COAR Next Generation Repositories Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -

Scientometrics1
Scientometrics1 Loet Leydesdorff a and Staša Milojević b a Amsterdam School of Communication Research (ASCoR), University of Amsterdam, Kloveniersburgwal 48, 1012 CX Amsterdam, The Netherlands; [email protected] b School of Informatics and Computing, Indiana University, Bloomington 47405-1901, United States; [email protected]. Abstract The paper provides an overview of the field of scientometrics, that is: the study of science, technology, and innovation from a quantitative perspective. We cover major historical milestones in the development of this specialism from the 1960s to today and discuss its relationship with the sociology of scientific knowledge, the library and information sciences, and science policy issues such as indicator development. The disciplinary organization of scientometrics is analyzed both conceptually and empirically. A state-of-the-art review of five major research threads is provided. Keywords: scientometrics, bibliometrics, citation, indicator, impact, library, science policy, research management, sociology of science, science studies, mapping, visualization Cross References: Communication: Electronic Networks and Publications; History of Science; Libraries; Networks, Social; Merton, Robert K.; Peer Review and Quality Control; Science and Technology, Social Study of: Computers and Information Technology; Science and Technology Studies: Experts and Expertise; Social network algorithms and software; Statistical Models for Social Networks, Overview; 1 Forthcoming in: Micheal Lynch (Editor), International -

Making Institutional Repositories Work “Making Institutional Repositories Work Sums It up Very Well
Making Institutional Repositories Work “Making Institutional Repositories Work sums it up very well. This book, the first of its kind, explains how IRs work and how to get the greatest re- sults from them. As many of us know, numerous IRs launched with high hopes have in fact languished with lackluster results. Faculty have little in- terest, and administrators see little promise. But the many chapter authors of this very well edited book have made their IRs successful, and here they share their techniques and successes. This is a necessary book for anyone contemplating starting an IR or looking to resurrect a moribund one.” — Richard W. Clement Dean, College of University Libraries & Learning Sciences University of New Mexico “This volume presents an interesting cross-section of approaches to in- stitutional repositories in the United States. Just about every view and its opposite makes an appearance. Readers will be able to draw their own con- clusions, depending on what they see as the primary purpose of IRs.” — Stevan Harnad Professor, University of Québec at Montréal & University of Southampton “Approaching this volume as one of ‘those of us who have been furiously working to cultivate thriving repositories,’ I am very excited about what this text represents. It is a broad compilation featuring the best and brightest writing on all the topics I’ve struggled to understand around re- positories, and it also marks a point when repository management and de- velopment is looking more and more like a core piece of research library work. Callicott, Scherer, and Wesolek have pulled together all the things I wished I’d been able to read in my first year as a scholarly communication librarian. -

Will Sci-Hub Kill the Open Access Citation Advantage and (At Least for Now) Save Toll Access Journals?
Will Sci-Hub Kill the Open Access Citation Advantage and (at least for now) Save Toll Access Journals? David W. Lewis October 2016 © 2016 David W. Lewis. This work is licensed under a Creative Commons Attribution 4.0 International license. Introduction It is a generally accepted fact that open access journal articles enjoy a citation advantage.1 This citation advantage results from the fact that open access journal articles are available to everyone in the word with an Internet collection. Thus, anyone with an interest in the work can find it and use it easily with no out-of-pocket cost. This use leads to citations. Articles in toll access journals on the other hand, are locked behind paywalls and are only available to those associated with institutions who can afford the subscription costs, or who are willing and able to purchase individual articles for $30 or more. There has always been some slippage in the toll access journal system because of informal sharing of articles. Authors will usually send copies of their work to those who ask and sometime post them on their websites even when this is not allowable under publisher’s agreements. Stevan Harnad and his colleagues proposed making this type of author sharing a standard semi-automated feature for closed articles in institutional repositories.2 The hashtag #ICanHazPDF can be used to broadcast a request for an article that an individual does not have access to.3 Increasingly, toll access articles are required by funder mandates to be made publically available, though usually after an embargo period. -

Mapping Scientometrics (1981-2001)
Mapping Scientometrics (1981 -2001) Chaomei Chen College of Information Science and Technology, Drexel University, Philadelphia, PA 19104, USA. Email: [email protected] Katherine McCain College of Information Science and Technology, Drexel University, Philadelphia, PA 19104, USA. Email: kate .mccai n@cis .drexel . ed u Howard White College of Information Science and Technology, Drexel University, Philadelphia, PA 19104, USA. Email: [email protected] Xia Lin College of Information Science and Technology, Drexel University, Philadelphia, PA 19104, USA. Email: xia .I in@cis . d rexel. edu We investigate an integrated approach to co-citation analysis could lead to a clearer picture of the scientometric studies with emphasis to the use of cognitive content of publications (Braam, Moed, & Raan, information visualization and animation 1991a, 1991b). techniques. This study draws upon citation and In Little Science, Big Science, Derek de Solla Price co-citation patterns derived from articles (1963) raised some of the most fundamental questions that published in the journal Scientornetrics (1981- have led to the scientometric study today: Why should we 2001). The modeling and visualization takes an not turn the tools of science on science itself? Why not evolutionary and historical perspective. The measure and generalize, make hypotheses, and derive design of the visualization model adapts a virtual conclusions? He used the metaphor of studying the landscape metaphor with document cocitation behavior of gas in thermodynamics as an analogue of the networks as the base map and annual citation science of science. Thermodynamics studies the behavior of rates as the thematic overlay. The growth of gas under various conditions of temperature and pressure, citation rates is presented through an animation but the focus is not on the trajectory of a specific molecule. -

Technical Design of Open Social Web for Crowdsourced Democracy
Project no. 610349 D-CENT Decentralised Citizens ENgagement Technologies Specific Targeted Research Project Collective Awareness Platforms D4.3 Technical Design of Open Social Web for Crowdsourced Democracy Version Number: 1 Lead beneficiary: OKF Due Date: 31 October 2014 Author(s): Pablo Aragón, Francesca Bria, Primavera de Filippi, Harry Halpin, Jaakko Korhonen, David Laniado, Smári McCarthy, Javier Toret Medina, Sander van der Waal Editors and reviewers: Robert Bjarnason, Joonas Pekkanen, Denis Roio, Guido Vilariño Dissemination level: PU Public X PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium (including the Commission Services) Approved by: Francesca Bria Date: 31 October 2014 This report is currently awaiting approval from the EC and cannot be not considered to be a final version. FP7 – CAPS - 2013 D-CENT D4.3 Technical Design of Open Social Web for Crowdsourced Democracy Contents 1 Executive Summary ........................................................................................................................................................ 6 Description of the D-CENT Open Democracy pilots ............................................................................................. 8 Description of the lean development process .......................................................................................................... 10 Hypotheses statements -

The W3C Social Web Activity
Standardizing the Social Web: The W3C Social Web Activity Harry Halpin World Wide Web Consortium/MIT, 32 Vassar Street Cambridge, MA 02139 USA [email protected] Abstract. The focus of the Social Activity is on making “social” a first-class citizen of the Open Web Platform by enabling standardized protocols, APIs, and an architecture for standardized communication among Social Web applications. These technologies are crucial for both federated social networking and the success of social business between and within the enterprise. Keywords: decentralization, social web, RDF 1Introduction The focus of the W3C Social Activity is on making “social” a first-class citizen of the Open Web Platform by enabling standardized protocols, APIs,andan architecture for standardized communication among Social Web applications. These technologies are crucial for both federated social networking and social business between and within the enterprise and can be built on top of Linked Data. This work will knit together via interoperable standards a number of industry platforms, including IBM Connections, SAP Jam, Jive, SugarCRM, and grassroots efforts such as IndieWeb.1 The mission of the Social Web Working Group,2 part of the Social Activ- ity,3 is to define the technical protocols, Semantic Web vocabularies, andAPIs to facilitate access to social functionality as part of the Open Web Platform. These technologies should allow communication between independent systems, federation (also called “decentralization”) being part of the design. The Working Group is chaired by Tantek Celik (Mozilla), Evan Prodromou (E14N), and Ar- naud Le Hors (IBM). Also part of the Social Activity is the Social Interest Group 4 focuses on messaging and co-ordination in the larger space. -

Notes from the Interoperability Front: a Progress Report on the Open Archives Initiative
Notes from the Interoperability Front: A Progress Report on the Open Archives Initiative Herbert Van de Sompel1, Carl Lagoze2 1Research Library, Los Alamos National Laboratory, Los Alamos, NM mailto:[email protected] 2Computing and Information Science, Cornell University Ithaca, NY USA 14850 [email protected] Abstract. The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) was first released in January 2001. Since that time, the protocol has been adopted by a broad community and become the focus of a number of research and implementation projects. We describe the various activities building on the OAI-PMH since its first release. We then describe the activities and decisions leading up to the release of a stable Version 2 of the OAI-PMH. Finally, we describe the key features of OAI-PMH Version 2. 1 Introduction Over a year has passed since the first release of the Open Archives Initiative Protocol for Metadata harvesting (OAI-PMH) in January 2001. During that period, the OAI- PMH has emerged as a practical foundation for digital library interoperability. The OAI-PMH supports interoperability via a relatively simple two-party model. At one end, data providers employ the OAI-PMH to expose structured data, metadata, in various forms. At the other end, service providers use the OAI-PMH to harvest the metadata from data providers and then subsequently automatically process it and add value in the form of services. While resource discovery is often mentioned as the exemplar service, other service possibilities include longevity and risk management [19], personalization [16], and current awareness. The general acceptance of the OAI-PMH is based on a number of factors. -

1 Citation Classes1: a Novel Indicator Base To
CITATION CLASSES1: A NOVEL INDICATOR BASE TO CLASSIFY SCIENTIFIC OUTPUT Wolfgang Glänzel*, Koenraad Debackere**, Bart Thijs**** * Wolfgang.Glä[email protected] Centre for R&D Monitoring (ECOOM) and Dept. MSI, KU Leuven, Leuven (Belgium) Department of Science Policy & Scientometrics, Library of the Hungarian Academy of Sciences, Budapest (Hungary) ** [email protected] Centre for R&D Monitoring (ECOOM) and Dept. MSI, KU Leuven, Leuven (Belgium) *** [email protected] Centre for R&D Monitoring (ECOOM) and Dept. MSI, KU Leuven, Leuven (Belgium) Abstract In the present paper we present use cases and scenarios for a new assessment tool based on bibliometric data and indicators. The method, the application of which is illustrated at different levels of aggregation (national, institutional and individual researchers), aims at building on traditional indicators while stepping away from the linear ranking model and thus at providing enough space for a more differentiated analysis of published research results. The method proved statistically robust and insensitive to the influence of the otherwise commonly encountered database-related, communication- and subject-specific factors. This finding is a clear step forward in the use of bibliometric data for assessment and evaluation purposes, as often is a need of science policy. 1. Introduction: The need for multi-level profiling of excellence The conceptual background One of the objectives of previous studies (Glänzel, 2013a,b) was to analyse to what extent the high-end of citation impact as reflected by the tail of scientometric distributions is in line with the “standard” citation impact attracted by the majority of scientific papers and to what extent ‘outliers’ might be responsible for possible deviations and distortions of citation indicators. -
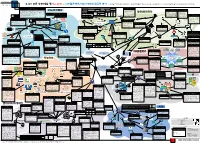
K-ICT · Ver.2017 –
http://www.tta.or.kr K-ICT Ver.2017 – /SW/ SW· - ( / , / , ), SW( , SW ), SW· ( / , ) TTA - 16142 - SD Service offering ( | ) ~'19, JTC1 SC34, IDPF, W3C ( | ) ~'19, JTC1 SC29 WG11 AR/VR App. AV App. ( ) KS X 6070-1~5 (EPUB) 3.0 , (EPUB) 3.0, (EPUB) 3.0, e-Learning App. (TTA) TTA.KO-10.0611 - Digital Signage App. Web App. , 2016-118 ( | ) ~'18, JTC1 SC29 WG11, SC24 ( | ) ~'18, JTC1 SC29 WG11 (EPUB) 3.0, (EPUB) 3.0 / SNS App. (HMD) (TTA) TTAK.OT-10.0337 - EPUB 2 , .0338 - EPUB 3.0, .0339 - EPUB , 2016-119 PC (TTA) TTAK.KO-10.0874 – (TTA) TTAK.KO-10.0317- 3.0, .0340 - EPUB 3 , .0341 - EPUB 3.0, .0342 - EPUB A/V/Data Terminal Control, (HMD) / 3.0, .0727 - EPUB , KR04-1 - EPUB3 EDUPUB , -2 - EPUB Service Info. Management (JTC1) Exploration Part # 12(Free-viewpoint TV) 1.0, -3 - EPUB 1.0, -4 - EPUB 1.0 DRM Service (JTC1) ISO/IEC 23000-13 Information technology - Call for Evidence on Free-Viewpoint Television: (JTC1) ISO/IEC 14496-10:2012 , NTP/ (ODPF) KR03-1 - EPUB 3.0.1 , -2 - EPUB 3.0.1, -3 - EPUB 3.0.1, -4 - EPUB Discovery ID Network DHCP DNS IGMP - Multimedia application format (MPEG-A) -- Part Super-Multiview and Free Navigation – update, Information technology -- Coding of 3.0.1, -5 - EPUB 3.0.1, -6 - EPUB 3.0.1 ( | ) ~'19, Web3D, JTC1 SC24 WG6/WG9, JTC1 SC29, JTC1 SC35, JTC1 SC36 MPEG / H.264, 265 audio-visual objects -- Part 10: Advanced agent Provisioning SNTP 13: Augmented reality application format, ISO/IEC Exploration Part # 12(Free-viewpoint TV) - FTV HDR (ISO TC171 SC2) ISO 32000-1 - PDF(portable document format) 23005-5 Information -

Open Knowledge Foundation Joins Europeana Space
This page was exported from - Digital meets Culture Export date: Fri Sep 24 11:54:13 2021 / +0000 GMT Open Knowledge Foundation joins Europeana Space by Lieke Ploeger and Marieke Guy, Open Knowledge Foundation Open Knowledge is a nonprofit organisation that promotes open knowledge, including open content and open data. Open Knowledge hosts over 20 working groups: domain-specific groups that focus on discussion and activity around a given area of open knowledge. OpenGLAM is an initiative run by Open Knowledge since 2012 for the promotion of open cultural content. The OpenGLAM working group is a global network of people who work to open up cultural data and content held by GLAM institutions. The OpenGLAM community provides documentation for cultural institutions wanting to open up their data and content and regularly organises events and workshops bringing together groups that are committed to building an open cultural commons. With such great OpenGLAM credentials it seemed natural for Open Knowledge to participate in the Europeana Space project to cooperate on WP3 ? The Content Space. Open Knowledge will be providing a ?Knowledge Base' on ?Open Content Exchange' known as the ?OpenContent Exchange Platform' for the Content Space. This platform will comprise of collated public domain and open content materials related to the value of digital public domain and best practices around open licensing. One particular area of focus will be the monetising of Europeana open content by creative industries and the challenges this poses related to IPR. The OpenContent Exchange Platform will help answer, in an accessible, user-friendly way, the question "What would those working in creative industries want to know or to happen to enable them to reuse Europeana content??. -

Open Access Self-Archiving: an Author Study
Open access self-archiving: An author study May 2005 Alma Swan and Sheridan Brown Key Perspectives Limited 48 Old Coach Road, Playing Place, TRURO, Cornwall, TR3 6ET, UK (Registered Office) Tel. +44 (0)1392 879702 www.keyperspectives.co.uk www.keyperspectives.com CONTENTS Executive summary 1. Introduction 1 2. The respondents 7 3. Open access journals 10 4. The use of research information 13 4.1 Ease of access to work-related information 13 4.2 Age of articles most commonly used 13 4.3 Respondents’ publishing activities 17 4.3.1 Number of articles published 17 4.3.2 Respondents’ citation records 20 4.3.3 Publishing objectives 23 4.4 Searching for information 23 4.4.1 Research articles in closed archives 24 4.4.2 Research articles in open archives 24 5. Self-archiving 26 5.1 Self-archiving experience 26 5.1.1 The level of self-archiving activity 26 5.1.2 Length of experience of self-archiving 38 5.2 Awareness of self-archiving as a means to providing open access 43 5.3 Motivation issues 49 5.4 The mechanics of self-archiving 51 5.4.1 Who has actually done the depositing? 51 5.4.2 How difficult is it to self-archive? 51 5.4.3 How long does it take to self-archive? 53 5.4.4 Preservation of archived articles 55 5.4.5 Copyright 56 5.4.6 Digital objects being deposited in open archives 57 5.4.7 Mandating self-archiving? 62 6. Discussion 69 References 74 Appendices: Appendix 1: Reasons for publishing in open access journals, by subject area (table) 77 Appendix 2: Reasons for publishing in open access journals, by subject area (verbatim responses) 79 Appendix 3: Reasons for not publishing in open access journals, by subject area (table) 83 Appendix 4: Reasons for not publishing in open access journals, by subject area (verbatim responses) 86 Appendix 5: Ease of access to research articles needed for work, by subject area 93 Appendix 6: Reasons for publishing research results (verbatim responses) 94 Appendix 7: Use of closed archives: results broken down by subject area 97 Tables 1.