Freebase-Triples: a Methodology for Processing the Freebase Data Dumps
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Comparative Evaluation of Geospatial Semantic Web Frameworks for Cultural Heritage
heritage Article A Comparative Evaluation of Geospatial Semantic Web Frameworks for Cultural Heritage Ikrom Nishanbaev 1,* , Erik Champion 1,2,3 and David A. McMeekin 4,5 1 School of Media, Creative Arts, and Social Inquiry, Curtin University, Perth, WA 6845, Australia; [email protected] 2 Honorary Research Professor, CDHR, Sir Roland Wilson Building, 120 McCoy Circuit, Acton 2601, Australia 3 Honorary Research Fellow, School of Social Sciences, FABLE, University of Western Australia, 35 Stirling Highway, Perth, WA 6907, Australia 4 School of Earth and Planetary Sciences, Curtin University, Perth, WA 6845, Australia; [email protected] 5 School of Electrical Engineering, Computing and Mathematical Sciences, Curtin University, Perth, WA 6845, Australia * Correspondence: [email protected] Received: 14 July 2020; Accepted: 4 August 2020; Published: 12 August 2020 Abstract: Recently, many Resource Description Framework (RDF) data generation tools have been developed to convert geospatial and non-geospatial data into RDF data. Furthermore, there are several interlinking frameworks that find semantically equivalent geospatial resources in related RDF data sources. However, many existing Linked Open Data sources are currently sparsely interlinked. Also, many RDF generation and interlinking frameworks require a solid knowledge of Semantic Web and Geospatial Semantic Web concepts to successfully deploy them. This article comparatively evaluates features and functionality of the current state-of-the-art geospatial RDF generation tools and interlinking frameworks. This evaluation is specifically performed for cultural heritage researchers and professionals who have limited expertise in computer programming. Hence, a set of criteria has been defined to facilitate the selection of tools and frameworks. -

Knowledge Graphs on the Web – an Overview Arxiv:2003.00719V3 [Cs
January 2020 Knowledge Graphs on the Web – an Overview Nicolas HEIST, Sven HERTLING, Daniel RINGLER, and Heiko PAULHEIM Data and Web Science Group, University of Mannheim, Germany Abstract. Knowledge Graphs are an emerging form of knowledge representation. While Google coined the term Knowledge Graph first and promoted it as a means to improve their search results, they are used in many applications today. In a knowl- edge graph, entities in the real world and/or a business domain (e.g., people, places, or events) are represented as nodes, which are connected by edges representing the relations between those entities. While companies such as Google, Microsoft, and Facebook have their own, non-public knowledge graphs, there is also a larger body of publicly available knowledge graphs, such as DBpedia or Wikidata. In this chap- ter, we provide an overview and comparison of those publicly available knowledge graphs, and give insights into their contents, size, coverage, and overlap. Keywords. Knowledge Graph, Linked Data, Semantic Web, Profiling 1. Introduction Knowledge Graphs are increasingly used as means to represent knowledge. Due to their versatile means of representation, they can be used to integrate different heterogeneous data sources, both within as well as across organizations. [8,9] Besides such domain-specific knowledge graphs which are typically developed for specific domains and/or use cases, there are also public, cross-domain knowledge graphs encoding common knowledge, such as DBpedia, Wikidata, or YAGO. [33] Such knowl- edge graphs may be used, e.g., for automatically enriching data with background knowl- arXiv:2003.00719v3 [cs.AI] 12 Mar 2020 edge to be used in knowledge-intensive downstream applications. -

New Generation of Social Networks Based on Semantic Web Technologies: the Importance of Social Data Portability
Workshop on Adaptation and Personalization for Web 2.0, UMAP'09, June 22-26, 2009 New Generation of Social Networks Based on Semantic Web Technologies: the Importance of Social Data Portability Liana Razmerita1, Martynas Jusevičius2, Rokas Firantas2 Copenhagen Business School, Denmark1 IT University of Copenhagen, Copenhagen, Denmark2 [email protected], [email protected], [email protected] Abstract. This article investigates several well-known social network applications such as Last.fm, Flickr and identifies social data portability as one of the main technical issues that need to be addressed in the future. We argue that this issue can be addressed by building social networks as Semantic Web applications with FOAF, SIOC, and Linked Data technologies, and prove it by implementing a prototype application using Java and core Semantic Web standards. Furthermore, the developed prototype shows how features from semantic websites such as Freebase and DBpedia can be reused in social applications and lead to more relevant content and stronger social connections. 1 Introduction Social networking sites are developing at a very fast pace, attracting more and more users. Their application domain can be music sharing, photos sharing, videos sharing, bookmarks sharing, professional networks, and others. Despite their tremendous success social networking websites have a number of limitations that are identified and discussed within this article. Most of the social networking applications are “walled websites” and the “online communities are like islands in a sea”[1]. Lack of interoperability between data in different social networks applications limits access to relevant content available on different social networking sites, and limits the integration and reuse of available data and information. -

How Much Is a Triple? Estimating the Cost of Knowledge Graph Creation
How much is a Triple? Estimating the Cost of Knowledge Graph Creation Heiko Paulheim Data and Web Science Group, University of Mannheim, Germany [email protected] Abstract. Knowledge graphs are used in various applications and have been widely analyzed. A question that is not very well researched is: what is the price of their production? In this paper, we propose ways to estimate the cost of those knowledge graphs. We show that the cost of manually curating a triple is between $2 and $6, and that the cost for automatically created knowledge graphs is by a factor of 15 to 250 cheaper (i.e., 1g to 15g per statement). Furthermore, we advocate for taking cost into account as an evaluation metric, showing the correspon- dence between cost per triple and semantic validity as an example. Keywords: Knowledge Graphs, Cost Estimation, Automation 1 Estimating the Cost of Knowledge Graphs With the increasing attention larger scale knowledge graphs, such as DBpedia [5], YAGO [12] and the like, have drawn towards themselves, they have been inspected under various angles, such as as size, overlap [11], or quality [3]. How- ever, one dimension that is underrepresented in those analyses is cost, i.e., the prize of creating the knowledge graphs. 1.1 Manual Curation: Cyc and Freebase For manually created knowledge graphs, we have to estimate the effort of pro- viding the statements directly. Cyc [6] is one of the earliest general purpose knowledge graphs, and, at the same time, the one for which the development effort is known. At a 2017 con- ference, Douglas Lenat, the inventor of Cyc, denoted the cost of creation of Cyc at $120M.1 In the same presentation, Lenat states that Cyc consists of 21M assertions, which makes a cost of $5.71 per statement. -
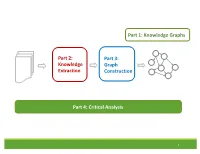
Knowledge Extraction Part 3: Graph
Part 1: Knowledge Graphs Part 2: Part 3: Knowledge Graph Extraction Construction Part 4: Critical Analysis 1 Tutorial Outline 1. Knowledge Graph Primer [Jay] 2. Knowledge Extraction from Text a. NLP Fundamentals [Sameer] b. Information Extraction [Bhavana] Coffee Break 3. Knowledge Graph Construction a. Probabilistic Models [Jay] b. Embedding Techniques [Sameer] 4. Critical Overview and Conclusion [Bhavana] 2 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 3 Critical Overview SUMMARY SUCCESS STORIES DATASETS, TASKS, SOFTWARES EXCITING ACTIVE RESEARCH FUTURE RESEARCH DIRECTIONS 4 Why do we need Knowledge graphs? • Humans can explore large database in intuitive ways •AI agents get access to human common sense knowledge 5 Knowledge graph construction A1 E1 • Who are the entities A2 (nodes) in the graph? • What are their attributes E2 and types (labels)? A1 A2 • How are they related E3 (edges)? A1 A2 6 Knowledge Graph Construction Knowledge Extraction Graph Knowledge Text Extraction graph Construction graph 7 Two perspectives Extraction graph Knowledge graph Who are the entities? (nodes) What are their attributes? (labels) How are they related? (edges) 8 Two perspectives Extraction graph Knowledge graph Who are the entities? • Named Entity • Entity Linking (nodes) Recognition • Entity Resolution • Entity Coreference What are their • Entity Typing • Collective attributes? (labels) classification How are they related? • Semantic role • Link prediction (edges) labeling • Relation Extraction 9 Knowledge Extraction John was born in Liverpool, to Julia and Alfred Lennon. Text NLP Lennon.. Mrs. Lennon.. his father John Lennon... the Pool .. his mother .. he Alfred Person Location Person Person John was born in Liverpool, to Julia and Alfred Lennon. -

Adding Realtime Coverage to the Google Knowledge Graph
Adding Realtime Coverage to the Google Knowledge Graph Thomas Steiner1?, Ruben Verborgh2, Raphaël Troncy3, Joaquim Gabarro1, and Rik Van de Walle2 1 Universitat Politècnica de Catalunya – Department lsi, Spain {tsteiner,gabarro}@lsi.upc.edu 2 Ghent University – IBBT, ELIS – Multimedia Lab, Belgium {ruben.verborgh,rik.vandewalle}@ugent.be 3 EURECOM, Sophia Antipolis, France [email protected] Abstract. In May 2012, the Web search engine Google has introduced the so-called Knowledge Graph, a graph that understands real-world entities and their relationships to one another. Entities covered by the Knowledge Graph include landmarks, celebrities, cities, sports teams, buildings, movies, celestial objects, works of art, and more. The graph enhances Google search in three main ways: by disambiguation of search queries, by search log-based summarization of key facts, and by explo- rative search suggestions. With this paper, we suggest a fourth way of enhancing Web search: through the addition of realtime coverage of what people say about real-world entities on social networks. We report on a browser extension that seamlessly adds relevant microposts from the social networking sites Google+, Facebook, and Twitter in form of a panel to Knowledge Graph entities. In a true Linked Data fashion, we inter- link detected concepts in microposts with Freebase entities, and evaluate our approach for both relevancy and usefulness. The extension is freely available, we invite the reader to reconstruct the examples of this paper to see how realtime opinions may have changed since time of writing. 1 Introduction With the introduction of the Knowledge Graph, the search engine Google has made a significant paradigm shift towards “things, not strings” [3], as a post on the official Google blog states. -

Question Answering Benchmarks for Wikidata Dennis Diefenbach, Thomas Tanon, Kamal Singh, Pierre Maret
Question Answering Benchmarks for Wikidata Dennis Diefenbach, Thomas Tanon, Kamal Singh, Pierre Maret To cite this version: Dennis Diefenbach, Thomas Tanon, Kamal Singh, Pierre Maret. Question Answering Benchmarks for Wikidata. ISWC 2017, Oct 2017, Vienne, Austria. hal-01637141 HAL Id: hal-01637141 https://hal.archives-ouvertes.fr/hal-01637141 Submitted on 17 Nov 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Question Answering Benchmarks for Wikidata Dennis Diefenbach1, Thomas Pellissier Tanon2, Kamal Singh1, Pierre Maret1 1 Universit´ede Lyon, CNRS UMR 5516 Laboratoire Hubert Curien fdennis.diefenbach,kamal.singh,[email protected] 2 Universit´ede Lyon, ENS de Lyon, Inria, CNRS, Universit´eClaude-Bernard Lyon 1, LIP. [email protected] Abstract. Wikidata is becoming an increasingly important knowledge base whose usage is spreading in the research community. However, most question answering systems evaluation datasets rely on Freebase or DBpedia. We present two new datasets in order to train and benchmark QA systems over Wikidata. The first is a translation of the popular SimpleQuestions dataset to Wikidata, the second is a dataset created by collecting user feedbacks. Keywords: Wikidata, Question Answering Datasets, SimpleQuestions, WebQuestions, QALD, SimpleQuestionsWikidata, WDAquaCore0Questions 1 Introduction Wikidata is becoming an increasingly important knowledge base. -

Farewell Freebase: Migrating the Simplequestions Dataset to Dbpedia
Farewell Freebase: Migrating the SimpleQuestions Dataset to DBpedia Michael Azmy,∗ Peng Shi,∗ Jimmy Lin, and Ihab F. Ilyas David R. Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada fmwazmy,p8shi,jimmylin,[email protected] Abstract Question answering over knowledge graphs is an important problem of interest both commer- cially and academically. There is substantial interest in the class of natural language questions that can be answered via the lookup of a single fact, driven by the availability of the popular SIMPLEQUESTIONS dataset. The problem with this dataset, however, is that answer triples are provided from Freebase, which has been defunct for several years. As a result, it is difficult to build “real-world” question answering systems that are operationally deployable. Furthermore, a defunct knowledge graph means that much of the infrastructure for querying, browsing, and ma- nipulating triples no longer exists. To address this problem, we present SIMPLEDBPEDIAQA, a new benchmark dataset for simple question answering over knowledge graphs that was created by mapping SIMPLEQUESTIONS entities and predicates from Freebase to DBpedia. Although this mapping is conceptually straightforward, there are a number of nuances that make the task non-trivial, owing to the different conceptual organizations of the two knowledge graphs. To lay the foundation for future research using this dataset, we leverage recent work to provide simple yet strong baselines with and without neural networks. 1 Introduction Question answering over knowledge graphs is an important problem at the intersection of multiple re- search communities, with many commercial deployments. To ensure continued progress, it is important that open and relevant benchmarks are available to support the comparison of various techniques. -

Wikigraphs: a Wikipedia Text - Knowledge Graph Paired Dataset
WikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset Luyu Wang* and Yujia Li* and Ozlem Aslan and Oriol Vinyals *Equal contribution DeepMind, London, UK {luyuwang,yujiali,ozlema,vinyals}@google.com Freebase Paul Hewson Abstract WikiText-103 Bono type.object.name Where the streets key/wikipedia.en “Where the Streets Have have no name We present a new dataset of Wikipedia articles No Name” is a song by ns/m.01vswwx Irish rock band U2. It is the ns/m.02h40lc people.person.date of birth each paired with a knowledge graph, to facili- opening track from their key/wikipedia.en 1987 album The Joshua ns/music.composition.language music.composer.compositions Tree and was released as tate the research in conditional text generation, 1960-05-10 the album’s third single in ns/m.06t2j0 August 1987. The song ’s ns/music.composition.form graph generation and graph representation 1961-08-08 hook is a repeating guitar ns/m.074ft arpeggio using a delay music.composer.compositions people.person.date of birth learning. Existing graph-text paired datasets effect, played during the key/wikipedia.en song’s introduction and ns/m.01vswx5 again at the end. Lead David Howell typically contain small graphs and short text Evans, better vocalist Bono wrote... Song key/wikipedia.en known by his ns/common.topic.description stage name The (1 or few sentences), thus limiting the capabil- Edge, is a people.person.height meters The Edge British-born Irish musician, ities of the models that can be learned on the songwriter... 1.77m data. -

Semantic Networks for Engineering Design: a Survey
Semantic Networks for Engineering Design: A Survey A Preprint Ji Han Serhad Sarica School of Engineering Data-Driven Innovation Lab University of Liverpool Singapore University of Technology and Design United Kingdom Singapore, 487372 [email protected] [email protected] Feng Shi Jianxi Luo Amazon Web Services Data-Driven Innovation Lab United Kingdom Singapore University of Technology and Design [email protected] Singapore, 487372 [email protected] 12th December, 2020 Abstract There have been growing uses of semantic networks in the past decade, such as leveraging large- scale pre-trained graph knowledge databases for various natural language processing (NLP) tasks in engineering design research. Therefore, the paper provides a survey of the research that has employed semantic networks in the engineering design research community. The survey reveals that engineering design researchers have primarily relied on WordNet, ConceptNet, and other common- sense semantic network databases trained on non-engineering data sources to develop methods or tools for engineering design. Meanwhile, there are emerging efforts to mine large scale technical publication and patent databases to construct engineering-contextualized semantic network databases, e.g., B-Link and TechNet, to support NLP in engineering design. On this basis, we recommend future research directions for the construction and applications of engineering-related semantic networks in engineering design research and practice. Keywords: Semantic data processing, Knowledge management, Design informatics, Semantic network, Knowledge base 1 1 INTRODUCTION Design knowledge retrieval, representation, and management are considered significant activities in engineering design because design is essentially a knowledge-intensive process (Bertola and Teixeira, 2003; Chandrasegaran et al., 2013). -

Semantic Web Technologies Public Knowledge Graphs
Semantic Web Technologies Public Knowledge Graphs Heiko Paulheim Previously on “Semantic Web Technologies” • Linked Open Data – We know the principles – We have seen examples for some datasets • Today – A closer look on actual examples – Some useful, large-scale resources 10/30/20 Heiko Paulheim 2 Growing Interest in Knowledge Graphs Sources: Google 10/30/20 Heiko Paulheim 3 Introduction • Knowledge Graphs on the Web • Everybody talks about them, but what is a Knowledge Graph? – I don’t have a definition either... Journal Paper Review, (Natasha Noy, Google, June 2015): “Please define what a knowledge graph is – and what it is not.” 10/30/20 Heiko Paulheim 4 Definitions • Knowledge graphs could be envisaged as a network of all kind things which are relevant to a specific domain or to an organization. They are not limited to abstract concepts and relations but can also contain instances of things like documents and datasets. (Blumauer, 2014) • We define a Knowledge Graph as an RDF graph. (Färber and Rettinger, 2015) • Knowledge graphs are large networks of entities, their semantic types, properties, and relationships between entities. (Kroetsch and Weikum, 2016) • [...] systems exist, [...], which use a variety of techniques to extract new knowledge, in the form of facts, from the web. These facts are interrelated, and hence, recently this extracted knowledge has been referred to as a knowledge graph. (Pujara et al., 2013) Ehrlinger and Wöß: Towards a Definition of Knowledge Graphs. 2016 10/30/20 Heiko Paulheim 5 Definitions • My working definition: a Knowledge Graph – mainly describes instances and their relations in a graph • Unlike an ontology • Unlike, e.g., WordNet – Defines possible classes and relations in a schema or ontology • Unlike schema-free output of some IE tools – Allows for interlinking arbitrary entities with each other • Unlike a relational database – Covers various domains • Unlike, e.g., Geonames Paulheim: Knowledge graph refinement: A survey of approaches and evaluation methods, 2017. -

OK Google, What Is Your Ontology? Or: Exploring Freebase Classification to Understand Google’S Knowledge Graph
OK Google, What Is Your Ontology? Or: Exploring Freebase Classification to Understand Google’s Knowledge Graph Niel Chah a;1 a University of Toronto, Faculty of Information Abstract. This paper reconstructs the Freebase data dumps to understand the under- lying ontology behind Google’s semantic search feature. The Freebase knowledge base was a major Semantic Web and linked data technology that was acquired by Google in 2010 to support the Google Knowledge Graph, the backend for Google search results that include structured answers to queries instead of a series of links to external resources. After its shutdown in 2016, Freebase is contained in a data dump of 1.9 billion Resource Description Format (RDF) triples. A recomposition of the Freebase ontology will be analyzed in relation to concepts and insights from the literature on classification by Bowker and Star. This paper will explore how the Freebase ontology is shaped by many of the forces that also shape classifica- tion systems through a deep dive into the ontology and a small correlational study. These findings will provide a glimpse into the proprietary blackbox Knowledge Graph and what is meant by Google’s mission to “organize the world’s information and make it universally accessible and useful”. Keywords. ontology, Google, Freebase, Knowledge Graph, classification 1. Introduction This paper’s title is a riff on a key phrase “OK, Google” that is uttered by users to trigger Google’s virtual assistant services. Through products such as the Google Home appli- arXiv:1805.03885v2 [cs.IR] 22 May 2018 ance and a mobile application, the Google Assistant taps into the structured data in the proprietary Google Knowledge Graph (KG) to answer queries like “What is the capital of Canada?”.