Zebra - User’S Guide and Reference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Run-Commands-Windows-10.Pdf
Run Commands Windows 10 by Bettertechtips.com Command Action Command Action documents Open Documents Folder devicepairingwizard Device Pairing Wizard videos Open Videos Folder msdt Diagnostics Troubleshooting Wizard downloads Open Downloads Folder tabcal Digitizer Calibration Tool favorites Open Favorites Folder dxdiag DirectX Diagnostic Tool recent Open Recent Folder cleanmgr Disk Cleanup pictures Open Pictures Folder dfrgui Optimie Drive devicepairingwizard Add a new Device diskmgmt.msc Disk Management winver About Windows dialog dpiscaling Display Setting hdwwiz Add Hardware Wizard dccw Display Color Calibration netplwiz User Accounts verifier Driver Verifier Manager azman.msc Authorization Manager utilman Ease of Access Center sdclt Backup and Restore rekeywiz Encryption File System Wizard fsquirt fsquirt eventvwr.msc Event Viewer calc Calculator fxscover Fax Cover Page Editor certmgr.msc Certificates sigverif File Signature Verification systempropertiesperformance Performance Options joy.cpl Game Controllers printui Printer User Interface iexpress IExpress Wizard charmap Character Map iexplore Internet Explorer cttune ClearType text Tuner inetcpl.cpl Internet Properties colorcpl Color Management iscsicpl iSCSI Initiator Configuration Tool cmd Command Prompt lpksetup Language Pack Installer comexp.msc Component Services gpedit.msc Local Group Policy Editor compmgmt.msc Computer Management secpol.msc Local Security Policy: displayswitch Connect to a Projector lusrmgr.msc Local Users and Groups control Control Panel magnify Magnifier -

LABEL MATRIX 2021 Release Notes Version 2021.00.00
LABEL MATRIX 2021 Release Notes Version 2021.00.00 Table of Contents System Requirements ................................................................................................................. 3 Virtual Environment .................................................................................................................... 3 LABEL MATRIX 2021 New Features, Improvements and Fixes ........................................................... 4 LABEL MATRIX 2019 New Features, Improvements and Fixes ........................................................... 5 LABEL MATRIX 2018 New Features, Improvements and Fixes ........................................................... 7 LABEL MATRIX 2016 New Features, Improvements and Fixes ......................................................... 10 LABEL MATRIX 2015 New Features, Improvements and Fixes ......................................................... 11 LABEL MATRIX 2014 New Features, Improvements and Fixes ......................................................... 12 LABEL MATRIX 2012 New Features, Improvements and Fixes ......................................................... 14 LABEL MATRIX 8 New Features, Improvements and Fixes .............................................................. 15 New Device Support.................................................................................................................. 19 Known Limitations .................................................................................................................... 34 www.teklynx.com -

P310 Maintenance Manual
P310 Maintenance Manual CPARD RINTER P RODUCTS Manual No. 980264-001 Rev. B ©2001 Zebra Technologies Corporation FOREWORD This manual contains service and repair information for P310 Card Printers manufactured by Zebra Technology Corporation, Camarillo, California. The contents include maintenance, diagnosis and repair information. TECHNICAL SUPPORT For technical support, users should first contact the distributor that originally sold the product—phone +1 (800) 344 4003 to locate the nearest Eltron Products Distributor. Eltron Products offers the following: U.S.A Europe Asia Latin America http://www.eltron.com Internet ftp://ftp.eltron.com e-mail [email protected] [email protected] [email protected] [email protected] Compu 102251,1164 Serve Phone +805 578 1800 +33 (0) 2 40 09 70 70 +65 73 33 123 +1 847 584 2714 +44 (0) 1189 895 762 FAX +1 805 579 1808 +65 73 38 206 +1 847 584 2725 +33 (0) 2 40 09 70 70 RETURN MATERIALS AUTHORIZATION Before returning any equipment to Eltron for either in- or out-of-warranty repairs, contact the Eltron Repair Administration for a Return Materials Authorization (RMA) number. Then repackage the equipment, if possible using original packing materials, and mark the RMA number clearly on the outside. Ship the equipment, freight prepaid, to one of the following addresses: For USA and Latin America: For Europe, Asia, and Pacific: Zebra Technologies Corporation Zebra Technologies Corporation Eltron Card Printer Products Eltron Card Printer Products 1001 Flynn Road Zone Industrielle Rue d’Amsterdam Camarillo, CA 93012-8706, USA 44370 Varades, France Phone: +1 (805) 579-1800 Phone: +33 (0) 2 40 09 70 70 FAX: +1 (805) 579-1808 FAX: +33 (0) 2 40 83 47 45 COPYRIGHT NOTICE This document contains information proprietary to Zebra Technology Corporation. -

The-Dark-Zebra-User-Guide.Pdf
ZebraHZ and THE DARK ZEBRA Version 2.9.3 22. Jul 2021 U-HE • Heckmann Audio GmbH • Berlin Table of Contents Introduction 5 The Dark Zebra .....................................................5 ZebraHZ ................................................................5 Installation .............................................................6 Terms of Use .........................................................7 User Interface 8 Basic Operation ....................................................8 Upper Bar ..............................................................9 GUI size ...............................................................10 Synthesis Window ...............................................10 Main grid .........................................................11 Lane Mixer ......................................................12 Lane Compressors ..........................................13 Performance Window ..........................................14 Lower Bar and Lower Pane .................................15 Preset Browser 16 Overview .............................................................16 Directory Panel (folders) ..................................17 Presets Panel (files) .........................................19 Preset Info Panel .............................................21 Installing More Soundsets................................... 21 Preset Tagging ....................................................22 Search by Tags ....................................................23 Search by Text ....................................................24 -

Programming Announcements Announcements Announcements
5/20/2008 Programming Announcements FIT100 FIT100 • Why is programming fun? • Undergraduate Research • Finally, there is the delight of working in such a Symposium tractable medium. The programmer, like the ∗ Friday poet, works only slihtllightly re-moved from pure thought-stuff. He builds his castles in the air, ∗ How many attended? from air, creating by exertion of the imagination. Few media of creation are so flexible, so easy to polish and rework, so readily capable of realizing grand conceptual structures. Source: Frederick P. Brooks, Jr. The Mythical Man-Month Essays on Software Engineering. Announcements Announcements FIT100 FIT100 •Project 2B • Labs this week ∗ Due on Wednesday before 12 Noon ∗ Monday-Tuesday •If yyqou don't submit the quiz before 11, • Finish uppp proj ect 2B your answers are gone!! ∗ Wednesday-Thursday • Aim at submitting quiz before 11 • Grading spreadsheet that will calculate your current grade in the class Getting Help Exercise 4 FIT100 FIT100 • JavaScript Exercise 4 ∗ Describe how you use a for loop to cyygcle through radio buttons to find the one that has been checked. 1 5/20/2008 Exercise 4 Exercise 4 FIT100 FIT100 <label for="giraffe">Giraffe</label><br /> <label for="giraffe">Giraffe</label><br /> <input type="radio" id="giraffe" <input type="radio" id="giraffe" name="animals" /> name="animals" /> <label for="zebra">Zebra</label><br /> <label for="zebra">Zebra</label><br /> <input type="radio" id="zebra" <input type="radio" id="zebra" name="animals" /> name="animals" /> <label for="lion">Lion</label><br -
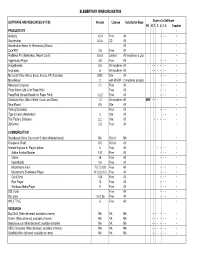
Elementary Windows Matrix
ELEMENTARY WINDOWS MATRIX SOFTWARE AND RESOURCES 8/17/05 Version License Installation Base Access to Software PK K 1 2 3 4 5 Teacher PRODUCTIVITY • Audacity 1.2.4 Free All • • • • Boardmaker 5.3.6 CD All • Boardmaker Addon for Elementary Schools All • Cute PDF 2.6 Free All • FileMaker Pro (Networked, Report Cards) 5.0v3 Limited AV machines & Lab • Hyperstudio Player 4.5 Free All • • • • ImageBlender 2.5 All machines All • • • • • • • • Inspiration 8 All machines All • • • • • • • Microsoft Office (Word, Excel, Access, PP, Publisher) 2000 Site All • • • • MovieMaker 2 with WinXP 2 machines on carts • Netscape Composer 7.1 Free All • • • • Photo Album add-in for PowerPoint Free All • • • • PowerTalk (Screen Reader for Power Point) 1.2.2 Free All • • • • Scholastic Keys (Max's Write, Count, and Show) 1.2 All machines All MW • • • • SmartBoard 9.5 Site All • Talking Calculator Free All • • • • Type to Learn (Networked) 3 Site All • • • Tool Factory Database 2.2 Site All • • • • • • ZipCentral 2.6 Free All • COMMUNICATION Blackboard Online Classroom Builder (Web-delivered) NA District NA • Groupwise Client 6.5 District All • Internet Explorer w. Plugins below: 6 Free All • • • • • Adobe Acrobat Reader 7.07 Free All • • • • Chime v6 Free All • • • • HyperStudio 4.5 Free All Macromedia Flash 7 (7.0.19.0) Free All • • • • Macromedia Shockwave Player 10 (0.0.21.0) Free All • • • • QuickTime 7.04 Free All • • • • Real Player 10 Free All • • • • Windows Media Player 9 Free All • • • • SOL Fonts Free All • • • • Sun Java 1.5.0_06 Free All • • • • -

Document Preparation in Classical Languages
4.2. Operating System Support: Windows tional language is not the same as anging the language of the user interface. If you want all your menus and so forth in German, that is an additional step. Additional Keyboard Resources Tom Gewee has created keyboards for many languages in addition to those provided by OS X. ey can be found at http://homepage. mac.com/thgewecke/tckbs.html. He also has a general “Multilin- gual Mac” page at http://homepage.mac.com/thgewecke/mlingos9. html and a blog at http://m10lmac.blogspot.com/, both of whi are excellent sources of information about using the Mac OS when writ- ing in languages other than English. ird-party Utilities You can use third-party utilities su as the well known PopChar to e out and enter aracters; see http://www.macility.com/ products/popcharx/), where a demo version is available. e Unicode Cheer utility from earthlingso does a few things that Character Palee doesn’t, su as convert Unicode values to HTML entities or help with normalization issues. In some ways it is more convenient than the Character Palee. See http://earthlingsoft. net/UnicodeChecker/index.html. See also the discussion of GreekKeys in §7.3, page 131. Warning for Mac Users! Be careful not to log out while using a keyboard that does not allow you to enter your password in order to get ba in — for example, logging out when a Hebrew or Greek keyboard is in effect if your password requires Latin aracters. SAMPLE4.2 Operating System Support: Windows -key Methods Windows, by contrast, provides two system-wide methods for access- ing non-English aracters, both of them clumsy. -

Copyrighted Material
18_579274 bindex.qxd 2/22/05 7:41 PM Page 312 Index A C accounts call waiting, dial-up account setup, 196 computer administrator, 157 cascade windows, 35 create, 156–157 CD Writing Wizard, 143 delete, 166–167 CDs Internet connection, manual setup, 194–197 backups to, 289 limited user, 157 burn music to, 124–125 name changes, 160–161 copy files to, 140–143 name restrictions, 161 music, Media Player and, 112–115, 120–123 passwords, 162–163 program installation, 18 picture change, 164–165 rip with Media Player, 120–121 sharing and, 155 view files, 135 switch between, 158–159 Character Map, special symbols, 62–63 User Accounts window, 154–155 check boxes, dialog boxes, 26 Welcome screen, 4 circles (Paint), 91 Activate Windows screen, 12–13 click mouse, 8–9 activate Windows XP, 12–13 close button, 23 Add or Remove Programs close windows, 33 installation and, 19 color uninstall programs, 40–41 background, 253 address bar (Internet Explorer), 206 custom, 256–257 Address Book (Outlook Express), 226–227 color box (Paint) addresses, Web, 204, 208–209 color selection, 99 airbrush freehand drawing (Paint), 96 eraser, 101 All Programs menu, 22 introduction, 86 Appearances and Themes, Display Properties and, 250–251 replace color, 101 attachments to e-mail (Outlook Express), 230-231, 240–241 color fills (Paint), 97 audio, play in Media Player, 110 combo boxes automatic updates, 280–281 dialog boxes, 26 item selection, 29 command buttons, dialog boxes, 27 B compressed folders, extract files, 150–151 Background, 252–253 computer administrator account, 157 Backup or Restore Wizard, 286–289 configuration, startup and, 4 Backup program, 286–287 connections, Internet. -

Zebra 2.0 and Lagopus: Newly-Designed Routing Stack On
Zebra 2.0 and Lagopus: newly-designed routing stack on high-performance packet forwarder Kunihiro Ishiguro∗, Yoshihiro Nakajimay, Masaru Okiz, Hirokazu Takahashiy ∗ Hash-Set, Tokyo, Japan y Nippon Telegraph and Telephone Corporation, Tokyo, Japan z Internet Initiative Japan Inc, Tokyo, Japan e-mail: [email protected], [email protected], [email protected], [email protected] Abstract First GNU Zebra architecture and its issues Zebra 2.0 is the new version of open source networking When we designed the first GNU Zebra, the biggest ambition software which is implemented from scratch. Zebra 2.0 was to make multi-process networking software work. The is designed to supports BGP/OSPF/LDP/RSVP-TE and co- first GNU Zebra is made from a collection of several dae- working with Lagopus as fast packet forwarder with Open- mons that work together to build the routing table. There may Flow API. In this new version of Zebra, it adapts new archi- be several protocol-specific routing daemons and Zebra’s ker- tecture which is mixture of thread model and task completion nel routing manager. Figure 1 shows the architecture of the model to achieve maximum scalability with multi-core CPUs. first GNU Zebra. RIB (Routing Information Base) / FIB (For- Zebra has separate independent configuration manager that warding Information Base) and the interface manager are sep- supports commit/rollback and validation functionality. The configuration manager understand YANG based configuration arated into an isolated process called ’zebra’. All of protocol model so we can easily add a new configuration written in handling is also separated to it’s own process such as ’ripd’, YANG. -
| Independent Consultant Logo
| INDEPENDENT CONSULTANT LOGO PRIMARY LOGO PRIMARY TWO-TONE HEXAGON LOGO The Scentsy Independent Consultant logo can be used by Consultants on their personal printed materials and websites to promote their business. The space between the elements within the logo should not be modified. The logo should always appear upright, with clearance on either side and clearance on the top and bottom equal to the height of the lower case “S” character as it’s used in the sized logo (see example). SPECIAL NOTE: If you need a two colour option for this logo, use Pantone 522 to replace the 80% screen. Pantone 519 Pantone 519 — 80% C 60 M 100 Y 0 K 40 C 45 M 57 Y 23 K 6 #5c305e #8f7290 7/22/15 SCENTSY CONSULTANT STYLE GUIDE 1 | FONT - INDEPENDENT CONSULTANT LOGO TYPE The logo displays the company name in the Scentsy Spirit font, and the accompanying type in Knockout-HTF34-Junior Sumo. No other fonts should be used to alter Scentsy Spirit the look of the Scentsy Independent Consultant logo. 1234567890!@#$%^&*()_=+ ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz Knockout-HTF34-JuniorSumo 1234567890!@#$%^&*()_=+ ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 7/22/15 SCENTSY CONSULTANT STYLE GUIDE 2 | INDEPENDENT CONSULTANT LOGO SECONDARY LOGO OPTIONS ONE-COLOUR HEXAGON LOGO ONE-COLOUR LOGO + STAR TRIO The following secondary logos may be used on specific Scentsy Family Store materials and by Scentsy Consultants to promote their personal business. The space between the elements within the secondary logos should not be modified. The logos should always appear upright, with clearance on either side and clearance on the top and bottom equal to the height of the lower case “S” character as it’s used in the sized logo. -

A Records, 244–245, 279 -A Switch in Nbtstat, 190 in Netstat, 186 AAS Deployment Package, 710 .Aas Extension, 712 Abstract
22_InsideWin_Index 13/3/03 9:50 AM Page 1269 Index A A records, 244–245, 279 ACEs (Access Control Entries) -a switch access masks in, 568–570 in Nbtstat, 190 command-line tools for, 572–576 in Netstat, 186 for cumulative permissions, 577 AAS deployment package, 710 for deny permissions, 578 .aas extension, 712 inheritance in, 579–580, 725–728 Abstract classes, 299–300 object ownership in, 572 Accelerated Graphics Port (AGP) adapters, 164 viewing and modifying, 570–571 Access Control Entries. See ACEs (Access ACKs in DHCP, 101–102 Control Entries) ACL Editor, 570, 723 Access control lists (ACLs) Advanced view in Active Directory security, 732–734 for inheritance, 578, 581 objects in, 339 for ownership, 572 in security descriptors, 559 for special permissions, 723–724 Access Control Settings window, 728 Edit view, 725–726 Access masks for permissions inheritance, 578 in ACEs, 568–570 blocking, 579 in DSOs, 733 settings for, 581 Access requests in Kerberos, 621 viewings, 582 Access rights. See also Permissions ACLs (access control lists) in Active Directory security in Active Directory security, 732–734 delegation, 729–732 objects in, 339 types of, 724–725 in security descriptors, 559 for group policies, 682 ACPI (Advanced Configuration and Power Access tokens Interface) contents of, 560–561 compatibility of, 23–28, 148–149 local, 559 kernel version for, 135 SIDs in, 559, 561, 581 for PnP,17, 147–149 ACCM (Asynchronous-Control- ACPIEnable option, 149 Character-Map), 1124 Activation Account domain upgrades, 496–498 in IA64, 130 BDC, 494–496 in installation, 49–50 PDC, 490–493 unattended setup scripts for, 95 Account lockout policies Active Directory, 238 in domain design, 429 bulk imports and exports in, 353–356 in password security, 593–594 DNS deployment in, 242–243 Account logons, auditing, 647 DNS integration in, 238–239 Account management, auditing, 511, 648 dynamic updates, 244–245 Accounts in domain migration. -

Verifiable Asics Riad S
Verifiable ASICs Riad S. Wahby?◦ Max Howald† Siddharth Garg? abhi shelat‡ Michael Walfish? [email protected] [email protected] [email protected] [email protected] [email protected] ?New York University ◦Stanford University †The Cooper Union ‡The University of Virginia Abstract—A manufacturer of custom hardware (ASICs) can under- deploy the two ASICs together, and, if their outputs differ, mine the intended execution of that hardware; high-assurance ex- a trusted processor can act (notify an operator, impose fail- ecution thus requires controlling the manufacturing chain. How- safe behavior, etc.). This technique provides no assurance if ever, a trusted platform might be orders of magnitude worse in per- formance or price than an advanced, untrusted platform. This pa- the foundries collude—a distinct possibility, given the small per initiates exploration of an alternative: using verifiable computa- number of top-end fabs. A high assurance variant is to execute tion (VC), an untrusted ASIC computes proofs of correct execution, the desired functionality in software or hardware on a trusted which are verified by a trusted processor or ASIC. In contrast to platform, treating the original ASIC as an untrusted accelerator the usual VC setup, here the prover and verifier together must im- pose less overhead than the alternative of executing directly on the whose outputs are checked, potentially with some lag. trusted platform. We instantiate this approach by designing and This leads to our motivating question: can we get high- implementing physically realizable, area-efficient, high throughput assurance execution at a lower price and higher performance ASICs (for a prover and verifier), in fully synthesizable Verilog.