A Survey of Location Inference Techniques on Twitter
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

EFFECTIVE SPOKESPERSONS on TWITTER: Master of Arts KATERINA
EFFECTIVE SPOKESPERSONS ON TWITTER: EXPERIMENTING WITH HOW PROFILE GENDER & NETWORK SIZE IMPACT USER PERCEPTIONS OF CREDIBILITY AND SOCIAL ATTRACTION A thesis presented to the Faculty of the Graduate School at the University of Missouri – Columbia In Partial Fulfillment of Requirement for the Degree Master of Arts by KATERINA M. STAM Dr. Glen T. Cameron, Thesis Supervisor MAY 2010 © Copyright by Kate M. Stam 2010 All Rights Reserved The undersigned, appointed by the dean of the Graduate School, have examined the thesis entitled EFFECTIVE SPOKESPERSONS ON TWITTER: EXPERIMENTING WITH HOW PROFILE GENDER & NETWORK SIZE IMAPCT USER PERCEPTIONS OF CREDIBILITY AND SOCIAL ATTRACTION presented by Katerina M. Stam, a candidate for the degree of Master of Arts, and hereby certify that, in their opinion, it is worthy of acceptance. _________________________________________________________________________ Professor Glen T. Cameron _________________________________________________________________________ Professor Glenn Leshner __________________________________________________________________________ Professor Lisa Sattenspiel __________________________________________________________________________ Professor Kevin Wise DEDICATION Of course my parents, Antonie and Tamara Stam, and my brother Elliott deserve acknowledgement for being kind and helpful in keeping a steady supply of sweets within reach, not to mention all the listening and editing and assistance. Kathy Sharp, Martha Pickens and Ginny Cowell—you ladies really are the best. Here is a nod to Ernest Hemingway, who may or may not have shown the world that stories can be brief and bold and less than 140 characters, regardless of what one thinks of Twitter: For sale: baby shoes, never used. - Ernest Hemingway (In only six words and 33 characters.) ACKNOWLEDGMENTS What makes the Missouri School of Journalism so special is its culture. It is a collaborative place, where students are offered the opportunity to not just observe but work alongside talented, experienced researchers in the field. -

ECLAP Best Practice Network User Manual
ANNEX of DE 3.1: “Infrastructure: ingestion and processing content and metadata”, M7 ECLAP BEST PRACTICE NETWORK User Manual Informative report Version: 1.6.2, draft Data: 18/04/2011 1 ECLAP Best Practice Network User Manual ECLAP Copyright Notice Depending on the document‘s declaration of accessibility on the title page, the following notices apply: This document is Public and it is available under the Creative Commons license: Attribution- NonCommercial-NoDerivs 3.0 Unported. This license permits non-commercial sharing and remixing of this work, so long as attribution is given. For more information on this license, you can visit, http://creativecommons.org/licenses/by- nc-nd/3.0/ Please note that: You can become affiliated with ECLAP. This will give you access to a great amount of knowledge, information related to ECLAP services, content and tools. If you are interested please contact ECLAP coordinator Paolo Nesi at [email protected]. Once affiliated with ECLAP you will have the possibility of using ECLAP for your organisation. You can contribute to the improvement of ECLAP by sending your contribution to ECLAP coordinator Paolo Nesi at [email protected] You can attend ECLAP meetings that are open to public, for additional information see www.eclap.eu or contact ECLAP coordinator Paolo Nesi at [email protected] Statement of originality: This deliverable contains original unpublished work except where clearly indicated otherwise. Acknowledgement of previously published material and of the work of others has been made through appropriate citation, quotation or both. 2 ECLAP Best Practice Network User Manual Index European Collected Library of Artistic Performance (ECLAP) .......................................................................... -

Green Tweets
twitter_praise_page Page i Thursday, March 12, 2009 12:35 PM Praise for Twitter API: Up and Running “Twitter API: Up and Running is a friendly, accessible introduction to the Twitter API. Even beginning web developers can have a working Twitter project before they know it. Sit down with this book for a weekend and you’re on your way to Twitter API mastery.” — Alex Payne, Twitter API lead “This book rocks! I would have loved to have had this kind of support when I initially created TwitDir.” — Laurent Pantanacce, creator of TwitDir “Twitter API: Up and Running is a very comprehensive and useful resource—any developer will feel the urge to code a Twitter-related application right after finishing the book!” — The Lollicode team, creators of Twitscoop “A truly comprehensive resource for anyone who wants to get started with developing applications around the Twitter platform.” — David Troy, developer of Twittervision “An exceptionally detailed look at Twitter from the developer’s perspective, including useful and functional sample code!” — Damon Cortesi, creator of TweetStats, TweepSearch, and TweetSum “This book is more than just a great technical resource for the Twitter API. It also provides a ton of insight into the Twitter culture and the current landscape of apps. It’s perfect for anyone looking to start building web applications that integrate with Twitter.” — Matt Gillooly, lead developer of Twalala “A wonderful account of the rich ecosystem surrounding Twitter’s API. This book gives you the insight and techniques needed to craft your own tools for this rapidly expanding social network.” — Craig Hockenberry, developer of Twitterrific twitter_praise_page Page ii Thursday, March 12, 2009 12:35 PM Twitter API: Up and Running Twitter API: Up and Running Kevin Makice Beijing • Cambridge • Farnham • Köln • Sebastopol • Taipei • Tokyo Twitter API: Up and Running by Kevin Makice Copyright © 2009 Kevin Makice. -

Understanding Simple HTML Tags • Creating and Editing Your Own
MS Access Lab Topic: HTML Summary · Understanding Simple HTML Tags · Creating and Editing Your Own Web Page · Publishing Your Web Page 1. Understanding Simple HTML Tags Go to the website: http://www.gettingstarted.net We will be going through the HTML tags listed on the page as an introduction to hypertext markup language. Other HTML resources: http://www.htmlguild.com/resources/ http://www.ieor.berkeley.edu/~ieor170/ (“Related Links” link) 2. Creating and Editing Your Own Web Page There are a good number of HTML editors that we can use to create our web page: · Adobe Page Mill · Microsoft Front Page · Netscape Composer They are great because they help you in inserting HTML tags graphically and simplifying the more complicated tasks (such as specifying tables and frames). But with all things great, they come with a price. However, since the lab already has Microsoft Front Page installed, we will be using it for this lab. A Basic Web Page We will be creating a very basic web page that contains: · Horizontal lines · Images · Text Links · Image Links Go to Start à Programs à Microsoft FrontPage Text · Just type normally as you would with a text document. Converting text into text link · Highlight the text that you want to show up as a link to another web page. In the example (Figure 1) we highlighted the word “IEOR Department” and then clicked on the “Hyperlink” icon in the toolbar. In the “Create Hyperlink” dialog box, insert the Web address that you want the link to go to. In this example, we entered the IEOR Department’s web site (Figure 2). -

Creating a Webpage Using Html James Tam 12/5/2018
12/5/2018 Creating And Publishing A Webpage You will learn how your web page can be ‘hosted’ as well as the basic html ‘tags’ for formatting a webpage along with the mechanism of including internal and external content Web Page • A document that can be seen “online” via the World-Wide- Web • Going to the web address: – www.cpsc.ucalgary.ca/~tamj (or pages.cpsc.ucalgary.ca/~tamj) – Retrieves a document called “index.html” from the computer science web server to load into your web browser. Creating a webpage using html James Tam 12/5/2018 Making A University Webpage • Use a simple editor WordPad (don’t use MS-Word because it will generate a great deal of extra unnecessary information for a simple webpage). • Save it as a text file Make sure you manually add the .htm or .html suffix to the end of the file otherwise it will be text .txt file and not display properly (uses a text editor such as Notepad instead of web browser to view). ‘Hosting’ Your Webpage • In order for your website to be available on the web, the page and it’s content has to be stored on a web server. • This web server is described as ‘hosting’ your webpage. • Two examples of how your page can be hosted will be described: – Creating a University of Calgary personal web page (the university web server hosts your page). – Creating a personal web page external to the university (a third party can host your page after you graduate). Creating a webpage using html James Tam 12/5/2018 Saving The Webpage On The ‘Host’ • Save documents (html, locally hosted images and videos) in a folder called “public_html” that is contained in a folder called “Webdisk”. -

Web Content and HTML
UNIT Ch. 1 1 2 3 4 5 6 7 8 9 Ch. 2 10 11 12 2 13 14 UNIT 2 - WEB DEVELOPMENT In this unit, students are empowered to create and share the content on their own web pages. They begin by thinking about the role of the web, and how it can be used as a medium for creative expression. As students develop their pages and begin to see themselves as programmers, they are encouraged think critically about the impact of sharing information online and how to be more critical content consumers. They are also introduced to problem solving as it relates to programming, as they learn valuable skills such as debugging, commenting, and structure of language. At the conclusion of the unit, students compile their work to create a personal website they can publish and share. CHAPTER 1: WEB CONTENT aND HTML BIG QUESTIONS Why do people create websites? How can text communicate content and structure on a web page? How can I incorporate content I find online into my own webpage? What strategies can I use when coding to find and fix issues? WEEK 1 LESSON 1: EXPLORING WEBSITES UNPLUGGED This lesson covers the purposes that a website might serve, both for the users and the creators. The class explores a handful of the most-used websites in the United States and discusses how each of those sites is useful for users and how it might also serve its creators. LESSON 2: WEBSITES FOR EXPRESSION UNPLUGGED This lesson introduces websites as a means of personal expression. -

Web 2.0 Tools Improve Teaching and Collaboration in High School English Language Classes Mahmud Shihab Nova Southeastern University, [email protected]
Nova Southeastern University NSUWorks CEC Theses and Dissertations College of Engineering and Computing 2008 Web 2.0 Tools Improve Teaching and Collaboration in High School English Language Classes Mahmud Shihab Nova Southeastern University, [email protected] This document is a product of extensive research conducted at the Nova Southeastern University College of Engineering and Computing. For more information on research and degree programs at the NSU College of Engineering and Computing, please click here. Follow this and additional works at: https://nsuworks.nova.edu/gscis_etd Part of the Computer Sciences Commons Share Feedback About This Item NSUWorks Citation Mahmud Shihab. 2008. Web 2.0 Tools Improve Teaching and Collaboration in High School English Language Classes. Doctoral dissertation. Nova Southeastern University. Retrieved from NSUWorks, Graduate School of Computer and Information Sciences. (303) https://nsuworks.nova.edu/gscis_etd/303. This Dissertation is brought to you by the College of Engineering and Computing at NSUWorks. It has been accepted for inclusion in CEC Theses and Dissertations by an authorized administrator of NSUWorks. For more information, please contact [email protected]. Web 2.0 Tools Improve Teaching and Collaboration in High School English Language Classes by Mahmud M. Shihab A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computing Technology in Education Graduate School of Computer and Information Sciences Nova Southeastern University 2008 We hereby certify that this dissertation, submitted by Mahmud M. Shihab, conforms to acceptable standards and is fully adequate in scope and quality to fulfill the dissertation requirements for the degree of Doctor of Philosophy. -

Journalism Students, Web 2.0 and the Digital Divide
The University of Southern Mississippi The Aquila Digital Community Dissertations Fall 12-2009 Journalism Students, Web 2.0 and the Digital Divide Mary Elizabeth Green University of Southern Mississippi Follow this and additional works at: https://aquila.usm.edu/dissertations Part of the Communication Technology and New Media Commons, Journalism Studies Commons, and the Mass Communication Commons Recommended Citation Green, Mary Elizabeth, "Journalism Students, Web 2.0 and the Digital Divide" (2009). Dissertations. 1080. https://aquila.usm.edu/dissertations/1080 This Dissertation is brought to you for free and open access by The Aquila Digital Community. It has been accepted for inclusion in Dissertations by an authorized administrator of The Aquila Digital Community. For more information, please contact [email protected]. The University of Southern Mississippi JOURNALISM STUDENTS, WEB 2.0 AND THE DIGITAL DIVIDE by Mary Elizabeth Green A Dissertation Submitted to the Graduate School of The University of Southern Mississippi in Partial Fulfillment of the Requirements of the Degree of Doctor of Philosophy December 2009 The University of Southern Mississippi JOURNALISM STUDENTS, WEB 2.0 AND THE DIGITAL DIVIDE by Mary Elizabeth Green Abstract of a Dissertation Submitted to the Graduate School of The University of Southern Mississippi in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy December 2009 ABSTRACT JOURNALISM STUDENTS, WEB 2.0 AND THE DIGITAL DIVIDE by Mary Elizabeth Green December 2009 The purpose of this study was to find out if students were utilizing Web 2.0 applications. Since the applications in question are often employed by the media industry, the study aspired to find out if students majoring in mass communication and journalism utilized the applications more often than other students. -

Unit 2 - Web Development
UNIT Ch. 1 1 2 3 4 5 6 7 8 9 10 11 12 13 2 Ch. 2 14 15 16 17 18 19 20 21 UNIT 2 - WEB DEVELOPMENT In the Web Development unit, students are empowered to create and share the content on their own web pages. They begin by thinking about the role of the web, and how it can be used as a medium for creative expression before creating their own personal web pages. As students develop their pages and begin to see themselves as programmers, they are encouraged think critically about the impact of sharing information online and how to be more critical content consumers. They are also introduced to problem solving as it relates to programming, as they learn valuable skills such as debugging, using resources, and teamwork. At the conclusion of the unit, students work together to create a website to address a problem. MODIFICATIONS FOR VIRTUAL AND SOCIALLY-DISTANCED CLASSROOMS ARE YOU TEACHING IN A VIRTUAL SETTING OR IN A SOCIALLY-DISTANCED CLASSROOM? Check out THIS DOCUMENT for ideas and resources to help you tailor common practices like THINK PAIR SHARE or PEER FEEDBACK to your learning environment. For lesson-specific modifications, check out the Lesson Modifications section within Lesson Plans. CHAPTER 1: CREATING WEBPAGES BIG QUESTIONS Why do people create websites? How can text communicate content, structure, and style on a web page? How do I safely and appropriately make use of the content published on the Internet? What strategies can I use when coding to find and fix issues? WEEK 1 LESSON 1: EXPLORING WEB PAGES UNPLUGGED **Question of the Day: Why do people create web pages?** This lesson covers the purposes that a web page might serve, both for the users and the creators. -

Engage Customers Through Social Media
How to Engage Customers through Social Media A Quick Start Guide for Avaya BusinessPartners + Plan + Execute Use this guide to learn how Follow steps to develop your business can benefit and manage your social through Social Media efforts presence online. Visit Avaya Partner Marketing Central at https://pmc.avaya.com for more Quick Start Guides and additional resources. Social Media Your Customers How Avaya Uses Introduction Get Started Glossary Basics and Social Media Social Media How to Engage Customers through Social Media A Quick Start Guide for Avaya BusinessPartners What is social media? The term “social media” refers to a broad range of online networks, Web sites and applications that allow you to easily and publicly share information. Social media lets you create, distribute and publish your own content instantly (photos, job listings, product reviews, personal “status,” etc.) and also helps you discover what other people (who you may or may not know) have posted for all to see. Some examples of social media include: + Blogs: Short for “web log,” a blog is a type of Web site that features chronological “posts” or articles by an author, usually all loosely related to a topic or theme. + Microblogging: A super-condensed blog format that limits you to postings of just a sentence or two, a practice popularized by Twitter twitter.com. It is typically used to answer the question “What are you doing right now?” + Wikis: A Wiki is a collaborative Web site guidebook with all content editable by the users themselves. The most famous is Wikipedia—the free online encyclopedia en.wikipedia.org/wiki/Main_Page. -
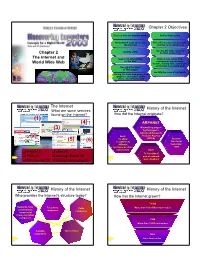
Chapter 2 the Internet and World Wide Web Chapter 2 Objectives
Chapter 2 Objectives Discuss how the Internet works Define Webcasting Understand ways to access Describe the uses of electronic the Internet commerce (e-commerce) Identify a URL Identify the tools required Chapter 2 for Web publishing The Internet and Search for information Explain how e-mail, FTP, on the Web newsgroups and message World Wide Web boards, mailing lists, chat rooms and instant messaging work Describe the types of Web pages Identify the rules of netiquette Recognize how Web pages use Next graphics, animation, audio, p. 2.2 video, and virtual reality The Internet History of the Internet What are some services found on the Internet? How did the Internet originate? (1) (4) ARPANET (3) Networking project by Pentagon’s Advanced Research (2) Goal: Projects Agency To allow (ARPA) Became (5) (6) scientists at functional different September locations to share 1969 e-mail (1) chat (4) information Goal: e-mail (1) chat (4) To function if Next Web (2) message board (5) Next part of network p. 2.3 were disabled p. 2.2 Fig. 2-1 file transfer (3) instantinstant messagingmessaging (6)(6) History of the Internet History of the Internet Who provides the Internet’s structure today? How has the Internet grown? Today Networks from Telephone Cable More than 100 million host nodes corporations, companies companies commercial firms, and other companies 1984 More than 1,000 host nodes Satellite Government companies 1969 Next Next Four host nodes p. 2.4 p. 2.4 1 How the Internet History of the Internet Works Who controls the Internet? What are ways to access the Internet? • Nobody; it is public, cooperative, and an 1 Regional independent network ISP • Several organizations set standards 2 National ISP 3 OSP (Ex. -

Setting the Stage 1 of 19
Setting the Stage 1 of 19 Setting the Stage Anne J. Gilliland Metadata, literally “data about data,” has become a widely used yet still frequently underspecified term that is understood in different ways by the diverse professional communities that design, create, describe, preserve, and use information systems and resources. It is a construct that has been around for as long as humans have been organizing information, albeit transparently in many cases, and today we create and interact with it in increasingly digital ways. For the past hundred years at least, the creation and management of metadata has primarily been the responsibility of information professionals engaged in cataloging, classification, and indexing; but as information resources are increasingly put online by the general public, metadata considerations are no longer solely the province of information professionals. Although metadata is arguably a much less familiar term among creators and consumers of networked digital content who are not information professionals per se, these same individuals are increasingly adept at creating, exploiting, and assessing user-contributed metadata such as Web page title tags, folksonomies, and social bookmarks. Schoolchildren and college students are taught in information literacy programs to look for metadata such as provenance and date information in order to ascertain the authoritativeness of information that they retrieve on the Web. Thus it has become more important than ever that not only information professionals but also other creators and users of digital content understand the critical roles of different types of metadata in ensuring accessible, authoritative, interoperable, scaleable, and preservable cultural heritage information and record-keeping systems.