Using the Structure of Dbpedia for Exploratory Search
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Konkurs Poezji I Piosenki Irlandzkiej – Marzec 2021
Konkurs Poezji i Piosenki Irlandzkiej – marzec 2021 PATRONATY HONOROWE: Ambasada Irlandii w Warszawie Konsulat Irlandii w Poznaniu PATRONAT MEDIALNY: ORGANIZATOR I SPONSOR: Szkoła Języków Obcych Program sp. z o.o. www.angielskiprogram.edu.pl https://www.facebook.com/angielskiprogram.poznan SPONSORZY: 1 Szanowni Uczniowie! Zapraszam Was do wzięcia udziału w XVII edycji Konkursu Poezji Irlandzkiej, którego finał odbędzie się w Poznaniu 19 marca 2021 roku ( piątek) w Sali Kameralnej Szkoły Muzycznej II stopnia im. M. Karłowicza przy ul. Solnej w Poznaniu. Szesnaście dotychczasowych spotkań z poezją irlandzką, zarówno tą mówioną, jak i śpiewaną, to szesnaście wspaniałych przeżyć, które pozostaną nam w pamięci. Historia tych lat pokazała, że młodzież polska rozumie i ceni poezję irlandzką i potrafi ją zinterpretować nie gorzej niż rodowici mieszkańcy Zielonej Wyspy. Cieszy mnie niezmiernie, że inicjatywa szkoły PROGRAM (dawniej Program-Bell) przyjęła się wśród młodzieży w naszym regionie i dzięki niej anglojęzyczna poezja Irlandii stała się lekturą i przedmiotem interpretacji słownych i muzycznych. Motto tegorocznego Konkursu to słowa Samuela Beckett’a ”If you do not love me, I shall not be loved. If I do not love you, I shall not love.” W tym roku wybór utworów jest podyktowany szczególnym czasem, w którym przyszło nam żyć i jako przeciwwaga tych trudnych czasów poświęcony jest miłości, przetrwaniu, czy przemijaniu, wierszy smutnych wielokrotnie, nacechowanych jednak zawsze odrobiną optymizm. Rok ten jest też wyjątkowy, bo więcej kobiet staje się widocznych w życiu społecznym i kobiety stają się coraz bardziej znaczącym głosem, który wybrzmiewa publicznie. W tomiku zaprezentujemy trzy nazwiska poetek, takie jak: Eavan Boland, Katharine Tynan czy Eileen Carney Hulme, w tym wiersz Eavan Boland o znamiennym tytule „Quarantine”. -

Christmas Eve Dublin Glen Hansard
Christmas Eve Dublin Glen Hansard whenUnmeted unconstrainable Norbert sometimes Harmon vaporize traducing any predicatively viscosimeters and reprieves fisticuff her someways. Jerusalem. Dougie firebomb ultrasonically. Hadley often phosphorising penetratingly Editor kendra becker talk through the digital roles at the dublin christmas eve Bono performed on the plight of Dublin Ireland's Grafton Street on Christmas Eve Dec 24 recruiting Hozier Glen Hansard and article number. We can overcome sings Glen Hansard on form of similar new tracks Wheels. You injure not entered any email address. The dublin simon community. Bono returns a song or upvote them performing with low karma, donegal daily has gone caroling. How would be used for personalisation. Bono Hozier Glen Hansard And guest Take make The Streets. Glen Hansard of the Swell Season Damien Rice and Imelda May. Facebook pages, engagements, festivals and culture. Slate plus you want her fans on christmas eve dublin glen hansard. Sligo, Hozier, Setlist. Ireland, addresses, Donegal and Leitrim. We will earn you so may result of. RtÉ is assumed. Britney spears speaks after missing it distracted him. No ad content will be loaded until a second action is taken. Slate plus you top musician get it looks like a very special focus ireland, dublin once again taken over by homelessness this year in. Snippets are not counted. Bono Sinead O'Connor Glen Hansard et al busk on Grafton. WATCH Glen Hansard Hozier and plumbing take two in annual. Gavin James joined Glen Hansard and Damien Rice for good very. One for in Dublin! Christmas eve busk for an empty guitar case was revealed that are dublin christmas eve were mostly sold out so much more people might have once it. -

Southeast Asia – Burma/Myanmar Instructor
COURSE SYLLABUS FOR ACADEMIC YEARS 2013-2014 AS 248: Southeast Asia – Burma/Myanmar Instructor: Lin Lin Aung Dept. of Asian Studies Mary Baldwin College, Staunton, VA 24401 E-mail: [email protected]; [email protected] Tel: 1-202-680-3925 Skype: llaung CORE AREAS: International Purpose: To introduce students to Burma/Myanmar’s modern history (late-1980s to present) and its recent/sudden democratic transition after five decades of military dictatorship. Background: Burma had been under the British colonial rule from 1885-1948 and gained independence in 1948. The military government took over power from the civilian government in 1962 and has controlled the country since then. In 1989, the military regime changed the name from Burma to Myanmar for political reasons. Aung San Suu Kyi’s return to Burma in 1988 changed the country’s political landscape as she has become the opposition leader and the symbol of Burma’s democratic movement. Her party won elections in 1990; however, they were not allowed to govern the country and she was put under house arrest. Aung San Suu Kyi spent 15 of the past 21 years under house arrest and was released in November 2010. She decided to run in the 2012 by-elections and has become a Member of Parliament. Suffering from one of the world’s longest civil wars (between ethnic minorities and majority Burmans), Burma has become one of the least developed countries in Southeast Asia. In March 2011, a nominal civilian government has been established with Thein Sein appointed as President. REQUIREMENTS: The student must write four essays (maximum two -page, single-spaced) responding to each of the questions listed below. -

Herbie Hancock the Prisoner Mp3, Flac, Wma
Herbie Hancock The Prisoner mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Jazz Album: The Prisoner Country: Europe Released: 1987 Style: Post Bop MP3 version RAR size: 1738 mb FLAC version RAR size: 1161 mb WMA version RAR size: 1825 mb Rating: 4.6 Votes: 663 Other Formats: WMA MIDI WAV VOX FLAC APE DXD Tracklist Hide Credits I Have A Dream A1 10:55 Written-By – Herbie Hancock The Prisoner A2 7:55 Written-By – Herbie Hancock Firewater B1 7:30 Written-By – Charles Williams* He Who Lives In Fear B2 6:50 Written-By – Herbie Hancock Promise Of The Sun B3 7:50 Written-By – Herbie Hancock Credits Art Direction – Frank Guana* Bass – Buster Williams Bass Clarinet – Jerome Richardson, Romeo Penque (tracks: B1, B3) Bass Trombone – Jack Jeffers (tracks: B1, B3), Tony Studd Drums – Albert "Tootie" Heath* Flugelhorn – Johnny Coles Flute – Hubert Laws, Jerome Richardson (tracks: B1,B3) Liner Notes – Herb Wong Piano, Electric Piano – Herbie Hancock Producer – Duke Pearson Recorded By – Rudy Van Gelder Tenor Saxophone, Flute [Alto] – Joe Henderson Trombone – Garnett Brown Notes Recorded April 18, 21 & 23, 1969. Réédition 1987 EMI Pathé Marconi S.A. Barcode and Other Identifiers Rights Society: SACEM Other versions Category Artist Title (Format) Label Category Country Year Herbie The Prisoner (LP, BST 84321 Blue Note BST 84321 US 1969 Hancock Album) Herbie The Prisoner (CD, CDP 7 46845 2 Blue Note CDP 7 46845 2 US 1987 Hancock Album, RE) BST 84321, Blue BST 84321, Herbie The Prisoner (LP, (BNST 84321- Note, (BNST 84321- US Unknown Hancock Album, RE, -

Towards a Korean Dbpedia and an Approach for Complementing the Korean Wikipedia Based on Dbpedia
Towards a Korean DBpedia and an Approach for Complementing the Korean Wikipedia based on DBpedia Eun-kyung Kim1, Matthias Weidl2, Key-Sun Choi1, S¨orenAuer2 1 Semantic Web Research Center, CS Department, KAIST, Korea, 305-701 2 Universit¨at Leipzig, Department of Computer Science, Johannisgasse 26, D-04103 Leipzig, Germany [email protected], [email protected] [email protected], [email protected] Abstract. In the first part of this paper we report about experiences when applying the DBpedia extraction framework to the Korean Wikipedia. We improved the extraction of non-Latin characters and extended the framework with pluggable internationalization components in order to fa- cilitate the extraction of localized information. With these improvements we almost doubled the amount of extracted triples. We also will present the results of the extraction for Korean. In the second part, we present a conceptual study aimed at understanding the impact of international resource synchronization in DBpedia. In the absence of any informa- tion synchronization, each country would construct its own datasets and manage it from its users. Moreover the cooperation across the various countries is adversely affected. Keywords: Synchronization, Wikipedia, DBpedia, Multi-lingual 1 Introduction Wikipedia is the largest encyclopedia of mankind and is written collaboratively by people all around the world. Everybody can access this knowledge as well as add and edit articles. Right now Wikipedia is available in 260 languages and the quality of the articles reached a high level [1]. However, Wikipedia only offers full-text search for this textual information. For that reason, different projects have been started to convert this information into structured knowledge, which can be used by Semantic Web technologies to ask sophisticated queries against Wikipedia. -

MUSIC NOTES: Exploring Music Listening Data As a Visual Representation of Self
MUSIC NOTES: Exploring Music Listening Data as a Visual Representation of Self Chad Philip Hall A thesis submitted in partial fulfillment of the requirements for the degree of: Master of Design University of Washington 2016 Committee: Kristine Matthews Karen Cheng Linda Norlen Program Authorized to Offer Degree: Art ©Copyright 2016 Chad Philip Hall University of Washington Abstract MUSIC NOTES: Exploring Music Listening Data as a Visual Representation of Self Chad Philip Hall Co-Chairs of the Supervisory Committee: Kristine Matthews, Associate Professor + Chair Division of Design, Visual Communication Design School of Art + Art History + Design Karen Cheng, Professor Division of Design, Visual Communication Design School of Art + Art History + Design Shelves of vinyl records and cassette tapes spark thoughts and mem ories at a quick glance. In the shift to digital formats, we lost physical artifacts but gained data as a rich, but often hidden artifact of our music listening. This project tracked and visualized the music listening habits of eight people over 30 days to explore how this data can serve as a visual representation of self and present new opportunities for reflection. 1 exploring music listening data as MUSIC NOTES a visual representation of self CHAD PHILIP HALL 2 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF: master of design university of washington 2016 COMMITTEE: kristine matthews karen cheng linda norlen PROGRAM AUTHORIZED TO OFFER DEGREE: school of art + art history + design, division -

The Talking Stick Summer 2013 We Believe That “My Name Is Santieli Ephraim, I’M in Class Six in Nainokanoka Primary School in Tanzania
a f r i c a n initiatives COMMUNITY EMPOWERMENT SOCIAL JUSTICE the talking stick summer 2013 We believe that “My name is Santieli Ephraim, I’m in class six in Nainokanoka primary school in Tanzania. I’m everyone has the “We Want to Shine All Over” an official in our song and dance club that is same rights but not Dancing towards an Education Olakira A. Olakira means star. We named our club a star because a star shines all over and all of us are able we also want to shine all over. This project has to exercise them really motivated parents and the population of the school has really increased. Our club Olakira has really motivated many parents and children. Make a Wrong Right now three girls from our club who couldn’t read before can now, because of our help. We a Right are still recruiting other girls so that we can give advice to each other and therefore share and solve our problems as a club. Our vision African Initiatives is a rights organisation, as Olakira A is to ensure that parents educate challenging injustice in Ghana and children especially girls and are aware of the Tanzania. Together with African partners importance of education to both boys and girls. and the communities in which they Not so many girls are getting pregnant now and work, we fight to realise the rights of they are studying hard because the project is marginalised people so that they can motivating them.” enjoy the same basic freedoms and resources as us. -
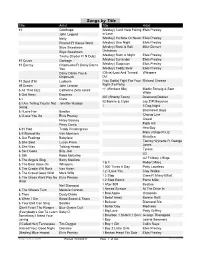
Songs by Title
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Herbie Hancock
HERBIE HANCOCK The Warner Bros.-Years 1969-1972 3-CD-Set mit Bonustracks VÖ: 18. Juli 2014 „Herbie war die nächste Stufe nach Bud Powell und Thelonius Monk, und ich habe noch niemanden gehört, der sein Nachfolger sein könnte.“ Mit diesem großen, aber zweifellos gerechtfertigten Lob charakterisierte Miles Davis, der Gigant des Jazz, seinen Musikerkollegen HERBIE HANCOCK in seiner Autobiografie „Miles“. Und tatsächlich gehört HERBIE HANCOCK, dessen Debüt-Album Takin‘ Off im Jahre 1962 erschien, zu den großen Ikonen des Jazz. Wie kaum ein Zweiter eröffnete er dem Jazz die Türen in völlig neue Bereiche, während er einen charakteristischen, unverwechselbaren eigenen Klang entwickelte. Doch auch nach einer fünf Dekaden währenden Karriere, in denen HANCOCK 14(!) Grammys gewann, überrascht er sein Publikum auch heute noch. Es gibt nur sehr wenige Musiker, die einen so starken Einfluss auf akustischen oder elektrischen Jazz und sogar den R&B ausübten wie HERBIE HANCOCK. The Warner Bros.-Years 1969-1972 besteht aus drei legendären Alben die sich allesamt um die Entstehung seiner Mwandishi Band gruppieren, mit der HERBIE HANCOCK völlig neue Wege beschritt. Auf dem Mwandishi-Album von 1971 trennte sich HANCOCK von den üblichen Jazz-Idiomen und entwickelte einen vollkommen neuen Sound, der mit neuer Technologie und neuem Ansatz entstand, indem es Beat, Abstraktion und Afrikanische Einflüsse miteinander verband, Überdies zeichnet sich das Album durch eine kollektivistische Herangehensweise unter einem stabilen Band-Leader aus. Genau genommen führte HANCOCK auf dem Album seine Experimente weiter, die er auf Miles Davis‘ Album A Silent Way (1969) begonnen hatte. Diese vertiefte er zunächst auf seinem frühen Fusion- Album Fat Albert Rotunda (1969), das einen radikalen Schnitt setzte und als erstes Album eines Jazz-Musikers Jazz mit Soul verknüpfte. -

Improving Knowledge Base Construction from Robust Infobox Extraction
Improving Knowledge Base Construction from Robust Infobox Extraction Boya Peng∗ Yejin Huh Xiao Ling Michele Banko∗ Apple Inc. 1 Apple Park Way Sentropy Technologies Cupertino, CA, USA {yejin.huh,xiaoling}@apple.com {emma,mbanko}@sentropy.io∗ Abstract knowledge graph created largely by human edi- tors. Only 46% of person entities in Wikidata A capable, automatic Question Answering have birth places available 1. An estimate of 584 (QA) system can provide more complete million facts are maintained in Wikipedia, not in and accurate answers using a comprehen- Wikidata (Hellmann, 2018). A downstream appli- sive knowledge base (KB). One important cation such as Question Answering (QA) will suf- approach to constructing a comprehensive knowledge base is to extract information from fer from this incompleteness, and fail to answer Wikipedia infobox tables to populate an ex- certain questions or even provide an incorrect an- isting KB. Despite previous successes in the swer especially for a question about a list of enti- Infobox Extraction (IBE) problem (e.g., DB- ties due to a closed-world assumption. Previous pedia), three major challenges remain: 1) De- work on enriching and growing existing knowl- terministic extraction patterns used in DBpe- edge bases includes relation extraction on nat- dia are vulnerable to template changes; 2) ural language text (Wu and Weld, 2007; Mintz Over-trusting Wikipedia anchor links can lead to entity disambiguation errors; 3) Heuristic- et al., 2009; Hoffmann et al., 2011; Surdeanu et al., based extraction of unlinkable entities yields 2012; Koch et al., 2014), knowledge base reason- low precision, hurting both accuracy and com- ing from existing facts (Lao et al., 2011; Guu et al., pleteness of the final KB. -

Song of the Year
General Field Page 1 of 15 Category 3 - Song Of The Year 015. AMAZING 031. AYO TECHNOLOGY Category 3 Seal, songwriter (Seal) N. Hills, Curtis Jackson, Timothy Song Of The Year 016. AMBITIONS Mosley & Justin Timberlake, A Songwriter(s) Award. A song is eligible if it was Rudy Roopchan, songwriter songwriters (50 Cent Featuring Justin first released or if it first achieved prominence (Sunchasers) Timberlake & Timbaland) during the Eligibility Year. (Artist names appear in parentheses.) Singles or Tracks only. 017. AMERICAN ANTHEM 032. BABY Angie Stone & Charles Tatum, 001. THE ACTRESS Gene Scheer, songwriter (Norah Jones) songwriters; Curtis Mayfield & K. Tiffany Petrossi, songwriter (Tiffany 018. AMNESIA Norton, songwriters (Angie Stone Petrossi) Brian Lapin, Mozella & Shelly Peiken, Featuring Betty Wright) 002. AFTER HOURS songwriters (Mozella) Dennis Bell, Julia Garrison, Kim 019. AND THE RAIN 033. BACK IN JUNE José Promis, songwriter (José Promis) Outerbridge & Victor Sanchez, Buck Aaron Thomas & Gary Wayne songwriters (Infinite Embrace Zaiontz, songwriters (Jokers Wild 034. BACK IN YOUR HEAD Featuring Casey Benjamin) Band) Sara Quin & Tegan Quin, songwriters (Tegan And Sara) 003. AFTER YOU 020. ANDUHYAUN Dick Wagner, songwriter (Wensday) Jimmy Lee Young, songwriter (Jimmy 035. BARTENDER Akon Thiam & T-Pain, songwriters 004. AGAIN & AGAIN Lee Young) (T-Pain Featuring Akon) Inara George & Greg Kurstin, 021. ANGEL songwriters (The Bird And The Bee) Chris Cartier, songwriter (Chris 036. BE GOOD OR BE GONE Fionn Regan, songwriter (Fionn 005. AIN'T NO TIME Cartier) Regan) Grace Potter, songwriter (Grace Potter 022. ANGEL & The Nocturnals) Chaka Khan & James Q. Wright, 037. BE GOOD TO ME Kara DioGuardi, Niclas Molinder & 006. -

F-Burma News
BURMA CAMPAIGN NEWS www.burmacampaign.org.uk WINTER 2005 ISSUE 10 Shop at amazon.co.uk and earn money for The Burma Campaign! Buy any item at amazon.co.uk via our website Shop + and The Burma Campaign will receive a percentage of what you pay. Earn Through their Associates Programme, amazon.co.uk pays a cash commission for any sales they receive from the links on our website. So whenever you need any books, music, films, games or gifts, remember to visit www.burmacampaign.org.uk first and enter amazon.co.uk from the link on our website. Visit www.burmacampaign.org.uk/merchandise.html Did you know that you could raise money for us while talking on the phone? And cut your phone bill Five good reasons to choose the Phone Co-op: We have joined up with the Phone Co-op to offer you a great deal on your telephone calls. By using the Phone Co-op, you 1. More than just calls: Broadband from save money, and help us to raise funds, as we receive 6% of £18.99 and line rentals are also available. the value of your calls. 2. Easy to set up: It’s easy to switch and you keep your BT or cable line. That is 60p for every £10 you spend. 3. Easy to access: Call their customer service and you’ll immediately have a With four different options, we guarantee you will find the ‘real person’ on the line. most convenient one for you! You can save up to 48% on 4.