Lossless Compression with Latent Variable Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Survey Paper on Different Speech Compression Techniques
Vol-2 Issue-5 2016 IJARIIE-ISSN (O)-2395-4396 A Survey Paper on Different Speech Compression Techniques Kanawade Pramila.R1, Prof. Gundal Shital.S2 1 M.E. Electronics, Department of Electronics Engineering, Amrutvahini College of Engineering, Sangamner, Maharashtra, India. 2 HOD in Electronics Department, Department of Electronics Engineering , Amrutvahini College of Engineering, Sangamner, Maharashtra, India. ABSTRACT This paper describes the different types of speech compression techniques. Speech compression can be divided into two main types such as lossless and lossy compression. This survey paper has been written with the help of different types of Waveform-based speech compression, Parametric-based speech compression, Hybrid based speech compression etc. Compression is nothing but reducing size of data with considering memory size. Speech compression means voiced signal compress for different application such as high quality database of speech signals, multimedia applications, music database and internet applications. Today speech compression is very useful in our life. The main purpose or aim of speech compression is to compress any type of audio that is transfer over the communication channel, because of the limited channel bandwidth and data storage capacity and low bit rate. The use of lossless and lossy techniques for speech compression means that reduced the numbers of bits in the original information. By the use of lossless data compression there is no loss in the original information but while using lossy data compression technique some numbers of bits are loss. Keyword: - Bit rate, Compression, Waveform-based speech compression, Parametric-based speech compression, Hybrid based speech compression. 1. INTRODUCTION -1 Speech compression is use in the encoding system. -
![Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020](https://docslib.b-cdn.net/cover/5419/arxiv-2004-10531v1-cs-oh-8-apr-2020-215419.webp)
Arxiv:2004.10531V1 [Cs.OH] 8 Apr 2020
ROOT I/O compression improvements for HEP analysis Oksana Shadura1;∗ Brian Paul Bockelman2;∗∗ Philippe Canal3;∗∗∗ Danilo Piparo4;∗∗∗∗ and Zhe Zhang1;y 1University of Nebraska-Lincoln, 1400 R St, Lincoln, NE 68588, United States 2Morgridge Institute for Research, 330 N Orchard St, Madison, WI 53715, United States 3Fermilab, Kirk Road and Pine St, Batavia, IL 60510, United States 4CERN, Meyrin 1211, Geneve, Switzerland Abstract. We overview recent changes in the ROOT I/O system, increasing per- formance and enhancing it and improving its interaction with other data analy- sis ecosystems. Both the newly introduced compression algorithms, the much faster bulk I/O data path, and a few additional techniques have the potential to significantly to improve experiment’s software performance. The need for efficient lossless data compression has grown significantly as the amount of HEP data collected, transmitted, and stored has dramatically in- creased during the LHC era. While compression reduces storage space and, potentially, I/O bandwidth usage, it should not be applied blindly: there are sig- nificant trade-offs between the increased CPU cost for reading and writing files and the reduce storage space. 1 Introduction In the past years LHC experiments are commissioned and now manages about an exabyte of storage for analysis purposes, approximately half of which is used for archival purposes, and half is used for traditional disk storage. Meanwhile for HL-LHC storage requirements per year are expected to be increased by factor 10 [1]. arXiv:2004.10531v1 [cs.OH] 8 Apr 2020 Looking at these predictions, we would like to state that storage will remain one of the major cost drivers and at the same time the bottlenecks for HEP computing. -

Panstamps Documentation Release V0.5.3
panstamps Documentation Release v0.5.3 Dave Young 2020 Getting Started 1 Installation 3 1.1 Troubleshooting on Mac OSX......................................3 1.2 Development...............................................3 1.2.1 Sublime Snippets........................................4 1.3 Issues...................................................4 2 Command-Line Usage 5 3 Documentation 7 4 Command-Line Tutorial 9 4.1 Command-Line..............................................9 4.1.1 JPEGS.............................................. 12 4.1.2 Temporal Constraints (Useful for Moving Objects)...................... 17 4.2 Importing to Your Own Python Script.................................. 18 5 Installation 19 5.1 Troubleshooting on Mac OSX...................................... 19 5.2 Development............................................... 19 5.2.1 Sublime Snippets........................................ 20 5.3 Issues................................................... 20 6 Command-Line Usage 21 7 Documentation 23 8 Command-Line Tutorial 25 8.1 Command-Line.............................................. 25 8.1.1 JPEGS.............................................. 28 8.1.2 Temporal Constraints (Useful for Moving Objects)...................... 33 8.2 Importing to Your Own Python Script.................................. 34 8.2.1 Subpackages.......................................... 35 8.2.1.1 panstamps.commonutils (subpackage)........................ 35 8.2.1.2 panstamps.image (subpackage)............................ 35 8.2.2 Classes............................................ -

Making Color Images with the GIMP Las Cumbres Observatory Global Telescope Network Color Imaging: the GIMP Introduction
Las Cumbres Observatory Global Telescope Network Making Color Images with The GIMP Las Cumbres Observatory Global Telescope Network Color Imaging: The GIMP Introduction These instructions will explain how to use The GIMP to take those three images and composite them to make a color image. Users will also learn how to deal with minor imperfections in their images. Note: The GIMP cannot handle FITS files effectively, so to produce a color image, users will have needed to process FITS files and saved them as grayscale TIFF or JPEG files as outlined in the Basic Imaging section. Separately filtered FITS files are available for you to use on the Color Imaging page. The GIMP can be downloaded for Windows, Mac, and Linux from: www.gimp.org Loading Images Loading TIFF/JPEG Files Users will be processing three separate images to make the RGB color images. When opening files in The GIMP, you can select multiple files at once by holding the Ctrl button and clicking on the TIFF or JPEG files you wish to use to make a color image. Go to File > Open. Image Mode RGB Mode Because these images are saved as grayscale, all three images need to be converted to RGB. This is because color images are made from (R)ed, (G)reen, and (B)lue picture elements (pixels). The different shades of gray in the image show the intensity of light in each of the wavelengths through the red, green, and blue filters. The colors themselves are not recorded in the image. Adding Color Information For the moment, these images are just grayscale. -

Lossless Compression of Audio Data
CHAPTER 12 Lossless Compression of Audio Data ROBERT C. MAHER OVERVIEW Lossless data compression of digital audio signals is useful when it is necessary to minimize the storage space or transmission bandwidth of audio data while still maintaining archival quality. Available techniques for lossless audio compression, or lossless audio packing, generally employ an adaptive waveform predictor with a variable-rate entropy coding of the residual, such as Huffman or Golomb-Rice coding. The amount of data compression can vary considerably from one audio waveform to another, but ratios of less than 3 are typical. Several freeware, shareware, and proprietary commercial lossless audio packing programs are available. 12.1 INTRODUCTION The Internet is increasingly being used as a means to deliver audio content to end-users for en tertainment, education, and commerce. It is clearly advantageous to minimize the time required to download an audio data file and the storage capacity required to hold it. Moreover, the expec tations of end-users with regard to signal quality, number of audio channels, meta-data such as song lyrics, and similar additional features provide incentives to compress the audio data. 12.1.1 Background In the past decade there have been significant breakthroughs in audio data compression using lossy perceptual coding [1]. These techniques lower the bit rate required to represent the signal by establishing perceptual error criteria, meaning that a model of human hearing perception is Copyright 2003. Elsevier Science (USA). 255 AU rights reserved. 256 PART III / APPLICATIONS used to guide the elimination of excess bits that can be either reconstructed (redundancy in the signal) orignored (inaudible components in the signal). -
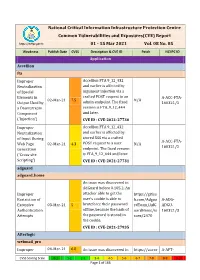
National Critical Information Infrastructure Protection Centre Common Vulnerabilities and Exposures(CVE) Report
National Critical Information Infrastructure Protection Centre Common Vulnerabilities and Exposures(CVE) Report https://nciipc.gov.in 01 - 15 Mar 2021 Vol. 08 No. 05 Weakness Publish Date CVSS Description & CVE ID Patch NCIIPC ID Application Accellion fta Improper Accellion FTA 9_12_432 Neutralization and earlier is affected by of Special argument injection via a Elements in crafted POST request to an A-ACC-FTA- 02-Mar-21 7.5 N/A Output Used by admin endpoint. The fixed 160321/1 a Downstream version is FTA_9_12_444 Component and later. ('Injection') CVE ID : CVE-2021-27730 Improper Accellion FTA 9_12_432 Neutralization and earlier is affected by of Input During stored XSS via a crafted A-ACC-FTA- Web Page 02-Mar-21 4.3 POST request to a user N/A 160321/2 Generation endpoint. The fixed version ('Cross-site is FTA_9_12_444 and later. Scripting') CVE ID : CVE-2021-27731 adguard adguard_home An issue was discovered in AdGuard before 0.105.2. An Improper attacker able to get the https://githu Restriction of user's cookie is able to b.com/Adgua A-ADG- Excessive 03-Mar-21 5 bruteforce their password rdTeam/AdG ADGU- Authentication offline, because the hash of uardHome/is 160321/3 Attempts the password is stored in sues/2470 the cookie. CVE ID : CVE-2021-27935 Afterlogic webmail_pro Improper 04-Mar-21 6.8 An issue was discovered in https://auror A-AFT- CVSS Scoring Scale 0-1 1-2 2-3 3-4 4-5 5-6 6-7 7-8 8-9 9-10 Page 1 of 166 Weakness Publish Date CVSS Description & CVE ID Patch NCIIPC ID Limitation of a AfterLogic Aurora through amail.wordpr WEBM- Pathname to a 8.5.3 and WebMail Pro ess.com/202 160321/4 Restricted through 8.5.3, when DAV is 1/02/03/add Directory enabled. -
![Arxiv:2002.01657V1 [Eess.IV] 5 Feb 2020 Port Lossless Model to Compress Images Lossless](https://docslib.b-cdn.net/cover/2332/arxiv-2002-01657v1-eess-iv-5-feb-2020-port-lossless-model-to-compress-images-lossless-882332.webp)
Arxiv:2002.01657V1 [Eess.IV] 5 Feb 2020 Port Lossless Model to Compress Images Lossless
LEARNED LOSSLESS IMAGE COMPRESSION WITH A HYPERPRIOR AND DISCRETIZED GAUSSIAN MIXTURE LIKELIHOODS Zhengxue Cheng, Heming Sun, Masaru Takeuchi, Jiro Katto Department of Computer Science and Communications Engineering, Waseda University, Tokyo, Japan. ABSTRACT effectively in [12, 13, 14]. Some methods decorrelate each Lossless image compression is an important task in the field channel of latent codes and apply deep residual learning to of multimedia communication. Traditional image codecs improve the performance as [15, 16, 17]. However, deep typically support lossless mode, such as WebP, JPEG2000, learning based lossless compression has rarely discussed. FLIF. Recently, deep learning based approaches have started One related work is L3C [18] to propose a hierarchical archi- to show the potential at this point. HyperPrior is an effective tecture with 3 scales to compress images lossless. technique proposed for lossy image compression. This paper In this paper, we propose a learned lossless image com- generalizes the hyperprior from lossy model to lossless com- pression using a hyperprior and discretized Gaussian mixture pression, and proposes a L2-norm term into the loss function likelihoods. Our contributions mainly consist of two aspects. to speed up training procedure. Besides, this paper also in- First, we generalize the hyperprior from lossy model to loss- vestigated different parameterized models for latent codes, less compression model, and propose a loss function with L2- and propose to use Gaussian mixture likelihoods to achieve norm for lossless compression to speed up training. Second, adaptive and flexible context models. Experimental results we investigate four parameterized distributions and propose validate our method can outperform existing deep learning to use Gaussian mixture likelihoods for the context model. -

Image Formats
Image Formats Ioannis Rekleitis Many different file formats • JPEG/JFIF • Exif • JPEG 2000 • BMP • GIF • WebP • PNG • HDR raster formats • TIFF • HEIF • PPM, PGM, PBM, • BAT and PNM • BPG CSCE 590: Introduction to Image Processing https://en.wikipedia.org/wiki/Image_file_formats 2 Many different file formats • JPEG/JFIF (Joint Photographic Experts Group) is a lossy compression method; JPEG- compressed images are usually stored in the JFIF (JPEG File Interchange Format) >ile format. The JPEG/JFIF >ilename extension is JPG or JPEG. Nearly every digital camera can save images in the JPEG/JFIF format, which supports eight-bit grayscale images and 24-bit color images (eight bits each for red, green, and blue). JPEG applies lossy compression to images, which can result in a signi>icant reduction of the >ile size. Applications can determine the degree of compression to apply, and the amount of compression affects the visual quality of the result. When not too great, the compression does not noticeably affect or detract from the image's quality, but JPEG iles suffer generational degradation when repeatedly edited and saved. (JPEG also provides lossless image storage, but the lossless version is not widely supported.) • JPEG 2000 is a compression standard enabling both lossless and lossy storage. The compression methods used are different from the ones in standard JFIF/JPEG; they improve quality and compression ratios, but also require more computational power to process. JPEG 2000 also adds features that are missing in JPEG. It is not nearly as common as JPEG, but it is used currently in professional movie editing and distribution (some digital cinemas, for example, use JPEG 2000 for individual movie frames). -

Comparison of Image Compressions: Analog Transformations P
Proceedings Comparison of Image Compressions: Analog † Transformations P Jose Balsa P CITIC Research Center, Universidade da Coruña (University of A Coruña), 15071 A Coruña, Spain; [email protected] † Presented at the 3rd XoveTIC Conference, A Coruña, Spain, 8–9 October 2020. Published: 21 August 2020 Abstract: A comparison between the four most used transforms, the discrete Fourier transform (DFT), discrete cosine transform (DCT), the Walsh–Hadamard transform (WHT) and the Haar- wavelet transform (DWT), for the transmission of analog images, varying their compression and comparing their quality, is presented. Additionally, performance tests are done for different levels of white Gaussian additive noise. Keywords: analog image transformation; analog image compression; analog image quality 1. Introduction Digitized image coding systems employ reversible mathematical transformations. These transformations change values and function domains in order to rearrange information in a way that condenses information important to human vision [1]. In the new domain, it is possible to filter out relevant information and discard information that is irrelevant or of lesser importance for image quality [2]. Both digital and analog systems use the same transformations in source coding. Some examples of digital systems that employ these transformations are JPEG, M-JPEG, JPEG2000, MPEG- 1, 2, 3 and 4, DV and HDV, among others. Although digital systems after transformation and filtering make use of digital lossless compression techniques, such as Huffman. In this work, we aim to make a comparison of the most commonly used transformations in state- of-the-art image compression systems. Typically, the transformations used to compress analog images work either on the entire image or on regions of the image. -

Frequently Asked Questions
Frequently Asked Questions After more than 16 years of business, we’ve run into a lot of questions from a lot of different people, each with different needs and requirements. Sometimes the questions are about our company or about the exact nature of dynamic imaging, but, no matter the question, we’re happy to answer and discuss any imaging solutions that may help the success of your business. So take a look... we may have already answered your question. If we haven’t, please feel free to contact us at www.liquidpixels.com. How long has LiquidPixels been in business? Do you have an API? LiquidPixels started in 2000 and has been going strong since LiquiFire OS uses our easy-to-learn LiquiFire® Image Chains to then, bringing dynamic imaging to the world of e-commerce. describe the imaging manipulations you wish to produce. Can you point me to live websites that use your services? What is the average time required to implement LiquiFire OS LiquidPixels’ website features some of our customers who into my environment? benefit from the LiquiFire® Operating System (OS). Our Whether you choose our turnkey LiquiFire Imaging Server™ sales team will be happy to showcase existing LiquiFire OS solutions or our LiquiFire Hosted Service™, LiquiFire OS can solutions or show you how incredible your website and be implemented in less than a day. Then your creative team can product imagery would look with the power of LiquiFire OS get to the exciting part: developing your website’s interface, behind it. presentation, and workflow. What types of images are required (file format, quality, etc.)? LiquiFire OS supports all common image formats, including JPEG, PNG, TIFF, WebP, JXR, and GIF and also allows for PostScript and PDF manipulation. -

Data Compression
Data Compression Data Compression Compression reduces the size of a file: ! To save space when storing it. ! To save time when transmitting it. ! Most files have lots of redundancy. Who needs compression? ! Moore's law: # transistors on a chip doubles every 18-24 months. ! Parkinson's law: data expands to fill space available. ! Text, images, sound, video, . All of the books in the world contain no more information than is Reference: Chapter 22, Algorithms in C, 2nd Edition, Robert Sedgewick. broadcast as video in a single large American city in a single year. Reference: Introduction to Data Compression, Guy Blelloch. Not all bits have equal value. -Carl Sagan Basic concepts ancient (1950s), best technology recently developed. Robert Sedgewick and Kevin Wayne • Copyright © 2005 • http://www.Princeton.EDU/~cos226 2 Applications of Data Compression Encoding and Decoding hopefully uses fewer bits Generic file compression. Message. Binary data M we want to compress. ! Files: GZIP, BZIP, BOA. Encode. Generate a "compressed" representation C(M). ! Archivers: PKZIP. Decode. Reconstruct original message or some approximation M'. ! File systems: NTFS. Multimedia. M Encoder C(M) Decoder M' ! Images: GIF, JPEG. ! Sound: MP3. ! Video: MPEG, DivX™, HDTV. Compression ratio. Bits in C(M) / bits in M. Communication. ! ITU-T T4 Group 3 Fax. Lossless. M = M', 50-75% or lower. ! V.42bis modem. Ex. Natural language, source code, executables. Databases. Google. Lossy. M ! M', 10% or lower. Ex. Images, sound, video. 3 4 Ancient Ideas Run-Length Encoding Ancient ideas. Natural encoding. (19 " 51) + 6 = 975 bits. ! Braille. needed to encode number of characters per line ! Morse code. -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S.