Integrating Planning and Learning: the PRODIGY Architecture 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Global and Country-Specific Mainstreaminess Measures: Definitions, Analysis, and Usage for Improving Personalized Music Recommendation Systems
RESEARCH ARTICLE Global and country-specific mainstreaminess measures: Definitions, analysis, and usage for improving personalized music recommendation systems ☯ ☯ Christine BauerID *, Markus Schedl Institute of Computational Perception, Johannes Kepler University Linz, Linz, Austria a1111111111 ☯ These authors contributed equally to this work. a1111111111 * [email protected] a1111111111 a1111111111 a1111111111 Abstract Relevance OPEN ACCESS Popularity-based approaches are widely adopted in music recommendation systems, both Citation: Bauer C, Schedl M (2019) Global and in industry and research. These approaches recommend to the target user what is currently country-specific mainstreaminess measures: popular among all users of the system. However, as the popularity distribution of music Definitions, analysis, and usage for improving items typically is a long-tail distribution, popularity-based approaches to music recommen- personalized music recommendation systems. PLoS ONE 14(6): e0217389. https://doi.org/ dation fall short in satisfying listeners that have specialized music preferences far away from 10.1371/journal.pone.0217389 the global music mainstream. Addressing this gap, the contribution of this article is three- Editor: Chi Ho Yeung, Education University of Hong fold. Kong, CHINA Received: August 28, 2018 Definition of mainstreaminess measures Accepted: May 12, 2019 First, we provide several quantitative measures describing the proximity of a user's music preference to the music mainstream. Assuming that there is a difference between the global Published: June 7, 2019 music mainstream and a country-specific one, we define the measures at two levels: relating Copyright: © 2019 Bauer, Schedl. This is an open a listener's music preferences to the global music preferences of all users, or relating them access article distributed under the terms of the Creative Commons Attribution License, which to music preferences of the user's country. -

At the Jericho Tavern on Saturday NIGHTSHIFT PHOTOGRAPHER 10Th November
[email protected] nightshift.oxfordmusic.net Free every month NIGHTSHIFT Issue 207 October Oxford’s Music Magazine 2012 Alphabet Backwards photo: Jenny Hardcore photo: Jenny Hardcore Go pop! NIGHTSHIFT: PO Box 312, Kidlington, OX5 1ZU. Phone: 01865 372255 NEWS Nightshift: PO Box 312, Kidlington, OX5 1ZU Phone: 01865 372255 email: [email protected] Online: nightshift.oxfordmusic.net DAMO SUZUKI is set to headline The album is available to download this year’s Audioscope festival. The for a bargain £5 at legendary former Can singer will www.musicforagoodhome.com. play a set with The ODC Drumline at the Jericho Tavern on Saturday NIGHTSHIFT PHOTOGRAPHER 10th November. Damo first headlined Johnny Moto officially launches his Audioscope back in 2003 and has new photo exhibition at the Jericho SUPERGRASS will receive a special Performing Rights Society Heritage made occasional return visits to Tavern with a gig at the same venue Award this month. The band, who formed in 1993, will receive the award Oxford since, including a spectacular this month. at The Jericho Tavern, the legendary venue where they signed their record set at Truck Festival in 2009 backed Johnny has been taking photos of deal back in 1994 before going on to release six studio albums and a string by an all-star cast of Oxfordshire local gigs for over 25 years now, of hit singles, helping to put the Oxford music scene on the world map in the musicians. capturing many of the best local and process. Joining Suzuki at Audioscope, which touring acts to pass through the city Gaz Coombes, Mick Quinn and Danny Goffey will receive the award at the raises money for homeless charity in that time and a remains a familiar Tavern on October 3rd. -

Martinlogan Prodigy Manual
P RODIGYTM user’s manual c l s e l e c t r o s t a t i c M ARTIN L OGAN CONTENTS Contents . .2 Dispersion Interactions . .14 Installation in Brief . .3 Controlled Horizontal Dispersion Assembly . .4 Controlled Vertical Dispersion Electrostatic Panel Three Major Types of Dispersion Front Grill Cloth Home Theater . .16 Rear Grill Cloth Electrostatic Advantages . .17 Introduction . .6 Full Range Operation Operation . .7 MartinLogan Exclusives . .19 AC Power Connection Curvilinear Line Source Signal Connection ForceForward Bass Alignment Break-In Vapor Deposited Film Jumper Clips Transducer Integrity Single-Wire Connection Electrostatic Loudspeaker History . .20 Bi-Wire Connection Frequently Asked Questions . .22 Passive Bi-Amplification Troubleshooting . .24 Bass Control Switch General Information . .25 Placement . .10 Specifications Listening Position Warranty and Registration The Wall Behind the Listener Service The Wall Behind the Speakers Glossary of Audio Terms . .26 The Side Walls Experimentation Final Placement The Extra “Tweak” Enjoy Yourself Room Acoustics . .12 Your Room Terminology Rules of Thumb Dipolar Speakers and Your Room Solid Footing 2 Contents INSTALLATION IN BRIEF We know you are eager to hear your new Prodigy loud- Step 1: Unpacking and Assembly speakers, so this section is provided to allow fast and easy Remove your new Prodigy speakers from their packing and set up. Once you have them operational, please take the time assemble them (pages 4-5) to read, in depth, the rest of the information in this manual. It will give you perspective on how to attain the greatest Step 2: Placement possible performance from this most exacting transducer. Place each Prodigy at least two feet from any wall and angle them slightly toward your listening area. -

Jonny L 2 of Us EP Mp3, Flac, Wma
Jonny L 2 Of Us EP mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Electronic Album: 2 Of Us EP Country: UK Released: 1996 Style: Drum n Bass MP3 version RAR size: 1728 mb FLAC version RAR size: 1905 mb WMA version RAR size: 1816 mb Rating: 4.2 Votes: 200 Other Formats: TTA MP1 AC3 FLAC AUD VOX MOD Tracklist Hide Credits A 2 Of Us 4:48 B1 Tychonic Cycle 6:50 B2 Strange Nature 7:34 2 Of Us (Photek Remix) C 5:32 Remix, Producer [Additional Production] – Rupert Parkes D1 Underwater Communication 6:33 D2 Symbiosis 6:41 Companies, etc. Distributed By – Warners Phonographic Copyright (p) – XL Recordings Ltd. Copyright (c) – XL Recordings Ltd. Pressed By – Damont Lacquer Cut At – The Exchange Published By – EMI Virgin Music Ltd. Credits Lacquer Cut By – Mike's* Photography By – Alex Jenkins Photography By [Cover] – Colin Hawkins Written-By, Producer, Mixed By – Jonny L Notes On back cover: Made in England. Distributed by Warners UK Vocals on '2 Of Us' by Angela for Me One Artist Management. ℗ & © XL Recordings 1996. XL thanx: Paul Morris & Breakbeat Science, New York. Barcode and Other Identifiers Barcode: 5 012093 512266 Matrix / Runout (Side A etched): XLEP122 A1 MIKE'S THE EXCHANGE DAMONT C Matrix / Runout (Side B etched): XLEP122 B1 - MIKE'S - THE EXCHANGE DAMONT E Matrix / Runout (Side C etched): XLEP122 C1 MIKE'S THE EXCHANGE DAMONT D Matrix / Runout (Side D etched): XLEP122 D1 E Other versions Category Artist Title (Format) Label Category Country Year XLEP 122 CD Jonny L 2 Of Us EP (CD, EP) XL Recordings XLEP 122 CD UK 1996 2 Of Us (CD, Single, XLEP 122 CD 2 Jonny L XL Recordings XLEP 122 CD 2 UK 1996 Promo) 2 Of Us EP (2x12", EP, XLEP 122 Jonny L XL Recordings XLEP 122 UK Unknown TP, W/Lbl) 2 Of Us EP (2x12", EP, XLEP 122 Jonny L XL Recordings XLEP 122 UK 1996 Promo) 2 Of Us EP (CD, EP, XLEP 122 CD Jonny L XL Recordings XLEP 122 CD Germany 1996 sli) Comments about 2 Of Us EP - Jonny L Small Black I love this release, which for me captures that beautiful intelligent Jungle sound from the mid nineties and is the best of Jonny Ls work period. -

Eucharistic Miracle of O'cebreiro, Spain
Eucharistic Miracle of O’CEBREIRO SPAIN, 1300 The Eucharistic miracle of O’Cebreiro – During the Mass the Host changed to Flesh and the wine changed to Blood and was expelled from the chalice, staining the Shrine of the chalice, paten and Holy Blood of the miracle corporal. The Lord performed this prodigy in order to Mountain where Juan Santín sustain the little faith of the used to retreat and pray Sanctuary of O’Cebreiro priest who did not believe in the Real Presence of Jesus in the Eucharist. To this day, the Sacred Relics of the miracle are guarded near the church Altar where the miracle took place The Madonna of the Prodigy Chapel where the relics of The interior of where this prodigy took place the miracle used to be housed Santa Maria and numerous pilgrims go there annually to honor them. Panoramic view of O’Cebreiro ne icy winter in 1300 a Benedictine priest of the Madonna was leaning in adoration. The Madonna. Among the most documented testimo- was celebrating the sacred Mass in a chapel people today call her the “Madonna of the nials of the miracle are the bull of Pope Innocent beside the church of the convent of Sacred Miracle”. The Lord had wanted to open VIII of 1487, that of Pope Alexander VI of O’Cebreiro. On that miserable day of unceasing the eyes of the incredulous priest who had 1496, and an account by Father Yepes. snow and unbearably freezing wind, he thought doubted and to compensate the farmer for his that no one would dare show up for Mass. -
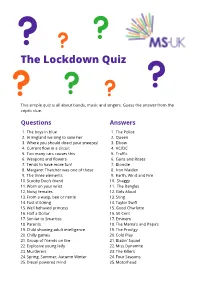
The Lockdown Quiz
The Lockdown Quiz This simple quiz is all about bands, music and singers. Guess the answer from the criptic clue. Questions Answers 1. The boys in blue 1. The Police 2. In England we sing to save her 2. Queen 3. Where you should direct your sneezes! 3. Elbow 4. Current flow in a circuit 4. AC/DC 5. Too many cars causes this 5. Traffic 6. Weapons and flowers 6. Guns and Roses 7. Tends to have more fun! 7. Blondie 8. Margaret Thatcher was one of these 8. Iron Maiden 9. The three elements 9. Earth, Wind and Fire 10. Scooby Doo’s friend 10. Shaggy 11. Worn on your wrist 11. The Bangles 12. Noisy females 12. Girls Aloud 13. From a wasp, bee or nettle 13. Sting 14. Fast stitching 14. Taylor Swift 15. Well behaved princess 15. Good Charlotte 16. Half a Dollar 16. 50 Cent 17. Similar to Smarties 17. Eminem 18. Parents 18. The Mama’s and Papa’s 19. Child showing adult intelligence 19. The Prodigy 20. Chilly games 20. Cold Play 21. Group of friends on fire 21. Blazin’ Squad 22. Explosive young lady 22. Miss Dynamite 23. Murderers 23. The Killers 24. Spring, Summer, Autumn Winter 24. Four Seasons 25. Diesel powered mind 25. Motorhead Questions Answers 26. Cold marsupials 26. Arctic Monkeys 27. Out of focus 27. Blur 28. Also known as a goat-pea 28. Black Eyed Peas 29. To make the boys wink 29. P!nk 30. Ten divided by two 30. Five 31. German emperor and ruler of the village 31. -

Neil Mclellan Complete CV
Neil McLellan Producer / Mixer / Programmer Producer / Songwriter Neil McLellan, currently the Creative Director of New York based multi-service Production company The Lodge, has enjoyed past successes with groups from Oasis to Madonna. He is internationally recognized for his work with the British dance act, The Prodigy, with his production, writing and mixing credits on all of their most successful releases. Prodigy ‘Invaders Must Die’ / Album MIx Senser Forthcoming Album Add Prod / Mix Prodigy ‘Always Outnumbered, Never Outgunned’ Co-prod / Mix / Co-write Carl Cox ‘Second Sign’ Album / Singles Co-prod / Co-write U.N.K.L.E. Sunna / Single Mix Terrorvision ‘Good To Go’ / Album / Singles Prod / Mix Brother Brown ‘Starcatching Girl’ / Single Add Prod / Mix Sasha ‘Xpander’ / single Mix Manu Chao ‘50 Millions’ / Single Mix Southern Fly Forthcoming album Co-Prod / Mix Regular Fries ‘Mash Man’ / album Prog / Prod Gintare ‘Earthless’ / album Mix Carl Cox ‘Phuture 2000’ / single Mix Bedlam A Go Go ‘Estate Style Entertainment’ / single Prod / Mix Supercharger ‘We Rock’ / single Mix Prodigy ‘Smack My Bitch Up’ / single Eng / Mix ‘Firestarter’ / single Eng / Mix ‘Breathe’ / single Eng / Mix ‘Minefield’ / single Eng / Mix ‘Music For The Jilted Generation’ / album Co-Prod / Mix ‘Voodoo People’ / single Co-Prod / Mix ‘Full Throttle’ / single Co-Prod / Mix ‘No Good (Start The Dance)’ / single Co-Prod / Mix ‘One Love’ / single Co-Prod / Mix ‘Poison’ / single Mix Erasure ‘Cowboy’ / album Co-Prod / Mix Archive ‘Londinium’ / album / singles Co-Prod / Mix -

08/10/18 “Outside Lands Music & Arts Festival” the Weeknd
Artist TicketsTickets SoldSold Date Facility/Promoter Support Capacity Capacity GrossGross 08/10/18 “Outside Lands Music & Arts Festival” The Weeknd 201,477 $27,743,508 08/11-12 Golden Gate Park Florence + The Machine / Janet Jackson 67,159 San Francisco, CA Future / Beck / Odesza / Bon Iver 100% 3 shows Another Planet Entertainment / Superfly Presents DJ Snake / N*E*R*D 149.50 - 795.00 1 03/23/18 “Lollapalooza Brazil” Red Hot Chili Peppers / Pearl Jam 300,000 $23,384,475 03/24-25 Autodromo de Interlagos Arctic Monkeys / The Killers 100,000 Sao Paulo, BRAZIL Kendrick Lamar / Lenny Kravitz 100% Reals 3 shows T4F - Time For Fun Kings Of Leon / Chance The Rapper 297.50 - 2,000.00 (75,2985,298) 06/15/18 “Pinkpop” Pearl Jam / Foo Fighters 133,350 $19,567,672 06/16-17 Megaland Bruno Mars / A Perfect Circle 44,450 Landgraaf, NETHERLANDS The Offspring / The Script 100% Euro 3 shows Buro Pinkpop / Live Nation Snow Patrol / Editors / The Kooks 100.00 - 220.00 (16,3753,000) 09/21/18 “Life Is Beautiful Festival” The Weeknd / N*E*R*D 158,282 $19,528,148 09/22-23 Downtown Las Vegas Odesza / Death Cab For Cutie 52,761 Las Vegas, NV Justice / Florence + The Machine 100% 3 shows Another Planet Entertainment Chvrches / RL Grime / Travis Scott 135.00 - 2,495.00 4 06/22/18 “Southside Festival” Arctic Monkeys / The Prodigy 57,236 $11,255,727 06/23-24 Take Off Park The Offspring / Arcade Fire 60,000 Neuhausen ob Eck, GERMANY Billy Talent / The Kooks 95% Euro FKP Scorpio Konzertproduktionen Justice / Franz Ferdinand / NOFX 137.58 - 577.58 5(9,636,670) 08/03/18 -

WAV / Kotori Magazine Issue 6 the Prodigy Dilated Peoples George
WWW.KOTORIMAG.COM MAGAZINE WWW.KOTORIMAG.COM MAGAZINE TM MUSIC/ART/POLITICS/CULTURE MUSIC/ART/POLITICS/CULTURE 006 / THE PRODIGY DILATED PEOPLES - GEORGE CLINTON FLIGHT COMICS - METRIC - SASHA & DIGWEED GRAM RABBIT MALKOVICH MUSIC DJ MUGGS PORTUGAL. THE MAN GOAPELE TIM FITE TWO GALLANTS USA $3.99 CANADA $4.99 ISSUE 6 SILVERSUN PICKUPS 0 6 0 74470 04910 4 BOMBAY DUB ORCHESTRA KOTORIMAG.COM RSE7!6SPRINGADPDF0- # - 9 #- -9 #9 #-9 + TABLE OF CONTENTS DILATED PEOPLES 12 They’re almost prophetic, hooking up with Kanye and Alchemist before most of the world even knew those names...now they’re back, and with 20/20, their vision is better than ever. Baby, Rakaa, and Evidence get all loose with our one and only Simonita. THE PRODIGY 40 Let the madness ensue as Maxim, Keith, and Liam reload The Prodigy cannon for another go round. Safety and sanity be damned. The electronic music world has never been the same since the Firestarter grabbed hold of us in the 90s. In this issue we explore the trials and tribs of megastardom and the never ending struggle to retain the punk rock performance belt they’ve been brandishing for years. GEORGE CLINTON 48 “Think! It ain’t illegal yet!!” That’s about the only venture outside the halls of justice that the P Funk Master has been able to afford of WOLFMOTHER late. Four score and seven lawyers later, the 08 man who fostered the groove for a nation of hip “You ever heard of Wolfmother?” ‘No.’ hop protagonists gets his pay day and let’s his “WOLFMOTHER WOLFMOTHER WOLF- story be told here in this exclusive interview. -

The Prodigy Press Release.Indd
PRESS RELEASE THE PRODIGY (15) Fast Sell: Orange Is The New Black’s Taylor Schilling makes her horror debut facing a mother’s worst nightmare to save RELEASE DATE her family from the evil within. From horror rising stars Nicholas McCarthy (The Pact), Jeff Buhler (Pet Sematary), and the producer of The Exorcism of Emily Rose, brace In Cinemas 15th March 2019 yourself for one of the scariest fi lms of the year! Synopsis: KEY TALENT INFORMATION In her much-anticipated foray into the horror-thriller Cast genre, Golden Globe and Emmy nominee Taylor Schilling • Taylor Schilling (Orange is the New Black) stars in The Prodigy as Sarah, a mother whose young son • Jackson Robert Scott (It) Miles’ disturbing behaviour signals that an evil, possibly • Peter Mooney (Rookie Blue) supernatural force has overtaken him. • Colm Feore (The Chronicles of Riddick) • Brittany Allen (Jigsaw, What Keeps You Alive) Fearing for her family’s safety, Sarah must choose between • Olunike Adeliyi (Boost) her maternal instinct to love and protect Miles and a desperate need to investigate what or who is causing his Directed by dark turn. She is forced to look for answers in the past, • Nicholas McCarthy (The Pact) taking the audience on a wild ride; one where the line Written by between perception and reality becomes frighteningly • Jeff Buhler (Pet Sematary) blurry. Produced by • Tripp Vinson (The Exorcism of Emily Rose) We Like It Because: • Tara Farney (Rose Red) With Taylor Schilling serving the last of her sentence as CONTACT/ORDER MEDIA the star of Netfl ix’s Orange Is The New Black later this year, the two-time Golden Globe nominee carves a harrowing Sadari Cunningham - [email protected] new identity as a mum living in fear of her own son, whose twisted turn by IT (2018) break-out Jackson Robert Scott makes us wonder if Pennywise was actually saving us from a more sinister threat? The Prodigy is the latest fi lm from celebrated horror director Nicholas McCarthy, who discovered his love for the genre through an unsupervised childhood viewing of The Exorcist. -

100 Years: a Century of Song 1990S
100 Years: A Century of Song 1990s Page 174 | 100 Years: A Century of song 1990 A Little Time Fantasy I Can’t Stand It The Beautiful South Black Box Twenty4Seven featuring Captain Hollywood All I Wanna Do is Fascinating Rhythm Make Love To You Bass-O-Matic I Don’t Know Anybody Else Heart Black Box Fog On The Tyne (Revisited) All Together Now Gazza & Lindisfarne I Still Haven’t Found The Farm What I’m Looking For Four Bacharach The Chimes Better The Devil And David Songs (EP) You Know Deacon Blue I Wish It Would Rain Down Kylie Minogue Phil Collins Get A Life Birdhouse In Your Soul Soul II Soul I’ll Be Loving You (Forever) They Might Be Giants New Kids On The Block Get Up (Before Black Velvet The Night Is Over) I’ll Be Your Baby Tonight Alannah Myles Technotronic featuring Robert Palmer & UB40 Ya Kid K Blue Savannah I’m Free Erasure Ghetto Heaven Soup Dragons The Family Stand featuring Junior Reid Blue Velvet Bobby Vinton Got To Get I’m Your Baby Tonight Rob ‘N’ Raz featuring Leila K Whitney Houston Close To You Maxi Priest Got To Have Your Love I’ve Been Thinking Mantronix featuring About You Could Have Told You So Wondress Londonbeat Halo James Groove Is In The Heart / Ice Ice Baby Cover Girl What Is Love Vanilla Ice New Kids On The Block Deee-Lite Infinity (1990’s Time Dirty Cash Groovy Train For The Guru) The Adventures Of Stevie V The Farm Guru Josh Do They Know Hangin’ Tough It Must Have Been Love It’s Christmas? New Kids On The Block Roxette Band Aid II Hanky Panky Itsy Bitsy Teeny Doin’ The Do Madonna Weeny Yellow Polka Betty Boo -

The Prodigy Fire • Jericho Mp3, Flac, Wma
The Prodigy Fire • Jericho mp3, flac, wma DOWNLOAD LINKS (Clickable) Genre: Electronic Album: Fire • Jericho Country: US Style: Breakbeat, Techno, Jungle MP3 version RAR size: 1849 mb FLAC version RAR size: 1141 mb WMA version RAR size: 1863 mb Rating: 4.5 Votes: 363 Other Formats: AHX XM DMF VQF MP1 DTS AA Tracklist Hide Credits 1 Fire (Edit) 3:21 2 Jericho (Original Version) 3:47 3 Fire (Sunrise Version) 4:58 Jericho (Genaside II Remix) 4 5:45 Engineer [Remix] – Dominic RobsonRemix, Producer [Additional] – Genaside II Pandemonium 5 4:25 Producer – Chaz Stevens, Liam HowlettWritten-By – Liam Howlett Companies, etc. Pressed By – Specialty Records Corporation Credits Photography By – Tui De Roy Written-By, Producer, Mixed By – L. Howlett* (tracks: 1 to 4) Notes Reissue with mould SID code Barcode and Other Identifiers Barcode (Text): 0 7559-66370-2 2 Barcode (String): 075596637022 Matrix / Runout: 2 66370-2 SRC*01 Matrix / Runout: M1S16 Mould SID Code: IFPI 2U4D Other versions Category Artist Title (Format) Label Category Country Year XL Recordings, XL XLT 30, XLT The Fire • Jericho (12", XLT 30, XLT Recordings, XL UK 1992 - 30, XLT-30 Prodigy Single, Ltd) - 30, XLT-30 Recordings The Fire / Jericho (12", INT 192 793 XL Recordings INT 192 793 Germany 1992 Prodigy Single, Promo) Fire • Jericho 33968-4, The (Strangely Limited Koch International, 33968-4, Poland 1997 33968-7 Prodigy Edition) (Cass, Koch International 33968-7 Single) Fire / Jericho The XLS 30CD (4xFile, MP3, XL Recordings XLS 30CD UK Unknown Prodigy Single, 320) Fire • Jericho The (Strangely Limited XLS 30CD XL Recordings XLS 30CD Canada 1997 Prodigy Edition) (CD, Single, Ltd, RE) Related Music albums to Fire • Jericho by The Prodigy 1.