Ask Bjørn Hansen Develooper LLC [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
TMS Xdata Documentation
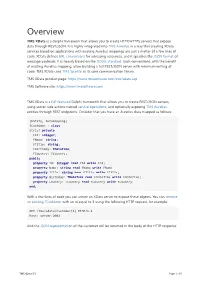
Overview TMS XData is a Delphi framework that allows you to create HTTP/HTTPS servers that expose data through REST/JSON. It is highly integrated into TMS Aurelius in a way that creating XData services based on applications with existing Aurelius mappings are just a matter of a few lines of code. XData defines URL conventions for adressing resources, and it specifies the JSON format of message payloads. It is heavily based on the OData standard. Such conventions, with the benefit of existing Aurelius mapping, allow building a full REST/JSON server with minimum writing of code. TMS XData uses TMS Sparkle as its core communication library. TMS XData product page: https://www.tmssoftware.com/site/xdata.asp TMS Software site: https://www.tmssoftware.com TMS XData is a full-featured Delphi framework that allows you to create REST/JSON servers, using server-side actions named service operations, and optionally exposing TMS Aurelius entities through REST endpoints. Consider that you have an Aurelius class mapped as follows: [Entity, Automapping] TCustomer = class strict private FId: integer; FName: string; FTitle: string; FBirthday: TDateTime; FCountry: TCountry; public property Id: Integer read FId write FId; property Name: string read FName write FName; property Title: string read FTitle write FTitle; property Birthday: TDateTime read FDateTime write FDateTime; property Country: TCountry read FCountry write FCountry; end; With a few lines of code you can create an XData server to expose these objects. You can retrieve an existing TCustomer -

Near Real-Time Synchronization Approach for Heterogeneous Distributed Databases
DBKDA 2015 : The Seventh International Conference on Advances in Databases, Knowledge, and Data Applications Near Real-time Synchronization Approach for Heterogeneous Distributed Databases Hassen Fadoua, Grissa Touzi Amel LIPAH FST, University of Tunis El Manar Tunis, Tunisia e-mail: [email protected], [email protected] Abstract—The decentralization of organizational units led to column is not available in the list of the existing relational database distribution in order to solve high availability and database management systems (RDBMS). This storage performance issues regarding the highly exhausting consumers unit’s variety holds the first problem discussed in this paper: nowadays. The distributed database designers rely on data data exchange format between the heterogeneous nodes in replication to make data as near as possible from the the same Distributed Database Management System requesting systems. The data replication involves a sensitive (DDBMS). The process of transforming raw data from operation to keep data integrity among the distributed architecture: data synchronization. While this operation is source system to an exchange format is called serialization. necessary to almost every distributed system, it needs an in The reverse operation, executed by the receiver side, is depth study before deciding which entity to duplicate and called deserialization. In the heterogeneous context, the which site will hold the copy. Moreover, the distributed receiver side is different from one site to another, and thus environment may hold different types of databases adding the deserialization implementation may vary depending on another level of complexity to the synchronization process. In the local DBMS. This data serialization is a very sensitive the near real-time duplication process, the synchronization task that may speed down the synchronization process and delay is a crucial criterion that may change depending on flood the network. -

Hidden Gears of Your Application
Hidden gears of your application Sergej Kurakin Problem ● Need for quick response ● Need for many updates ● Need for different jobs done ● Need for task to be done as different user on server side ● Near real-time job start ● Load distribution Job Queue ● You put job to queue ● Worker takes the job and makes it done Job Queue using Crons ● Many different implementations ● Perfect for small scale ● Available on many systems/servers ● Crons are limited to running once per minute ● Harder to distribute load Gearman Job Server ● Job Queue ● http://gearman.org/ ● C/C++ ● Multi-language ● Scalable and Fault Tolerant ● Huge message size (up to 4 gig) Gearman Stack Gearman Job Types Normal Job Background Job ● Run Job ● Run Job in ● Return Result Background ● No Return of Result Gearman Parallel Tasks Gearman Supported Languages ● C ● Java ● Perl ● C#/.NET ● NodeJS ● Ruby ● PHP ● Go ● Python ● Lisp Job Priority ● Low ● Normal ● High Gearman Worker Example <?php // Reverse Worker Code $worker = new GearmanWorker(); $worker->addServer(); $worker->addFunction("reverse", function ($job) { return strrev($job->workload()); }); while ($worker->work()); Gearman Client Example <?php // Reverse Client Code $client = new GearmanClient(); $client->addServer(); print $client->do("reverse", "Hello World!"); Gearman Client Example <?php // Reverse Client Code $client = new GearmanClient(); $client->addServer(); $client->doBackground("reverse", "Hello World!"); Running Worker in Background ● CLI ● screen / tmux ● supervisord - http://supervisord.org/ ● daemontools -

VSI's Open Source Strategy
VSI's Open Source Strategy Plans and schemes for Open Source so9ware on OpenVMS Bre% Cameron / Camiel Vanderhoeven April 2016 AGENDA • Programming languages • Cloud • Integraon technologies • UNIX compability • Databases • Analy;cs • Web • Add-ons • Libraries/u;li;es • Other consideraons • SoDware development • Summary/conclusions tools • Quesons Programming languages • Scrip;ng languages – Lua – Perl (probably in reasonable shape) – Tcl – Python – Ruby – PHP – JavaScript (Node.js and friends) – Also need to consider tools and packages commonly used with these languages • Interpreted languages – Scala (JVM) – Clojure (JVM) – Erlang (poten;ally a good fit with OpenVMS; can get good support from ESL) – All the above are seeing increased adop;on 3 Programming languages • Compiled languages – Go (seeing rapid adop;on) – Rust (relavely new) – Apple Swi • Prerequisites (not all are required in all cases) – LLVM backend – Tweaks to OpenVMS C and C++ compilers – Support for latest language standards (C++) – Support for some GNU C/C++ extensions – Updates to OpenVMS C RTL and threads library 4 Programming languages 1. JavaScript 2. Java 3. PHP 4. Python 5. C# 6. C++ 7. Ruby 8. CSS 9. C 10. Objective-C 11. Perl 12. Shell 13. R 14. Scala 15. Go 16. Haskell 17. Matlab 18. Swift 19. Clojure 20. Groovy 21. Visual Basic 5 See h%p://redmonk.com/sogrady/2015/07/01/language-rankings-6-15/ Programming languages Growing programming languages, June 2015 Steve O’Grady published another edi;on of his great popularity study on programming languages: RedMonk Programming Language Rankings: June 2015. As usual, it is a very valuable piece. There are many take-away from this research. -

Technical Update & Roadmap
18/05/2018 VMS Software Inc. (VSI) Technical Update & Roadmap May 2018 Brett Cameron Agenda ▸ What we've done to date ▸ Product roadmap ▸ TCP/IP update ▸ Upcoming new products ▸ Support roadmap ▸ Storage ▸ x86 update, roadmap, and licensing ▸ x86 servers ▸ ISV programme ▸ Other stuff 1 18/05/2018 WhatDivider we’ve with done to date OpenVMS releases to date 3 OpenVMS I64 releases: Plus … Two OpenVMS Alpha Japanese version • V8.4-1H1 – Bolton releases: • DECforms V4.2 • – June 2015 V8.4-2L1 – February • DCPS V2.8 2017 • V8.4-2 - Maynard • FMS V2.6 • Standard OpenVMS – March 2016 • DECwindows Motif V1.7E release (Hudson) • V8.4-2L1 – Hudson • V8.4-2L2 - April 2017 – August 2016 • Performance build, EV6/EV7 (Felton) 2 18/05/2018 Products introduced from 2015 to date Technical achievements to date 65 Layered Product Releases 12 Open Source Releases OpenVMS Releases 4 VSI OpenVMS Statistics 515 VSI Defect Repairs 179 New Features Since V7.3-2 0 100 200 300 400 500 600 3 18/05/2018 Defect repairs 515 Total Defect Repairs 343 Source - Internal BZ VSI - Defect Repairs 118 Source - External BZ 54 Source - Quix 0 100 200 300 400 500 600 Testing hours Test Hours Per VSI OpenVMS Version TKSBRY IA64 V8.4-2L1 Test Hours V8.4-2 V8.4-1H1 0 20000 40000 60000 80000 100000 120000 140000 4 18/05/2018 ProductDivider roadmap with OpenVMS Integrity operating environment Released Planned BOE Components: • NOTARY V1.0 BOE Components: • • V8.4-2L1 operating system OpenSSL V1.02n • CSWS additional modules • • ANT V1.7-1B Perl V5.20-2A • PHP additional modules • -

List of TCP and UDP Port Numbers from Wikipedia, the Free Encyclopedia
List of TCP and UDP port numbers From Wikipedia, the free encyclopedia This is a list of Internet socket port numbers used by protocols of the transport layer of the Internet Protocol Suite for the establishment of host-to-host connectivity. Originally, port numbers were used by the Network Control Program (NCP) in the ARPANET for which two ports were required for half- duplex transmission. Later, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) needed only one port for full- duplex, bidirectional traffic. The even-numbered ports were not used, and this resulted in some even numbers in the well-known port number /etc/services, a service name range being unassigned. The Stream Control Transmission Protocol database file on Unix-like operating (SCTP) and the Datagram Congestion Control Protocol (DCCP) also systems.[1][2][3][4] use port numbers. They usually use port numbers that match the services of the corresponding TCP or UDP implementation, if they exist. The Internet Assigned Numbers Authority (IANA) is responsible for maintaining the official assignments of port numbers for specific uses.[5] However, many unofficial uses of both well-known and registered port numbers occur in practice. Contents 1 Table legend 2 Well-known ports 3 Registered ports 4 Dynamic, private or ephemeral ports 5 See also 6 References 7 External links Table legend Official: Port is registered with IANA for the application.[5] Unofficial: Port is not registered with IANA for the application. Multiple use: Multiple applications are known to use this port. Well-known ports The port numbers in the range from 0 to 1023 are the well-known ports or system ports.[6] They are used by system processes that provide widely used types of network services. -

Innodb Plugin 1.0 for Mysql 5.1 User's Guide Innodb Plugin 1.0 for Mysql 5.1 User's Guide
InnoDB Plugin 1.0 for MySQL 5.1 User's Guide InnoDB Plugin 1.0 for MySQL 5.1 User's Guide Abstract This is the User's Guide for InnoDB Plugin 1.0.8 for MySQL 5.1. Starting with version 5.1, MySQL AB has promoted the idea of a “pluggable” storage engine architecture , which permits multiple storage engines to be added to MySQL. Beginning with MySQL version 5.1, it is possible for users to swap out one version of InnoDB and use another. The pluggable storage engine architecture also permits Innobase Oy to release new versions of InnoDB containing bug fixes and new features independently of the release cycle for MySQL. This User's Guide documents the installation and removal procedures and the additional features of the InnoDB Plugin 1.0.8 for MySQL 5.1. WARNING: Because the InnoDB Plugin introduces a new file format, restrictions apply to the use of a database created with the InnoDB Plugin with earlier versions of InnoDB, when using mysqldump or MySQL replication and if you use the InnoDB Hot Backup utility. See Section 1.5, “Operational Restrictions”. For legal information, see the Legal Notices. Document generated on: 2014-01-30 (revision: 37573) Table of Contents Preface and Legal Notices ........................................................................................................... vii 1 Introduction to the InnoDB Plugin ............................................................................................... 1 1.1 Overview ....................................................................................................................... -

A Fully In-Browser Client and Server Web Application Debug and Test Environment
LIBERATED: A fully in-browser client and server web application debug and test environment Derrell Lipman University of Massachusetts Lowell Abstract ging and testing the entire application, both frontend and backend, within the browser environment. Once the ap- Traditional web-based client-server application devel- plication is tested, the backend portion of the code can opment has been accomplished in two separate pieces: be moved to the production server where it operates with the frontend portion which runs on the client machine has little, if any, additional debugging. been written in HTML and JavaScript; and the backend portion which runs on the server machine has been writ- 1.1 Typical web application development ten in PHP, ASP.net, or some other “server-side” lan- guage which typically interfaces to a database. The skill There are many skill sets required to implement a sets required for these two pieces are different. modern web application. On the client side, initially, the In this paper, I demonstrate a new methodology user interface must be defined. A visual designer, in con- for web-based client-server application development, in junction with a human-factors engineer, may determine which a simulated server is built into the browser envi- what features should appear in the interface, and how to ronment to run the backend code. This allows the fron- best organize them for ease of use and an attractive de- tend to issue requests to the backend, and the developer sign. to step, using a debugger, directly from frontend code into The language used to write the user interface code is backend code, and to debug and test both the frontend most typically JavaScript [6]. -

Livejournal: Behind the Scenes Scaling Storytime
LiveJournal: Behind The Scenes Scaling Storytime April 2007 Brad Fitzpatrick [email protected] danga.com / livejournal.com / sixapart.com This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike License. To view a copy of this license, visit http://creativecommons.org/licenses/by-nc-sa/1.0/ or send a letter to Creative Commons, 559 Nathan Abbott Way, Stanford, California 94305, USA. http://danga.com/words/ 1 This Talk’s Gracious Sponsor Buy your servers from them Much love They didn’t even ask for me to put this slide in. :) http://danga.com/words/ 2 The plan... Refer to previous presentations for more details... http://danga.com/words/ Questions anytime! Yell. Interrupt. Part N: − show where talk will end up Part I: − What is LiveJournal? Quick history. − LJ’s scaling history Part II: − explain all our software, − explain all the moving parts http://danga.com/words/ 3 net. LiveJournal Backend: Today (Roughly.) BIG-IP perlbal (httpd/proxy) Global Database bigip1 mod_perl bigip2 proxy1 web1 master_a master_b proxy2 web2 proxy3 web3 Memcached slave1 slave2 ... slave5 djabberd proxy4 web4 mc1 djabberd proxy5 ... mc2 djabberd User DB Cluster 1 webN mc3 uc1a uc1b mc4 User DB Cluster 2 ... uc2a uc2b gearmand Mogile Storage Nodes gearmand1 mcN User DB Cluster 3 sto1 sto2 Mogile Trackers gearmandN uc3a uc3b ... sto8 tracker1 tracker3 User DB Cluster N ucNa ucNb MogileFS Database “workers” gearwrkN Job Queues (xN) mog_a mog_b theschwkN jqNa jqNb http:/slave1/danga.comslaveN/words/ 4 LiveJournal Overview college hobby project, Apr 1999 4-in-1: − blogging − forums − social-networking (“friends”) − aggregator: “friends page” + RSS/Atom 10M+ accounts Open Source! − server, − infrastructure, − original clients, − .. -

Data Management Organization Charter
Large Synoptic Survey Telescope (LSST) Database Design Jacek Becla, Daniel Wang, Serge Monkewitz, K-T Lim, Douglas Smith, Bill Chickering LDM-135 08/02/2013 LSST Database Design LDM-135 08/02/13 Change Record Version Date Description Revision Author 1.0 6/15/2009 Initial version Jacek Becla 2.0 7/12/2011 Most sections rewritten, added scalability test Jacek Becla section 2.1 8/12/2011 Refreshed future-plans and schedule of testing Jacek Becla, sections, added section about fault tolerance Daniel Wang 3.0 8/2/2013 Synchronized with latest changes to the Jacek Becla, requirements (LSE-163). Rewrote most of the Daniel Wang, “Implementation” chapter. Documented new Serge Monkewitz, tests, refreshed all other chapters. Kian-Tat Lim, Douglas Smith, Bill Chickering 2 LSST Database Design LDM-135 08/02/13 Table of Contents 1. Executive Summary.....................................................................................................................8 2. Introduction..................................................................................................................................9 3. Baseline Architecture.................................................................................................................10 3.1 Alert Production and Up-to-date Catalog..........................................................................10 3.2 Data Release Production....................................................................................................13 3.3 User Query Access.............................................................................................................13 -

Laith Shadeed [email protected] +31627249393 L3.Ai
Laith Shadeed [email protected] +31627249393 l3.ai EXPERIENCE Senior Full-Stack Software Engineer AIMMS, Haarlem 2017 - Current Decrease page load 50th percentile from 20s to below 4s (Javascript, Node.js). Reduce GitLab end-2-end test pipeline execution time from 46 min to 3 min (Docker, Bash). Maintaining back-end REST APIs & TCP proxy in Node.js Stack: AWS, Docker, GitLab, Javascript, Node.js, Webpack and jQuery. Lead Software Engineer SuperSaaS, Amsterdam 2016 - 2017 Add credit card payments. 60% of new subscriptions start using it in the 1st week (Ruby, Javascript). Add automated bare-metal server provisioning, monitoring, real-time logging and alerting (Bash, Perl). Stack: Passenger, Capistrano, Apache httpd, MySQL, Monit, Munin, Nagios and Ubuntu. Back-end Software Engineer Booking.com, Amsterdam 2014 - 2016 Launch Apple Map integration with Booking.com Hotels for the first time for Mac users (Perl). Improve response time of Maps XHR requests by 50% (Perl, Javascript). On the hiring team for final face-face interviews. Stack: uWSGI, Ngnix, MySQL, Puppet, Redis, Hadoop, Graphite and Debian. Senior Back-end Software Engineer One.com, Dubai 2012 - 2014 In-house Photo Processing, Video Transcoding, Job Queuing serving +200,000 web domains (PHP, Node.js). Lead the design of v2 & v3 of the photo application (PHP, Javascript). Stack: Node.js, PostgreSQL, Apache httpd, Varnish, Gearman, Redis, Puppet and Debian. Back-end Software Engineer Yahoo!, Amman & Bangalore 2009 - 2012 Launch Y! News Mobile for Middle East market serving 17 countries (PHP, Javascript). Part of Y! Mail team launching the product for +70 million Arabic users (PHP, Javascript). Stack: Apache httpd, MySQL, Memcache, Apache Traffic Server and Redhat. -

Alibaba Cloud Apsara Stack Enterprise
Alibaba Cloud Apsara Stack Enterprise Technical Whitepaper Version: 1807 Issue: 20180731 2 | Introduction | Apsara Stack Enterprise Apsara Stack Enterprise Technical Whitepaper / Legal disclaimer Legal disclaimer Alibaba Cloud reminds you to carefully read and fully understand the terms and conditions of this legal disclaimer before you read or use this document. If you have read or used this document, it shall be deemed as your total acceptance of this legal disclaimer. 1. You shall download and obtain this document from the Alibaba Cloud website or other Alibaba Cloud-authorized channels, and use this document for your own legal business activities only. The content of this document is considered confidential information of Alibaba Cloud. You shall strictly abide by the confidentiality obligations. No part of this document shall be disclosed or provided to any third party for use without the prior written consent of Alibaba Cloud. 2. No part of this document shall be excerpted, translated, reproduced, transmitted, or disseminat ed by any organization, company, or individual in any form or by any means without the prior written consent of Alibaba Cloud. 3. The content of this document may be changed due to product version upgrades, adjustment s, or other reasons. Alibaba Cloud reserves the right to modify the content of this document without notice and the updated versions of this document will be occasionally released through Alibaba Cloud-authorized channels. You shall pay attention to the version changes of this document as they occur and download and obtain the most up-to-date version of this document from Alibaba Cloud-authorized channels.