Louisiana State University Nasalance Protocol Standardization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UC Berkeley Dissertations, Department of Linguistics
UC Berkeley Dissertations, Department of Linguistics Title The Aeroacoustics of Nasalized Fricatives Permalink https://escholarship.org/uc/item/00h9g9gg Author Shosted, Ryan K Publication Date 2006 eScholarship.org Powered by the California Digital Library University of California The Aeroacoustics of Nasalized Fricatives by Ryan Keith Shosted B.A. (Brigham Young University) 2000 M.A. (University of California, Berkeley) 2003 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the GRADUATE DIVISION of the UNIVERSITY OF CALIFORNIA, BERKELEY Committee in charge: John J. Ohala, Chair Keith Johnson Milton M. Azevedo Fall 2006 The dissertation of Ryan Keith Shosted is approved: Chair Date Date Date University of California, Berkeley Fall 2006 The Aeroacoustics of Nasalized Fricatives Copyright 2006 by Ryan Keith Shosted 1 Abstract The Aeroacoustics of Nasalized Fricatives by Ryan Keith Shosted Doctor of Philosophy in Linguistics University of California, Berkeley John J. Ohala, Chair Understanding the relationship of aerodynamic laws to the unique geometry of the hu- man vocal tract allows us to make phonological and typological predictions about speech sounds typified by particular aerodynamic regimes. For example, some have argued that the realization of nasalized fricatives is improbable because fricatives and nasals have an- tagonistic aerodynamic specifications. Fricatives require high pressure behind the suprala- ryngeal constriction as a precondition for high particle velocity. Nasalization, on the other hand, vents back pressure by allowing air to escape through the velopharyngeal orifice. This implies that an open velopharyngeal port will reduce oral particle velocity, thereby potentially extinguishing frication. By using a mechanical model of the vocal tract and spoken fricatives that have undergone coarticulatory nasalization, it is shown that nasal- ization must alter the spectral characteristics of fricatives, e.g. -

Velopharyngeal Insufficiency in Children
Open Access Austin Journal of Otolaryngology A Austin Full Text Article Publishing Group Review Article Velopharyngeal Insufficiency in Children Abdel-Aziz M* Department of Otolaryngology, Cairo University, Egypt Abstract *Corresponding author: Mosaad Abdel-Aziz, Velopharyngeal insufficiency (VPI) is the incomplete closure of the Department of Otolaryngology, Cairo University, 2 el- velopharyngeal valve during articulation and may be during feeding. The patients salam st., King Faisal, Above El-baraka bank, Giza, Cairo, presented with hypernasal speech which results in difficult communication with Egypt its negative effects on the social life of the family. The problem has many causes Received: August 21, 2014; Accepted: September 07, that include structural defects either in palatal or in pharyngeal muscles. For 2014; Published: October 10, 2014 better understanding of the underlying cause, good anatomical knowledge should be acquainted. Assessment of patients includes otolaryngologic examination, auditory perceptual assessment, nasometric assessment, and radiologic evaluation. However, flexible nasopharyngoscopy is very important to detect the degree and type of velopharyngeal closure pattern. The condition should be managed through a team approach that includes an otolaryngologist, a speech and language pathologist, an audiologist, a radiologist, an orthodontist, a pediatrician, and a psychologist. Speech therapy can be used for patients with small velopharyngeal gap and in postoperative patients where functional residual VPI is present. Orthodontic treatment with palatal obturator or speech aid prostheses is used for children with VPI who are not surgical candidates for palatal reconstruction, or who have had less than optimal surgical results. Surgical intervention is indicated for patients with structural defects, it is either palatal or pharyngeal procedure that aiming for strengthening and/or narrowing of the velopharyngeal valve. -

Cleft Palate/Lip
CLEFT PALATE/LIP WHAT IS A CLEFT? A cleft is a separation in the skin, tissue lining of the mouth, muscle, and bone that is normally fused together; however, no structures are missing. Clefts can be either unilateral (one side) or bilateral (both sides) and may include the lip, soft palate and/or hard palate or any of the structures in isolation. TYPES OF CLEFTS Cleft Lip – separation in the lip and may include the bottom of the nose Cleft Palate – separation in the hard palate and/or soft palate Submucous Cleft – separation in the muscle of the soft palate with the tissue lining of the mouth intact. Often, it is not easily viewed. WHEN DID CLEFTING HAPPEN? During the 4th week of fetal development, the primary palate (line from nostril to upper lip and mucosa behind upper teeth) fuse together. By the 8th week, the tongue drops in the mouth and the secondary palate (hard palate and soft palate) fuse together with the nasal septum. By the 12th week, if the process is not complete, a cleft (separation) will develop. WHAT CAUSED MY CHILD’S CLEFT? The exact cause is not known but theories include: Low intake of Folic Acid (Vitamin B) Large intake of Vitamin A Genetic disposition Syndromes or Sequences (Pierre Robin, Treacher Collins) Drugs, alcohol, medication, and smoking CLEFT PALATE MANAGEMENT You and your child will be in contact with many different healthcare professionals who need to work together. Every case is individualized, therefore your child will need a thorough assessment to the appropriate treatment plan. -

Section V. Resonance and Phonation SAMUEL G. FLETCHER, Ph.D. (CHAIRMAN) Despite an Ever Widening Scope of Topics in Cleft Palate
Section V. Resonance and Phonation SAMUEL G. FLETCHER, Ph.D. (CHAIRMAN) Despite an ever widening scope of topics use of instrumentation and procedures to in cleft palate research, progress in reha- increase diagnostic and management pre- bilitation is still largely defined by the ex- cision, and (c) systematic evaluation of tent to which speech disorders exist, may «speech treatment restults. The importance be prevented, or are eradicated (Bauer, of multistructural dynamic impairment 1972; Randal, 1974; Kraus, VanDemark, - has also been mentioned frequently but and Tharp, 1975; Wilder and Baken, has received little direct attention. 1975). In the speech section of the previous Palatopharyngeal Disturbance Without state-of-the-art review (Spriestersbach et Overt Cleft al., 1973) major attention was given to Identification of palatopharyngeal dis- three broad aspects of speech research: 1) turbance in the absence of overt cleft disturbances in anatomical and physiologi- serves to highlight a variety of disorders cal aspects of speaking; 2) assessment of with potentially common speech symptom- special speech characteristics and disor- atology. Calnan (1976) recently re-pre- ders attributable to maxillofacial anomaly; sented his system for classifying such dis- and 3) therapeutic processes and proce- turbances. Minami and associates (1975) dures for speech habilitation. A number of proposed an expanded etiological classifi- issues identified in the earlier review re- cation system in which nearly fifty types of main unresolved. For example, informa- disability known to affect palatopharyn- tion is still unavailable concerning a variety geal structure and function are itemized. of essential components of velopharyngeal They also reviewed observations from 188 (V-P) movement in speakers with V-P in- patients and attempted to differentiate eti- sufficiency. -

Treatment Options for Better Speech
TREATMENT OPTIONS FOR BETTER SPEECH TREATMENT OPTIONS FOR BETTER SPEECH Major Contributor to the First Edition: David Jones, PhD, Speech-Language Pathology Edited by the 2004 Publications Committee: Cassandra Aspinall, MSW, Social Work John W. Canady, MD, Plastic & Reconstructive Surgery David Jones, PhD, Speech-Language Pathology Alice Kahn, PhD, Speech-Language Pathology Kathleen Kapp-Simon, PhD, Psychology Karlind Moller, PhD, Speech-Language Pathology Gary Neiman, PhD, Speech-Language Pathology Francis Papay, MD, Plastic Surgery David Reisberg, DDS, Prosthodontics Maureen Cassidy Riski, AuD, Audiology Carol Ritter, RN, BSN, Nursing Marlene Salas-Provance, PhD, Speech-Language Pathology James Sidman, MD, Otolaryngology Timothy Turvey, DDS, Oral/Maxillofacial Surgery Craig Vander Kolk, MD, Plastic Surgery Leslie Will, DMD, Orthodontics Lisa Young, MS, CCC-SLP, Speech-Language Pathology Figures 1, 2 and 5 are reproduced with the kind permission of University of Minnesota Press, Minneapolis, A Parent’s Guide to Cleft Lip and Palate, Karlind Moller, Clark Starr and Sylvia Johnson, eds., 1990. Figure 3 is reproduced with the kind permission of Millard DR: Cleft Craft: The Evolution of its Surgeries. Volume 3: Alveolar and Palatal Deformities. Boston: Little, Brown, 1980, pp. 653-654 Figure 4 is an original drawing by David Low, MD. Copyright ©?2004 by American Cleft Palate-Craniofacial Association. All rights reserved. This publi-cation is protected by Copyright. Permission should be obtained from the American Cleft Palate-Craniofacial Association -

Speech Results and Associated Findings Following Pharyngeal Flap Surgery in an Established State Craniofacial Disorders Program
University of Montana ScholarWorks at University of Montana Graduate Student Theses, Dissertations, & Professional Papers Graduate School 1985 Speech results and associated findings following pharyngeal flap surgery in an established state craniofacial disorders program Maureen Patricia McMahon The University of Montana Follow this and additional works at: https://scholarworks.umt.edu/etd Let us know how access to this document benefits ou.y Recommended Citation McMahon, Maureen Patricia, "Speech results and associated findings following pharyngeal flap surgery in an established state craniofacial disorders program" (1985). Graduate Student Theses, Dissertations, & Professional Papers. 3639. https://scholarworks.umt.edu/etd/3639 This Professional Paper is brought to you for free and open access by the Graduate School at ScholarWorks at University of Montana. It has been accepted for inclusion in Graduate Student Theses, Dissertations, & Professional Papers by an authorized administrator of ScholarWorks at University of Montana. For more information, please contact [email protected]. COPYRIGHT ACT OF 1976 THIS IS AN UNPUBLISHED MANUSCRIPT IN WHICH COPYRIGHT SUB SISTS. ANY FURTHER REPRINTING OF ITS CONTENTS MUST BE APPROVED BY THE AUTHOR. MANSFIELD LIBRARY UNIVERSITY OF MONTANA DATE : 19 8 5 Speech Results and Associated Findings Following Pharyngeal Flap Surgery in an Established State Craniofacial Disorders Program by Maureen Patricia McMahon B.A., Carroll College, 1982 Presented in Partial Fulfillment of the Requirements for the Degree of Master of Communication Sciences and Disorders UNIVERSITY OF MONTANA 1985 Approved by: ^ Chairman, fioard ot''examiners Dean, Graduate School / Date UMI Number: EP34664 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent on the quality of the copy submitted. -

Robust Estimation of Hypernasality in Dysarthria with Acoustic Model
1 Robust Estimation of Hypernasality in Dysarthria with Acoustic Model Likelihood Features Michael Saxon1, Ayush Tripathi2, Yishan Jiao3, Julie Liss3, and Visar Berisha1;3 1School of Electrical, Computer, and Energy Engineering, Arizona State University 2Department of Electrical and Electronics Engineering, Visvesvaraya National Institute of Technology 3College of Health Solutions, Arizona State University Abstract—Hypernasality is a common characteristic symp- work we present automated metrics for hypernasality scoring tom across many motor-speech disorders. For voiced sounds, that are robust to disease- and speaker-specific confounders. hypernasality introduces an additional resonance in the lower Clinician perceptual assessment is the gold-standard tech- frequencies and, for unvoiced sounds, there is reduced articu- latory precision due to air escaping through the nasal cavity. nique for assessing hypernasality [8]. However, this method However, the acoustic manifestation of these symptoms is highly has been shown to be susceptible to a wide variety of er- variable, making hypernasality estimation very challenging, both ror sources, including stimulus type, phonetic context, vocal for human specialists and automated systems. Previous work in quality, articulation patterns, and previous listener experience this area relies on either engineered features based on statistical [9]. Additionally, these perceptual metrics have been shown signal processing or machine learning models trained on clinical ratings. Engineered features often fail to capture the complex to erroneously overestimate severity on high vowels when acoustic patterns associated with hypernasality, whereas metrics compared with low vowels [10], and vary based on broader based on machine learning are prone to overfitting to the phonetic context [11]. Although these difficulties may be small disease-specific speech datasets on which they are trained. -

Velopharyngeal Sphincter Pathophysiologic Aspects in the in Cleft Palate
Artigo de Revisão Velopharyngeal Sphincter Pathophysiologic Aspects in the in Cleft Palate Daniela Preto da Silva*, Sílvia Dornelles**, Lauren Medeiros Paniagua***, Sady Selaimen da Costa****, Marcus Vinicius Martins Collares*****. * Otorhinolaryngologist medical doctor. In course for Master’s Degree in the Program for Post-Graduation in Medicine: Surgery of Universidade Federal do Rio Grande do Sul. ** Phonoaudiologist. In Course for Doctor’s Degree of Post-Graduation in Medical Sciences: Paediatrics of Universidade Federal do Rio Grande do Sul. ** Phonoaudiologist. In Course for Master’s Degree of Post-Graduation in Medical Sciences: Paediatrics of Universidade Federal do Rio Grande do Sul. **** Otorhinolaryngologist Medical Doctor. Associate Professor of Otorhinolaryngology Discipline of the Medicine College of Universidade Federal do Rio Grande do Sul. ***** Doctor, Plastic Surgeon. Assistant Professor of Plastic Surgery Discipline of the Medicine College of Universidade Federal do Rio Grande do Sul. Head of the Craniomaxillofacial Surgery Service of Hospital de Clínicas de Porto Alegre. Institution: Universidade Federal do Rio Grande do Sul, Hospital de Clínicas de Porto Alegre, Services of Otorhinolaryngology and Craniomaxillofacial Surgery, Otorhinolaryngology and Cleft Palate Ambulatory Porto Alegre / RS - Brazil. Mail address: Daniela Preto da Silva - Avenida Soledade, 569 - Conj. 805 e 806 - Torre Beta - Porto Alegre / RS - Brazil - Zip code: 90470-340 - Phone: (+55 51) 3378- 9997 - E-mail: [email protected] Article received on December 04, 2007. Article approved on August 23, 2008. SUMMARY Introduction: Cleft lip and palate are common congenital abnormalities with typical functional disorders on speech, deglutition and middle ear function. Objective: This article reviews functional labiopalatine disorders through a pathophysiological view. Method: We performed a literature search on line, as well as books and periodicals related to velopharyngeal sphincter. -

Evaluation of Nasal Speech a Study of Assessments by Speech-Language Pathologists, Untrained Listeners and Nasometry
UMEÅ UNIVERSITY MEDICAL DISSERTATION New series No 1185, ISBN 978-91-7264-678-0, ISSN 0346-6612-1222 Department of Clinical Sciences, Speech and Language Pathology, Umeå University SE-901 87 Umeå, Sweden Evaluation of nasal speech A study of assessments by speech-language pathologists, untrained listeners and nasometry Karin Brunnegård Umeå 2008 Copyright © 2008 Karin Brunnegård Dept of Clinical Sciences, Speech and Language Pathology Umeå University SE-901 87 Sweden Photo on cover: Carina Kristiansson Printed by Print & Media, Umeå, Sweden - 2 - TABLE of CONTENTS ABSTRACT -5- POPULÄRVETENSKAPLIG SAMMANFATTNING -7- LIST of ARTICLES -9- WORD LIST/ORDLISTA (English – Swedish) -10- PREFACE -11- INTRODUCTION -12- BACKGROUND -12- Normal speech production Resonance disorders and velopharyngeal impairment Resonance disorders in cleft lip and palate Resonance disorders in other groups Auditory perceptual assessments Perceptual assessment of cleft lip and palate and VPI Reliability of perceptual assessment of nasality Validity of perceptual assessments of nasality Untrained listeners in speech assessments Instrumental assessment The Nasometer™ - an acoustic instrument AIMS -21- METHODS -22- Participants Speakers Listeners Assessment materials and instrumentation Speech stimuli Audio-recordings of perceptual speech stimuli Assessment form for expert and non-expert SLPs Assessment form for untrained listeners Experimental procedures Auditory perceptual assessment Measurement of nasalance Data analysis Reliability of auditory perceptual ratings for -

Original Article Original Article Pediatric/Craniofacial Xxx Congenital Palatal Fistula Associated with Xxx Submucous Cleft Palate
Mahalakshmi ORIGINAL ARTICLE Original Article Pediatric/Craniofacial xxx Congenital Palatal Fistula Associated with xxx Submucous Cleft Palate 2016 Mekonen Eshete, MD* Liliana Camison, MD† Background: Although cleft lip and cleft palate are among the most com- mon congenital malformations, the presence of an isolated congenital Plastic & Reconstructive Surgery-Global Open Fikre Abate, MD‡ Taye Hailu, MD‡ palatal fistula along with a submucous cleft is very rare. This appears as Yohannes Demissie, MD* an oval-shaped, full-thickness fenestration in the palatal midline that does 4 Ibrahim Mohammed, MD* not fully extend anteriorly or posteriorly, accompanied by the findings of a Azeez Butali, DDS, PhD§ submucous cleft. Because of the uncommon nature of this entity, there is H. Wolfgang Losken, MD¶ controversy about its etiology, diagnosis, and management. 2 Alexander M. Spiess, MD† Methods: Two cases of children with congenital palatal fistulae and a sub- mucous cleft palate are presented who were treated in different settings by different surgeons. Cases are discussed along with a thorough review of the Congenital Palate Fistula available literature. Results: Patient 1 presented at 4 years of age with “a hole in the palate” Eshete et al. since birth and abnormal speech. His palatal fistula and submucous cleft were repaired with a modified von Langenbeck technique in Ethiopia. At a 2-year follow-up, the palate remained closed, but hypernasal speech per- sisted. Patient 2 was a 1-year-old presenting with failure to thrive and nasal regurgitation, who underwent a Furlow palatoplasty in the United States with good immediate results. She was unfortunately lost to follow-up. -

Adenotonsillectomy Complications
ADENOTONSILLECTOMY COMPLICATIONS ELENA RIZZO RIERA R1 ORL HUSE PALATINE TONSILS • Component of Waldeyer’s tonsillar ring. Consists of • Lingual tonsil • Palatine tonsils (2) • Adenoids (NF tonsil) • Lymphoid tissue on the posterior pharyngeal wall PALATINE TONSILS • The PT are the largest component of the ring. • Defense against infection. Development of the immune system. • PT grow throughout childhood until the age of 11 years. • Decrease spontaneously. • Placed in the space between the palatopharyngeal and palatoglossus muscles. • Hyperplasia of the tonsilsà breathing and swallowing problems. PALATINE TONSILS SPECIALIZED HISTOLOGIC STRUCTURE: • Matrix: lymphoid tissue with crypts. • Cells organized in lymphoid follicles. • Adherent to a capsuleà limited inflammation. • Stratified squamous epithelium. ADENOIDS • Median mass of mucosa situated in the posterior wall of nasopharinx. • Composed of vertical ridges of lymphoid tissue separated by deep clefts. • Pseudostratified ciliated columnar epithelium. ADENOIDS • Prominent in children up to 6 years of age. • Gradually undergo atrophy. • Hyperplasia of the adenoids: § Nasal obstruction § Epistaxis § Voice change § Tubal obstruction § Otitis media TONSILS AND ADENOIDS BLOOD SUPPLY • Tonsillar branch of the facial artery is the main supply of the entire tonsil. • Facial artery: • Tonsillar art • Ascending palatine art • Lingual art • dorsal lingual branch • Internal maxillary art • Desceding palatine • Greater palatine • Ascending pharyngeal (ECA) • Adenoids: • Ascending palatine, • Ascending -
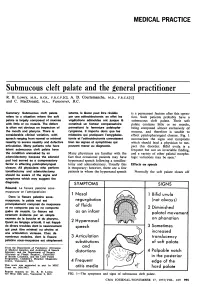
Submucous Cleft Palate and the General Practitioner R
MEDICAL PRACTICE Submucous cleft palate and the general practitioner R. B. Lowry, m.b., b.ch., f.r.c.p.[c], A. D. Courtemanche, m.d., f.r.c.s.[c] and C. MacDonald, m.a., Vancouver, B.C. Summary: Submucous cleft palate latente, la lesion peut etre revelee is a permanent feature after this opera¬ refers to a situation where the soft par une adenoidectomie: en effet les tion. Such patients probably have a palate is largely composed of mucosa vegetations adenoides ont jusque la submucous cleft palate. Their soft with little or no muscle. The defect constitue un facteur compensatoire palate contains little or no muscle, is often not obvious on inspection of permettant la fermeture palatopha- being composed almost exclusively of the mouth and pharynx. There is ryngienne. II importe done que les mucosa, and therefore is unable to considerable clinical variation, with medecins qui pratiquent I'amygdalec- effect palatopharyngeal closure. Fig. 1 speech ranging from normal or minimal tomie et I'adenoidectomie connaissent summarizes the signs and symptoms nasality to severe nasality and defective bien les signes et symptdmes qui which should lead a physician to sus- articulation. Many patients who have peuvent mener au diagnostic. pect this disorder. Bifid uvula is a latent submucous cleft palate have frequent but not an invariable finding, the condition unmasked by an Many physicians are familiar with the and a variety of other palatal morpho- adenoidectomy because the adenoid fact that occasional patients may have logic variations may be seen.1 pad had served as a compensatory hypernasal speech following a tonsillec¬ factor in effecting palatopharyngeal tomy and adenoidectomy.