Rethinking the Application-Database Interface Alvin K. Cheung
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The State of the Feather
The State of the Feather An Overview and Year In Review of The Apache Software Foundation The Overview • Not a replacement for “Behind the Scenes...” • To appreciate where we are - • Need to understand how we got here 2 In the beginning... • There was The Apache Group • But we needed a more formal and legal entity • Thus was born: The Apache Software Foundation (April/June 1999) • A non-profit, 501(c)3 Corporation • Governed by members - member based entity 3 “Hierarchies” Development Administrative PMC Members Committers Board Contributors Officers Patchers/Buggers Members Users 4 At the start • There were only 21 members • And 2 “projects”: httpd and Concom • All servers and services were donated 5 Today... • We have 227 members... • ~54 TLPs • ~25 Incubator podlings • Tons of committers (literally) 6 The only constant... • Has been Change (and Growth!) • Over the years, the ASF has adjusted to handle the increasing “administrative” aspects of the foundation • While remaining true to our goals and our beginnings 7 Handling growth • ASF dedicated to providing the infrastructure resources needed • Volunteers supplemented by contracted out SysAdmin • Paperwork handling supplemented by contracted out SecAssist • Accounting services as needed • Using pro-bono legal services 8 Staying true • Policy still firmly in the hands of the ASF • Use outsourced help where needed – Help volunteers, not replace them – Only for administrative efforts • Infrastructure itself is a service provided by the ASF • Board/Infra/etc exists so projects and people -
TMS Xdata Documentation
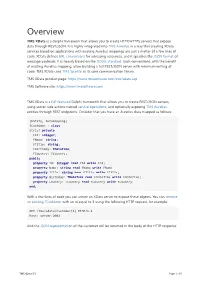
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

Near Real-Time Synchronization Approach for Heterogeneous Distributed Databases
DBKDA 2015 : The Seventh International Conference on Advances in Databases, Knowledge, and Data Applications Near Real-time Synchronization Approach for Heterogeneous Distributed Databases Hassen Fadoua, Grissa Touzi Amel LIPAH FST, University of Tunis El Manar Tunis, Tunisia e-mail: [email protected], [email protected] Abstract—The decentralization of organizational units led to column is not available in the list of the existing relational database distribution in order to solve high availability and database management systems (RDBMS). This storage performance issues regarding the highly exhausting consumers unit’s variety holds the first problem discussed in this paper: nowadays. The distributed database designers rely on data data exchange format between the heterogeneous nodes in replication to make data as near as possible from the the same Distributed Database Management System requesting systems. The data replication involves a sensitive (DDBMS). The process of transforming raw data from operation to keep data integrity among the distributed architecture: data synchronization. While this operation is source system to an exchange format is called serialization. necessary to almost every distributed system, it needs an in The reverse operation, executed by the receiver side, is depth study before deciding which entity to duplicate and called deserialization. In the heterogeneous context, the which site will hold the copy. Moreover, the distributed receiver side is different from one site to another, and thus environment may hold different types of databases adding the deserialization implementation may vary depending on another level of complexity to the synchronization process. In the local DBMS. This data serialization is a very sensitive the near real-time duplication process, the synchronization task that may speed down the synchronization process and delay is a crucial criterion that may change depending on flood the network. -

Objektově Orientovaný Přístup K Perzistentní Vrstvě V Prostředí Java Object Oriented Database Access in Java
Objektově orientovaný přístup k perzistentní vrstvě v prostředí Java Object Oriented Database Access in Java Roman Janás Bakalářská práce 2014 *** nascannované zadání str. 1 *** *** nascannované zadání str. 2 *** UTB ve Zlíně, Fakulta aplikované informatiky, 2014 4 ABSTRAKT Předmětem bakalářské práce „Objektově orientovaný přístup k perzistentní vrstvě v prostředí Java“ je analýza dostupných ORM aplikačních rámců pro programovací jazyk Java. Cílem je zjistit, který aplikační rámec je v současnosti nejlépe použitelný. Obsahem práce je také srovnání s technologií JDBC - porovnání výkonnosti jednotlivých řešení a popis používaných návrhových vzorů. Praktická část názorně ukazuje práci se zvolenými aplikačními rámci a výsledky výkonnostních testů. Klíčová slova: ORM, Java, návrhové vzory, JDBC, Hibernate, Cayenne ABSTRACT The subject of the submitted thesis “Object Oriented Database Access in Java” is analysis of available ORM frameworks for programming language Java. The goal is to determine which framework is the most applicable. The content is also comparison with JDBC technology – comparison of efficiency of each solutions and description of used design patterns. The practical part clearly shows work with chosen frameworks and results of efficiency tests. Keywords: ORM, Java, design patterns, JDBC, Hibernate, Cayenne UTB ve Zlíně, Fakulta aplikované informatiky, 2014 5 Na tomto místě bych rád poděkoval Ing. Janu Šípkovi za cenné připomínky a odborné rady, kterými přispěl k vypracování této bakalářské práce. Dále děkuji svým kolegům z -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

Innodb Plugin 1.0 for Mysql 5.1 User's Guide Innodb Plugin 1.0 for Mysql 5.1 User's Guide
InnoDB Plugin 1.0 for MySQL 5.1 User's Guide InnoDB Plugin 1.0 for MySQL 5.1 User's Guide Abstract This is the User's Guide for InnoDB Plugin 1.0.8 for MySQL 5.1. Starting with version 5.1, MySQL AB has promoted the idea of a “pluggable” storage engine architecture , which permits multiple storage engines to be added to MySQL. Beginning with MySQL version 5.1, it is possible for users to swap out one version of InnoDB and use another. The pluggable storage engine architecture also permits Innobase Oy to release new versions of InnoDB containing bug fixes and new features independently of the release cycle for MySQL. This User's Guide documents the installation and removal procedures and the additional features of the InnoDB Plugin 1.0.8 for MySQL 5.1. WARNING: Because the InnoDB Plugin introduces a new file format, restrictions apply to the use of a database created with the InnoDB Plugin with earlier versions of InnoDB, when using mysqldump or MySQL replication and if you use the InnoDB Hot Backup utility. See Section 1.5, “Operational Restrictions”. For legal information, see the Legal Notices. Document generated on: 2014-01-30 (revision: 37573) Table of Contents Preface and Legal Notices ........................................................................................................... vii 1 Introduction to the InnoDB Plugin ............................................................................................... 1 1.1 Overview ....................................................................................................................... -

Cayenne Guide
Cayenne Guide Version 4.1 (4.1) Table of Contents 1. Object Relational Mapping with Cayenne . 2 1.1. Setup . 2 1.2. Cayenne Mapping Structure . 3 1.3. CayenneModeler Application . 5 2. Cayenne Framework . 8 2.1. Including Cayenne in a Project . 8 2.2. Starting Cayenne. 8 2.3. Persistent Objects and ObjectContext . 11 2.4. Expressions . 18 2.5. Orderings . 24 2.6. Queries . 24 2.7. Lifecycle Events . 37 2.8. Performance Tuning . 43 2.9. Customizing Cayenne Runtime . 50 3. Cayenne Framework - Remote Object Persistence. 61 3.1. Introduction to ROP . 61 3.2. ROP Deployment . 62 4. DB-First Flow. 63 4.1. Introduction. 63 4.2. Filtering. 64 4.3. Other Settings . 72 4.4. Reverse Engineering in Cayenne Modeler . 73 5. Additional Modules . 76 5.1. Cache Invalidation Extension . 76 5.2. Commit log extension . 77 5.3. Crypto extension. 78 5.4. JCache integration . 80 5.5. Project compatibility extension . 82 5.6. Apache Velocity Extension . 82 5.7. Cayenne Web Extension . 83 5.8. Cayenne OSGI extension . 84 5.9. Cayenne ROP Server Extension. 84 6. Build Tools . 85 6.1. Maven Plugin. 85 6.2. Gradle Plugin . 92 6.3. Ant Tasks . 96 7. Appendix A. Configuration Properties . 97 8. Appendix B. Service Collections . 100 9. Appendix C. Expressions BNF . 102 Copyright © 2011-2020 Apache Software Foundation and individual authors License Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. -

A Fully In-Browser Client and Server Web Application Debug and Test Environment
LIBERATED: A fully in-browser client and server web application debug and test environment Derrell Lipman University of Massachusetts Lowell Abstract ging and testing the entire application, both frontend and backend, within the browser environment. Once the ap- Traditional web-based client-server application devel- plication is tested, the backend portion of the code can opment has been accomplished in two separate pieces: be moved to the production server where it operates with the frontend portion which runs on the client machine has little, if any, additional debugging. been written in HTML and JavaScript; and the backend portion which runs on the server machine has been writ- 1.1 Typical web application development ten in PHP, ASP.net, or some other “server-side” lan- guage which typically interfaces to a database. The skill There are many skill sets required to implement a sets required for these two pieces are different. modern web application. On the client side, initially, the In this paper, I demonstrate a new methodology user interface must be defined. A visual designer, in con- for web-based client-server application development, in junction with a human-factors engineer, may determine which a simulated server is built into the browser envi- what features should appear in the interface, and how to ronment to run the backend code. This allows the fron- best organize them for ease of use and an attractive de- tend to issue requests to the backend, and the developer sign. to step, using a debugger, directly from frontend code into The language used to write the user interface code is backend code, and to debug and test both the frontend most typically JavaScript [6]. -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/ -

Alibaba Cloud Apsara Stack Enterprise
Alibaba Cloud Apsara Stack Enterprise Technical Whitepaper Version: 1807 Issue: 20180731 2 | Introduction | Apsara Stack Enterprise Apsara Stack Enterprise Technical Whitepaper / Legal disclaimer Legal disclaimer Alibaba Cloud reminds you to carefully read and fully understand the terms and conditions of this legal disclaimer before you read or use this document. If you have read or used this document, it shall be deemed as your total acceptance of this legal disclaimer. 1. You shall download and obtain this document from the Alibaba Cloud website or other Alibaba Cloud-authorized channels, and use this document for your own legal business activities only. The content of this document is considered confidential information of Alibaba Cloud. You shall strictly abide by the confidentiality obligations. No part of this document shall be disclosed or provided to any third party for use without the prior written consent of Alibaba Cloud. 2. No part of this document shall be excerpted, translated, reproduced, transmitted, or disseminat ed by any organization, company, or individual in any form or by any means without the prior written consent of Alibaba Cloud. 3. The content of this document may be changed due to product version upgrades, adjustment s, or other reasons. Alibaba Cloud reserves the right to modify the content of this document without notice and the updated versions of this document will be occasionally released through Alibaba Cloud-authorized channels. You shall pay attention to the version changes of this document as they occur and download and obtain the most up-to-date version of this document from Alibaba Cloud-authorized channels. -

Ask Bjørn Hansen Develooper LLC [email protected]
If this text is too small to read, move closer! Real World Web Scalability Slides at http://develooper.com/talks/ Ask Bjørn Hansen Develooper LLC [email protected] r8 Hello. • I’m Ask Bjørn Hansen • Tutorial in a box 59 minutes! • 53* brilliant° tips to make your website keep working past X requests/transactions per T time • Requiring minimal extra work! (or money) • Concepts applicable to ~all languages and platforms! * Estimate, your mileage may vary ° Well, a lot of them are pretty good Construction Ahead! • Conflicting advice ahead • Not everything here is applicable to everything • Ways to “think scalable” rather than end- all-be-all solutions Questions ... • Did anyone see this talk at OSCON or the MySQL UC before? • ... are using Perl? PHP? Python? Java? Ruby? • ... Oracle? • The first, last and only lesson: • Think Horizontal! • Everything in your architecture, not just the front end web servers • Micro optimizations and other implementation details –– Bzzzzt! Boring! (blah blah blah, we’ll get to the cool stuff in a moment!) Benchmarking techniques • Scalability isn't the same as processing time • Not “how fast” but “how many” • Test “force”, not speed. Think amps, not voltage • Test scalability, not just performance • Use a realistic load • Test with "slow clients" Vertical scaling • “Get a bigger server” • “Use faster CPUs” • Can only help so much (with bad scale/$ value) • A server twice as fast is more than twice as expensive • Super computers are horizontally scaled! Horizontal scaling • “Just add another box” (or another thousand or ...) • Good to great ... • Implementation, scale your system a few times • Architecture, scale dozens or hundreds of times • Get the big picture right first, do micro optimizations later Scalable Application Servers Don’t paint yourself into a corner from the start Run Many of Them • For your application..