Programs That Test Themselves
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

From Eiffel to the Java Virtual Machine
From Eiffel to the Java Virtual Machine Adding a new language target to the EiffelStudio compiler Søren Engel, [email protected] Supervisor Dr. Joseph R. Kiniry Thesis submitted to The IT University of Copenhagen for the degree of Bachelor of Science in Software Development August 2012 Abstract Previous attemps has been made towards translating and executing programs written in Eiffel on the Java platform, as described in Baumgartner [1]. However, the generated Java code has not been easy to use in terms of interoperability between the two languages, due to the restrictions of the Java language. Due to the evolution of the Java language, the work presented in this thesis examines whether it is possible to simplify the translation model of Eiffel to Java. In doing so, this thesis describes a refined translation model that leverages on some of the new features of the Java language, such as the invokedynamic bytecode instruction. Moreover, in order to verify the correctness of the proposed translation model, a description follows on how the translation model may be integrated into the existing EiffelStudio compiler, in terms extending the back-end to target the Java platform. In regards of simplicity, it was found that by using new language features of Java, the translation model of Eiffel to Java could be simplified to the extend that it solves the known issues found in the solution presented in Baumgartner [1]. In trying to integrate the translation model into the existing EiffelStudio compiler, it was found that no public documentation exists which described the internal structure of the EiffelStudio compiler. -

Eiffelstudio: a Guided Tour
EiffelStudio: A Guided Tour Interactive Software Engineering 2 EIFFELSTUDIO: A GUIDED TOUR § Manual identification Title: EiffelStudio: A Guided Tour, ISE Technical Report TR-EI-68/GT. (Replaces TR-EI-38/EB.) Publication history First published 1993 as First Steps with EiffelBench (TR-EI-38/EB) and revised as a chapter of Eiffel: The Environment (TR-EI- 39/IE), also available as An Object-Oriented Environment (Prentice Hall, 1994, ISBN 0-13-245-507-2. Version 3.3.8, 1995. Version 4.1, 1997 This version: July 2001. Corresponds to release 5.0 of the ISE Eiffel environment. Author Bertrand Meyer. Software credits Emmanuel Stapf, Arnaud Pichery, Xavier Rousselot, Raphael Simon; Étienne Amodeo, Jérôme Bou Aziz, Vincent Brendel, Gauthier Brillaud, Paul Colin de Verdière, Jocelyn Fiat, Pascal Freund, Savrak Sar, Patrick Schönbach, Zoran Simic, Jacques Sireude, Tanit Talbi, Emmanuel Texier, Guillaume Wong-So; EiffelVision 2: Leila Ait-Kaci, Sylvain Baron, Sami Kallio, Ian King, Sam O’Connor, Julian Rogers. See also acknowledgments for earlier versions in Eiffel: The Environment (TR-EI-39/IE) Non-ISE: special thanks to Thomas Beale, Éric Bezault, Paul Cohen, Paul-Georges Crismer, Michael Gacsaly, Dave Hollenberg, Mark Howard, Randy John, Eirik Mangseth, Glenn Maughan, Jacques Silberstein. Cover design Rich Ayling. Copyright notice and proprietary information Copyright © Interactive Software Engineering Inc. (ISE), 2001. May not be reproduced in any form (including electronic storage) without the written permission of ISE. “Eiffel Power” and the Eiffel Power logo are trademarks of ISE. All uses of the product documented here are subject to the terms and conditions of the ISE Eiffel user license. -

Spest - a Tool for Specification-Based Testing
SPEST - A TOOL FOR SPECIFICATION-BASED TESTING A Thesis presented to the Faculty of California Polytechnic State University, San Luis Obispo In Partial Fulfillment of the Requirements for the Degree Master of Science in Computer Science by Corrigan Johnson January 2016 !c 2016 Corrigan Johnson ALL RIGHTS RESERVED ii COMMITTEE MEMBERSHIP TITLE: SPEST - A Tool for Specification-Based Testing AUTHOR: Corrigan Johnson DATE SUBMITTED: January 2016 COMMITTEE CHAIR: Gene Fisher, Ph.D. Professor of Computer Science COMMITTEE MEMBER: David Janzen, Ph.D. Professor of Computer Science COMMITTEE MEMBER: John Clements, Ph.D. Associate Professor of Computer Science iii ABSTRACT SPEST - A Tool for Specification-Based Testing Corrigan Johnson This thesis presents a tool for SPEcification based teSTing (SPEST). SPEST is designed to use well known practices for automated black-box testing to reduce the burden of testing on developers. The tool uses a simple formal specification language to generate highly-readable unit tests that embody best practices for thorough software testing. Because the specification language used to generate the assertions about the code can be compiled, it can also be used to ensure that documentation describing the code is maintained during development and refactoring. The utility and effectiveness of SPEST were validated through several experiments conducted with students in undergraduate software engineering classes. The first experiment compared the understand- ability and efficiency of SPEST generated tests against student written tests based on the Java Modeling Language (JML)[25] specifications. JML is a widely used language for behavior program specification. A second experiment evaluated readability through a survey comparing SPEST generated tests against tests written by well established software developers. -

Automatic Verification of Eiffel Programs
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by CiteSeerX Automatic Verification of Eiffel Programs Master Thesis By: Julian Tschannen Supervised by: Martin Nordio Prof. Bertrand Meyer Student Number: 02-715-498 Abstract Correctness of software systems can be proven by using static verification techniques. Static verifiers such as Spec# and ESC/Java have been developed for object-oriented languages. These verifiers have shown that static verification can be applied to object-oriented languages such as C# and Java. However, these verifiers are not easy to use, as they introduce many new concepts that programmers have to learn. To apply these verifiers to a real project, one has to modify existing code by adding contracts and annotations such as pure method marks or ownership information. Eiffel supports Design by Contract. Current libraries and programs are therefore already annotated with contracts. The goal of this thesis is to develop an automatic verifier for Eiffel which can prove existing code without the need of further annotations. The main features supported by the tool are agents and dynamic invocation. The tool, called EVE Proofs, translates Eiffel programs to Boogie and runs a fully automatic theorem prover to check correctness of the code. EVE Proofs is integrated in EVE, the Eiffel Verification Environment. This integration enables Eiffel programmers to use it directly from the programming environment. To reason about framing of routines, one needs modifies clauses. To prove existing Eiffel code, we implemented an automatic extraction of modifies clauses. Although the extraction of modifies clauses is limited, it enables us to prove examples with simple frame conditions. -
List of Compilers 1 List of Compilers
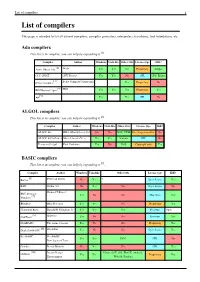
List of compilers 1 List of compilers This page is intended to list all current compilers, compiler generators, interpreters, translators, tool foundations, etc. Ada compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [2] Aonix Object Ada Atego Yes Yes Yes Proprietary Eclipse GCC GNAT GNU Project Yes Yes No GPL GPS, Eclipse [3] Irvine Compiler Irvine Compiler Corporation Yes Proprietary No [4] IBM Rational Apex IBM Yes Yes Yes Proprietary Yes [5] A# Yes Yes GPL No ALGOL compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? ALGOL 60 RHA (Minisystems) Ltd No No DOS, CP/M Free for personal use No ALGOL 68G (Genie) Marcel van der Veer Yes Yes Various GPL No Persistent S-algol Paul Cockshott Yes No DOS Copyright only Yes BASIC compilers This list is incomplete; you can help by expanding it [1]. Compiler Author Windows Unix-like Other OSs License type IDE? [6] BaCon Peter van Eerten No Yes ? Open Source Yes BAIL Studio 403 No Yes No Open Source No BBC Basic for Richard T Russel [7] Yes No No Shareware Yes Windows BlitzMax Blitz Research Yes Yes No Proprietary Yes Chipmunk Basic Ronald H. Nicholson, Jr. Yes Yes Yes Freeware Open [8] CoolBasic Spywave Yes No No Freeware Yes DarkBASIC The Game Creators Yes No No Proprietary Yes [9] DoyleSoft BASIC DoyleSoft Yes No No Open Source Yes FreeBASIC FreeBASIC Yes Yes DOS GPL No Development Team Gambas Benoît Minisini No Yes No GPL Yes [10] Dream Design Linux, OSX, iOS, WinCE, Android, GLBasic Yes Yes Proprietary Yes Entertainment WebOS, Pandora List of compilers 2 [11] Just BASIC Shoptalk Systems Yes No No Freeware Yes [12] KBasic KBasic Software Yes Yes No Open source Yes Liberty BASIC Shoptalk Systems Yes No No Proprietary Yes [13] [14] Creative Maximite MMBasic Geoff Graham Yes No Maximite,PIC32 Commons EDIT [15] NBasic SylvaWare Yes No No Freeware No PowerBASIC PowerBASIC, Inc. -

PART VI: Appendices
PART VI: Appendices This part complements the main material of the book by providing an introduction to four important programming languages: Java, C#, C++ and (briefly) C. The presentations are specifically designed for the readers of this book: they do not describe the four languages from scratch, but assume you are familiar with the concepts developed in the preceding chapters, and emphasize the differences with the Eiffel notation that they use. The descriptions do not cover the languages in their entirety, but include enough to enable you to start programming in these languages if you have mastered the concepts of the rest of this book. For practical use of a language system (compiler, interpreter, integrated development environment) you will of course need the corresponding reference information, from books or online. Since not every reader will want to learn every one of the languages, each of the first three appendices can be read independently; this also means, since Java, C# and C++ share a number of characteristics (due to the influence of C and, for the first two, C++), that if you do read all three you will encounter some repetitions. The fourth appendix is a short overview of C presented as a subset of C++, and hence assumes that you have read the C++ appendix. The last appendix presents basic information about using the EiffelStudio environment, to help with the examples of this book and the Traffic software. The appendices are followed by the list of picture credits and the index. A An introduction to Java (from material by Marco Piccioni) A.1 LANGUAGE BACKGROUND AND STYLE Java was introduced in 1995, the result of an internal research project at Sun Microsystems led by James Gosling (other key contributors include Bill Joy, Guy Steele and Gilad Bracha). -

Invitation to Eiffel (Bertrand Meyer)
Invitation to Eiffel Interactive Software Engineering 2 § Manual identification Title: Invitation to Eiffel, ISE Technical Report TR-EI-67/IV. Publication history First published 1987. Some revisions (in particular Web versions) have used the title “Eiffel in a Nutshell” This version: July 2001. Introduces coverage of agents; several other improvements. Corresponds to release 5.0 of the ISE Eiffel environment. Author Bertrand Meyer. Software credits See acknowledgments in book Eiffel: The Language. Cover design Rich Ayling. Copyright notice and proprietary information Copyright © Interactive Software Engineering Inc. (ISE), 2001. May not be reproduced in any form (including electronic storage) without the written permission of ISE. “Eiffel Power” and the Eiffel Power logo are trademarks of ISE. All uses of the product documented here are subject to the terms and conditions of the ISE Eiffel user license. Any other use or duplication is a violation of the applicable laws on copyright, trade secrets and intellectual property. Special duplication permission for educational institutions Degree-granting educational institutions using ISE Eiffel for teaching purposes as part of the Eiffel University Partnership Program may be permitted under certain conditions to copy specific parts of this book. Contact ISE for details. About ISE ISE (Interactive Software Engineering) helps you produce software better, faster and cheaper. ISE provides a wide range of products and services based on object technology, including ISE Eiffel, a complete development environment for the full system lifecycle. ISE’s training courses, available worldwide, cover key management and technical topics. ISE’s consultants are available to address your project needs at all levels. ISE’s TOOLS (Technology of Object-Oriented Languages and Systems) conferences, http://www.tools- conferences.com, are the meeting point for anyone interested in the software technologies of the future. -

Ada-Europe 2010 That Will Take Place June 2010 in Valencia, Spain
ADA Volume 30 USER Number 2 June 2009 JOURNAL Contents Page Editorial Policy for Ada User Journal 66 Editorial 67 News 69 Conference Calendar 98 Forthcoming Events 106 K. Fairlamb “Ada UK Conference 2009” 111 Articles from the Industrial Track of Ada-Europe 2009 J. S. Harbaugh “Pattern-Based Refactoring Shrinks Maintenance Costs” 115 Ada-Europe 2009 Tutorials Q. Ochem “Building Cross Language Applications with Ada” 119 R. I. Davis, I. Broster “Execution Time: Analysis, Verification and Optimization for Reliable Systems” 121 P. Rogers “Software Fault Tolerance” 125 Ada Gems 129 Ada-Europe Associate Members (National Ada Organizations) 132 Ada-Europe 2009 Sponsors Inside Back Cover Ada User Journal Volume 30, Number 2, June 2009 66 Editorial Policy for Ada User Journal Publication Original Papers Commentaries Ada User Journal — The Journal for Manuscripts should be submitted in We publish commentaries on Ada and the international Ada Community — is accordance with the submission software engineering topics. These published by Ada-Europe. It appears guidelines (below). may represent the views either of four times a year, on the last days of individuals or of organisations. Such March, June, September and All original technical contributions are articles can be of any length – December. Copy date is the last day of submitted to refereeing by at least two inclusion is at the discretion of the the month of publication. people. Names of referees will be kept Editor. confidential, but their comments will Opinions expressed within the Ada Aims be relayed to the authors at the discretion of the Editor. User Journal do not necessarily Ada User Journal aims to inform represent the views of the Editor, Ada- readers of developments in the Ada The first named author will receive a Europe or its directors. -

Eiffel Analysis, Design and Programming Language ECMA-367
ECMA-367 1st Edition / June 2005 Eiffel Analysis, Design and Programming Language Standard ECMA-367 1st Edition - June 2005 Eiffel Analysis, Design and Programming Language Ecma International Rue du Rhône 114 CH-1204 Geneva T/F: +41 22 849 6000/01 www.ecma-international.org Brief history Eiffel was originally designed, as a method of software construction and a notation to support that method, in 1985. The first implementation, from Eiffel Software (then Interactive Software Engineering Inc.), was commercially released in 1986. The principal designer of the first versions of the language was Bertrand Meyer. Other people closely involved with the original definition included Jean-Marc Nerson. The language was originally described in Eiffel Software technical documents that were expanded to yield Meyer’s book Eiffel: The Language in 1990-1991. The two editions of Object-Oriented Software Construction (1988 and 1997) also served to describe the concepts. (For bibliographical references on the documents cited see 3.6.) As usage of Eiffel grew, other Eiffel implementations appeared, including Eiffel/S and Visual Eiffel from Object Tools, Germany, EiffelStudio and Eiffel Envision from Eiffel Software, and SmartEiffel from LORIA, France. Eiffel today is used throughout the world for industrial applications in banking and finance, defense and aerospace, health care, networking and telecommunications, computer-aided design, game programming, and many other application areas. Eiffel is particularly suited for mission-critical developments in which programmer productivity and product quality are essential. In addition Eiffel is a popular medium for teaching programming and software engineering in universities. In 2002 Ecma International formed Technical Group 4 (Eiffel) of Technical Committee 39 (Programming and Scripting Languages). -

Advancing Compilers
© 2014 IJIRT | Volume 1 Issue 6 | ISSN : 2349-6002 COMPILERS-STUDY FROM ZERO Vishal Sharma, Priyanka Yadav, Priti Yadav Computer Science Department, Dronacharya College of Engineering/ Maharishi Dayanand University, India Abstract- This paper gives the basic understanding of Compilers also aid in detecting programming errors compilers. The beginning of paper explain the term (which are all too common). compiler followed by its working, need and Compiler techniques also help to improve computer knowledge required in building compilers. Further security. we have explained the different types of compiler and For example, the Java Byte code Verifier helps to the application of compilers. The paper shows the study of different types of compilers.Thus, going guarantee that Java security rules are satisfied. through this paper one will end up with a good II. HOW DOES A COMPILER WORK? understanding of compilers and their future aspect. A compiler can be viewed in two parts: Index Terms- Analyser, Compilers, FORTRAN, LISP, UNIVAC. 1. Source Code Analyser: which takes as input I. INTRODUCTION source code as a sequence of characters, and Compilers are fundamental to modern computing. interprets it as a structure of symbols (vars, values, They act as translators, transforming human- operators, etc.) oriented programming languages into computer- oriented machine languages. 2. Object Code Generator: which takes the A compiler allows programmers to ignore the structural analysis from (1) and produces runnable machine-dependent details of programming. code as output? Compilers allow programs and programming skills to be machine-independent. Code Source analyser Code Code generator Object Code The Code Analyser typically has three stages: • Semantic Analyser: checks that variables are • Lexical Analysis: accepts the source code as a instantiated before use, etc. -

Eiffel: Analysis, Design and Programming Language ECMA-367
ECMA-367 2nd Edition / June 2006 Eiffel: Analysis, Design and Programming Language Standard ECMA-367 2nd Edition - June 2006 Eiffel: Analysis, Design and Programming Language Ecma International Rue du Rhône 114 CH-1204 Geneva T/F: +41 22 849 6000/01 www.ecma-international.org Brief history Eiffel was originally designed, as a method of software construction and a notation to support that method, in 1985. The first implementation, from Eiffel Software (then Interactive Software Engineering Inc.), was commercially released in 1986. The principal designer of the first versions of the language was Bertrand Meyer. Other people closely involved with the original definition included Jean-Marc Nerson. The language was originally described in Eiffel Software technical documents that were expanded to yield Meyer’s book Eiffel: The Language in 1990-1991. The two editions of Object-Oriented Software Construction (1988 and 1997) also served to describe the concepts. (For bibliographical references on the documents cited see 3.6.) As usage of Eiffel grew, other Eiffel implementations appeared, including Eiffel/S and Visual Eiffel from Object Tools, Germany, EiffelStudio and Eiffel Envision from Eiffel Software, and SmartEiffel from LORIA, France. Eiffel today is used throughout the world for industrial applications in banking and finance, defense and aerospace, health care, networking and telecommunications, computer-aided design, game programming, and many other application areas. Eiffel is particularly suited for mission-critical developments in which programmer productivity and product quality are essential. In addition, Eiffel is a popular medium for teaching programming and software engineering in universities. In 2002 Ecma International formed Technical Group 4 (Eiffel) of Technical Committee 39 (Programming and Scripting Languages), known as TC39-TG4. -

Data Persistence in Eiffel
University of Kentucky UKnowledge Theses and Dissertations--Computer Science Computer Science 2016 Data Persistence in Eiffel Jimmy J. Johnson University of Kentucky, [email protected] Digital Object Identifier: https://doi.org/10.13023/ETD.2016.444 Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Johnson, Jimmy J., "Data Persistence in Eiffel" (2016). Theses and Dissertations--Computer Science. 51. https://uknowledge.uky.edu/cs_etds/51 This Doctoral Dissertation is brought to you for free and open access by the Computer Science at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Computer Science by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. I agree that the document mentioned above may be made available immediately for worldwide access unless an embargo applies.