Installing Linux Applications for the First Time
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Leveraging Activation Sparsity for Training Deep Neural Networks
Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks Minsoo Rhu Mike O’Connor Niladrish Chatterjee Jeff Pool Stephen W. Keckler NVIDIA Santa Clara, CA 95050 fmrhu, moconnor, nchatterjee, jpool, [email protected] Abstract—Popular deep learning frameworks require users to the time needed to copy data back and forth through PCIe is fine-tune their memory usage so that the training data of a deep smaller than the time the GPU spends computing the DNN neural network (DNN) fits within the GPU physical memory. forward and backward propagation operations, vDNN does Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory not affect performance. For networks whose memory copying to be utilized for memory allocations. Despite its merits, vir- operation is bottlenecked by the data transfer bandwidth of tualizing memory can incur significant performance overheads PCIe however, vDNN can incur significant overheads with an when the time needed to copy data back and forth from CPU average 31% performance loss (worst case 52%, Section III). memory is higher than the latency to perform the computations The trend in deep learning is to employ larger and deeper required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on networks that leads to large memory footprints that oversub- a “compressing DMA engine” (cDMA) that drastically reduces scribe GPU memory [13, 14, 15]. Therefore, ensuring the the size of the data structures that are targeted for CPU-side performance scalability of the virtualization features offered allocations. -

Contrasting the Performance of Compression Algorithms on Genomic Data
Contrasting the Performance of Compression Algorithms on Genomic Data Cornel Constantinescu, IBM Research Almaden Outline of the Talk: • Introduction / Motivation • Data used in experiments • General purpose compressors comparison • Simple Improvements • Special purpose compression • Transparent compression – working on compressed data (prototype) • Parallelism / Multithreading • Conclusion Introduction / Motivation • Despite the large number of research papers and compression algorithms proposed for compressing genomic data generated by sequencing machines, by far the most commonly used compression algorithm in the industry for FASTQ data is gzip. • The main drawbacks of the proposed alternative special-purpose compression algorithms are: • slow speed of either compression or decompression or both, and also their • brittleness by making various limiting assumptions about the input FASTQ format (for example, the structure of the headers or fixed lengths of the records [1]) in order to further improve their specialized compression. 1. Ibrahim Numanagic, James K Bonfield, Faraz Hach, Jan Voges, Jorn Ostermann, Claudio Alberti, Marco Mattavelli, and S Cenk Sahinalp. Comparison of high-throughput sequencing data compression tools. Nature Methods, 13(12):1005–1008, October 2016. Fast and Efficient Compression of Next Generation Sequencing Data 2 2 General Purpose Compression of Genomic Data As stated earlier, gzip/zlib compression is the method of choice by the industry for FASTQ genomic data. FASTQ genomic data is a text-based format (ASCII readable text) for storing a biological sequence and the corresponding quality scores. Each sequence letter and quality score is encoded with a single ASCII character. FASTQ data is structured in four fields per record (a “read”). The first field is the SEQUENCE ID or the header of the read. -

Ultumix GNU/Linux 0.0.1.7 32 Bit!
Welcome to Ultumix GNU/Linux 0.0.1.7 32 Bit! What is Ultumix GNU/Linux 0.0.1.7? Ultumix GNU/Linux 0.0.1.7 is a full replacement for Microsoft©s Windows and Macintosh©s Mac OS for any Intel based PC. Of course we recommend you check the system requirements first to make sure your computer meets our standards. The 64 bit version of Ultumix GNU/Linux 0.0.1.7 works faster than the 32 bit version on a 64 bit PC however the 32 bit version has support for Frets On Fire and a few other 32 bit applications that won©t run on 64 bit. We have worked hard to make sure that you can justify using 64 bit without sacrificing too much compatibility. I would say that Ultumix GNU/Linux 0.0.1.7 64 bit is compatible with 99.9% of all the GNU/Linux applications out there that will work with Ultumix GNU/Linux 0.0.1.7 32 bit. Ultumix GNU/Linux 0.0.1.7 is based on Ubuntu 8.04 but includes KDE 3.5 as the default interface and has the Mac4Lin Gnome interface for Mac users. What is Different Than Windows and Mac? You see with Microsoft©s Windows OS you have to defragment your computer, use an anti-virus, and run chkdsk or a check disk manually or automatically once every 3 months in order to maintain a normal Microsoft Windows environment. With Macintosh©s Mac OS you don©t have to worry about fragmentation but you do have to worry about some viruses and you still should do a check disk on your system every once in a while or whatever is equivalent to that in Microsoft©s Windows OS. -
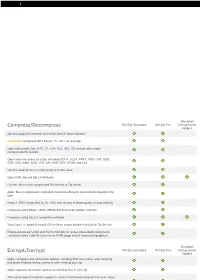
Compress/Decompress Encrypt/Decrypt
Windows Compress/Decompress WinZip Standard WinZip Pro Compressed Folders Zip and unzip files instantly with 64-bit, best-in-class software ENHANCED! Compress MP3 files by 15 - 20 % on average Open and extract Zipx, RAR, 7Z, LHA, BZ2, IMG, ISO and all other major compression file formats Open more files types as a Zip, including DOCX, XLSX, PPTX, XPS, ODT, ODS, ODP, ODG,WMZ, WSZ, YFS, XPI, XAP, CRX, EPUB, and C4Z Use the super picker to unzip locally or to the cloud Open CAB, Zip and Zip 2.0 Methods Convert other major compressed file formats to Zip format Apply 'Best Compression' method to maximize efficiency automatically based on file type Reduce JPEG image files by 20 - 25% with no loss of photo quality or data integrity Compress using BZip2, LZMA, PPMD and Enhanced Deflate methods Compress using Zip 2.0 compatible methods 'Auto Open' a zipped Microsoft Office file by simply double-clicking the Zip file icon Employ advanced 'Unzip and Try' functionality to review interrelated components contained within a Zip file (such as an HTML page and its associated graphics). Windows Encrypt/Decrypt WinZip Standard WinZip Pro Compressed Folders Apply encryption and conversion options, including PDF conversion, watermarking and photo resizing, before, during or after creating your zip Apply separate conversion options to individual files in your zip Take advantage of hardware support in certain Intel-based computers for even faster AES encryption Administrative lockdown of encryption methods and password policies Check 'Encrypt' to password protect your files using banking-level encryption and keep them completely secure Secure sensitive data with strong, FIPS-197 certified AES encryption (128- and 256- bit) Auto-wipe ('shred') temporarily extracted copies of encrypted files using the U.S. -

Creating Rpms Guide
CREATING RPMS (Student version) v1.0 Featuring 36 pages of lecture and a 48 page lab exercise This docu m e n t serves two purpose s: 1. Representative sample to allow evaluation of our courseware manuals 2. Make available high quality RPM documentation to Linux administrators A bout this m aterial : The blue background you see simulates the custom paper that all Guru Labs course w are is printed on. This student version does not contain the instructor notes and teaching tips present in the instructor version. For more information on all the features of our unique layout, see: http://ww w . g urulabs.co m /courseware/course w are_layout.php For more freely available Guru Labs content (and the latest version of this file), see: http://www.gurulabs.co m/goodies/ This sample validated on: Red Hat Enterprise Linux 4 & Fedora Core v3 SUSE Linux Enterprise Server 9 & SUSE Linux Professional 9.2 About Guru Labs: Guru Labs is a Linux training company started in 199 9 by Linux experts to produce the best Linux training and course w are available. For a complete list, visit our website at: http://www.gurulabs.co m/ This work is copyrighted Guru Labs, L.C. 2005 and is licensed under the Creative Common s Attribution- NonCom mer cial- NoDerivs License. To view a copy of this license, visit http://creativecom m o n s.org/licenses/by- nc- nd/2.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 943 0 5, USA. Guru Labs 801 N 500 W Ste 202 Bountiful, UT 84010 Ph: 801-298-5227 WWW.GURULABS.COM Objectives: • Understand -

NXP Eiq Machine Learning Software Development Environment For
AN12580 NXP eIQ™ Machine Learning Software Development Environment for QorIQ Layerscape Applications Processors Rev. 3 — 12/2020 Application Note Contents 1 Introduction 1 Introduction......................................1 Machine Learning (ML) is a computer science domain that has its roots in 2 NXP eIQ software introduction........1 3 Building eIQ Components............... 2 the 1960s. ML provides algorithms capable of finding patterns and rules in 4 OpenCV getting started guide.........3 data. ML is a category of algorithm that allows software applications to become 5 Arm Compute Library getting started more accurate in predicting outcomes without being explicitly programmed. guide................................................7 The basic premise of ML is to build algorithms that can receive input data and 6 TensorFlow Lite getting started guide use statistical analysis to predict an output while updating output as new data ........................................................ 8 becomes available. 7 Arm NN getting started guide........10 8 ONNX Runtime getting started guide In 2010, the so-called deep learning started. It is a fast-growing subdomain ...................................................... 16 of ML, based on Neural Networks (NN). Inspired by the human brain, 9 PyTorch getting started guide....... 17 deep learning achieved state-of-the-art results in various tasks; for example, A Revision history.............................17 Computer Vision (CV) and Natural Language Processing (NLP). Neural networks are capable of learning complex patterns from millions of examples. A huge adaptation is expected in the embedded world, where NXP is the leader. NXP created eIQ machine learning software for QorIQ Layerscape applications processors, a set of ML tools which allows developing and deploying ML applications on the QorIQ Layerscape family of devices. -

Kde-Guide-De-Developpement.Web.Pdf
KDE Published : 2017-06-26 License : GPLv2+ 1 KDE DU POINT DE VUE D'UN DÉVELOPPEUR 1. AVEZ-VOUS BESOIN DE CE LIVRE ? 2. LA PHILOSOPHIE DE KDE 3. COMMENT OBTENIR DE L'AIDE 2 1. AVEZ-VOUS BESOIN DE CE LIVRE ? Vous devriez lire ce livre si vous voulez développer pour KDE. Nous utilisons le terme développement très largement pour couvrir tout ce qui peut conduire à un changement dans le code source, ce qui inclut : Soumettre une correction de bogue Écrire une nouvelle application optimisée par la technologie KDE Contribuer à un projet existant Ajouter de la fonctionnalité aux bibliothèques de développement de KDE Dans ce livre, nous vous livrerons les bases dont vous avez besoin pour être un développeur productif. Nous décrirons les outils que vous devrez installer, montrer comment lire la documentation (et écrire la vôtre propre, une fois que vous aurez créé la nouvelle fonctionnalité !) et comment obtenir de l'aide par d'autres moyens. Nous vous présenterons la communauté KDE, qui est essentielle pour comprendre KDE parce que nous sommes un projet « open source », libre (gratuit). Les utilisateurs finaux du logiciel n'ont PAS besoin de ce livre ! Cependant, ils pourraient le trouver intéressant pour les aider à comprendre comment les logiciels complexes et riches en fonctionnalités qu'ils utilisent ont vu le jour. 3 2. LA PHILOSOPHIE DE KDE Le succès de KDE repose sur une vue globale, que nous avons trouvée à la fois pratique et motivante. Les éléments de cette philosophie de développement comprennent : L'utilisation des outils disponibles plutôt que de ré-inventer ceux existants : beaucoup des bases dont vous avez besoin pour travailler font déjà partie de KDE, comme les bibliothèques principales ou les « Kparts », et sont tout à fait au point. -

Pack, Encrypt, Authenticate Document Revision: 2021 05 02
PEA Pack, Encrypt, Authenticate Document revision: 2021 05 02 Author: Giorgio Tani Translation: Giorgio Tani This document refers to: PEA file format specification version 1 revision 3 (1.3); PEA file format specification version 2.0; PEA 1.01 executable implementation; Present documentation is released under GNU GFDL License. PEA executable implementation is released under GNU LGPL License; please note that all units provided by the Author are released under LGPL, while Wolfgang Ehrhardt’s crypto library units used in PEA are released under zlib/libpng License. PEA file format and PCOMPRESS specifications are hereby released under PUBLIC DOMAIN: the Author neither has, nor is aware of, any patents or pending patents relevant to this technology and do not intend to apply for any patents covering it. As far as the Author knows, PEA file format in all of it’s parts is free and unencumbered for all uses. Pea is on PeaZip project official site: https://peazip.github.io , https://peazip.org , and https://peazip.sourceforge.io For more information about the licenses: GNU GFDL License, see http://www.gnu.org/licenses/fdl.txt GNU LGPL License, see http://www.gnu.org/licenses/lgpl.txt 1 Content: Section 1: PEA file format ..3 Description ..3 PEA 1.3 file format details ..5 Differences between 1.3 and older revisions ..5 PEA 2.0 file format details ..7 PEA file format’s and implementation’s limitations ..8 PCOMPRESS compression scheme ..9 Algorithms used in PEA format ..9 PEA security model .10 Cryptanalysis of PEA format .12 Data recovery from -

Lossless Compression of Internal Files in Parallel Reservoir Simulation
Lossless Compression of Internal Files in Parallel Reservoir Simulation Suha Kayum Marcin Rogowski Florian Mannuss 9/26/2019 Outline • I/O Challenges in Reservoir Simulation • Evaluation of Compression Algorithms on Reservoir Simulation Data • Real-world application - Constraints - Algorithm - Results • Conclusions 2 Challenge Reservoir simulation 1 3 Reservoir Simulation • Largest field in the world are represented as 50 million – 1 billion grid block models • Each runs takes hours on 500-5000 cores • Calibrating the model requires 100s of runs and sophisticated methods • “History matched” model is only a beginning 4 Files in Reservoir Simulation • Internal Files • Input / Output Files - Interact with pre- & post-processing tools Date Restart/Checkpoint Files 5 Reservoir Simulation in Saudi Aramco • 100’000+ simulations annually • The largest simulation of 10 billion cells • Currently multiple machines in TOP500 • Petabytes of storage required 600x • Resources are Finite • File Compression is one solution 50x 6 Compression algorithm evaluation 2 7 Compression ratio Tested a number of algorithms on a GRID restart file for two models 4 - Model A – 77.3 million active grid blocks 3.5 - Model K – 8.7 million active grid blocks 3 - 15.6 GB and 7.2 GB respectively 2.5 2 Compression ratio is between 1.5 1 compression ratio compression - From 2.27 for snappy (Model A) 0.5 0 - Up to 3.5 for bzip2 -9 (Model K) Model A Model K lz4 snappy gzip -1 gzip -9 bzip2 -1 bzip2 -9 8 Compression speed • LZ4 and Snappy significantly outperformed other algorithms -
Oak Park Area Visitor Guide
OAK PARK AREA VISITOR GUIDE COMMUNITIES Bellwood Berkeley Broadview Brookfield Elmwood Park Forest Park Franklin Park Hillside Maywood Melrose Park Northlake North Riverside Oak Park River Forest River Grove Riverside Schiller Park Westchester www.visitoakpark.comvisitoakpark.com | 1 OAK PARK AREA VISITORS GUIDE Table of Contents WELCOME TO THE OAK PARK AREA ..................................... 4 COMMUNITIES ....................................................................... 6 5 WAYS TO EXPERIENCE THE OAK PARK AREA ..................... 8 BEST BETS FOR EVERY SEASON ........................................... 13 OAK PARK’S BUSINESS DISTRICTS ........................................ 15 ATTRACTIONS ...................................................................... 16 ACCOMMODATIONS ............................................................ 20 EATING & DRINKING ............................................................ 22 SHOPPING ............................................................................ 34 ARTS & CULTURE .................................................................. 36 EVENT SPACES & FACILITIES ................................................ 39 LOCAL RESOURCES .............................................................. 41 TRANSPORTATION ............................................................... 46 ADVERTISER INDEX .............................................................. 47 SPRING/SUMMER 2018 EDITION Compiled & Edited By: Kevin Kilbride & Valerie Revelle Medina Visit Oak Park -
![User Commands GZIP ( 1 ) Gzip, Gunzip, Gzcat – Compress Or Expand Files Gzip [ –Acdfhllnnrtvv19 ] [–S Suffix] [ Name ... ]](https://docslib.b-cdn.net/cover/1609/user-commands-gzip-1-gzip-gunzip-gzcat-compress-or-expand-files-gzip-acdfhllnnrtvv19-s-suffix-name-561609.webp)
User Commands GZIP ( 1 ) Gzip, Gunzip, Gzcat – Compress Or Expand Files Gzip [ –Acdfhllnnrtvv19 ] [–S Suffix] [ Name ... ]
User Commands GZIP ( 1 ) NAME gzip, gunzip, gzcat – compress or expand files SYNOPSIS gzip [–acdfhlLnNrtvV19 ] [– S suffix] [ name ... ] gunzip [–acfhlLnNrtvV ] [– S suffix] [ name ... ] gzcat [–fhLV ] [ name ... ] DESCRIPTION Gzip reduces the size of the named files using Lempel-Ziv coding (LZ77). Whenever possible, each file is replaced by one with the extension .gz, while keeping the same ownership modes, access and modification times. (The default extension is – gz for VMS, z for MSDOS, OS/2 FAT, Windows NT FAT and Atari.) If no files are specified, or if a file name is "-", the standard input is compressed to the standard output. Gzip will only attempt to compress regular files. In particular, it will ignore symbolic links. If the compressed file name is too long for its file system, gzip truncates it. Gzip attempts to truncate only the parts of the file name longer than 3 characters. (A part is delimited by dots.) If the name con- sists of small parts only, the longest parts are truncated. For example, if file names are limited to 14 characters, gzip.msdos.exe is compressed to gzi.msd.exe.gz. Names are not truncated on systems which do not have a limit on file name length. By default, gzip keeps the original file name and timestamp in the compressed file. These are used when decompressing the file with the – N option. This is useful when the compressed file name was truncated or when the time stamp was not preserved after a file transfer. Compressed files can be restored to their original form using gzip -d or gunzip or gzcat. -

Software to Extract Cab Files
Software to extract cab files click here to download You can use WinZip to extract CAB files by following the steps listed below. file extension associated with WinZip program, just double-click on the file. PeaZip offers read-only support (open and extract cab files) for Microsoft Cabinet file format, providing a free alternative utility to open (list content) and www.doorway.ru packages, or disassemble single files from the container, under Windows and Linux operating systems. Moreover, the OS can create, extract, or rebuild cab files. This means you do not require any additional third-party software for this task. All CAB. For a number of years, Microsoft has www.doorway.ru files to compress software that was distributed on disks. Originally, these files were used to minimize the number . The InstallShield installer program makes files with the CAB However, you can also open or extract CAB files with a file decompression tool. Open, browse, extract, or view Microsoft CAB files with Altap Salamander File Manager. High quality software with emphasis on error states. Affordable cost: . Microsoft uses cab files to package software programs. You can view the contents of a cab file by unzipping it and extracting its contents to a. Hi, I need some help www.doorway.ru files. I have to extract a patch for one game, so i used universal extractor for to extract www.doorway.ru Now I have to. cab Extension - List of programs that can www.doorway.ru files. www.doorway.ru, Inventoria Stock Manager, NCH Software, Extract with Express Zip, Low.