19 Sep. 1995 Dr. Jon Baker
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supporting Information
Electronic Supplementary Material (ESI) for RSC Advances. This journal is © The Royal Society of Chemistry 2020 Supporting Information How to Select Ionic Liquids as Extracting Agent Systematically? Special Case Study for Extractive Denitrification Process Shurong Gaoa,b,c,*, Jiaxin Jina,b, Masroor Abroc, Ruozhen Songc, Miao Hed, Xiaochun Chenc,* a State Key Laboratory of Alternate Electrical Power System with Renewable Energy Sources, North China Electric Power University, Beijing, 102206, China b Research Center of Engineering Thermophysics, North China Electric Power University, Beijing, 102206, China c Beijing Key Laboratory of Membrane Science and Technology & College of Chemical Engineering, Beijing University of Chemical Technology, Beijing 100029, PR China d Office of Laboratory Safety Administration, Beijing University of Technology, Beijing 100124, China * Corresponding author, Tel./Fax: +86-10-6443-3570, E-mail: [email protected], [email protected] 1 COSMO-RS Computation COSMOtherm allows for simple and efficient processing of large numbers of compounds, i.e., a database of molecular COSMO files; e.g. the COSMObase database. COSMObase is a database of molecular COSMO files available from COSMOlogic GmbH & Co KG. Currently COSMObase consists of over 2000 compounds including a large number of industrial solvents plus a wide variety of common organic compounds. All compounds in COSMObase are indexed by their Chemical Abstracts / Registry Number (CAS/RN), by a trivial name and additionally by their sum formula and molecular weight, allowing a simple identification of the compounds. We obtained the anions and cations of different ILs and the molecular structure of typical N-compounds directly from the COSMObase database in this manuscript. -

GROMACS: Fast, Flexible, and Free
GROMACS: Fast, Flexible, and Free DAVID VAN DER SPOEL,1 ERIK LINDAHL,2 BERK HESS,3 GERRIT GROENHOF,4 ALAN E. MARK,4 HERMAN J. C. BERENDSEN4 1Department of Cell and Molecular Biology, Uppsala University, Husargatan 3, Box 596, S-75124 Uppsala, Sweden 2Stockholm Bioinformatics Center, SCFAB, Stockholm University, SE-10691 Stockholm, Sweden 3Max-Planck Institut fu¨r Polymerforschung, Ackermannweg 10, D-55128 Mainz, Germany 4Groningen Biomolecular Sciences and Biotechnology Institute, University of Groningen, Nijenborgh 4, NL-9747 AG Groningen, The Netherlands Received 12 February 2005; Accepted 18 March 2005 DOI 10.1002/jcc.20291 Published online in Wiley InterScience (www.interscience.wiley.com). Abstract: This article describes the software suite GROMACS (Groningen MAchine for Chemical Simulation) that was developed at the University of Groningen, The Netherlands, in the early 1990s. The software, written in ANSI C, originates from a parallel hardware project, and is well suited for parallelization on processor clusters. By careful optimization of neighbor searching and of inner loop performance, GROMACS is a very fast program for molecular dynamics simulation. It does not have a force field of its own, but is compatible with GROMOS, OPLS, AMBER, and ENCAD force fields. In addition, it can handle polarizable shell models and flexible constraints. The program is versatile, as force routines can be added by the user, tabulated functions can be specified, and analyses can be easily customized. Nonequilibrium dynamics and free energy determinations are incorporated. Interfaces with popular quantum-chemical packages (MOPAC, GAMES-UK, GAUSSIAN) are provided to perform mixed MM/QM simula- tions. The package includes about 100 utility and analysis programs. -

Starting SCF Calculations by Superposition of Atomic Densities
Starting SCF Calculations by Superposition of Atomic Densities J. H. VAN LENTHE,1 R. ZWAANS,1 H. J. J. VAN DAM,2 M. F. GUEST2 1Theoretical Chemistry Group (Associated with the Department of Organic Chemistry and Catalysis), Debye Institute, Utrecht University, Padualaan 8, 3584 CH Utrecht, The Netherlands 2CCLRC Daresbury Laboratory, Daresbury WA4 4AD, United Kingdom Received 5 July 2005; Accepted 20 December 2005 DOI 10.1002/jcc.20393 Published online in Wiley InterScience (www.interscience.wiley.com). Abstract: We describe the procedure to start an SCF calculation of the general type from a sum of atomic electron densities, as implemented in GAMESS-UK. Although the procedure is well known for closed-shell calculations and was already suggested when the Direct SCF procedure was proposed, the general procedure is less obvious. For instance, there is no need to converge the corresponding closed-shell Hartree–Fock calculation when dealing with an open-shell species. We describe the various choices and illustrate them with test calculations, showing that the procedure is easier, and on average better, than starting from a converged minimal basis calculation and much better than using a bare nucleus Hamiltonian. © 2006 Wiley Periodicals, Inc. J Comput Chem 27: 926–932, 2006 Key words: SCF calculations; atomic densities Introduction hrstuhl fur Theoretische Chemie, University of Kahrlsruhe, Tur- bomole; http://www.chem-bio.uni-karlsruhe.de/TheoChem/turbo- Any quantum chemical calculation requires properly defined one- mole/),12 GAMESS(US) (Gordon Research Group, GAMESS, electron orbitals. These orbitals are in general determined through http://www.msg.ameslab.gov/GAMESS/GAMESS.html, 2005),13 an iterative Hartree–Fock (HF) or Density Functional (DFT) pro- Spartan (Wavefunction Inc., SPARTAN: http://www.wavefun. -

Parameterizing a Novel Residue
University of Illinois at Urbana-Champaign Luthey-Schulten Group, Department of Chemistry Theoretical and Computational Biophysics Group Computational Biophysics Workshop Parameterizing a Novel Residue Rommie Amaro Brijeet Dhaliwal Zaida Luthey-Schulten Current Editors: Christopher Mayne Po-Chao Wen February 2012 CONTENTS 2 Contents 1 Biological Background and Chemical Mechanism 4 2 HisH System Setup 7 3 Testing out your new residue 9 4 The CHARMM Force Field 12 5 Developing Topology and Parameter Files 13 5.1 An Introduction to a CHARMM Topology File . 13 5.2 An Introduction to a CHARMM Parameter File . 16 5.3 Assigning Initial Values for Unknown Parameters . 18 5.4 A Closer Look at Dihedral Parameters . 18 6 Parameter generation using SPARTAN (Optional) 20 7 Minimization with new parameters 32 CONTENTS 3 Introduction Molecular dynamics (MD) simulations are a powerful scientific tool used to study a wide variety of systems in atomic detail. From a standard protein simulation, to the use of steered molecular dynamics (SMD), to modelling DNA-protein interactions, there are many useful applications. With the advent of massively parallel simulation programs such as NAMD2, the limits of computational anal- ysis are being pushed even further. Inevitably there comes a time in any molecular modelling scientist’s career when the need to simulate an entirely new molecule or ligand arises. The tech- nique of determining new force field parameters to describe these novel system components therefore becomes an invaluable skill. Determining the correct sys- tem parameters to use in conjunction with the chosen force field is only one important aspect of the process. -
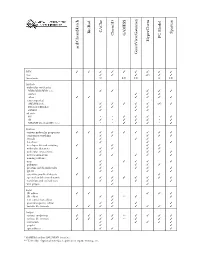
D:\Doc\Workshops\2005 Molecular Modeling\Notebook Pages\Software Comparison\Summary.Wpd
CAChe BioRad Spartan GAMESS Chem3D PC Model HyperChem acd/ChemSketch GaussView/Gaussian WIN TTTT T T T T T mac T T T (T) T T linux/unix U LU LU L LU Methods molecular mechanics MM2/MM3/MM+/etc. T T T T T Amber T T T other TT T T T T semi-empirical AM1/PM3/etc. T T T T T (T) T Extended Hückel T T T T ZINDO T T T ab initio HF * * T T T * T dft T * T T T * T MP2/MP4/G1/G2/CBS-?/etc. * * T T T * T Features various molecular properties T T T T T T T T T conformer searching T T T T T crystals T T T data base T T T developer kit and scripting T T T T molecular dynamics T T T T molecular interactions T T T T movies/animations T T T T T naming software T nmr T T T T T polymers T T T T proteins and biomolecules T T T T T QSAR T T T T scientific graphical objects T T spectral and thermodynamic T T T T T T T T transition and excited state T T T T T web plugin T T Input 2D editor T T T T T 3D editor T T ** T T text conversion editor T protein/sequence editor T T T T various file formats T T T T T T T T Output various renderings T T T T ** T T T T various file formats T T T T ** T T T animation T T T T T graphs T T spreadsheet T T T * GAMESS and/or GAUSSIAN interface ** Text only. -

Dmol Guide to Select a Dmol3 Task 1
DMOL3 GUIDE MATERIALS STUDIO 8.0 Copyright Notice ©2014 Dassault Systèmes. All rights reserved. 3DEXPERIENCE, the Compass icon and the 3DS logo, CATIA, SOLIDWORKS, ENOVIA, DELMIA, SIMULIA, GEOVIA, EXALEAD, 3D VIA, BIOVIA and NETVIBES are commercial trademarks or registered trademarks of Dassault Systèmes or its subsidiaries in the U.S. and/or other countries. All other trademarks are owned by their respective owners. Use of any Dassault Systèmes or its subsidiaries trademarks is subject to their express written approval. Acknowledgments and References To print photographs or files of computational results (figures and/or data) obtained using BIOVIA software, acknowledge the source in an appropriate format. For example: "Computational results obtained using software programs from Dassault Systèmes Biovia Corp.. The ab initio calculations were performed with the DMol3 program, and graphical displays generated with Materials Studio." BIOVIA may grant permission to republish or reprint its copyrighted materials. Requests should be submitted to BIOVIA Support, either through electronic mail to [email protected], or in writing to: BIOVIA Support 5005 Wateridge Vista Drive, San Diego, CA 92121 USA Contents DMol3 1 Setting up a molecular dynamics calculation20 Introduction 1 Choosing an ensemble 21 Further Information 1 Defining the time step 21 Tasks in DMol3 2 Defining the thermostat control 21 Energy 3 Constraints during dynamics 21 Setting up the calculation 3 Setting up a transition state calculation 22 Dynamics 4 Which method to use? -

Computational Studies on Carbohydrates: I. Density Functional Ab Initio Geometry Optimization on Maltose Conformations
Computational Studies on Carbohydrates: I. Density Functional Ab Initio Geometry Optimization on Maltose Conformations F. A. MOMANY, J. L. WILLETT Plant Polymer Research, National Center for Agricultural Utilization Research, USDA, Agricultural Research Service, 1815 N. University St., Peoria, Illinois 61604 Received 10 September 1999; accepted 10 May 2000 ABSTRACT: Ab initio geometry optimization was carried out on 10 selected conformations of maltose and two 2-methoxytetrahydropyran conformations using the density functional denoted B3LYP combined with two basis sets. The 6-31G∗ and 6-311CCG∗∗ basis sets make up the B3LYP/6-31G∗ and B3LYP/6-311CCG∗∗ procedures. Internal coordinates were fully relaxed, and structures were gradient optimized at both levels of theory. Ten conformations were studied at the B3LYP/6-31G∗ level, and five of these were continued with ∗∗ full gradient optimization at the B3LYP/6-311CCG level of theory. The details of the ab initio optimized geometries are presented here, with particular attention given to the positions of the atoms around the anomeric center and the effect of the particular anomer and hydrogen bonding pattern on the maltose ring structures and relative conformational energies. The size and complexity of the hydrogen-bonding network prevented a rigorous search of conformational space by ab initio calculations. However, using empirical force fields, low-energy conformers of maltose were found that were subsequently gradient optimized at the two ab initio levels of theory. Three classes of conformations were studied, as defined by the clockwise or counterclockwise direction of the hydroxyl groups, or a flipped conformer in which the -dihedral is rotated by ∼180◦.Different combinations of ! side-chain rotations gave energy differences of more than 6 kcal/mol above the lowest energy structure found. -

Jaguar 5.5 User Manual Copyright © 2003 Schrödinger, L.L.C
Jaguar 5.5 User Manual Copyright © 2003 Schrödinger, L.L.C. All rights reserved. Schrödinger, FirstDiscovery, Glide, Impact, Jaguar, Liaison, LigPrep, Maestro, Prime, QSite, and QikProp are trademarks of Schrödinger, L.L.C. MacroModel is a registered trademark of Schrödinger, L.L.C. To the maximum extent permitted by applicable law, this publication is provided “as is” without warranty of any kind. This publication may contain trademarks of other companies. October 2003 Contents Chapter 1: Introduction.......................................................................................1 1.1 Conventions Used in This Manual.......................................................................2 1.2 Citing Jaguar in Publications ...............................................................................3 Chapter 2: The Maestro Graphical User Interface...........................................5 2.1 Starting Maestro...................................................................................................5 2.2 The Maestro Main Window .................................................................................7 2.3 Maestro Projects ..................................................................................................7 2.4 Building a Structure.............................................................................................9 2.5 Atom Selection ..................................................................................................10 2.6 Toolbar Controls ................................................................................................11 -

Visualization and Analysis of Petascale Molecular Simulations with VMD John E
S4410: Visualization and Analysis of Petascale Molecular Simulations with VMD John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of Illinois at Urbana-Champaign http://www.ks.uiuc.edu/Research/gpu/ S4410, GPU Technology Conference 15:30-16:20, Room LL21E, San Jose Convention Center, San Jose, CA, Tuesday March 25, 2014 Biomedical Technology Research Center for Macromolecular Modeling and Bioinformatics Beckman Institute, University of Illinois at Urbana-Champaign - www.ks.uiuc.edu VMD – “Visual Molecular Dynamics” • Visualization and analysis of: – molecular dynamics simulations – particle systems and whole cells – cryoEM densities, volumetric data – quantum chemistry calculations – sequence information • User extensible w/ scripting and plugins Whole Cell Simulation MD Simulations • http://www.ks.uiuc.edu/Research/vmd/ CryoEM, Cellular Biomedical Technology Research Center for Macromolecular Modeling and Bioinformatics SequenceBeckman Data Institute, University of Illinois at QuantumUrbana-Champaign Chemistry - www.ks.uiuc.edu Tomography Goal: A Computational Microscope Study the molecular machines in living cells Ribosome: target for antibiotics Poliovirus Biomedical Technology Research Center for Macromolecular Modeling and Bioinformatics Beckman Institute, University of Illinois at Urbana-Champaign - www.ks.uiuc.edu VMD Interoperability Serves Many Communities • VMD 1.9.1 user statistics: – 74,933 unique registered users from all over the world • Uniquely interoperable -

The Molpro Quantum Chemistry Package
The Molpro Quantum Chemistry package Hans-Joachim Werner,1, a) Peter J. Knowles,2, b) Frederick R. Manby,3, c) Joshua A. Black,1, d) Klaus Doll,1, e) Andreas Heßelmann,1, f) Daniel Kats,4, g) Andreas K¨ohn,1, h) Tatiana Korona,5, i) David A. Kreplin,1, j) Qianli Ma,1, k) Thomas F. Miller, III,6, l) Alexander Mitrushchenkov,7, m) Kirk A. Peterson,8, n) Iakov Polyak,2, o) 1, p) 2, q) Guntram Rauhut, and Marat Sibaev 1)Institut f¨ur Theoretische Chemie, Universit¨at Stuttgart, Pfaffenwaldring 55, 70569 Stuttgart, Germany 2)School of Chemistry, Cardiff University, Main Building, Park Place, Cardiff CF10 3AT, United Kingdom 3)School of Chemistry, University of Bristol, Cantock’s Close, Bristol BS8 1TS, United Kingdom 4)Max-Planck Institute for Solid State Research, Heisenbergstraße 1, 70569 Stuttgart, Germany 5)Faculty of Chemistry, University of Warsaw, L. Pasteura 1 St., 02-093 Warsaw, Poland 6)Division of Chemistry and Chemical Engineering, California Institute of Technology, Pasadena, California 91125, United States 7)MSME, Univ Gustave Eiffel, UPEC, CNRS, F-77454, Marne-la- Vall´ee, France 8)Washington State University, Department of Chemistry, Pullman, WA 99164-4630 1 Molpro is a general purpose quantum chemistry software package with a long devel- opment history. It was originally focused on accurate wavefunction calculations for small molecules, but now has many additional distinctive capabilities that include, inter alia, local correlation approximations combined with explicit correlation, highly efficient implementations of single-reference correlation methods, robust and efficient multireference methods for large molecules, projection embedding and anharmonic vibrational spectra. -
Massive-Parallel Implementation of the Resolution-Of-Identity Coupled
Article Cite This: J. Chem. Theory Comput. 2019, 15, 4721−4734 pubs.acs.org/JCTC Massive-Parallel Implementation of the Resolution-of-Identity Coupled-Cluster Approaches in the Numeric Atom-Centered Orbital Framework for Molecular Systems † § † † ‡ § § Tonghao Shen, , Zhenyu Zhu, Igor Ying Zhang,*, , , and Matthias Scheffler † Department of Chemistry, Fudan University, Shanghai 200433, China ‡ Shanghai Key Laboratory of Molecular Catalysis and Innovative Materials, MOE Key Laboratory of Computational Physical Science, Fudan University, Shanghai 200433, China § Fritz-Haber-Institut der Max-Planck-Gesellschaft, Faradayweg 4-6, 14195 Berlin, Germany *S Supporting Information ABSTRACT: We present a massive-parallel implementation of the resolution of identity (RI) coupled-cluster approach that includes single, double, and perturbatively triple excitations, namely, RI-CCSD(T), in the FHI-aims package for molecular systems. A domain-based distributed-memory algorithm in the MPI/OpenMP hybrid framework has been designed to effectively utilize the memory bandwidth and significantly minimize the interconnect communication, particularly for the tensor contraction in the evaluation of the particle−particle ladder term. Our implementation features a rigorous avoidance of the on- the-fly disk storage and excellent strong scaling of up to 10 000 and more cores. Taking a set of molecules with different sizes, we demonstrate that the parallel performance of our CCSD(T) code is competitive with the CC implementations in state-of- the-art high-performance-computing computational chemistry packages. We also demonstrate that the numerical error due to the use of RI approximation in our RI-CCSD(T) method is negligibly small. Together with the correlation-consistent numeric atom-centered orbital (NAO) basis sets, NAO-VCC-nZ, the method is applied to produce accurate theoretical reference data for 22 bio-oriented weak interactions (S22), 11 conformational energies of gaseous cysteine conformers (CYCONF), and 32 Downloaded via FRITZ HABER INST DER MPI on January 8, 2021 at 22:13:06 (UTC). -

Lawrence Berkeley National Laboratory Recent Work
Lawrence Berkeley National Laboratory Recent Work Title From NWChem to NWChemEx: Evolving with the Computational Chemistry Landscape. Permalink https://escholarship.org/uc/item/4sm897jh Journal Chemical reviews, 121(8) ISSN 0009-2665 Authors Kowalski, Karol Bair, Raymond Bauman, Nicholas P et al. Publication Date 2021-04-01 DOI 10.1021/acs.chemrev.0c00998 Peer reviewed eScholarship.org Powered by the California Digital Library University of California From NWChem to NWChemEx: Evolving with the computational chemistry landscape Karol Kowalski,y Raymond Bair,z Nicholas P. Bauman,y Jeffery S. Boschen,{ Eric J. Bylaska,y Jeff Daily,y Wibe A. de Jong,x Thom Dunning, Jr,y Niranjan Govind,y Robert J. Harrison,k Murat Keçeli,z Kristopher Keipert,? Sriram Krishnamoorthy,y Suraj Kumar,y Erdal Mutlu,y Bruce Palmer,y Ajay Panyala,y Bo Peng,y Ryan M. Richard,{ T. P. Straatsma,# Peter Sushko,y Edward F. Valeev,@ Marat Valiev,y Hubertus J. J. van Dam,4 Jonathan M. Waldrop,{ David B. Williams-Young,x Chao Yang,x Marcin Zalewski,y and Theresa L. Windus*,r yPacific Northwest National Laboratory, Richland, WA 99352 zArgonne National Laboratory, Lemont, IL 60439 {Ames Laboratory, Ames, IA 50011 xLawrence Berkeley National Laboratory, Berkeley, 94720 kInstitute for Advanced Computational Science, Stony Brook University, Stony Brook, NY 11794 ?NVIDIA Inc, previously Argonne National Laboratory, Lemont, IL 60439 #National Center for Computational Sciences, Oak Ridge National Laboratory, Oak Ridge, TN 37831-6373 @Department of Chemistry, Virginia Tech, Blacksburg, VA 24061 4Brookhaven National Laboratory, Upton, NY 11973 rDepartment of Chemistry, Iowa State University and Ames Laboratory, Ames, IA 50011 E-mail: [email protected] 1 Abstract Since the advent of the first computers, chemists have been at the forefront of using computers to understand and solve complex chemical problems.