Advanced Compiling Techniques to Reduce RAM Usage of Static Operating Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

R:BASE Plugin Power Pack X.5 Help
R:BASE Plugin Power Pack X.5 Help Manual R:BASE Plugin Power Pack X.5 Manual by R:BASE Technologies, Inc. Welcome to the R:BASE Plugin Power Pack X.5! The R:BASE Plugin Power Pack is a collection of exclusive and enhanced R:BASE Plugins to increase the functionality of your R:BASE applications. An R:BASE Plugin is a file containing data used to alter, enhance, or extend the operation of R:BASE. Contents 3 Table of Contents Part I Introduction 5 1 Introdu.c.i.n..g.. .R...:.B..A..S..E.. .P...l.u..g..i.n.. .P..o..w...e..r. .P..a..c..k.. .X....5.. ......................................................................... 6 2 Copyrig..h..t.s. ............................................................................................................................. 6 3 License.. ................................................................................................................................. 7 4 Compl.i.m...e..n..t.a..r..y. .T..e..c..h..n..i.c..a..l. .S..u..p..p..o..r.t. ...................................................................................... 11 Part II Installation 12 1 System... .R..e..q..u..i.r.e..m...e..n..t.s.. ......................................................................................................... 13 2 Things.. .Y..o..u.. .W...i.l.l. .N..e..e..d.. .......................................................................................................... 13 3 Softwa..r.e.. .I.n..s..t.a..l.l.a..t.i.o..n.. .......................................................................................................... -

Vbcc Compiler System
vbcc compiler system Volker Barthelmann i Table of Contents 1 General :::::::::::::::::::::::::::::::::::::::::: 1 1.1 Introduction ::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Legal :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.3 Installation :::::::::::::::::::::::::::::::::::::::::::::::::::: 2 1.3.1 Installing for Unix::::::::::::::::::::::::::::::::::::::::: 3 1.3.2 Installing for DOS/Windows::::::::::::::::::::::::::::::: 3 1.3.3 Installing for AmigaOS :::::::::::::::::::::::::::::::::::: 3 1.4 Tutorial :::::::::::::::::::::::::::::::::::::::::::::::::::::::: 5 2 The Frontend ::::::::::::::::::::::::::::::::::: 7 2.1 Usage :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Configuration :::::::::::::::::::::::::::::::::::::::::::::::::: 8 3 The Compiler :::::::::::::::::::::::::::::::::: 11 3.1 General Compiler Options::::::::::::::::::::::::::::::::::::: 11 3.2 Errors and Warnings :::::::::::::::::::::::::::::::::::::::::: 15 3.3 Data Types ::::::::::::::::::::::::::::::::::::::::::::::::::: 15 3.4 Optimizations::::::::::::::::::::::::::::::::::::::::::::::::: 16 3.4.1 Register Allocation ::::::::::::::::::::::::::::::::::::::: 18 3.4.2 Flow Optimizations :::::::::::::::::::::::::::::::::::::: 18 3.4.3 Common Subexpression Elimination :::::::::::::::::::::: 19 3.4.4 Copy Propagation :::::::::::::::::::::::::::::::::::::::: 20 3.4.5 Constant Propagation :::::::::::::::::::::::::::::::::::: 20 3.4.6 Dead Code Elimination::::::::::::::::::::::::::::::::::: 21 3.4.7 Loop-Invariant Code Motion -

Amigaone-XE G4 We Preview the Fastest Powerpc Motherboard in Eyetech’S Range
Issue 16, Autumn 2003 £4.00 8.00Euro Find out all about this feature-packed Zorro card inside. AmigaOne-XE G4 We preview the fastest PowerPC motherboard in Eyetech’s range. Improve your digital photos and scans with our image enhancement tutorial. Contents News PageStream Issue 16 EditorialChandler’s Amiga OS 4 Update for Amiga OS 4 Autumn 2003 elcome to another on page 10. This time he Grasshopper LLC has display. Hopefully this feature Wbumper 52-page edition reports some interesting announced that they will may be added to the new of Total Amiga! As I write this developments relating to support AmigaOS 4 with a new Amiga version too. The Contents the production of this issue has developing programs for OS 4 version of their professional standard retail price of the full gone very smoothly and it and some changes in priority DTP package, PageStream 4. version of PageStream has looks like it will be out on time. that should mean the As regular readers will know, been reduced to just $99 News This has largely been made AmigaOne version is available Editorial ..............................2 PageStream is a powerful (approximately £65) making it possible by all the people who earlier than would otherwise finding software currently in program and, I think most much more affordable. There is News Items ........................3 contributed to this issue, as have been possible. This development so we thought it people will agree, one of best also a new professional edition Amiga OS 4 Update........ 10 you will see there are several should please Mick and would be worth reviewing. -

Vasm Assembler System
vasm assembler system Volker Barthelmann, Frank Wille June 2021 i Table of Contents 1 General :::::::::::::::::::::::::::::::::::::::::: 1 1.1 Introduction ::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Legal :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.3 Installation :::::::::::::::::::::::::::::::::::::::::::::::::::: 1 2 The Assembler :::::::::::::::::::::::::::::::::: 3 2.1 General Assembler Options ::::::::::::::::::::::::::::::::::::: 3 2.2 Expressions :::::::::::::::::::::::::::::::::::::::::::::::::::: 5 2.3 Symbols ::::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.4 Predefined Symbols :::::::::::::::::::::::::::::::::::::::::::: 7 2.5 Include Files ::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.6 Macros::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.7 Structures:::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.8 Conditional Assembly :::::::::::::::::::::::::::::::::::::::::: 8 2.9 Known Problems ::::::::::::::::::::::::::::::::::::::::::::::: 9 2.10 Credits ::::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 2.11 Error Messages :::::::::::::::::::::::::::::::::::::::::::::: 10 3 Standard Syntax Module ::::::::::::::::::::: 13 3.1 Legal ::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 13 3.2 Additional options for this module :::::::::::::::::::::::::::: 13 3.3 General Syntax ::::::::::::::::::::::::::::::::::::::::::::::: 13 3.4 Directives ::::::::::::::::::::::::::::::::::::::::::::::::::::: 14 3.5 Known Problems:::::::::::::::::::::::::::::::::::::::::::::: -

Hollywood 7.1 the Cross-Platform Multimedia Application Layer
Hollywood 7.1 The Cross-Platform Multimedia Application Layer Andreas Falkenhahn i Table of Contents 1 General information::::::::::::::::::::::::::::: 1 1.1 Introduction :::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Philosophy ::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 1.3 Terms and conditions ::::::::::::::::::::::::::::::::::::::::::: 4 1.4 Requirements::::::::::::::::::::::::::::::::::::::::::::::::::: 6 1.5 Credits ::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 1.6 Forum and mailing list:::::::::::::::::::::::::::::::::::::::::: 8 1.7 Contact :::::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2 Getting started :::::::::::::::::::::::::::::::::: 9 2.1 Overview ::::::::::::::::::::::::::::::::::::::::::::::::::::::: 9 2.2 The GUI :::::::::::::::::::::::::::::::::::::::::::::::::::::: 10 2.3 Windows IDE ::::::::::::::::::::::::::::::::::::::::::::::::: 15 2.4 Mobile platforms :::::::::::::::::::::::::::::::::::::::::::::: 22 3 Console usage :::::::::::::::::::::::::::::::::: 29 3.1 Console mode ::::::::::::::::::::::::::::::::::::::::::::::::: 29 3.2 Console arguments :::::::::::::::::::::::::::::::::::::::::::: 29 3.3 Console emulation ::::::::::::::::::::::::::::::::::::::::::::: 46 4 Compiler and linker:::::::::::::::::::::::::::: 49 4.1 Compiling executables ::::::::::::::::::::::::::::::::::::::::: 49 4.2 Compiling applets ::::::::::::::::::::::::::::::::::::::::::::: 50 4.3 Linking data files :::::::::::::::::::::::::::::::::::::::::::::: 50 4.4 Linking fonts :::::::::::::::::::::::::::::::::::::::::::::::::: -
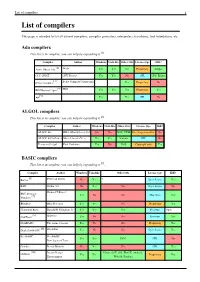
List of Compilers 1 List of Compilers
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -
Morphos Full Features List
MorphOS Full Features List v1.2 12/12/02 by the MorphOS team. • MorphOS Features at a glance • Core OS • OS Components • 3D Graphics Support • Applications / Utilities • Miscellaneous • Pegasos specific software • Appendix • Contact and Additional Information MorphOS Features at a glance: • Native PowerPC Operating System • Supports Pegasos and Amigas fitted with PowerUP cards • Runs Native PPC and Amiga OS RTG Applications • 68K JIT compiler runs applications at up to 75% of native PPC speed • Hardware 3D support (3dfx, 3DLabs, SiS + more to come) • New Ambient Desktop with 32 bit colour support • Fully Skinnable user interface • MUI Object Orientated GUI Toolkit • Media Player (Frogger) • Multi-threaded Image viewer (MysticView) • Web browser (Voyager) • PDF viewer (APDF) • Supports an extensive range of Printers (TurboPrint v7) • TCP/IP Stack for networking. • Built in Software Development Kit • AHI Audio • USB Support • Multiple 64 bit File systems supported including FFS2 & SFS Core OS Quark - State of the Art micro-kernel designed for: High Super/Usermode switch speed Low interrupt latency IntThread and Int PCode abstraction Memory protection Symmetrical multi processing (SMP) Task/Thread and Clan/Chief model Resource tracking Asynchronous message system Virtual memory (optional) Recursive Memory Management Distributed computing No access to Kernel structures Clean design with an elegant API HAL - The Hardware Abstraction Layer Makes MorphOS hardware independent, through the following points: Determines the CPU types, the number of CPUs and clock speed. Scans the ABox Zorro I/O ports for Zorro-II and Zorro-III cards and configures them. Finds local hardware (CVisionPPC, SymbiosPPC, PCI bus) Creates a resource map for the Quark microkernel. -

Hollywood SDK 9.0 the Cross-Platform Multimedia Application Layer
Hollywood SDK 9.0 The Cross-Platform Multimedia Application Layer Andreas Falkenhahn i Table of Contents 1 General information::::::::::::::::::::::::::::: 1 1.1 Introduction :::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Terms and conditions ::::::::::::::::::::::::::::::::::::::::::: 1 1.3 Requirements::::::::::::::::::::::::::::::::::::::::::::::::::: 3 1.4 Examples::::::::::::::::::::::::::::::::::::::::::::::::::::::: 3 1.5 History ::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 1.6 Contact :::::::::::::::::::::::::::::::::::::::::::::::::::::::: 5 2 Conceptual overview :::::::::::::::::::::::::::: 7 2.1 Getting started ::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Plugin types and Hollywood APIs :::::::::::::::::::::::::::::: 7 2.3 What is a Hollywood plugin? ::::::::::::::::::::::::::::::::::: 9 2.4 Basic plugin design :::::::::::::::::::::::::::::::::::::::::::: 10 2.5 Auto and manual init plugins :::::::::::::::::::::::::::::::::: 10 2.6 Compiling plugins ::::::::::::::::::::::::::::::::::::::::::::: 13 2.7 Error codes:::::::::::::::::::::::::::::::::::::::::::::::::::: 14 2.8 Data types :::::::::::::::::::::::::::::::::::::::::::::::::::: 14 2.9 Version compatibility :::::::::::::::::::::::::::::::::::::::::: 14 2.10 Tag lists ::::::::::::::::::::::::::::::::::::::::::::::::::::: 16 2.11 Unicode support ::::::::::::::::::::::::::::::::::::::::::::: 16 2.12 File IO information::::::::::::::::::::::::::::::::::::::::::: 18 2.13 File attributes :::::::::::::::::::::::::::::::::::::::::::::::: 18 -

Exhibit 4, Page 69 "Classic Amiga OS" Means the Operating System Owned and Developed by Amiga Inc
AGREEMENT FOR THE PROVISION OF SERVICES This agreement (this"Agreement") is made and entered into as of this 10 day of October 2001, by and between Olaf Barthel (hereafter: "Developer"), Gneisenaustrasse 43, D-31275 Lehrte, Germany and HYPERION ENTERTA!NMENT VOF (hereafter: "Hyperion"), a Belglan corporation with its administrative seat at Brouwersstr. IB, B-3000 Leuven, Belgium. RECITALS WHEREAS Amiga Inc. has contracted with Hyperion to develop the next release of its Classic Amiga operating system for PPC systems; WHEREAS Developer has (in his capacity as a contractor for Amiga Technologies GmbH) over a period of 3 years reworked/cleaned up the source-code of Amiga OS 3.1 (including to but not limited to cutting down the number of compilers and assemblers required to produce a complete build, rewriting sections of assembly code into C and integrating the end-result into a CYS); WHEREAS this effort took approximately 750 hours of work; WHEREAS Developer was promised compensation for this work by the previous and current Amiga Inc. management which has until now not materialized; WHEREAS Hyperion's ability to successfully carry out the OS 4 project hinges in part on the availability of the Amiga OS 3.1 source-code in a useable form; WHEREAS Developer and Hyperion have therefore decided that Hyperion shall over time compensate Developer for the aforementioned work; NOW, THEREFORE, for good and valuable consideration, receipt and sufficiency of which is hereby acknowledged, and intending to be legally bound, the parties hereto agree as follows: ARTICLE 1. DEFINITIONS 1.01 Definitions. For purposes of this Agreement, in addition to capitalized terms defined elsewhere in this agreement, the following defined terms shall have the meanings set forth below: 1 Exhibit 4, Page 69 "Classic Amiga OS" means the operating system owned and developed by Amiga Inc. -

Vbcc Compiler System
vbcc compiler system Volker Barthelmann i Table of Contents 1 General::::::::::::::::::::::::::::::::::::::::::: 1 1.1 Introduction :::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Legal ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.3 Installation ::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 1.3.1 Installing for Unix ::::::::::::::::::::::::::::::::::::::::: 3 1.3.2 Installing for DOS/Windows ::::::::::::::::::::::::::::::: 3 1.3.3 Installing for AmigaOS :::::::::::::::::::::::::::::::::::: 3 1.4 Tutorial :::::::::::::::::::::::::::::::::::::::::::::::::::::::: 6 2 The Frontend :::::::::::::::::::::::::::::::::::: 7 2.1 Usage :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Configuration::::::::::::::::::::::::::::::::::::::::::::::::::: 8 3 The Compiler::::::::::::::::::::::::::::::::::: 11 3.1 General Compiler Options ::::::::::::::::::::::::::::::::::::: 11 3.2 Errors and Warnings :::::::::::::::::::::::::::::::::::::::::: 15 3.3 Data Types ::::::::::::::::::::::::::::::::::::::::::::::::::: 16 3.4 Optimizations ::::::::::::::::::::::::::::::::::::::::::::::::: 17 3.4.1 Register Allocation ::::::::::::::::::::::::::::::::::::::: 19 3.4.2 Flow Optimizations::::::::::::::::::::::::::::::::::::::: 19 3.4.3 Common Subexpression Elimination :::::::::::::::::::::: 20 3.4.4 Copy Propagation :::::::::::::::::::::::::::::::::::::::: 20 3.4.5 Constant Propagation :::::::::::::::::::::::::::::::::::: 21 3.4.6 Dead Code Elimination ::::::::::::::::::::::::::::::::::: 22 3.4.7 Loop-Invariant -

Subject: Tiny68k, 68000 SBC with 16 Meg Memory for CP/M-68K Posted
Subject: Tiny68K, 68000 SBC with 16 Meg memory for CP/M-68K Posted by plasmo on Wed, 01 Nov 2017 04:02:56 GMT View Forum Message <> Reply to Message This is a branch off "Plasmo's 68k pathfinder projects" https://www.retrobrewcomputers.org/forum/index.php?t=msg& ;th=152&start=0& Since the rev 1 of Tiny68K is reasonably matured, I like to start a new topic dedicated to this design and its derivatives. There is a wiki page for Tiny68K: https://www.retrobrewcomputers.org/doku.php?id=boards:sbc:ti ny68k A brief highlight of features: * 68000 CPU with a nominal clock of 8MHz * Entire 68000 address space is filled with a 16-meg SIMM72 DRAM except for I/O devices located at the top 32K bytes. * 68681 dual UART. Port A is dedicate to console at 38400, N81, CTS/RTS handshake. Port B is available for other uses. * IDE44 interface to CompactFlash * Two serial EEPROM, 24C256. Software may boot from either serial EEPROM depending on one jumper select. The second EEPROM is writable in-situ. * A 7-segment display for status indication. plasmo wrote on Fri, 27 October 2017 23:09 * I encountered a curious bug on "pip" command: when I tried to concatenate multiple files using the command format: pip file1.txt=file2.txt,file3.txt I get the error message: Exception $03 at user address $0001B1BA. Aborted. pip works fine otherwise. This error occurs in simulation as well, so it may be a bug in pip command or corrupted distribution disk. * Beside the strange bug in "pip", most software work fine except gkermit.