A Comparison of Fractal Trees to Log-Structured Merge (LSM) Trees
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tree-Combined Trie: a Compressed Data Structure for Fast IP Address Lookup
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 6, No. 12, 2015 Tree-Combined Trie: A Compressed Data Structure for Fast IP Address Lookup Muhammad Tahir Shakil Ahmed Department of Computer Engineering, Department of Computer Engineering, Sir Syed University of Engineering and Technology, Sir Syed University of Engineering and Technology, Karachi Karachi Abstract—For meeting the requirements of the high-speed impact their forwarding capacity. In order to resolve two main Internet and satisfying the Internet users, building fast routers issues there are two possible solutions one is IPv6 IP with high-speed IP address lookup engine is inevitable. addressing scheme and second is Classless Inter-domain Regarding the unpredictable variations occurred in the Routing or CIDR. forwarding information during the time and space, the IP lookup algorithm should be able to customize itself with temporal and Finding a high-speed, memory-efficient and scalable IP spatial conditions. This paper proposes a new dynamic data address lookup method has been a great challenge especially structure for fast IP address lookup. This novel data structure is in the last decade (i.e. after introducing Classless Inter- a dynamic mixture of trees and tries which is called Tree- Domain Routing, CIDR, in 1994). In this paper, we will Combined Trie or simply TC-Trie. Binary sorted trees are more discuss only CIDR. In addition to these desirable features, advantageous than tries for representing a sparse population reconfigurability is also of great importance; true because while multibit tries have better performance than trees when a different points of this huge heterogeneous structure of population is dense. -

Heaps a Heap Is a Complete Binary Tree. a Max-Heap Is A
Heaps Heaps 1 A heap is a complete binary tree. A max-heap is a complete binary tree in which the value in each internal node is greater than or equal to the values in the children of that node. A min-heap is defined similarly. 97 Mapping the elements of 93 84 a heap into an array is trivial: if a node is stored at 90 79 83 81 index k, then its left child is stored at index 42 55 73 21 83 2k+1 and its right child at index 2k+2 01234567891011 97 93 84 90 79 83 81 42 55 73 21 83 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Building a Heap Heaps 2 The fact that a heap is a complete binary tree allows it to be efficiently represented using a simple array. Given an array of N values, a heap containing those values can be built, in situ, by simply “sifting” each internal node down to its proper location: - start with the last 73 73 internal node * - swap the current 74 81 74 * 93 internal node with its larger child, if 79 90 93 79 90 81 necessary - then follow the swapped node down 73 * 93 - continue until all * internal nodes are 90 93 90 73 done 79 74 81 79 74 81 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Heap Class Interface Heaps 3 We will consider a somewhat minimal maxheap class: public class BinaryHeap<T extends Comparable<? super T>> { private static final int DEFCAP = 10; // default array size private int size; // # elems in array private T [] elems; // array of elems public BinaryHeap() { . -

Betrfs: a Right-Optimized Write-Optimized File System
BetrFS: A Right-Optimized Write-Optimized File System William Jannen, Jun Yuan, Yang Zhan, Amogh Akshintala, Stony Brook University; John Esmet, Tokutek Inc.; Yizheng Jiao, Ankur Mittal, Prashant Pandey, and Phaneendra Reddy, Stony Brook University; Leif Walsh, Tokutek Inc.; Michael Bender, Stony Brook University; Martin Farach-Colton, Rutgers University; Rob Johnson, Stony Brook University; Bradley C. Kuszmaul, Massachusetts Institute of Technology; Donald E. Porter, Stony Brook University https://www.usenix.org/conference/fast15/technical-sessions/presentation/jannen This paper is included in the Proceedings of the 13th USENIX Conference on File and Storage Technologies (FAST ’15). February 16–19, 2015 • Santa Clara, CA, USA ISBN 978-1-931971-201 Open access to the Proceedings of the 13th USENIX Conference on File and Storage Technologies is sponsored by USENIX BetrFS: A Right-Optimized Write-Optimized File System William Jannen, Jun Yuan, Yang Zhan, Amogh Akshintala, John Esmet∗, Yizheng Jiao, Ankur Mittal, Prashant Pandey, Phaneendra Reddy, Leif Walsh∗, Michael Bender, Martin Farach-Colton†, Rob Johnson, Bradley C. Kuszmaul‡, and Donald E. Porter Stony Brook University, ∗Tokutek Inc., †Rutgers University, and ‡Massachusetts Institute of Technology Abstract (microwrites). Examples include email delivery, creat- The Bε -tree File System, or BetrFS, (pronounced ing lock files for an editing application, making small “better eff ess”) is the first in-kernel file system to use a updates to a large file, or updating a file’s atime. The un- write-optimized index. Write optimized indexes (WOIs) derlying problem is that many standard data structures in are promising building blocks for storage systems be- the file-system designer’s toolbox optimize for one case cause of their potential to implement both microwrites at the expense of another. -

Binary Search Tree
ADT Binary Search Tree! Ellen Walker! CPSC 201 Data Structures! Hiram College! Binary Search Tree! •" Value-based storage of information! –" Data is stored in order! –" Data can be retrieved by value efficiently! •" Is a binary tree! –" Everything in left subtree is < root! –" Everything in right subtree is >root! –" Both left and right subtrees are also BST#s! Operations on BST! •" Some can be inherited from binary tree! –" Constructor (for empty tree)! –" Inorder, Preorder, and Postorder traversal! •" Some must be defined ! –" Insert item! –" Delete item! –" Retrieve item! The Node<E> Class! •" Just as for a linked list, a node consists of a data part and links to successor nodes! •" The data part is a reference to type E! •" A binary tree node must have links to both its left and right subtrees! The BinaryTree<E> Class! The BinaryTree<E> Class (continued)! Overview of a Binary Search Tree! •" Binary search tree definition! –" A set of nodes T is a binary search tree if either of the following is true! •" T is empty! •" Its root has two subtrees such that each is a binary search tree and the value in the root is greater than all values of the left subtree but less than all values in the right subtree! Overview of a Binary Search Tree (continued)! Searching a Binary Tree! Class TreeSet and Interface Search Tree! BinarySearchTree Class! BST Algorithms! •" Search! •" Insert! •" Delete! •" Print values in order! –" We already know this, it#s inorder traversal! –" That#s why it#s called “in order”! Searching the Binary Tree! •" If the tree is -

Algorithms and Complexity (AL)
Algorithms and Complexity (AL) Algorithms are fundamental to computer science and software engineering. The real-world performance of any software system depends on the algorithms chosen and the suitability of the various layers of implementation. Good algorithm design is therefore crucial for the performance of all software systems. Moreover, the study of algorithms provides insight into the intrinsic nature of the problem as well as possible solution techniques independent of programming language, programming paradigm, computer hardware, or any other implementation aspect. An important part of computing is the ability to select algorithms appropriate to particular purposes and to apply them, recognizing the possibility that no suitable algorithm may exist. This facility relies on understanding the range of algorithms that address an important set of well-defined problems, recognizing their strengths and weaknesses, and their suitability in particular contexts. Efficiency is a pervasive theme throughout this area. This knowledge area defines the central concepts and skills required to design, implement, and analyze algorithms for solving problems. Algorithms are essential in all advanced areas of computer science: artificial intelligence, databases, distributed computing, graphics, networking, operating systems, programming languages, security, and so on. Algorithms that have specific utility in each of these are listed in the relevant knowledge areas. Cryptography, for example, appears in the new Knowledge Area on Information Assurance and Security (IAS), while parallel and distributed algorithms appear in the Knowledge Area in Parallel and Distributed Computing (PD). As with all knowledge areas, the order of topics and their groupings do not necessarily correlate to a specific order of presentation. Different programs will teach the topics in different courses and should do so in the order they believe is most appropriate for their students. -

6.172 Lecture 19 : Cache-Oblivious B-Tree (Tokudb)
How TokuDB Fractal TreeTM Indexes Work Bradley C. Kuszmaul Guest Lecture in MIT 6.172 Performance Engineering, 18 November 2010. 6.172 —How Fractal Trees Work 1 My Background • I’m an MIT alum: MIT Degrees = 2 × S.B + S.M. + Ph.D. • I was a principal architect of the Connection Machine CM-5 super computer at Thinking Machines. • I was Assistant Professor at Yale. • I was Akamai working on network mapping and billing. • I am research faculty in the SuperTech group, working with Charles. 6.172 —How Fractal Trees Work 2 Tokutek A few years ago I started collaborating with Michael Bender and Martin Farach-Colton on how to store data on disk to achieve high performance. We started Tokutek to commercialize the research. 6.172 —How Fractal Trees Work 3 I/O is a Big Bottleneck Sensor Query Systems include Sensor Disk Query sensors and Sensor storage, and Query want to perform Millions of data elements arrive queries on per second Query recently arrived data using indexes. recent data. Sensor 6.172 —How Fractal Trees Work 4 The Data Indexing Problem • Data arrives in one order (say, sorted by the time of the observation). • Data is queried in another order (say, by URL or location). Sensor Query Sensor Disk Query Sensor Query Millions of data elements arrive per second Query recently arrived data using indexes. Sensor 6.172 —How Fractal Trees Work 5 Why Not Simply Sort? • This is what data Data Sorted by Time warehouses do. • The problem is that you Sort must wait to sort the data before querying it: Data Sorted by URL typically an overnight delay. -

Assignment of Master's Thesis
CZECH TECHNICAL UNIVERSITY IN PRAGUE FACULTY OF INFORMATION TECHNOLOGY ASSIGNMENT OF MASTER’S THESIS Title: Approximate Pattern Matching In Sparse Multidimensional Arrays Using Machine Learning Based Methods Student: Bc. Anna Kučerová Supervisor: Ing. Luboš Krčál Study Programme: Informatics Study Branch: Knowledge Engineering Department: Department of Theoretical Computer Science Validity: Until the end of winter semester 2018/19 Instructions Sparse multidimensional arrays are a common data structure for effective storage, analysis, and visualization of scientific datasets. Approximate pattern matching and processing is essential in many scientific domains. Previous algorithms focused on deterministic filtering and aggregate matching using synopsis style indexing. However, little work has been done on application of heuristic based machine learning methods for these approximate array pattern matching tasks. Research current methods for multidimensional array pattern matching, discovery, and processing. Propose a method for array pattern matching and processing tasks utilizing machine learning methods, such as kernels, clustering, or PSO in conjunction with inverted indexing. Implement the proposed method and demonstrate its efficiency on both artificial and real world datasets. Compare the algorithm with deterministic solutions in terms of time and memory complexities and pattern occurrence miss rates. References Will be provided by the supervisor. doc. Ing. Jan Janoušek, Ph.D. prof. Ing. Pavel Tvrdík, CSc. Head of Department Dean Prague February 28, 2017 Czech Technical University in Prague Faculty of Information Technology Department of Knowledge Engineering Master’s thesis Approximate Pattern Matching In Sparse Multidimensional Arrays Using Machine Learning Based Methods Bc. Anna Kuˇcerov´a Supervisor: Ing. LuboˇsKrˇc´al 9th May 2017 Acknowledgements Main credit goes to my supervisor Ing. -
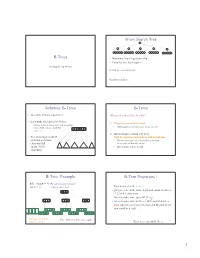
B-Trees M-Ary Search Tree Solution
M-ary Search Tree B-Trees • Maximum branching factor of M • Complete tree has height = Section 4.7 in Weiss # disk accesses for find : Runtime of find : 2 Solution: B-Trees B-Trees • specialized M-ary search trees What makes them disk-friendly? • Each node has (up to) M-1 keys: 1. Many keys stored in a node – subtree between two keys x and y contains leaves with values v such that • All brought to memory/cache in one access! 3 7 12 21 x ≤ v < y 2. Internal nodes contain only keys; • Pick branching factor M Only leaf nodes contain keys and actual data such that each node • The tree structure can be loaded into memory takes one full irrespective of data object size {page, block } x<3 3≤x<7 7≤x<12 12 ≤x<21 21 ≤x • Data actually resides in disk of memory 3 4 B-Tree: Example B-Tree Properties ‡ B-Tree with M = 4 (# pointers in internal node) and L = 4 (# data items in leaf) – Data is stored at the leaves – All leaves are at the same depth and contain between 10 40 L/2 and L data items – Internal nodes store up to M-1 keys 3 15 20 30 50 – Internal nodes have between M/2 and M children – Root (special case) has between 2 and M children (or root could be a leaf) 1 2 10 11 12 20 25 26 40 42 AB xG 3 5 6 9 15 17 30 32 33 36 50 60 70 Data objects, that I’ll Note: All leaves at the same depth! ignore in slides 5 ‡These are technically B +-Trees 6 1 Example, Again B-trees vs. -

AVL Trees and Rotations
/ AVL trees and rotations Q1 Operations (insert, delete, search) are O(height) Tree height is O(log n) if perfectly balanced ◦ But maintaining perfect balance is O(n) Height-balanced trees are still O(log n) ◦ For T with height h, N(T) ≤ Fib(h+3) – 1 ◦ So H < 1.44 log (N+2) – 1.328 * AVL (Adelson-Velskii and Landis) trees maintain height-balance using rotations Are rotations O(log n)? We’ll see… / or = or \ Different representations for / = \ : Just two bits in a low-level language Enum in a higher-level language / Assume tree is height-balanced before insertion Insert as usual for a BST Move up from the newly inserted node to the lowest “unbalanced” node (if any) ◦ Use the balance code to detect unbalance - how? Do an appropriate rotation to balance the sub-tree rooted at this unbalanced node For example, a single left rotation: Two basic cases ◦ “See saw” case: Too-tall sub-tree is on the outside So tip the see saw so it’s level ◦ “Suck in your gut” case: Too-tall sub-tree is in the middle Pull its root up a level Q2-3 Unbalanced node Middle sub-tree attaches to lower node of the “see saw” Diagrams are from Data Structures by E.M. Reingold and W.J. Hansen Q4-5 Unbalanced node Pulled up Split between the nodes pushed down Weiss calls this “right-left double rotation” Q6 Write the method: static BalancedBinaryNode singleRotateLeft ( BalancedBinaryNode parent, /* A */ BalancedBinaryNode child /* B */ ) { } Returns a reference to the new root of this subtree. -

Tries and String Matching
Tries and String Matching Where We've Been ● Fundamental Data Structures ● Red/black trees, B-trees, RMQ, etc. ● Isometries ● Red/black trees ≡ 2-3-4 trees, binomial heaps ≡ binary numbers, etc. ● Amortized Analysis ● Aggregate, banker's, and potential methods. Where We're Going ● String Data Structures ● Data structures for storing and manipulating text. ● Randomized Data Structures ● Using randomness as a building block. ● Integer Data Structures ● Breaking the Ω(n log n) sorting barrier. ● Dynamic Connectivity ● Maintaining connectivity in an changing world. String Data Structures Text Processing ● String processing shows up everywhere: ● Computational biology: Manipulating DNA sequences. ● NLP: Storing and organizing huge text databases. ● Computer security: Building antivirus databases. ● Many problems have polynomial-time solutions. ● Goal: Design theoretically and practically efficient algorithms that outperform brute-force approaches. Outline for Today ● Tries ● A fundamental building block in string processing algorithms. ● Aho-Corasick String Matching ● A fast and elegant algorithm for searching large texts for known substrings. Tries Ordered Dictionaries ● Suppose we want to store a set of elements supporting the following operations: ● Insertion of new elements. ● Deletion of old elements. ● Membership queries. ● Successor queries. ● Predecessor queries. ● Min/max queries. ● Can use a standard red/black tree or splay tree to get (worst-case or expected) O(log n) implementations of each. A Catch ● Suppose we want to store a set of strings. ● Comparing two strings of lengths r and s takes time O(min{r, s}). ● Operations on a balanced BST or splay tree now take time O(M log n), where M is the length of the longest string in the tree. -

UNIVERSIDAD SAN FRANCISCO DE QUITO USFQ Optimizing Large
UNIVERSIDAD SAN FRANCISCO DE QUITO USFQ Colegio de Ciencias e Ingenierías Optimizing Large Databases: A Study on Index Structures Proyecto de Investigación . Ricardo Andres Leon Ruiz Ingeniería en Sistemas Trabajo de titulación presentado como requisito para la obtención del título de Ingeniero en Sistemas Quito, 22 de Diciembre de 2017 2 UNIVERSIDAD SAN FRANCISCO DE QUITO USFQ COLEGIO DE CIENCIAS E INGENIERÍAS HOJA DE CALIFICACIÓN DE TRABAJO DE TITULACIÓN Optimizing Large Databases: A Study on Index Structures Ricardo Andres Leon Ruiz Calificación: Nombre del profesor, Título académico Aldo Cassola, Ph.D. Firma del profesor Quito, Diciembre de 2017 3 Derechos de Autor Por medio del presente documento certifico que he leído todas las Políticas y Manuales de la Universidad San Francisco de Quito USFQ, incluyendo la Política de Propiedad Intelectual USFQ, y estoy de acuerdo con su contenido, por lo que los derechos de propiedad intelectual del presente trabajo quedan sujetos a lo dispuesto en esas Políticas. Asimismo, autorizo a la USFQ para que realice la digitalización y publicación de este trabajo en el repositorio virtual, de conformidad a lo dispuesto en el Art. 144 de la Ley Orgánica de Educación Superior. Firma del estudiante: Nombres y Apellidos: Ricardo Andres Leon Ruiz Código de estudiante: 110346 C. I.: 1714286265 Lugar, Fecha Quito, 22 de Diciembre de 2017 4 RESUMEN La siguiente investigación trata sobre comparar estructuras de índice para grandes bases de datos, tanto analíticamente, como experimentalmente. El estudio se encuentra dividido en dos partes principales. La primera parte se centra en índices de hash y B-trees. Ambas estructuras son estudiadas en el contexto del modelo de acceso de disco tradicional. -

Binary Tree Fall 2017 Stony Brook University Instructor: Shebuti Rayana [email protected] Introduction to Tree
CSE 230 Intermediate Programming in C and C++ Binary Tree Fall 2017 Stony Brook University Instructor: Shebuti Rayana [email protected] Introduction to Tree ■ Tree is a non-linear data structure which is a collection of data (Node) organized in hierarchical structure. ■ In tree data structure, every individual element is called as Node. Node stores – the actual data of that particular element and – link to next element in hierarchical structure. Tree with 11 nodes and 10 edges Shebuti Rayana (CS, Stony Brook University) 2 Tree Terminology ■ Root ■ In a tree data structure, the first node is called as Root Node. Every tree must have root node. In any tree, there must be only one root node. Root node does not have any parent. (same as head in a LinkedList). Here, A is the Root node Shebuti Rayana (CS, Stony Brook University) 3 Tree Terminology ■ Edge ■ The connecting link between any two nodes is called an Edge. In a tree with 'N' number of nodes there will be a maximum of 'N-1' number of edges. Edge is the connecting link between the two nodes Shebuti Rayana (CS, Stony Brook University) 4 Tree Terminology ■ Parent ■ The node which is predecessor of any node is called as Parent Node. The node which has branch from it to any other node is called as parent node. Parent node can also be defined as "The node which has child / children". Here, A is Parent of B and C B is Parent of D, E and F C is the Parent of G and H Shebuti Rayana (CS, Stony Brook University) 5 Tree Terminology ■ Child ■ The node which is descendant of any node is called as CHILD Node.