADAM DOMAGALSKI ZBIGNIEW DOMALEWSKI PIOTR DOMIN MAŁGORZATA DRĄŻEWSKI MAREK A. DROSIO JACEK DRYGAS MACIEJ DUCKI TOMASZ DUDA LIDIA DUDKIEWICZ RAFAŁ DUDZIŃSKI ANDRZEJ DUMAŁA PIOTR DUNIN KINGA DUSZYŃSKI JAKUB DYLEWSKA JOLANTA DYMEK ANNA DZIANOWICZ BEATA DZIDO MARTA DZIEDZIC AGNIESZKA DZIĘCIOŁ PIOTR -
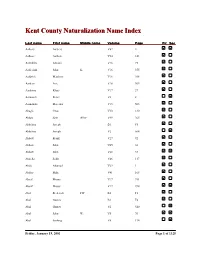
Kent County Naturalization Name Index, Aalbers, A
Kent County Naturalization Name Index Last name First name Middle name Volume Page Fir Sec Aalbers Aalbers V62 4 Aalbers Aalbert V24 141 Aalddriks Antonie V16 75 Aalderink John K. V16 355 Aaldrick Matthew V16 308 Aardem Arie V16 304 Aardema Klaas V17 27 Aarnouds Pieter V6 8 Aarnoudse Marenus V15 503 Abagis Chas V30 130 Abbas Sain Allez V49 265 Abbelma Joseph B1 F5 Abbelma Joseph V2 564 Abbott Frank V27 92 Abbott John V45 36 Abbott John V68 33 Abdella Salik V46 117 Abdo Ahamad V29 1 Abdoo Mike V41 168 Abeaf Moses V17 391 Abeaf Moses V17 394 Abel Frederick FW B1 F1 Abel Gustav B1 F4 Abel Gustav V2 540 Abel John W. V5 70 Abel Ludwig V8 134 Friday, January 19, 2001 Page 1 of 1325 Last name First name Middle name Volume Page Fir Sec Abella Salih V68 85 Abezi Albert V25 76 Aboabsee Theab V74 40 Aboasee Theab V18 150 Abood N. B1 F5 Abood Nemy V3 90 Abraham John V17 381 Abrahamson Charles Y. B7 200 Abram John B1 F1 Abramson Morris B1 F3 Abraursz Abram Peter V27 159 Abromaitis Louis V27 381 Abromaitis Louis V67 90 Absmaier Carl V77 4 Accardi Guiseppe V50 79 Acheson John V16 616 Achille Minciotti V51 142 Achtenhof Jakob V15 145 Achter Jan V17 200 Achterhof Henri B1 F1 Achterhof Johannes V15 500 Achterhof Matheus B1 F1 Achtjes John B7 107 Ackermann Joseph V15 282 Acton John C. B7 222 Adair David G. V15 335 Adair Joseph V15 335 Adalphson Emil V18 197 Friday, January 19, 2001 Page 2 of 1325 Last name First name Middle name Volume Page Fir Sec Adam Frickartz Heinrich V41 279 Adama Jelle V22 176 Adamawiczus Baltris V37 155 Adamczak Peter V38 245 Adamczyk Wladyslaw V35 291 Adams Edward John V24 70 Adams Frank B1 F2 Adams George W. -

Wayne County Death Index, 1934-1939 1 SURNAME FIRST
SURNAME FIRST NAME MIDDLE AGE DATE LOCATION BOX FILE Aaron Phillip W 305 4/21/1938 WD 21 16 Aarons Victoria 149 10/9/1937 EC 13 16 Abbeg Minnie Manning 160 7/13/1938 SM TP 21 8 Abbey Thomas J 180 8/7/1939 HP 30 16 Abbote Vito 165 3/3/1938 NK TP 23 7 Abbott Ada 180 3/2/1938 HP 22 3 Abbott Blanche Maude 152 5/24/1938 HP 22 7 Abbott Chester 155 10/21/1938 WD 21 20 Abbott Ira W 190 8/20/1935 WY 6 11 Abbott Melvin J 102 3/31/1936 WD 9 15 Abbott Roy 142 6/24/1937 WD 15 19 Abbott William C 184 9/28/1936 RM TP 8 14 Abell Ellen 163 2/20/1937 NK TP 17 8 Abelson James H 183 11/27/1938 NK TP 24 12 Aben Augusta 171 11/25/1937 LP 14 15 Abernathy Paul 152 4/3/1939 NK TP 28 16 Abjorson Sven J 148 8/2/1938 GPF 19 16 Abraham Anna 155 4/3/1938 HP 22 5 Abraham Fay 142 9/17/1939 WD 27 22 Abraham Frank Wilson 119 2/18/1937 HP 16 4 Abraham Omar 150 8/2/1938 NK TP 24 1 Abrahamson John 157 12/22/1937 NK TP 18 16 Abram William 175 11/3/1937 NK TP 18 12 Abshagen William 163 2/11/1937 NK TP 17 7 Acciaccafero Dora 159 5/21/1939 NK TP 28 23 Acker Baby 0 4/12/1936 ML 7 27 Acker William H 187 8/12/1939 HP 30 16 Ackerman Jessie W 165 5/31/1939 WD 27 18 Ackerman Leo 174 4/15/1935 NK TP 4 14 Ackermann Joseph M 167 4/15/1936 HP 10 7 Ackersville William 141 10/30/1935 HP 3 19 Ackley Robert D 106 6/28/1936 HP 10 12 Adach John 150 8/17/1939 NK TP 29 7 Adair Baby 0 8/28/1939 WD 27 21 Adair Kristine Ann 105 5/6/1937 WD 15 17 Adamczak Baby 0 7/8/1935 HM 1 29 Adamczak Veronika 301 1/14/1939 HM 31 1 Adamczyk Baby 0 8/3/1937 HM 14 8 Adamczyk Donald 204 2/6/1937 HM 14 2 Adamczyk -

Urzędu Patentowego
URZĄD PATENTOWY RZECZYPOSPOLITEJ POLSKIEJ BIULETYN Urzędu Patentowego Wynalazki i Wzory użytkowe ISSN - 2543 - 5779 • Cena 10,50 zł (w tym 5% VAT) • Warszawa 2017 4 UUrządrząd PPatentowyatentowy RPRP – nana ppodstawieodstawie art.art. 4343 ust.ust. 1,1, art.art. 100100 orazoraz art.art. 2332331 uustawystawy z ddniania 3300 cczerwcazerwca 22000000 rr.. PPraworawo wwłasnościłasności przemysłowejprzemysłowej (Dz.(Dz. U.U. z 20132013 r.r. poz.poz. 14101410 z późniejszymipóźniejszymi zzmianami)mianami) oorazraz rrozporządzeniaozporządzenia PPrezesarezesa RRadyady MMinistrówinistrów wwydanegoydanego nnaa ppodstawieodstawie aart.rt. 9933 oorazraz aart.rt. 110101 uust.st. 2 ppowołanejowołanej ustawyustawy – dokonujedokonuje ogłoszeniaogłoszenia w „„BiuletynieBiuletynie UUrzędurzędu PPatentowego”atentowego” o zzgłoszonychgłoszonych wwynalazkach,ynalazkach, wwzorachzorach uużytkowych.żytkowych. OOgłoszeniagłoszenia o zzgłoszeniachgłoszeniach wwynalazkówynalazków i wwzorówzorów uużytkowychżytkowych ppublikowaneublikowane w BiuletynieBiuletynie ppodaneodane ssąą w uukła-kła- ddziezie klasowymklasowym wedługwedług MiędzynarodowejMiędzynarodowej KlasyfiKlasyfi kacjikacji PatentowejPatentowej i zawierają:zawierają: – ssymbolymbol MiędzynarodowejMiędzynarodowej KKlasyfilasyfi kkacjiacji PPatentowej,atentowej, – nnumerumer zgłoszeniazgłoszenia wwynalazkuynalazku llubub wwzoruzoru uużytkowego,żytkowego, – ddatęatę zzgłoszeniagłoszenia wwynalazkuynalazku llubub wwzoruzoru uużytkowego,żytkowego, – datędatę i kkrajraj uuprzedniegoprzedniego ppierwszeństwaierwszeństwa -
Marriage Certificates
GROOM LAST NAME GROOM FIRST NAME BRIDE LAST NAME BRIDE FIRST NAME DATE PLACE Abbott Calvin Smerdon Dalkey Irene Mae Davies 8/22/1926 Batavia Abbott George William Winslow Genevieve M. 4/6/1920Alabama Abbotte Consalato Debale Angeline 10/01/192 Batavia Abell John P. Gilfillaus(?) Eleanor Rose 6/4/1928South Byron Abrahamson Henry Paul Fullerton Juanita Blanche 10/1/1931 Batavia Abrams Albert Skye Berusha 4/17/1916Akron, Erie Co. Acheson Harry Queal Margaret Laura 7/21/1933Batavia Acheson Herbert Robert Mcarthy Lydia Elizabeth 8/22/1934 Batavia Acker Clarence Merton Lathrop Fannie Irene 3/23/1929East Bethany Acker George Joseph Fulbrook Dorothy Elizabeth 5/4/1935 Batavia Ackerman Charles Marshall Brumsted Isabel Sara 9/7/1917 Batavia Ackerson Elmer Schwartz Elizabeth M. 2/26/1908Le Roy Ackerson Glen D. Mills Marjorie E. 02/06/1913 Oakfield Ackerson Raymond George Sherman Eleanora E. Amelia 10/25/1927 Batavia Ackert Daniel H. Fisher Catherine M. 08/08/1916 Oakfield Ackley Irving Amos Reid Elizabeth Helen 03/17/1926 Le Roy Acquisto Paul V. Happ Elsie L. 8/27/1925Niagara Falls, Niagara Co. Acton Robert Edward Derr Faith Emma 6/14/1913Brockport, Monroe Co. Adamowicz Ian Kizewicz Joseta 5/14/1917Batavia Adams Charles F. Morton Blanche C. 4/30/1908Le Roy Adams Edward Vice Jane 4/20/1908Batavia Adams Edward Albert Considine Mary 4/6/1920Batavia Adams Elmer Burrows Elsie M. 6/6/1911East Pembroke Adams Frank Leslie Miller Myrtle M. 02/22/1922 Brockport, Monroe Co. Adams George Lester Rebman Florence Evelyn 10/21/1926 Corfu Adams John Benjamin Ford Ada Edith 5/19/1920Batavia Adams Joseph Lawrence Fulton Mary Isabel 5/21/1927Batavia Adams Lawrence Leonard Boyd Amy Lillian 03/02/1918 Le Roy Adams Newton B. -

06 Foundation Annual Report
NEWSLETTER AND ANNUAL REPORT WINTER 2005 S SPECTIVE R E FOUNDATION 1 P MESSAGE FROM THE PRESIDENT D. DAVID CONKLIN t is my pleasure to present the 2004-2005 Dutchess ICommunity College Foundation Annual Report. Many exciting things have happened here at the College over the past academic year, and I am happy to share them with you. In 2002, the Dutchess Community College Foundation embarked on a Capital Campaign to raise $3.4 million dollars to endow four areas: scholarships, technology, facility and campus enhancements, and facul- ty program incentives. I am happy to let you know that the Foundation has met and surpassed its Campaign goal by more than 25 percent. I would like thank all of you in D. David Conklin the community who support the College and helped us achieve this success. The Campaign was entitled “Maintaining Excellence,” and our raising these funds will ensure that as the College moves into the future it will indeed be able to maintain the excellence of its educational offerings. In addition, the College received national recognition for the student referendum to donate to the Campaign, initiated by Foundation Executive Director, Patricia Prunty. Academically, the College continues to grow. For the fall 2004 semester, four new academic programs were added to the curriculum and in the fall of 2005, we began another new degree program, Aviation – Pilot Training, and this spring, we added a General Studies Associate in Science degree. I have every confidence that these programs will be equally as successful. A full-tuition scholarship, The President’s Scholarship for Academic Excellence, created for Dutchess County students who graduated in the top ten percent of their high school class has been renamed, thanks to a local business leader and his wife. -
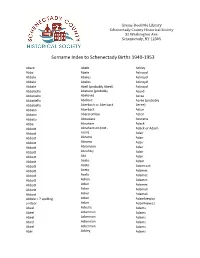
Surname Index to Schenectady Births 1940-1953
Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. Schenectady, NY 12305 Surname Index to Schenectady Births 1940-1953 Abare Abele Ackley Abba Abele Ackroyd Abbale Abeles Ackroyd Abbale Abeles Ackroyd Abbale Abell (probably Abeel) Ackroyd Abbatiello Abelone (probably Acord Abbatiello Abelove) Acree Abbatiello Abelove Acree (probably Abbatiello Aberbach or Aberback Aeree) Abbato Aberback Acton Abbato Abercrombie Acton Abbato Aboudara Acucena Abbe Abraham Adack Abbott Abrahamson (not - Adack or Adach Abbott nson) Adair Abbott Abrams Adair Abbott Abrams Adair Abbott Abramson Adair Abbott Abrofsky Adair Abbott Abt Adair Abbott Aceto Adam Abbott Aceto Adamczak Abbott Aceto Adamec Abbott Aceto Adamec Abbott Acken Adamec Abbott Acker Adamec Abbott Acker Adamek Abbott Acker Adamek Abbzle = ? spelling Acker Adamkiewicz unclear Acker Adamkiewicz Abeel Ackerle Adams Abeel Ackerman Adams Abeel Ackerman Adams Abeel Ackerman Adams Abeel Ackerman Adams Abel Ackley Adams Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. Schenectady, NY 12305 Surname Index to Schenectady Births 1940-1953 Adams Adamson Ahl Adams Adanti Ahles Adams Addis Ahman Adams Ademec or Adamec Ahnert Adams Adinolfi Ahren Adams Adinolfi Ahren Adams Adinolfi Ahrendtsen Adams Adinolfi Ahrendtsen Adams Adkins Ahrens Adams Adkins Ahrens Adams Adriance Ahrens Adams Adsit Aiken Adams Aeree Aiken Adams Aernecke Ailes = ? Adams Agans Ainsworth Adams Agans Aker (or Aeher = ?) Adams Aganz (Agans ?) Akers Adams Agare or Abare = ? Akerson Adams Agat Akin Adams Agat Akins Adams Agen Akins Adams Aggen Akland Adams Aggen Albanese Adams Aggen Alberding Adams Aggen Albert Adams Agnew Albert Adams Agnew Albert or Alberti Adams Agnew Alberti Adams Agostara Alberti Adams Agostara (not Agostra) Alberts Adamski Agree Albig Adamski Ahave ? = totally Albig Adamson unclear Albohm Adamson Ahern Albohm Adamson Ahl Albohm (not Albolm) Adamson Ahl Albrezzi Grems-Doolittle Library Schenectady County Historical Society 32 Washington Ave. -

A and No Surname
-A- Surname Index and without a surname St. Clair County Genealogical Society Quarterly Volumes 1–40 (1978-2017) Nuns are indexed under “S” as Sister [given name] To find all instances of your family name, search for variants caused by poor handwriting, misinterpretation of similar letters or their sounds. A few such examples are L for S, c for e, n for u, u for a; phonetic spellings (Aubuchon for Oubuchon); abbreviations (M’ for Mc); single letters for double (m for mm, n for nn); translations (King for Roy, Carpenter for Zimmermann). Other search tips: substitute each vowel for other ones, search for nicknames, when hyphenated – search for each surname alone, with and without “de” or “von”; with and without a space or apostrophe (Lachance and La Chance, O’Brien and OBRIEN). More suggestions are on the SCCGS website Quarterly pages at https://stclair-ilgs.org . Surname Vol. Issue Page(s) Surname Vol. Issue Page(s) Surname Vol. Issue Page(s) ___ , Cunagunda Isabella27 2 81 ___, George 24 3 108 ___, unknown 34 2 87, 89, 91, 93, ___ , Eugene 33 2 62 ___, George H. 24 3 111 96, 101 ___ , female child 33 3 135 ___, Illegible 27 1 32, 37 ___, unknown 34 3 150, 156 ___ , female infant 30 4 217 ___, Illia 24 3 116 ___, unknown 35 2 63, 73, 77 ___ , female newborn 33 2 65, 69 ___, INDIANS 16 2 109 ___, unknown 35 2 69, 70, 76 ___ , female, 25y 31 2 65 ___, Infant 38 1 45 ___, unknown 35 3 161, 162, 154 ___ , female, age 32 31 1 29 ___, Infant 38 2 92 ___, unknown 36 1 95, 96, 98, 110 ___ , Jacob 26 2 98 ___, Jacco 16 2 91 ___, unknown 36 3 122 -

Carbon Dioxide and Earth's Future
Carbon Dioxide and Earth’s Future Pursuing the Prudent Path Craig D. Idso and Sherwood B. Idso Center for the Study of Carbon Dioxide and Global Change P a g e | 2 Table of Contents Executive Summary ................................................................................................................... 3 Introduction ................................................................................................................................. 5 1. Unprecedented Warming of the Planet .................................................................... 6 2. More Frequent and Severe Floods and Droughts ................................................. 16 3. More Frequent and Severe Hurricanes ................................................................... 32 4. Rising Sea Levels Inundating Coastal Lowlands ..................................................... 43 5. More Frequent and Severe Storms ........................................................................... 50 6. Increased Human Mortality ........................................................................................ 58 7. Widespread Plant and Animal Extinctions .............................................................. 72 8. Declining Vegetative Productivity ............................................................................. 85 9. Frequent Coral Bleaching ............................................................................................ 92 10. Marine Life Dissolving Away in Acidified Oceans ............................................ -

Lp. Kontrahent NIP Adres Kontrahenta 1 1002 DROBIAZGI
Lista podmiotów współpracujących z Bankiem BNP Paribas S.A. na podstawie art. 111 b Ustawy Prawo bankowe, o przedsiębiorcach lub przedsiębiorcach zagranicznych mających dostęp do tajemnicy bankowej, którym Bank zgodnie z art. 6a ust. 1 i 7 Ustawy Prawo bankowe powierzył wykonywanie określonych czynności stan na 30.09.2020r. Lp. Kontrahent NIP Adres kontrahenta 1 1002 DROBIAZGI MARZENA OLEJNICZAK 6931825467 GŁOGÓW GARNCARSKA 2 2 100LARKA INŻ.ANDRZEJ CHIR 7551594074 BRZEG STAROMIEJSKA 1 3 100LARNIA AGATA PODKOWIAK 7132990380 20-301 Lublin FABRYCZNA 2 413 VIP PIOTR ZUBRYCKI 966129154215-324 BIAŁYSTOK KAWALERYJSKA 4C 513 VIP SP. Z O.O. SP.K. 542324479815-324 Białystok KAWALERYJSKA 4C 62 KOŁA SP Z O. O. 627274417241-500 Chorzów KATOWICKA 121 7 2 KOŁA SPÓŁKA CYWILNA 6272763695 CHORZÓW KATOWICKA 121 82 KÓŁKA GÓRZYŃSKI TOMASZ 525103025402-219 WARSZAWA AL. KRAKOWSKA 227 92B3 SPORT GRZEGORZ KAMPA 6411580568 41-706 Ruda Śląska MARII KUNCEWICZOWEJ 18 102BITS Sp. z.o.o. 634266041240-568 Katowice Ligocka 103 112-E S.C. 796261946226-600 RADOM WROCŁAWSKA 11 12 360 CIRCUS SPÓŁKA z o.o. 7010180906 Rzeszów LENARTOWICZA 6 13360 SKLEP ROWEROWY S.C. 739388912510-408 Olsztyn LUBELSKA 37A 14 3ATHLETE SP. Z O. O. S. K. 9571100337 GDAŃSK RAKOCZEGO 7 15 3ENERGY LECH SZAFRAN 6661777668 Łódź NEFRYTOWA 58 163GRAVITY ŁUKASZ PILEWSKI 837175428100-316 WARSZAWA LIPOWA 7A 3MLEASING M.M.SIENIAWSCY-ŁASKI SPÓŁKA 17 JAWNA 7532447082Nysa Wyszków Śląski 6A 183P NSU SP. Z.O.O. 9680972378OPATÓWEK CIENIA PIERWSZA 35 194 BIKE TOMASZ PROSZEWSKI 827211860798-200 Sieradz JANA PAWŁA II 63 20 4- BIKER SP Z OO SPÓŁKA KOMANDYTOWA 7773174817 62-020 SWARZĘDZ OS.LEŚNE 70 4 ECO SPÓŁKA Z OGRANICZONĄ 21 ODPOWIEDZIALNOŚCIĄ 9592015766KIELCE PL.