Proceedings of the 2Nd Workshop on Natural Language Processing Techniques for Educational Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

102Nd Annual General Meeting -.:: GEOCITIES.Ws
St Albans Cricket Club Notice is hereby given that the 102nd Annual General Meeting of the St Albans Cricket Club Inc. will be held at Trevinos Restaurant and Bar, cnr Riccarton Road and Mona Vale Avenue (in the upstairs conference room, access at rear) on Monday, 31 July 2006 at 7:30pm Business: 1. To receive the Minutes of the 2005 Annual General Meeting; 2. To consider and adopt the 2005/06 Annual Report and Accounts; 3. Election of Officers and Management Committee for the 2006/07 season; 4. Notice of Motion That the club levy the following levels of subscriptions (GST inclusive) for the 2006/07 season, namely: a) Adult Men and Women: $220 to be paid by 30 November 2006; b) Full-time University, Polytechnic, Training College Students, Men and Women Under 18: $165 to be paid by 30 November 2006; 3 c) Secondary School Pupils: $110 to be paid by 30 November 2006; d) Primary/Intermediate School Pupils: $40 for first member of family, and $10 for any subsequent members of the same family, to be paid by 30 November 2006; e) Social: $50 to be paid upon joining the club. Please note: there have been no increases in these subscription levels from last season. 5. Notice of Motion That article 21 (Audit) of the St Albans Cricket Club Constitution be amended to read: “The Statement of Income and Expenditure and Balance Sheet for each Financial Year which shall end on the 31st day of May, shall be audited by one or more Auditors elected at the preceding Annual General Meeting of the Club. -

The Salopian No
TITLE HERE 1 THE SALOPIAN SALOPIAN CLUB FORTHCOMING EVENTS n More details can be found on the Salopian Club website: www.shrewsbury.org.uk/page/os-events THE SALOPIAN Issue No. 159 - Winter 2016 n Sporting fixtures at: www.shrewsbury.org.uk/page/os-sport (Click on individual sport) n Except where stated email: [email protected] All Shrewsbury School parents (including former parents) and guests of members are most welcome at the majority of our events. It is our policy to include in all invitations all former parents for whom we have contact details. The exception is any event marked ‘Old Salopian’ which, for reasons of space, is restricted to Club members only (e.g. Birmingham Dinner). Supporters or guests are always very welcome at Salopian Club sporting or arts events. Emails containing further details are sent out prior to all events, so please make sure that we have your up to date contact details. Date Event Venue Wednesday 11 January, 7pm A Celebration of Epiphany Service St Mary-le-Bow, London WC2V 6AU led by Revd Gavin Williams (former Shrewsbury School Chaplain) with a choir conducted by OS Patrick Craig and Richard Eteson Wednesday 18 January, 5.30pm Salopian Club Committee Meeting London Thursday 2 February, 7.30pm Shrewsbury School in Concert with Barber Institute of Fine Arts a pre-concert drinks reception in the Birmingham B15 2TS Gallery at the Barber Institute Contact: [email protected] from 6-7pm Wednesday 22 February, 6.00pm OS Sports Committee Meeting London Thursday 23 February, 5.00pm Evensong at -
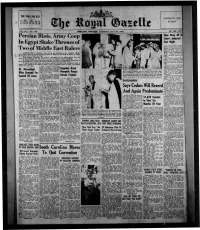
Persian Riots, Army Coup in Egypt Shake Thrones Pi Two of Middle
TIDE TABLE FOR JULY LpHTING-UP TIME High Low Date Water Water Sun- Sun- 8.52 p.m. ajn. p.ro. «.n_. p TO. __se get i 24 11.05 11.19 5.10 5.05 6.28 8.22 25 11.41 11.54 S.43 5.45 6 28 8$2 VOL. 32 — NO. 172 HAMILTON. BERMUDA. THURSDAY, JULY 24, 1952 6D PER COPM Now Vicar Of Si Persian Riots, Army Coup John's Inducted In Egypt Shake Thrones pi Last Night f| In the presence of tf Bishop of Bermuda, the Arc deacon of Bermuda and tf Two of Middle East Rulers churchwardens and co: gregation of St. John's, Per broke, the Rev. Edward Now LONDON, July 23 (Reuter).—Two thrones are tottering in the turbulent Middle Bewes Chapman was la East today—those of 32-year-old King Farouk of Egypt and the Shah ot Persia, to whom night inducted vicar' of tt he is related by a former marriage. church. 1 Both thrones symbolise the opulent remoteness of the ruling classes from the Mr. Chapman arrived in tt. poverty which burdens the life of the great mass of people ia their kingdoms. Colony on Monday froi in Persia the Shah was forced to recognise the claims of .Mohammed Mussadegh to Emmanuel Church, Plymout) the Premiership by a yelling mob wbich threatened to tear his capital apart. where he had been vicar sine In Egypt part of the army has revolted against the graft and corruption which it 1946. claims was revealed in the supply of faulty arms to Egyptian troops ia their war against The new minister formally too: Israel 18 months ago. -

2006/07 Annual Report and Accounts;
St Albans Cricket Club Notice is hereby given that the 103rd Annual General Meeting of the St Albans Cricket Club Inc. will be held at Trevinos Restaurant and Bar, cnr Riccarton Road and Mona Vale Avenue (in the upstairs conference room, access at rear) on Monday, 30 July 2007 at 7:30pm Business: 1. To receive the Minutes of the 2006 Annual General Meeting; 2. To consider and adopt the 2006/07 Annual Report and Accounts; 3. Election of Officers and Management Committee for the 2007/08 season; 4. Notice of Motion That the club levy the following levels of subscriptions (GST inclusive) for the 2007/08 season, namely: a) Adult Men and Women: $240 to be paid by 30 November 2007; b) Full-time University, Polytechnic, Training College Students, Men and Women Under 18: $180 to be paid by 30 November 2007; 3 c) Secondary School Pupils: $120 to be paid by 30 November 2007; d) Primary/Intermediate School Pupils: $50 for first member of family, and $25 for any subsequent members of the same family, to be paid by 30 November 2007; e) Social: $60 per year. 5. Notice of Motion That article 6 (Membership) of the St Albans Cricket Club Constitution be amended, with references to “Honorary Members” or “Honorary Associate Members” removed from the article. 6. General Business: Members are reminded to resign (in writing) before the date of the AGM, to ensure that no subscription payment is due for the 2007/08 season, in the event of any member deciding not to play or transferring to another club, or moving out of the city. -

Wesley Times – September’12
Wesley Times – September’12 Newsletter of Wesley College Colombo Old Boys Union Australia Branch Inc. Message from the President IN THIS ISSUE From the Editor’s desk 2 Condolences 4 I trust that all of you have been well this winter. This Tributes time of the year brings sniffles, coughs and colds Abu Fuard 5 and I thought of bringing you some news and Saybhan Samat 6 developments that the OBU has in store to help you A grand Old Lady of Wesley 7 Student loses battle with through those winter blues. 7 cancer Pirncipal’s Report – Prize 8 Those who were able to make it to the Winter Giving 2012 Warm-up in May enjoyed themselves and a Where are they now? 10 successful night was had by all. Over 250 patrons Athula Wickramasinghe attended with a notable presence of alumni and the A tribute to Wilfred & Elna 10 return of old boys that we haven’t seen in some time Wickramasinghe as well as some first timers. The committee was Double Blue Ball 2012 11 most encouraged by the success of the event and we are hoping this is a First Wesleyite to skipper a good precursor to the Annual ‘Double Blue Ball’ to be held on the 6th League Champion Rugby 11 Team – Henry Terrence October 2012. If anyone is still requiring tickets please contact one of the Your Committee committee members listed. Tickets are limited so I would encourage you Membership renewals to hurry! Cedric Oorloff Golf Tournament 12 For those avid golfers or those that prefer army golf (left, right, left, right) Dates for your diary there will be the Annual Cedric Oorloff Golf Tournament between Trinity Snippets of news from College and Wesley College to be held on the 21st October at the Morack Wesley Golf Club (refer page ?). -

Diet Delightfully with "Diet Delight" SATURDAY, AUOBST IS, W61 Page«
*++^^w oxeX. Hi JLHecorde gives ameal Ir Published Bi-Weekly PRICE: 6d. Wednesdays: 1/- Saturdays man-appeal! VOLUME xxxvin HAMILTON. BERMUDA, SATURDAY, AUGUST 5, 1961. No. 2. St.George's Win60th AnnualCup Match _______ m Wz By an Innings and 44 Another change of bowling replace _m - - * ' saw Charles Swan _------------------i-~ *,%^r*-"^ -. ____H____F j~ ' mSmt z- * Runs^^^BSimmons, y two 8_Bk ~__^wfe Mackie after ?:S ';ntw-. ■>■ __M_____m "'_________________ - **-; *: __________________* 1 H. -_-_. -» mmmm A ■<■... 4_. overs, taking the new ball, Mm^* !_B .____P*___. _____■■ "■*■■ I _P- A T_k___* **fc*k H? JpHlS 60th Cup Match can be regarded as the most successful live mimil i s of play, when he ami at the eastern end Daul- one as far as the St. George's Cricket Club is concerned, b» hit Edwards through the phin cam. on for Rremar, and cause of the records which were made and broken, at the ex*** covers for a lioundary four. on Daulpliin's first ball, a sin- _^ cf the Somerset Cricket Club, who went down to a crusimi. George Dyer was caught out :_lt' was scored by James, but defeat, losing by an innings and 44 runs, thereby putting St hy Timmy Kdwards. after the return throw went away George's in the record book as having recorded the tb'rd bigges eighty-four minute^ of flatting. for another single, giving vktory in the history of the series« Inning contributed a personal "lames his century, after two total of 38 runs, and engaging the outstand-Hserved their victory, mown and fifty-seven minutes and at in a t t Z I■ epi I an bird wield stand of of chance-less batting. -

Copy of St-A Ar 2003-04.Pub
St Albans Cricket Club Notice is hereby given that the 100th Annual General Meeting of the St Albans Cricket Club Inc. will be held at Robbie's on Riccarton, Clarence Street (in the private Committee Room) on Monday, 2 August 2004 at 7:30pm Business: 1. To receive the Minutes of the 2003 Annual General Meeting; 2. To consider and adopt the 2003/04 Annual Report and Accounts; 3. Election of Officers and Management Committee for the 2004/05 season; 4. Notice of Motion That the club levy the following levels of subscriptions (GST inclusive) for the 2004/05 season, namely: a) Adult Men and Women: $200 to be paid by 30 November 2004; b) Full-time University, Polytechnic, Training College Students, Men and Women Under 18: $150 to be paid by 30 November 2004; 3 c) Secondary School Pupils: $100 to be paid by 30 November 2004; d) Primary/Intermediate School Pupils: $40 for first member of family, and $10 for any subsequent members of the same family, to be paid by 30 November 2004; e) Social: $50 to be paid upon joining the club. Please note: there have be no increases in these subscription levels from last season. 5. General Business: Members are reminded to resign (in writing) before the date of the AGM, to ensure that no subscription payment is due for the 2004/05 season, in the event of any member deciding not to play or transferring to another club, or moving out of the city. A light supper will be provided by the club at the conclusion of the AGM. -

MB Permuba Eecorbtx 'Vmm Man-Oi Ea/! CH* Published Bi-Weekly PRICE: 6D
0X0 givesameal MB permuba Eecorbtx 'vmm man-Oi ea/! CH* Published Bi-Weekly PRICE: 6d. Wednesdays: 1/- Saturda HAMILTON, SATURDAY, JUNE 23, 1962 No. 89. volume xxxvm BERMUDA — " ** M.C.P.s Give B.U.T. Bermuda Girls Sweep Honours :1^ ~7.' "~~~ Wk ~**. At Washington Business College on Education "W ■I¥W:$W Views pOUR Bermudians were members of the graduating class of Wawaw **3m Cortez Peters Business College in Washington, D.C. this T"*WO members of Parliament, Sir John Cox and Mr. A. E. month. One of them, Miss Brenda Zuill, daughter of Mr. and Nicholl, who respectively were chairman and deputy chair- Mrs. Eugene Zuill of West Side^ Somerset Bridge, received -a » man of the Board of Education for a number of years, were &old medallion, symbolic of her being the best female typist m— am u Tuesday the first of a new series bf educational at the famed institution. ■ speakers last at """rlr meetings being sponsored by the Bermuda Union of Teachers Zuill, college less than two years, ...... Miss a former student «,.»*.,.""" A Institute, per- were 80 and 75 net The meeting was held in the prevented wastage of time and of the Berkeley in the words a minute group. Room of St. Paul's effort where, even with the fected a typing speed of 100 Both L-ecture straight Were at Church, Miss children could not words a minute copy. former students Pros- A.M.E. Hamilton. best efforts pect Secondary Hodgson, president of the learn She is listed in the year book School. Eva outstanding College " B.U.T., was chairman and a from as "the most non- The whieh takes the That final comment to at- name of its famous founder group of teach immigrant student ever representative Mr. -

2007/08 Annual Report and Accounts;
St Albans Cricket Club Notice is hereby given that the 104th Annual General Meeting of the St Albans Cricket Club Inc. will be held at Trevinos Restaurant and Bar, cnr Riccarton Road and Mona Vale Avenue (in the upstairs conference room, access at rear) on Monday, 4 August 2008 at 7:30pm Business: 1. To receive the Minutes of the 2007 Annual General Meeting; 2. To consider and adopt the 2007/08 Annual Report and Accounts; 3. Election of Officers and Management Committee for the 2008/09 season; 4. Notice of Motion That the club levy the following levels of subscriptions (GST inclusive) for the 2008/09 season, namely: a) Adult Men and Women: $240 to be paid by 30 November 2008; b) Full-time University, Polytechnic, Training College Students, Men and Women Under 18: $180 to be paid by 30 November 2008; 3 c) Secondary School Pupils: $120 to be paid by 30 November 2008; d) Primary/Intermediate School Pupils: $50 for first member of family, and $25 for any subsequent members of the same family, to be paid by 30 November 2008; e) Social: $60 per year. Please note: there have been no increases in these subscription levels from last season. 5. General Business: Members are reminded to resign (in writing) before the date of the AGM, to ensure that no subscription payment is due for the 2008/09 season, in the event of any member deciding not to play or transferring to another club, or moving out of the city. Honorary Secretary PO Box 1919 CHRISTCHURCH Pavilion: Hagley Oval, South Hagley Park, Riccarton Ave, Christchurch, New Zealand. -
2008/09 Annual Report and Accounts;
St Albans Cricket Club ANNUAL REPORT SStt AAlbanslbans CricketCricket ClubClub 2008-2009 Winners • Premier Men - Two Day Title • 3A Men • Premier Men - One Day Title • 3C Men • 2A Men - Two Day Title • 1st Grade Women • 2C Men - Two Day Title • 2nd Grade Women • Petersen Shield and Financial Statement for 2008 - 2009 St Albans Cricket Club Notice is hereby given that the 105th Annual General Meeting of the St Albans Cricket Club Inc. will be held at SoHo Restaurant and Bar, 1 Riccarton Road (on the Deans Ave roundabout) on Monday, 3 August 2009 at 7:30pm Business: 1. To receive the Minutes of the 2008 Annual General Meeting; 2. To consider and adopt the 2008/09 Annual Report and Accounts; 3. Election of Officers and Management Committee for the 2009/10 season; 4. Notice of Motion That the club levy the following levels of subscriptions (GST inclusive) for the 2009/10 season, namely: a) Adult Men and Women: $240 to be paid by 30 November 2009; b) Full-time University, Polytechnic, Training College Students, Men and Women Under 18: $180 to be paid by 30 November 2009; 3 c) Secondary School Pupils: $120 to be paid by 30 November 2009; d) Primary/Intermediate School Pupils: $60 for first member of family, and $30 for any subsequent members of the same family, to be paid by 30 November 2009; e) MILO Module: $40 for first member of family, and $20 for any subsequent members of the same family, to be paid by 30 November 2009; f) Social: $60 per year. Please note: there have been no increases in adult subscription levels from last season. -

17-Media World Cup 1973-2013
WOMEN'S CRICKET WORLD CUP 2017 ENGLAND (INCLUDES SUMMARY OF ALL ONE DAY INTERNATIONAL (STATISTICS 1973-2013) COMPILED BY: Marion R.Collin Hon Statistician I. C.C. and E.C.B. W.C.A. Statistics Programme Version 7.07 (S) (C) Gordon Vince 1989-2006 1 WOMEN'S CRICKET MEDIA PACK CONTENTS ALL ONE INNINGS MATCHES Table of Results 1973to 29/11/2016 Team Records Individual Records Batting Records All Player Partnership Records Bowling Records All Round Records Wicketkeeping and Fielding Records PAGES 3-22 WORLD CUP MATCHES Table of Results 1973-20013 Team Records Individual Records Batting Records All Player Partnership Records Bowling Records All Round Records Wicketkeeping and Fielding Records PAGES 23-29 AUSTRALIA World Cup Team Records PAGES 30-33 Individual Records Batting Records Australia Partnership Records Bowling Records All Round Records Wicketkeeping and Fielding Records Batting and Bowling Averages to 17/02/2013 PAGES 34-37 ENGLAND World Cup Team Records PAGES 38-41 Individual Records Batting Records England Partnership Records Bowling Records All Round Records Wicketkeeping and Fielding Records Batting and Bowling Averages to 17/02/2013 PAGES 42-45 INDIA World Cup Team Records PAGES 46-49 Individual Records Batting Records India Partnership Records Bowling Records All Round Records Wicketkeeping and Fielding Records Batting and Bowling Averages to 17/02/2013 PAGES 50-53 2 WOMEN'S CRICKET MEDIA PACK CONTENTS NEW ZEALAND World Cup Team Records PAGES 54-57 Individual Records Batting Records New Zealand Partnership Records Bowling Records -

Headmaster's Letter
The 2019 MERCHISTONIAN Headmaster’s Letter It is with great pleasure to and memorable event and a great here, the rewards are there to enjoy. introduce this year’s example of the strong bonds that the Merchiston community shares. Challenging - in the most positive Merchistonian magazine - it is possible sense. Merchiston is a School of very hard to believe that it On the sports field, we have had yet proud tradition and the challenge to all has been a year since I wrote another stunning year of success; of us that hold the School in such high personal highlights include our U18 regards is to ensure that continues. my very first introduction; Tennis Team winning back-to-back time certainly flies when you national titles, our Rugby Fives players Seriously Enjoyable - I return to enjoyment; it is such a key aspect of are enjoying yourself! winning two national titles in one year (doubling our previous total of titles in what we want our pupils to experience My first year at Merchiston has been one one visit!) and of course, our 1XV and I am pleased that I have been able of great enjoyment; getting to know the winning the Scottish Schools’ Cup for to share that feeling. pupils and their families, colleagues, and a record sixth time. Watching the team I am immensely proud of the many and of course, the many Merchistonians and play such fast paced and skilful rugby varied contributions by every pupil and Friends of Merchiston all over the world. through the mist of a cold December member of staff to this School.