Real-Time Black-Box Modelling with Recurrent Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chombining Recurrent Neural Networks and Adversarial Training
Combining Recurrent Neural Networks and Adversarial Training for Human Motion Modelling, Synthesis and Control † ‡ Zhiyong Wang∗ Jinxiang Chai Shihong Xia Institute of Computing Texas A&M University Institute of Computing Technology CAS Technology CAS University of Chinese Academy of Sciences ABSTRACT motions from the generator using recurrent neural networks (RNNs) This paper introduces a new generative deep learning network for and refines the generated motion using an adversarial neural network human motion synthesis and control. Our key idea is to combine re- which we call the “refiner network”. Fig 2 gives an overview of current neural networks (RNNs) and adversarial training for human our method: a motion sequence XRNN is generated with the gener- motion modeling. We first describe an efficient method for training ator G and is refined using the refiner network R. To add realism, a RNNs model from prerecorded motion data. We implement recur- we train our refiner network using an adversarial loss, similar to rent neural networks with long short-term memory (LSTM) cells Generative Adversarial Networks (GANs) [9] such that the refined because they are capable of handling nonlinear dynamics and long motion sequences Xre fine are indistinguishable from real motion cap- term temporal dependencies present in human motions. Next, we ture sequences Xreal using a discriminative network D. In addition, train a refiner network using an adversarial loss, similar to Gener- we embed contact information into the generative model to further ative Adversarial Networks (GANs), such that the refined motion improve the quality of the generated motions. sequences are indistinguishable from real motion capture data using We construct the generator G based on recurrent neural network- a discriminative network. -

Recurrent Neural Network for Text Classification with Multi-Task
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16) Recurrent Neural Network for Text Classification with Multi-Task Learning Pengfei Liu Xipeng Qiu⇤ Xuanjing Huang Shanghai Key Laboratory of Intelligent Information Processing, Fudan University School of Computer Science, Fudan University 825 Zhangheng Road, Shanghai, China pfliu14,xpqiu,xjhuang @fudan.edu.cn { } Abstract are based on unsupervised objectives such as word predic- tion for training [Collobert et al., 2011; Turian et al., 2010; Neural network based methods have obtained great Mikolov et al., 2013]. This unsupervised pre-training is effec- progress on a variety of natural language process- tive to improve the final performance, but it does not directly ing tasks. However, in most previous works, the optimize the desired task. models are learned based on single-task super- vised objectives, which often suffer from insuffi- Multi-task learning utilizes the correlation between related cient training data. In this paper, we use the multi- tasks to improve classification by learning tasks in parallel. [ task learning framework to jointly learn across mul- Motivated by the success of multi-task learning Caruana, ] tiple related tasks. Based on recurrent neural net- 1997 , there are several neural network based NLP models [ ] work, we propose three different mechanisms of Collobert and Weston, 2008; Liu et al., 2015b utilize multi- sharing information to model text with task-specific task learning to jointly learn several tasks with the aim of and shared layers. The entire network is trained mutual benefit. The basic multi-task architectures of these jointly on all these tasks. Experiments on four models are to share some lower layers to determine common benchmark text classification tasks show that our features. -

An Overview of Deep Learning Strategies for Time Series Prediction
An Overview of Deep Learning Strategies for Time Series Prediction Rodrigo Neves Instituto Superior Tecnico,´ Lisboa, Portugal [email protected] June 2018 Abstract—Deep learning is getting a lot of attention in the last Jenkins methodology [2] and were developed mainly in the few years, mainly due to the state-of-the-art results obtained in area of econometrics and statistics. different areas like object detection, natural language processing, Driven by the rise of popularity and attention in the area sequential modeling, among many others. Time series problems are a special case of sequential data, where deep learning models of deep learning, due to the state-of-the-art results obtained can be applied. The standard option to this type of problems in several areas, Artificial Neural Networks (ANN), which are are Recurrent Neural Networks (RNNs), but recent results are non-linear function approximator, have also been receiving an supporting the idea that Convolutional Neural Networks (CNNs) increasing attention in time series field. This rise of popularity can also be applied to time series with good results. This raises is associated with the breakthroughs achieved in this area, with the following question - Which are the best attributes and architectures to apply in time series prediction problems? It was the successful application of CNNs and RNNs to sequential assessed which is the current state on deep learning applied to modeling problems, with promising results [3]. RNNs are a time-series and studied which are the most promising topologies type of artificial neural networks that were specially designed and characteristics on sequential tasks that are worth it to to deal with sequential tasks, and thus can be used on time be explored. -

Deep Learning Architectures for Sequence Processing
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright © 2021. All rights reserved. Draft of September 21, 2021. CHAPTER Deep Learning Architectures 9 for Sequence Processing Time will explain. Jane Austen, Persuasion Language is an inherently temporal phenomenon. Spoken language is a sequence of acoustic events over time, and we comprehend and produce both spoken and written language as a continuous input stream. The temporal nature of language is reflected in the metaphors we use; we talk of the flow of conversations, news feeds, and twitter streams, all of which emphasize that language is a sequence that unfolds in time. This temporal nature is reflected in some of the algorithms we use to process lan- guage. For example, the Viterbi algorithm applied to HMM part-of-speech tagging, proceeds through the input a word at a time, carrying forward information gleaned along the way. Yet other machine learning approaches, like those we’ve studied for sentiment analysis or other text classification tasks don’t have this temporal nature – they assume simultaneous access to all aspects of their input. The feedforward networks of Chapter 7 also assumed simultaneous access, al- though they also had a simple model for time. Recall that we applied feedforward networks to language modeling by having them look only at a fixed-size window of words, and then sliding this window over the input, making independent predictions along the way. Fig. 9.1, reproduced from Chapter 7, shows a neural language model with window size 3 predicting what word follows the input for all the. Subsequent words are predicted by sliding the window forward a word at a time. -
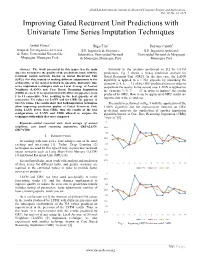
Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 12, 2019 Improving Gated Recurrent Unit Predictions with Univariate Time Series Imputation Techniques 1 Anibal Flores Hugo Tito2 Deymor Centty3 Grupo de Investigación en Ciencia E.P. Ingeniería de Sistemas e E.P. Ingeniería Ambiental de Datos, Universidad Nacional de Informática, Universidad Nacional Universidad Nacional de Moquegua Moquegua, Moquegua, Perú de Moquegua, Moquegua, Perú Moquegua, Perú Abstract—The work presented in this paper has its main Similarly to the analysis performed in [1] for LSTM objective to improve the quality of the predictions made with the predictions, Fig. 1 shows a 14-day prediction analysis for recurrent neural network known as Gated Recurrent Unit Gated Recurrent Unit (GRU). In the first case, the LANN (GRU). For this, instead of making different adjustments to the algorithm is applied to a 1 NA gap-size by rebuilding the architecture of the neural network in question, univariate time elements 2, 4, 6, …, 12 of the GRU-predicted series in order to series imputation techniques such as Local Average of Nearest outperform the results. In the second case, LANN is applied for Neighbors (LANN) and Case Based Reasoning Imputation the elements 3, 5, 7, …, 13 in order to improve the results (CBRi) are used. It is experimented with different gap-sizes, from produced by GRU. How it can be appreciated GRU results are 1 to 11 consecutive NAs, resulting in the best gap-size of six improve just in the second case. consecutive NA values for LANN and for CBRi the gap-size of two NA values. -

Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Lecture 11 Recurrent Neural Networks I CMSC 35246 Introduction Sequence Learning with Neural Networks Lecture 11 Recurrent Neural Networks I CMSC 35246 Some Sequence Tasks Figure credit: Andrej Karpathy Lecture 11 Recurrent Neural Networks I CMSC 35246 MLPs only accept an input of fixed dimensionality and map it to an output of fixed dimensionality Great e.g.: Inputs - Images, Output - Categories Bad e.g.: Inputs - Text in one language, Output - Text in another language MLPs treat every example independently. How is this problematic? Need to re-learn the rules of language from scratch each time Another example: Classify events after a fixed number of frames in a movie Need to resuse knowledge about the previous events to help in classifying the current. Problems with MLPs for Sequence Tasks The "API" is too limited. Lecture 11 Recurrent Neural Networks I CMSC 35246 Great e.g.: Inputs - Images, Output - Categories Bad e.g.: Inputs - Text in one language, Output - Text in another language MLPs treat every example independently. How is this problematic? Need to re-learn the rules of language from scratch each time Another example: Classify events after a fixed number of frames in a movie Need to resuse knowledge about the previous events to help in classifying the current. Problems with MLPs for Sequence Tasks The "API" is too limited. MLPs only accept an input of fixed dimensionality and map it to an output of fixed dimensionality Lecture 11 Recurrent Neural Networks I CMSC 35246 Bad e.g.: Inputs - Text in one language, Output - Text in another language MLPs treat every example independently. -

Sentiment Analysis with Gated Recurrent Units
Advances in Computer Science and Information Technology (ACSIT) Print ISSN: 2393-9907; Online ISSN: 2393-9915; Volume 2, Number 11; April-June, 2015 pp. 59-63 © Krishi Sanskriti Publications http://www.krishisanskriti.org/acsit.html Sentiment Analysis with Gated Recurrent Units Shamim Biswas1, Ekamber Chadda2 and Faiyaz Ahmad3 1,2,3Department of Computer Engineering Jamia Millia Islamia New Delhi, India E-mail: [email protected], 2ekamberc @gmail.com, [email protected] Abstract—Sentiment analysis is a well researched natural language learns word embeddings from unlabeled text samples. It learns processing field. It is a challenging machine learning task due to the both by predicting the word given its surrounding recursive nature of sentences, different length of documents and words(CBOW) and predicting surrounding words from given sarcasm. Traditional approaches to sentiment analysis use count or word(SKIP-GRAM). These word embeddings are used for frequency of words in the text which are assigned sentiment value by some expert. These approaches disregard the order of words and the creating dictionaries and act as dimensionality reducers in complex meanings they can convey. Gated Recurrent Units are recent traditional method like tf-idf etc. More approaches are found form of recurrent neural network which have the ability to store capturing sentence level representations like recursive neural information of long term dependencies in sequential data. In this tensor network (RNTN) [2] work we showed that GRU are suitable for processing long textual data and applied it to the task of sentiment analysis. We showed its Convolution neural network which has primarily been used for effectiveness by comparing with tf-idf and word2vec models. -

Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting
water Article Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting Halit Apaydin 1 , Hajar Feizi 2 , Mohammad Taghi Sattari 1,2,* , Muslume Sevba Colak 1 , Shahaboddin Shamshirband 3,4,* and Kwok-Wing Chau 5 1 Department of Agricultural Engineering, Faculty of Agriculture, Ankara University, Ankara 06110, Turkey; [email protected] (H.A.); [email protected] (M.S.C.) 2 Department of Water Engineering, Agriculture Faculty, University of Tabriz, Tabriz 51666, Iran; [email protected] 3 Department for Management of Science and Technology Development, Ton Duc Thang University, Ho Chi Minh City, Vietnam 4 Faculty of Information Technology, Ton Duc Thang University, Ho Chi Minh City, Vietnam 5 Department of Civil and Environmental Engineering, Hong Kong Polytechnic University, Hong Kong, China; [email protected] * Correspondence: [email protected] or [email protected] (M.T.S.); [email protected] (S.S.) Received: 1 April 2020; Accepted: 21 May 2020; Published: 24 May 2020 Abstract: Due to the stochastic nature and complexity of flow, as well as the existence of hydrological uncertainties, predicting streamflow in dam reservoirs, especially in semi-arid and arid areas, is essential for the optimal and timely use of surface water resources. In this research, daily streamflow to the Ermenek hydroelectric dam reservoir located in Turkey is simulated using deep recurrent neural network (RNN) architectures, including bidirectional long short-term memory (Bi-LSTM), gated recurrent unit (GRU), long short-term memory (LSTM), and simple recurrent neural networks (simple RNN). For this purpose, daily observational flow data are used during the period 2012–2018, and all models are coded in Python software programming language. -

A Guide to Recurrent Neural Networks and Backpropagation
A guide to recurrent neural networks and backpropagation Mikael Bod´en¤ [email protected] School of Information Science, Computer and Electrical Engineering Halmstad University. November 13, 2001 Abstract This paper provides guidance to some of the concepts surrounding recurrent neural networks. Contrary to feedforward networks, recurrent networks can be sensitive, and be adapted to past inputs. Backpropagation learning is described for feedforward networks, adapted to suit our (probabilistic) modeling needs, and extended to cover recurrent net- works. The aim of this brief paper is to set the scene for applying and understanding recurrent neural networks. 1 Introduction It is well known that conventional feedforward neural networks can be used to approximate any spatially finite function given a (potentially very large) set of hidden nodes. That is, for functions which have a fixed input space there is always a way of encoding these functions as neural networks. For a two-layered network, the mapping consists of two steps, y(t) = G(F (x(t))): (1) We can use automatic learning techniques such as backpropagation to find the weights of the network (G and F ) if sufficient samples from the function is available. Recurrent neural networks are fundamentally different from feedforward architectures in the sense that they not only operate on an input space but also on an internal state space – a trace of what already has been processed by the network. This is equivalent to an Iterated Function System (IFS; see (Barnsley, 1993) for a general introduction to IFSs; (Kolen, 1994) for a neural network perspective) or a Dynamical System (DS; see e.g. -

Overview of Lstms and Word2vec and a Bit About Compositional Distributional Semantics If There’S Time
Overview of LSTMs and word2vec and a bit about compositional distributional semantics if there’s time Ann Copestake Computer Laboratory University of Cambridge November 2016 Outline RNNs and LSTMs Word2vec Compositional distributional semantics Some slides adapted from Aurelie Herbelot. Outline. RNNs and LSTMs Word2vec Compositional distributional semantics Motivation I Standard NNs cannot handle sequence information well. I Can pass them sequences encoded as vectors, but input vectors are fixed length. I Models are needed which are sensitive to sequence input and can output sequences. I RNN: Recurrent neural network. I Long short term memory (LSTM): development of RNN, more effective for most language applications. I More info: http://neuralnetworksanddeeplearning.com/ (mostly about simpler models and CNNs) https://karpathy.github.io/2015/05/21/rnn-effectiveness/ http://colah.github.io/posts/2015-08-Understanding-LSTMs/ Sequences I Video frame categorization: strict time sequence, one output per input. I Real-time speech recognition: strict time sequence. I Neural MT: target not one-to-one with source, order differences. I Many language tasks: best to operate left-to-right and right-to-left (e.g., bi-LSTM). I attention: model ‘concentrates’ on part of input relevant at a particular point. Caption generation: treat image data as ordered, align parts of image with parts of caption. Recurrent Neural Networks http://colah.github.io/posts/ 2015-08-Understanding-LSTMs/ RNN language model: Mikolov et al, 2010 RNN as a language model I Input vector: vector for word at t concatenated to vector which is output from context layer at t − 1. I Performance better than n-grams but won’t capture ‘long-term’ dependencies: She shook her head. -

Long Short Term Memory (LSTM) Recurrent Neural Network (RNN)
Long Short Term Memory (LSTM) Recurrent Neural Network (RNN) To understand RNNs, let’s use a simple perceptron network with one hidden layer. Loops ensure a consistent flow of informa=on. A (chunk of neural network) produces an output ht based on the input Xt . A — Neural Network Xt — Input ht — Output Disadvantages of RNN • RNNs have a major setback called vanishing gradient; that is, they have difficul=es in learning long-range dependencies (rela=onship between en==es that are several steps apart) • In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in prac=ce, RNNs don’t seem to be able to learn them. The problem was explored in depth by Bengio, et al. (1994), who found some preTy fundamental reasons why it might be difficult. Solu%on • To solve this issue, a special kind of RNN called Long Short-Term Memory cell (LSTM) was developed. Introduc@on to LSTM • Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. • LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering informa=on for long periods of =me is prac=cally their default behavior, not something they struggle to learn! • All recurrent neural networks have the form of a chain of repea=ng modules of neural network. In standard RNNs, this repea=ng module will have a very simple structure, such as a single tanh layer. • LSTMs also have this chain like structure, but the repea=ng module has a different structure. -
![Arxiv:1910.10202V2 [Cs.LG] 6 Aug 2021 Its Richer Representational Capacity](https://docslib.b-cdn.net/cover/8198/arxiv-1910-10202v2-cs-lg-6-aug-2021-its-richer-representational-capacity-1348198.webp)
Arxiv:1910.10202V2 [Cs.LG] 6 Aug 2021 Its Richer Representational Capacity
COMPLEX TRANSFORMER: A FRAMEWORK FOR MODELING COMPLEX-VALUED SEQUENCE Muqiao Yang*, Martin Q. Ma*, Dongyu Li*, Yao-Hung Hubert Tsai, Ruslan Salakhutdinov Carnegie Mellon University, Pittsburgh, PA, USA fmuqiaoy, qianlim, dongyul, yaohungt, [email protected] ABSTRACT model because of their capability of looking at a more ex- tended range of input contexts and representing those in While deep learning has received a surge of interest in a va- different subspaces. Attention is, therefore, promising for riety of fields in recent years, major deep learning models building a complex-valued model capable of analyzing high- barely use complex numbers. However, speech, signal and dimensional data with long temporal dependency. We in- audio data are naturally complex-valued after Fourier Trans- troduce a Complex Transformer to solve complex-valued form, and studies have shown a potentially richer represen- sequence modeling tasks, including prediction and genera- tation of complex nets. In this paper, we propose a Com- tion. The Complex Transformer adapts complex representa- plex Transformer, which incorporates the transformer model tions and operations into the transformer network. We test as a backbone for sequence modeling; we also develop at- the model with MusicNet, a dataset for music transcription tention and encoder-decoder network operating for complex [14], and a complex high-dimensional time series In-phase input. The model achieves state-of-the-art performance on Quadrature (IQ) signal dataset. The specific contributions of the MusicNet dataset and an In-phase Quadrature (IQ) sig- our work are as follows: nal dataset. The GitHub implementation to reproduce the ex- Our Complex Transformer achieves state-of-the-art re- perimental results is available at https://github.com/ sults on the MusicNet dataset [14], a dataset of classical mu- muqiaoy/dl_signal.