Adaptive Multimodale Exploration Von Musiksammlungen
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Songs by Title Karaoke Night with the Patman
Songs By Title Karaoke Night with the Patman Title Versions Title Versions 10 Years 3 Libras Wasteland SC Perfect Circle SI 10,000 Maniacs 3 Of Hearts Because The Night SC Love Is Enough SC Candy Everybody Wants DK 30 Seconds To Mars More Than This SC Kill SC These Are The Days SC 311 Trouble Me SC All Mixed Up SC 100 Proof Aged In Soul Don't Tread On Me SC Somebody's Been Sleeping SC Down SC 10CC Love Song SC I'm Not In Love DK You Wouldn't Believe SC Things We Do For Love SC 38 Special 112 Back Where You Belong SI Come See Me SC Caught Up In You SC Dance With Me SC Hold On Loosely AH It's Over Now SC If I'd Been The One SC Only You SC Rockin' Onto The Night SC Peaches And Cream SC Second Chance SC U Already Know SC Teacher, Teacher SC 12 Gauge Wild Eyed Southern Boys SC Dunkie Butt SC 3LW 1910 Fruitgum Co. No More (Baby I'm A Do Right) SC 1, 2, 3 Redlight SC 3T Simon Says DK Anything SC 1975 Tease Me SC The Sound SI 4 Non Blondes 2 Live Crew What's Up DK Doo Wah Diddy SC 4 P.M. Me So Horny SC Lay Down Your Love SC We Want Some Pussy SC Sukiyaki DK 2 Pac 4 Runner California Love (Original Version) SC Ripples SC Changes SC That Was Him SC Thugz Mansion SC 42nd Street 20 Fingers 42nd Street Song SC Short Dick Man SC We're In The Money SC 3 Doors Down 5 Seconds Of Summer Away From The Sun SC Amnesia SI Be Like That SC She Looks So Perfect SI Behind Those Eyes SC 5 Stairsteps Duck & Run SC Ooh Child SC Here By Me CB 50 Cent Here Without You CB Disco Inferno SC Kryptonite SC If I Can't SC Let Me Go SC In Da Club HT Live For Today SC P.I.M.P. -

DEUTSCHE KARAOKE LIEDER 2Raumwohnung 36 Grad DUI-7001
DEUTSCHE KARAOKE LIEDER 2Raumwohnung 36 Grad DUI-7001 Adel Tawil Ist Da Jemand DUI-7137 Amigos 110 Karat DUI-7166 Andrea Berg Das Gefuhl DUI-7111 Andrea Berg Davon Geht Mein Herz Nicht Unter DUI-7196 Andrea Berg Du Bist Das Feuer DUI-7116 Andrea Berg Du Hast Mich 1000 Mal Belogen DUI-7004 Andrea Berg Feuervogel DUI-7138 Andrea Berg Himmel Auf Erden DUI-7112 Andrea Berg In Dieser Nacht DUI-7003 Andrea Berg Lass Mich In Flammen Stehen DUI-7117 Andrea Berg Lust Auf Pures Leben DUI-7118 Andrea Berg Mosaik DUI-7197 Andrea Berg Wenn Du Jetzt Gehst, Nimm Auch Deine Liebe Mit DUI-7002 Andreas Gabalier I Sing A Liad Für Di DUI-7054 Andreas MarWn Du Bist Alles (Maria Maria) DUI-7139 Anna-Maria Zimmermann Du Hast Mir So Den Kopf Verdreht DUI-7119 Anna-Maria Zimmermann Scheiß Egal DUI-7167 Anstandslos & Durchgeknallt Egal DUI-7168 Beatrice Egli Fliegen DUI-7120 Beatrice Egli Keiner Küsst Mich (So Wie Du) DUI-7175 Beatrice Egli Mein Ein Und Alles DUI-7176 Beatrice Egli Was Geht Ab DUI-7177 Bill Ramsey Ohne Krimi Geht Die Mimi Nie Ins Bea DUI-7063 Cassandra Steen & Adel Tawil Stadt DUI-7055 Charly Brunner Wahre Liebe DUI-7178 Chris Roberts Du Kannst Nicht Immer 17 Sein DUI-7005 Chris Roberts Ich Bin Verliebt In Die Liebe DUI-7134 ChrisWan Anders Einsamkeit Had Viele Namen DUI-7006 ChrisWna Sturmer Engel Fliegen Einsam DUI-7007 ChrisWna Stürmer Mama Ana Ahabak DUI-7008 Cindy & Bert Immer Wieder Sonntags DUI-7136 Claudia Jung Mein Herz Lässt Dich Nie Allein DUI-7009 Conny & Peter Alexander Verliebt Verlobt Verheiratet DUI-7010 Conny Francis Schöner Fremder -

Eric Singer: Road Warrior
EXCLUSIVE! KISS DRUMMERS TIMELINE KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISSTHE WORLD’SKISS KISS #1 DRUMKISS RESOURCEKISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS ERICKISS KISS KISSSINGER: KISS KISS KISS ROADKISS KISS KISS WARRIOR KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS2020 KISS KISSMD KISS READERS KISS KISS KISS KISSPOLL KISS KISS KISS KISS KISSSS KISSKIS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISSSS KISSKIS KISS KISS KISSBALLOT’S KISS KISS KISS KISSOPEN! KISS KISS KISS KISS KISS KISS KISSSS KISS KIS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISSREMO KISS SUBKISS MUFF’LKISS KISS REVIEWED KISS KISS KISS KISS KISS KISS KISS KISSJANUARY KISS 2020 KISS KISS2019 KISS CHICAGO KISS KISS DRUM KISS KISS SHOW KISS KISS KISS KISS KISS KISS KISS KISS KISS KISSCREATIVE KISS KISS PRACTICE KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISSSTANTON KISS KISS MOORE KISS KISS GEARS KISS UPKISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS KISS What’s Old is New Again. -
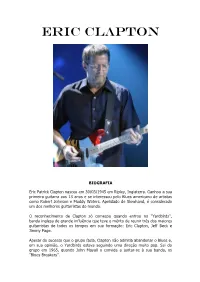
Eric Clapton
ERIC CLAPTON BIOGRAFIA Eric Patrick Clapton nasceu em 30/03/1945 em Ripley, Inglaterra. Ganhou a sua primeira guitarra aos 13 anos e se interessou pelo Blues americano de artistas como Robert Johnson e Muddy Waters. Apelidado de Slowhand, é considerado um dos melhores guitarristas do mundo. O reconhecimento de Clapton só começou quando entrou no “Yardbirds”, banda inglesa de grande influência que teve o mérito de reunir três dos maiores guitarristas de todos os tempos em sua formação: Eric Clapton, Jeff Beck e Jimmy Page. Apesar do sucesso que o grupo fazia, Clapton não admitia abandonar o Blues e, em sua opinião, o Yardbirds estava seguindo uma direção muito pop. Sai do grupo em 1965, quando John Mayall o convida a juntar-se à sua banda, os “Blues Breakers”. Gravam o álbum “Blues Breakers with Eric Clapton”, mas o relacionamento com Mayall não era dos melhores e Clapton deixa o grupo pouco tempo depois. Em 1966, forma os “Cream” com o baixista Jack Bruce e o baterista Ginger Baker. Com a gravação de 4 álbuns (“Fresh Cream”, “Disraeli Gears”, “Wheels Of Fire” e “Goodbye”) e muitos shows em terras norte americanas, os Cream atingiram enorme sucesso e Eric Clapton já era tido como um dos melhores guitarristas da história. A banda separa-se no fim de 1968 devido ao distanciamento entre os membros. Neste mesmo ano, Clapton a convite de seu amigo George Harisson, toca na faixa “While My Guitar Gently Weeps” do White Album dos Beatles. Forma os “Blind Faith” em 1969 com Steve Winwood, Ginger Baker e Rick Grech, que durou por pouco tempo, lançando apenas um album. -

Before You Accuse Me Tab by Eric Clapton
Before You Accuse Me Tab by Eric Clapton, www.Ultimate-Guitar.Com #----------------------------------PLEASE NOTE---------------------------------# #This file is the author's own work and represents their interpretation of the # #song. You may only use this file for private study, scholarship, or research. # #------------------------------------------------------------------------------# Date: 23.04.2005 Tabbed by Peter Tuyp ([email protected]) Subject: Eric Clapton - Before you accuse me (unplugged) This is the part Eric Clapton plays, but maybe here and there some notes of Andy Fairweather Low sneeked in. Chords: E7 0xx434 E°7 0xx323 Am6/e 0xx212 E 022100 B7 021202 Em 022000 E5 02xxxx E6 04xxxx A5 x022xx A6 x04xxx A7 x020xx A#m/d# xx1321 Bm/e xx2432 Intro: E7 E°7 Am6/e |---3/4-4-4-4---4-----------4---4---3---3---3---2---2-------------------| |---2/3-3-3-3---3-----------3---3---2---2---2---1---1-------------------| |---3/4-----4-----------------------3---3-----------2---------0h1p0h1---| |-----------------------------------------------------------------------| |-----------------------------------------------------------------------| |-0-0---0-0-0-------0---0---0---0---0-----0---0-0-------0---0-----------| E B7 |-0-3-0-3-0---0---------0-----------------------------------------------| |---3-0-3-0-3-----------0-----0---0------0------------------------------| |---------------2---0h1--------------------2-2--------------------------| |---------------------2-------------------------------------------------| |---------------------------2-------------------------------------------| -

June 30, 1973 CMS E POLVDOR CAPITOL F QUALITY I
GROUP AMERICA OF AVENUE THE OF MEMBER A best is ours feel We p.m. to RECORDS G.A.S. on 8:00 7:30 9 July and 2 July 5, 110[1,W d30[111 Tapes and Records Family Small Baby My Wrong Is Something When sy Sweet Railroad) The (On VVork'in song. same the release to companies I've Alimony Love Me Buy includes: record two for reason a be must There 0173 LI-0173/APS1-0173/APKI Longhair Professor Lady Harbor Junction Harmony Hideaway Hernando's Includes: kA 2 page on continued PROBST Windsor. of University The at course tics pj drama- a for this abandon to had but group a forming at try a made He published. songs his of one had and Music Berandol to tape a submitted Canada, to returned He world. songwriting the in down goes what into insight critical more a him gave but 7auieLLtailyhonza4 Probst for bust a was show Miami The Show. 11 Talent Club Key American North the in representative country's this as Club Key -THOMAS ID International the by sponsorship his came CLAYTON wins contest these of Out Festival. Folk and Kawartha the at Award Performer Solo Best Mekler Gabriel ticulous with year same the up followed he which World the in Musicians est Contest Talent Club Key Quebec/Maritimes Love and Happiness Ontario/ the won Probst 1968 of March In Sweat and Essentials gy performer. regular a Drive and reativity as... in hung he where Alternative, Only The time big the finally and Bramalea mixing by accomplished was ng in Bottom Rock the and Brampton in Club Knight The including houses coffee local playing to on went he there From material. -

Neil Reads Some Books Keith and What He Did
February 2018 February 101 In association with "AMERICAN MUSIC MAGAZINE" ALL ARTICLES/IMAGES ARE COPYRIGHT OF THEIR RESPECTIVE AUTHORS. FOR REPRODUCTION, PLEASE CONTACT ALAN LLOYD VIA TFTW.ORG.UK © Paul Harris Jeff Tuck finally gets some prominence (usually hidden behind guitars and vocalists) From the Last Hurrah for Skiffle on January 28th, courtesy of Paul Harris Neil reads some books Keith and what he did with Willie Mr Angry chats with Freddy Cannon We “borrow” more stuff from Nick Cobban Jazz Junction, Soul Kitchen, Blues Rambling And more.... 1 Greetings From Snobbo Manor I have not contributed to this publication for some years, but last night Henry and I went to see some Grand Opera, or so we thought. It turned out to be some dreadful American music apparently performed at something called the 'Grand Ole Opry' in Nashville, Tennessee. This woman sang a totally inappropriate song entitled 'Blanket On The Ground', one line of which went: 'Just because we are married doesn't mean we can't sleep around'! I ask you, this may be normal behaviour for hillbillies who marry their 13-year old cousins, but it is totally unacceptable here. A gentleman in the next row leaned over and tried to make out the words 'slip around', but of course that is absolute nonsense. Unless they were laying the blanket on icy ground why should they be slipping around? Then some awful man in a cowboy hat sang about his girlfriend coming out of a honkytonk. Why on Earth a woman would climb into an old upright pianoforte I have no idea; presumably this is where poor hillbillies live when their ramshackle huts fall down. -

Defining Music As an Emotional Catalyst Through a Sociological Study of Emotions, Gender and Culture
Western Michigan University ScholarWorks at WMU Dissertations Graduate College 12-2011 All I Am: Defining Music as an Emotional Catalyst through a Sociological Study of Emotions, Gender and Culture Adrienne M. Trier-Bieniek Western Michigan University Follow this and additional works at: https://scholarworks.wmich.edu/dissertations Part of the Musicology Commons, Music Therapy Commons, and the Sociology Commons Recommended Citation Trier-Bieniek, Adrienne M., "All I Am: Defining Music as an Emotional Catalyst through a Sociological Study of Emotions, Gender and Culture" (2011). Dissertations. 328. https://scholarworks.wmich.edu/dissertations/328 This Dissertation-Open Access is brought to you for free and open access by the Graduate College at ScholarWorks at WMU. It has been accepted for inclusion in Dissertations by an authorized administrator of ScholarWorks at WMU. For more information, please contact [email protected]. "ALL I AM": DEFINING MUSIC AS AN EMOTIONAL CATALYST THROUGH A SOCIOLOGICAL STUDY OF EMOTIONS, GENDER AND CULTURE. by Adrienne M. Trier-Bieniek A Dissertation Submitted to the Faculty of The Graduate College in partial fulfillment of the requirements for the Degree of Doctor of Philosophy Department of Sociology Advisor: Angela M. Moe, Ph.D. Western Michigan University Kalamazoo, Michigan April 2011 "ALL I AM": DEFINING MUSIC AS AN EMOTIONAL CATALYST THROUGH A SOCIOLOGICAL STUDY OF EMOTIONS, GENDER AND CULTURE Adrienne M. Trier-Bieniek, Ph.D. Western Michigan University, 2011 This dissertation, '"All I Am': Defining Music as an Emotional Catalyst through a Sociological Study of Emotions, Gender and Culture", is based in the sociology of emotions, gender and culture and guided by symbolic interactionist and feminist standpoint theory. -

The Big List (My Friends Are Gonna Be) Strangers Merle Haggard 1948 Barry P
THE BIG LIST (MY FRIENDS ARE GONNA BE) STRANGERS MERLE HAGGARD 1948 BARRY P. FOLEY A LIFE THAT'S GOOD LENNIE & MAGGIE A PLACE TO FALL APART MERLE HAGGARD ABILENE GEORGE HAMILITON IV ABOVE AND BEYOND WYNN STEWART-RODNEY CROWELL ACT NATURALLY BUCK OWENS-THE BEATLES ADALIDA GEORGE STRAIT AGAINST THE WIND BOB SEGER-HIGHWAYMAN AIN’T NO GOD IN MEXICO WAYLON JENNINGS AIN'T LIVING LONG LIKE THIS WAYLON JENNINGS AIN'T NO SUNSHINE BILL WITHERS AIRPORT LOVE STORY BARRY P. FOLEY ALL ALONG THE WATCHTOWER BOB DYLAN-JIMI HENDRIX ALL I HAVE TO DO IS DREAM EVERLY BROTHERS ALL I HAVE TO OFFER IS ME CHARLIE PRIDE ALL MY EX'S LIVE IN TEXAS GEORGE STRAIT ALL MY LOVING THE BEATLES ALL OF ME WILLIE NELSON ALL SHOOK UP ELVIS PRESLEY ALL THE GOLD IN CALIFORNIA GATLIN BROTHERS ALL YOU DO IS BRING ME DOWN THE MAVERICKS ALMOST PERSUADED DAVID HOUSTON ALWAYS LATE LEFTY FRIZZELL-DWIGHT YOAKAM ALWAYS ON MY MIND ELVIS PRESLEY-WILLIE NELSON ALWAYS WANTING YOU MERLE HAGGARD AMANDA DON WILLIAMS-WAYLON JENNINGS AMARILLO BY MORNING TERRY STAFFORD-GEORGE STRAIT AMAZING GRACE TRADITIONAL AMERICAN PIE DON McLEAN AMERICAN TRILOGY MICKEY NEWBERRY-ELVIS PRESLEY AMIE PURE PRAIRIE LEAGUE ANGEL FLYING TOO CLOSE WILLIE NELSON ANGEL OF LYON TOM RUSSELL-STEVE YOUNG ANGEL OF MONTGOMERY JOHN PRINE-BONNIE RAITT-DAVE MATTHEWS ANGELS LIKE YOU DAN MCCOY ANNIE'S SONG JOHN DENVER ANOTHER SATURDAY NIGHT SAM COOKE-JIMMY BUFFET-CAT STEVENS ARE GOOD TIMES REALLY OVER MERLE HAGGARD ARE YOU SURE HANK DONE IT WAYLON JENNINGS AUSTIN BLAKE SHELTON BABY PLEASE DON'T GO MUDDY WATERS-BIG JOE WILLIAMS BABY PUT ME ON THE WAGON BARRY P. -

Karaoke Mietsystem Songlist
Karaoke Mietsystem Songlist Ein Karaokesystem der Firma Showtronic Solutions AG in Zusammenarbeit mit Karafun. Karaoke-Katalog Update vom: 13/10/2020 Singen Sie online auf www.karafun.de Gesamter Katalog TOP 50 Shallow - A Star is Born Take Me Home, Country Roads - John Denver Skandal im Sperrbezirk - Spider Murphy Gang Griechischer Wein - Udo Jürgens Verdammt, Ich Lieb' Dich - Matthias Reim Dancing Queen - ABBA Dance Monkey - Tones and I Breaking Free - High School Musical In The Ghetto - Elvis Presley Angels - Robbie Williams Hulapalu - Andreas Gabalier Someone Like You - Adele 99 Luftballons - Nena Tage wie diese - Die Toten Hosen Ring of Fire - Johnny Cash Lemon Tree - Fool's Garden Ohne Dich (schlaf' ich heut' nacht nicht ein) - You Are the Reason - Calum Scott Perfect - Ed Sheeran Münchener Freiheit Stand by Me - Ben E. King Im Wagen Vor Mir - Henry Valentino And Uschi Let It Go - Idina Menzel Can You Feel The Love Tonight - The Lion King Atemlos durch die Nacht - Helene Fischer Roller - Apache 207 Someone You Loved - Lewis Capaldi I Want It That Way - Backstreet Boys Über Sieben Brücken Musst Du Gehn - Peter Maffay Summer Of '69 - Bryan Adams Cordula grün - Die Draufgänger Tequila - The Champs ...Baby One More Time - Britney Spears All of Me - John Legend Barbie Girl - Aqua Chasing Cars - Snow Patrol My Way - Frank Sinatra Hallelujah - Alexandra Burke Aber Bitte Mit Sahne - Udo Jürgens Bohemian Rhapsody - Queen Wannabe - Spice Girls Schrei nach Liebe - Die Ärzte Can't Help Falling In Love - Elvis Presley Country Roads - Hermes House Band Westerland - Die Ärzte Warum hast du nicht nein gesagt - Roland Kaiser Ich war noch niemals in New York - Ich War Noch Marmor, Stein Und Eisen Bricht - Drafi Deutscher Zombie - The Cranberries Niemals In New York Ich wollte nie erwachsen sein (Nessajas Lied) - Don't Stop Believing - Journey EXPLICIT Kann Texte enthalten, die nicht für Kinder und Jugendliche geeignet sind. -

Songs by Title
Karaoke Song Book Songs by Title Title Artist Title Artist #1 Nelly 18 And Life Skid Row #1 Crush Garbage 18 'til I Die Adams, Bryan #Dream Lennon, John 18 Yellow Roses Darin, Bobby (doo Wop) That Thing Parody 19 2000 Gorillaz (I Hate) Everything About You Three Days Grace 19 2000 Gorrilaz (I Would Do) Anything For Love Meatloaf 19 Somethin' Mark Wills (If You're Not In It For Love) I'm Outta Here Twain, Shania 19 Somethin' Wills, Mark (I'm Not Your) Steppin' Stone Monkees, The 19 SOMETHING WILLS,MARK (Now & Then) There's A Fool Such As I Presley, Elvis 192000 Gorillaz (Our Love) Don't Throw It All Away Andy Gibb 1969 Stegall, Keith (Sitting On The) Dock Of The Bay Redding, Otis 1979 Smashing Pumpkins (Theme From) The Monkees Monkees, The 1982 Randy Travis (you Drive Me) Crazy Britney Spears 1982 Travis, Randy (Your Love Has Lifted Me) Higher And Higher Coolidge, Rita 1985 BOWLING FOR SOUP 03 Bonnie & Clyde Jay Z & Beyonce 1985 Bowling For Soup 03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 BOWLING FOR SOUP '03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 Bowling For Soup 03 Bonnie And Clyde Jay Z & Beyonce 1999 Prince 1 2 3 Estefan, Gloria 1999 Prince & Revolution 1 Thing Amerie 1999 Wilkinsons, The 1, 2, 3, 4, Sumpin' New Coolio 19Th Nervous Breakdown Rolling Stones, The 1,2 STEP CIARA & M. ELLIOTT 2 Become 1 Jewel 10 Days Late Third Eye Blind 2 Become 1 Spice Girls 10 Min Sorry We've Stopped Taking Requests 2 Become 1 Spice Girls, The 10 Min The Karaoke Show Is Over 2 Become One SPICE GIRLS 10 Min Welcome To Karaoke Show 2 Faced Louise 10 Out Of 10 Louchie Lou 2 Find U Jewel 10 Rounds With Jose Cuervo Byrd, Tracy 2 For The Show Trooper 10 Seconds Down Sugar Ray 2 Legit 2 Quit Hammer, M.C. -

Mediated Music Makers. Constructing Author Images in Popular Music
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Helsingin yliopiston digitaalinen arkisto Laura Ahonen Mediated music makers Constructing author images in popular music Academic dissertation to be publicly discussed, by due permission of the Faculty of Arts at the University of Helsinki in auditorium XII, on the 10th of November, 2007 at 10 o’clock. Laura Ahonen Mediated music makers Constructing author images in popular music Finnish Society for Ethnomusicology Publ. 16. © Laura Ahonen Layout: Tiina Kaarela, Federation of Finnish Learned Societies ISBN 978-952-99945-0-2 (paperback) ISBN 978-952-10-4117-4 (PDF) Finnish Society for Ethnomusicology Publ. 16. ISSN 0785-2746. Contents Acknowledgements. 9 INTRODUCTION – UNRAVELLING MUSICAL AUTHORSHIP. 11 Background – On authorship in popular music. 13 Underlying themes and leading ideas – The author and the work. 15 Theoretical framework – Constructing the image. 17 Specifying the image types – Presented, mediated, compiled. 18 Research material – Media texts and online sources . 22 Methodology – Social constructions and discursive readings. 24 Context and focus – Defining the object of study. 26 Research questions, aims and execution – On the work at hand. 28 I STARRING THE AUTHOR – IN THE SPOTLIGHT AND UNDERGROUND . 31 1. The author effect – Tracking down the source. .32 The author as the point of origin. 32 Authoring identities and celebrity signs. 33 Tracing back the Romantic impact . 35 Leading the way – The case of Björk . 37 Media texts and present-day myths. .39 Pieces of stardom. .40 Single authors with distinct features . 42 Between nature and technology . 45 The taskmaster and her crew.