The Value of a Win: Analysis of Playoff Structures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

National Basketball Association Scheduling Simulation
National Basketball Association Scheduling Simulation 21-393 Final Project, Fall 2016 Shengqi Chai, Yutong Li, Liyunshu Qian, Ming Yang Department of Mathematics Carnegie Mellon University Pittsburgh, PA 15213 Table of Contents I. Abstract II. Background and Problem Description III. Solution IV. Results V. Conclusion VI. Reference Page 1 of 12 I. Abstract Sport scheduling is a complex task in the presence of a myriad of conflicting requirements and preferences. In this work, our primary goal is to find a feasible and approximately optimal schedule in terms of travel distance for the 30 teams in National Basketball Association. We focus on the schedule for the regular season, which usually spans over a 5-month duration. Existing approaches to build a schedule from scratch tends to suffer from substantial runtime overhead. In particular, it is computationally infeasible to solve the problem directly using linear programming and constraint programming due to the complicate formats and rules for NBA scheduling. Thus for the sake of simplification, we adopted assumptions so that integer programming is applicable. Additionally, we approached the problem using divide and conquer to reduce computational complexity. Apart from Operations Research techniques, methods from Machine Learning and Data Collection are also exploited in finding the solution. Our approach yields reliable schedules in a reasonable runtime, and the algorithm should be applicable, with slight modifications, to any scheduling problems in single-round robin or double-round robin fashion. II. Problem Background National Basketball Association is the preeminent men’s professional basketball league in North America, and is widely considered as one of the best basketball leagues in the world. -

Boston Celtics PLAYOFF and RENEWAL INFORMATION
BOSTON CELTICS PLAYOFF AND RENEWAL INFORMATION INVOICING FULL SEASON PLAN You will see the following three payment options on the Full Season Ticket Holders will receive tickets to 14 potential enclosed invoice: home playoff games (4 each in Rounds One and Two; 3 each in Rounds Three and Four).* • Monthly EZ-Pay Payment Plan – spread your playoff and renewal payments evenly over 10 months with our convenient HALF SEASON 1 PLAN payment plan by either debit/credit card each month. All current Half Season 1 holders will receive alternating home games in alternating rounds of the 2013 playoffs. • Three payments by check or credit/debit card – you are Games 1 and 3 in Round One, Games 2 and 4 in Round asked to pay your first installment by February 28, 2013. Two, Games 1 and 3 in Round Three and Game 2 in the The remaining payments will be due in May and August Finals Round.* respectively. HALF SEASON 2 PLAN • Pay in full by check or credit/debit card by February 28, 2013. All current Half Season 2 holders will receive alternating home If you elect to take only your 2013 Playoff tickets OR only games in alternating rounds of the 2013 Playoffs. Games 2 your 2013-14 season tickets, please contact your Celtics and 4 in Round One, Games 1 and 3 in Round Two, Game Account Executive at 866-4CELTIX to discuss your options. 2 in Round Three and Games 1 and 3 in the Finals Round.* *If a 4th home playoff game is necessary in either Rounds Three or Four and is part of RESALE CREDIT FROM NBATICKETS.COM your package (See below), that game will added to your account and you will need to print online via Account Manager. -

FOOTBALL Table of Contents (Click on an Item to Jump Directly to That Section) Page IMPORTANT DATES and DEADLINES
FOOTBALL Table of Contents (click on an item to jump directly to that section) Page IMPORTANT DATES AND DEADLINES ..................................................................................................................... 2 RULE ON SEASON DATES ............................................................................................................................................. 2 HEAT ACCLIMATIZATION REGULATIONS FOR SDHSAA FOOTBALL ........................................................... 3 GAME LIMITATION ....................................................................................................................................................... 4 CLASSIFICATION AND ALIGNMENT ........................................................................................................................ 4 RULE REVISIONS FOR THE 2021 SEASON ................................................................................................................ 5 NFHS EDITORIAL CHANGES FOR 2021 SEASON .................................................................................................... 5 SOUTH DAKOTA RULE CHANGES ............................................................................................................................. 5 GENERAL INFORMATION Athletic Contest Contracts ............................................................................................................................................... 6 Licensed Officials Mandatory ........................................................................................................................................ -

Introduction Predictive Vs. Earned Ranking Methods
An overview of some methods for ranking sports teams Soren P. Sorensen University of Tennessee Knoxville, TN 38996-1200 [email protected] Introduction The purpose of this report is to argue for an open system for ranking sports teams, to review the history of ranking systems, and to document a particular open method for ranking sports teams against each other. In order to do this extensive use of mathematics is used, which might make the text more difficult to read, but ensures the method is well documented and reproducible by others, who might want to use it or derive another ranking method from it. The report is, on the other hand, also more detailed than a ”typical” scientific paper and discusses details, which in a scientific paper intended for publication would be omitted. We will in this report focus on NCAA 1-A football, but the methods described here are very general and can be applied to most other sports with only minor modifications. Predictive vs. Earned Ranking Methods In general most ranking systems fall in one of the following two categories: predictive or earned rankings. The goal of an earned ranking is to rank the teams according to their past performance in the season in order to provide a method for selecting either a champ or a set of teams that should participate in a playoff (or bowl games). The goal of a predictive ranking method, on the other hand, is to provide the best possible prediction of the outcome of a future game between two teams. In an earned system objective and well publicized criteria should be used to rank the teams, like who won or the score difference or a combination of both. -

Chapter Two Massey’S Method
Chapter Two Massey’s Method The Bowl Championship Series (BCS) is a rating system for NCAA college football that wasdesignedtodeterminewhichteamsareinvitedtoplayinwhichbowlgames.The BCS has become famous, and perhaps notorious, for the ratings it generates for each team in the NCAA. These ratings are assembled from two sources, humans and computers. Human input comes from the opinions of coaches and media. Computer input comes from six computer and mathematical models—details are given in the aside on page 17. The BCS ratings for the 2001 and 2003 seasons are known as particularly controversial among sports fans and analysts. The flaws in the BCS selection system as opposed to a tournament playoff are familiar to most, including the President of the United States—read the aside on page 19. Initial Massey Rating Method In 1997, Kenneth Massey, then an undergraduate at Bluefield College, created a method for ranking college football teams. He wrote about this method, which uses the mathematical theory of least squares, as his honors thesis [52]. In this book we refer to this as the Massey method, despite the fact that there are actually several other methods attributed to Ken Massey. Massey has since become a mathematics professor at Carson-Newman College and today continues to refine his sports ranking models. Professor Massey has created various rat- ing methods, one of which is used by the Bowl Championship Series K. Massey (or BCS) system to select NCAA football bowl matchups—see the aside on page 17. The Colley method, described in the next chapter, is also one of the six computer rating sys- tems used by the BCS. -

Season Seat Holder Retention in Minor League Baseball
St. John Fisher College Fisher Digital Publications Sport Management Undergraduate Sport Management Department Spring 2013 Season Seat Holder Retention in Minor League Baseball Matt Butler St. John Fisher College Follow this and additional works at: https://fisherpub.sjfc.edu/sport_undergrad Part of the Sports Management Commons How has open access to Fisher Digital Publications benefited ou?y Recommended Citation Butler, Matt, "Season Seat Holder Retention in Minor League Baseball" (2013). Sport Management Undergraduate. Paper 93. Please note that the Recommended Citation provides general citation information and may not be appropriate for your discipline. To receive help in creating a citation based on your discipline, please visit http://libguides.sjfc.edu/citations. This document is posted at https://fisherpub.sjfc.edu/sport_undergrad/93 and is brought to you for free and open access by Fisher Digital Publications at St. John Fisher College. For more information, please contact [email protected]. Season Seat Holder Retention in Minor League Baseball Abstract In lieu of an abstract, here is the paper's first paragraph: In minor league (AAA) baseball the amount of season tickets sold for the season can account for at least fifteen percent of total paid attendance for the. With this in mind a sport manager may wonder what brings season ticket buyers back season after season, and what can be done to measure this occurrence. An added question for front office staff members is, do these reasons coincide with a team’s marketing strategy to maximize the amount of fans who buy season tickets? To analyze this occurrence I looked into exactly what behavior fans exhibit and their motivation to purchase. -

Indiana Pacers Vs New York Knicks Live Stream
1 / 4 Indiana Pacers Vs New York Knicks Live Stream NBA Live: Pacers vs Hornets Live Stream Reddit Free Charlotte Hornets vs Indiana Pacers will happen in NBA Play-in tournament. New York is 31-27 overall .... Aug 22, 2020 — No time like the present for the Indiana Pacers to show up. The NBA's Eastern Conference No. 4 seed cannot afford another unsatisfying .... ... To Elevate Knicks · MSG PM. Jul 12, 2021. Video Player is loading. Play Video. Play. Mute. Current Time 0:00. /. Duration -:-. Loaded: 0%. Stream Type LIVE.. Free Picks » NBA Picks » Cleveland Cavaliers vs Indiana Pacers Prediction, 12/31/2020 ... though the Cavaliers lost a home game to the New York Knicks in their last outing. ... You can also live stream the same via the NBA League Pass.. Learn how to watch Indiana Pacers vs New York Knicks 3 April 2012 stream online, see match results and teams h2h stats at Scores24.live!. May 20, 2021 — The Washington Wizards will host the Indiana Pacers on Thursday night for the right to be eighth playoff seed in the Eastern Conference.. Jan 16, 2014 — New York Knicks vs Indiana Pacers Live Stream: Watch Online Free 7 ET Thursday Night, TNT – Paul George Looking To Give His All Against .... Oct 19, 2018 — Brooklyn Nets vs. New York Knicks: Live stream, TV, injury report ... Meanwhile, the New York Knicks are looking for their first 2-0 start to a season since ... Brooklyn: at Indiana, Saturday; at Cleveland, Wednesday; at New Orleans, Oct. 26 ... Chicago Bulls · Cleveland Cavs · Detroit Pistons · Indiana Pacers ... -

Quantifying the Influence of Deviations in Past NFL Standings on the Present
Can Losing Mean Winning in the NFL? Quantifying the Influence of Deviations in Past NFL Standings on the Present The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation MacPhee, William. 2020. Can Losing Mean Winning in the NFL? Quantifying the Influence of Deviations in Past NFL Standings on the Present. Bachelor's thesis, Harvard College. Citable link https://nrs.harvard.edu/URN-3:HUL.INSTREPOS:37364661 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA Can Losing Mean Winning in the NFL? Quantifying the Influence of Deviations in Past NFL Standings on the Present A thesis presented by William MacPhee to Applied Mathematics in partial fulfillment of the honors requirements for the degree of Bachelor of Arts Harvard College Cambridge, Massachusetts November 15, 2019 Abstract Although plenty of research has studied competitiveness and re-distribution in professional sports leagues from a correlational perspective, the literature fails to provide evidence arguing causal mecha- nisms. This thesis aims to isolate these causal mechanisms within the National Football League (NFL) for four treatments in past seasons: win total, playoff level reached, playoff seed attained, and endowment obtained for the upcoming player selection draft. Causal inference is made possible due to employment of instrumental variables relating to random components of wins (both in the regular season and in the postseason) and the differential impact of tiebreaking metrics on teams in certain ties and teams not in such ties. -

Nothing Minor About It the American Association/AFL of 1936-50
THE COFFIN CORNER: Vol. 12, No. 2 (1990) Nothing minor about it The American Association/AFL of 1936-50 By Bob Gill Try as I might, I can’t seem to mention the era before World War II without calling it “the heyday of pro football’s minor leagues.” But it’s not just an idle comment. In the 1930s several flourishing regional “circuits” of independent teams coalesced into outstanding minor leagues. From today’s perspective, one of the least likely locales for such a circuit was the New York-New Jersey area, where fans had the New York Giants and the Brooklyn Dodgers to satisfy their hunger for pro football. Despite that, the area produced the best of all the pre-war minor leagues: the American Association (soon to be immortalized in another best-selling PFRA publication). The AA was formed in June 1936, in response to a proposal by Edwin (Piggy) Simandl, manager of the Orange Tornadoes. Charter members were Brooklyn, Mt. Vernon, New Rochelle, Orange, Passaic, Paterson, Staten Island and White Plains. Several of these cities had been represented in two earlier leagues, the 1932 Eastern League and the 1933 Interstate League, both of which failed after a single season. However, those leagues didn’t have Joe Rosentover as president. Despite the early demise of his own Passaic club, Rosentover remained at the helm of the league for its whole existence. The AA’s first season was somewhat like that of its main rival, the Dixie League, which also opened for business in 1936. No team established any clear superiority, and at the end of November Rosentover announced a playoff series matching the top four teams, two each from what the newspapers sometimes called the New York group and the New Jersey group. -
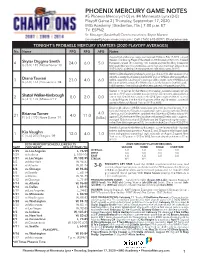
PHOENIX MERCURY GAME NOTES #5 Phoenix Mercury (1-0) Vs
PHOENIX MERCURY GAME NOTES #5 Phoenix Mercury (1-0) vs. #4 Minnesota Lynx (0-0) Playoff Game 2 | Thursday, September 17, 2020 IMG Academy | Bradenton, Fla. | 7:00 p.m. ET TV: ESPN2 Sr. Manager, Basketball Communications: Bryce Marsee [email protected] | Cell: (765) 618-0897 | @brycemarsee TONIGHT'S PROBABLE MERCURY STARTERS (2020 PLAYOFF AVERAGES) No. Name PPG RPG APG Notes Aquired by the Mercury in a sign-and-trade with Dallas on Feb. 12, 2020...named Western Conference Player of the Week on 9/8 for week of 8/31-9/6...finished 4 Skylar Diggins-Smith 24.0 6.0 5.0 the season ranked 7th in scoring, 10th in assists and tied for 4th in three-point G | 5-9 | 145 | Notre Dame '13 field goals (46)...scored a postseason career-high and team-high 24 points on 9/15 vs. WAS...picked up her first playoffs win over Washington on 9/15 WNBA's all-time leader in postseason scoring and ranks 3rd in all-time assists in the playoffs...6 assists shy of passing Sue Bird for 2nd on WNBA's all-time playoffs as- 3 Diana Taurasi 23.0 4.0 6.0 sists list...ranked 5th in the league in scoring and 8th in assists...led the WNBA in 3-pt G | 6-0 | 163 | Connecticut '04 field goals (61) this season, the 11th time she's led the league in 3-pt field goals... holds a perfect 7-0 record in single elimination games in the playoffs since 2016 Started in 10 games for the Mercury this season..scored a career-high 24 points on 9/11 against Seattle in a career-high 35 mimutes...also posted a 2 Shatori Walker-Kimbrough 8.0 2.0 0.0 career-high 5 steals this season in the 8/14 game against Atlanta...scored G | 6-1 | 170 | Missouri '19 in double figures 5 of the final 8 games of the regular season...scored 8 points in Mercury's Round 1 win on 9/15 vs. -

A Comparison of Rating Systems for Competitive Women's Beach Volleyball
Statistica Applicata - Italian Journal of Applied Statistics Vol. 30 (2) 233 doi.org/10.26398/IJAS.0030-010 A COMPARISON OF RATING SYSTEMS FOR COMPETITIVE WOMEN’S BEACH VOLLEYBALL Mark E. Glickman1 Department of Statistics, Harvard University, Cambridge, MA, USA Jonathan Hennessy Google, Mountain View, CA, USA Alister Bent Trillium Trading, New York, NY, USA Abstract Women’s beach volleyball became an official Olympic sport in 1996 and continues to attract the participation of amateur and professional female athletes. The most well-known ranking system for women’s beach volleyball is a non-probabilistic method used by the Fédération Internationale de Volleyball (FIVB) in which points are accumulated based on results in designated competitions. This system produces rankings which, in part, determine qualification to elite events including the Olympics. We investigated the application of several alternative probabilistic rating systems for head-to-head games as an approach to ranking women’s beach volleyball teams. These include the Elo (1978) system, the Glicko (Glickman, 1999) and Glicko-2 (Glickman, 2001) systems, and the Stephenson (Stephenson and Sonas, 2016) system, all of which have close connections to the Bradley- Terry (Bradley and Terry, 1952) model for paired comparisons. Based on the full set of FIVB volleyball competition results over the years 2007-2014, we optimized the parameters for these rating systems based on a predictive validation approach. The probabilistic rating systems produce 2014 end-of-year rankings that lack consistency with the FIVB 2014 rankings. Based on the 2014 rankings for both probabilistic and FIVB systems, we found that match results in 2015 were less predictable using the FIVB system compared to any of the probabilistic systems. -

Quantifying How NBA Playoff Format Impacts Playoff Excitement
Quantifying How NBA Playoff Format Impacts Playoff Excitement Quinn Johnson, Bailey Fosdick, Connor Gibbs Colorado State University, Fort Collins, Colorado, United States Abbreviated abstract: The National Basketball Association has predominantly kept its same basic playoff format since 1984. Here, we explore two alternative playoff formats and quantify the expected excitement in game play across the playoffs. We consider format changes to include each conference's top 8 teams and playing a conference-less tournament, as well as, taking the top 16 teams in the NBA and playing a conference-less tournament. Using simulation, we found small to no differences in excitement between the three formats but continue to endorse the top 16 team system due its advantage in fairness to all teams. Related publications: – Tokarz D. How We Make the YUSAG Power Rankings. R: NBA Power Rankings. 2018 Mar 20. UCSAS [email protected] - 1 2020 Motivation Deserving teams are often left out Would changing the playoff format of postseason due to conference result in a drastically more or less strength differences. exciting postseason? Seeding Differences between Current and Top 16 Format Possible playoff formats Current play: conference who’s in: Top 8 West, Top 8 East –––––––––––––––––––––––––––––––––– 8W8E play: overall seeding who’s in: Top 8 West, Top 8 East –––––––––––––––––––––––––––––––––– 16TOT play: overall seeding who’s in: Top 16 NBA UCSAS 2020 Methods 1) Model win probability for each game 2) Simulate playoffs under different formats • Using