A Comparison of Selected Bibliographic Database Search Retrieval for Agricultural Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CAB Direct Help V1.0
® CAB Direct Help v1.0 User Guide © 2016 CABI by CABI 2 CAB Direct User Guide version 1.0 by CABI Welcome to the CAB Direct user guide. This guide contains similar content to the online help, which is available on the CAB Direct interface from the help icons. CAB Direct Help v1.0 © 2016 CABI Table of Contents 3 1. Getting Started 6 1.1 Signing in and out ......................................................................................................... 7 1.2 Searching Overview ....................................................................................................... 8 2. Keyword Searching 9 2.1 Word Stemming ........................................................................................................... 10 2.2 Search Rules ................................................................................................................. 11 2.3 Preferred terms ............................................................................................................ 12 2.4 Boolean Operators ...................................................................................................... 12 2.5 Using Multiple Operators ............................................................................................ 13 3. Advanced searching 15 3.1 Field searching ............................................................................................................. 17 3.1.1 Article title ............................................................................................................. 18 3.1.2 -

Air Pollution
GLOBAL HEALTH HOT TOPIC: Air Pollution Air pollution and air quality is causing concern in both the developed and developing world, exacerbating respiratory and cardiovascular diseases, and linked to infant mortality. The introduction of chemicals, particulates, and biological matter into the atmosphere negatively changes indoor and outdoor air quality. CABI’s Global Health database enables the work of researchers, practitioners and trainers at leading public health schools including the universities of Oxford (UK), Yale (USA), and Association of Medical Schools – ASCOFAME (Columbia). CABI’s Global Health database comprehensively covers hot topics that matter Global Health covers environmental and public health sources to provide the complete picture on causes of air pollution, its impact on human health and its mitigation, including information on: • Household air pollution from biomass fuels: traditional • Poverty and air toxins: socioeconomic status and the cooking practices expose women and children to unhealthy disproportional affect by air pollution. pollutants; collecting fuel limits time for education. Better fuels Children’s exposure to nitrogen dioxide in Sweden: and stoves will help meet sustainable development goals. investigating environmental injustice in an egalitarian country Perceptions of rural females on their performance with Journal of Epidemiology & Community Health 2006 upgraded stoves in a Peruvian community Revista Cubana de Salud Pública 2014 Death of a Mwana: biomass fuels, poverty, gender and climate change -

Advanced Searching of CABCD
zzz CABI Training Materials CAB Direct Advanced Searching of Global Health www.cabi.org KNOWLEDGE FOR LIFE Contents Why use Advanced Search Features ................................................................................. 3 Field Searching .................................................................................................................. 4 Title Fields ......................................................................................................................... 7 Author Fields ............................................................................................................... 7 I. Personal Authors .................................................................................................. 7 II. Corporate Authors ............................................................................................... 9 Index Terms or “Descriptors” ........................................................................................... 10 CABICODES .................................................................................................................... 13 The CAB Thesaurus: ....................................................................................................... 15 Subject Codes Field ......................................................................................................... 20 Search Limits ................................................................................................................... 22 Additional Search Fields ................................................................................................. -

Global Health Database Detailed Coverage
Global Health database Detailed coverage Public health Community health Patterns of disease, health inequalities, health determinants, health indicators in a defined geographical area or in particular groups of the population. Community based interventions to promote health. Community participation in health interventions. Neighbourhood effects on health e.g. effects of environment, traffic, housing, pollution, poverty, cultural attitudes. Social medicine and behaviour Relationships between health, disease and social conditions including: causes and patterns of disease, social health Determinants and causes of health inequality e.g. socioeconomic status, education, housing, ethnicity, gender. Substance abuse including tobacco, alcohol, behavioural patterns and behaviour change, influences on behaviour such as advertising, health campaigns, partner violence and injury. Rural health Health and disease patterns in rural populations. Health promotion and disease prevention activities. Access to health care and provision of health services. Occupational health and safety of farming and rural occupations such as forestry. Pesticide safety and poisoning, as well as general farm safety. Refugee, migrant and indigenous health Epidemiology, prevalence and incidence of infectious and non-communicable diseases, diet and nutritional status, health services for refugees including access to and uptake of healthcare, emergency medicine. Cultural attitudes to care. Healthy ageing Changing patterns of disease associated with ageing, disease/injury epidemiology -

Community-Based Governance
CAB ABSTRACTS HOT TOPIC: Community-based governance Given the Brexit and Trump votes of 2016 the importance of engaging the disenfranchised amid rising populism and discrimination is more important than ever. Community-based governance if supported by a social involvement process that includes all population groups, and that has the appropriate technical and institutional support, can be one way to do this. People need to feel as if they have a stake in the existing order, and that their grievances can be resolved through political means. CABI’s CAB Abstracts database covers the world literature on the effects and impacts of governance on communities’ structures and livelihoods, and is strong on coverage of research in the developing world where community-based governance plays an important part in natural resource management and stewardship in particular. CABI’s CAB Abstracts database comprehensively covers hot topics that matter CAB Abstracts covers agricultural, environmental, social and economic sources to provide the complete picture on the effects of community-based governance including information on: • Natural resource management: Effects of governance forms • Tourism development: How can good governance help on the management of the environment, natural resources, sustainable tourism development? What are the political land, common property resources challenges? ‘Raising the bar’: the role of institutional frameworks for The influence of the political environment and destination community engagement in Australian natural resource governance on sustainable tourism development: a study of governance. Bled, Slovenia. Journal of Rural Studies, 2017 Journal of Sustainable Tourism, 2016 ‘Traditional peoples’ and the struggle for inclusive land • Gender equality: Can community governance help reverse governance in Brazil. -

Specialist Bibliographic Databases
SPECIAL ARTICLE Editing, Writing & Publishing http://dx.doi.org/10.3346/jkms.2016.31.5.660 • J Korean Med Sci 2016; 31: 660-673 Specialist Bibliographic Databases Armen Yuri Gasparyan,1 Specialist bibliographic databases offer essential online tools for researchers and authors Marlen Yessirkepov,2 who work on specific subjects and perform comprehensive and systematic syntheses of Alexander A. Voronov,3 evidence. This article presents examples of the established specialist databases, which may Vladimir I. Trukhachev,4 be of interest to those engaged in multidisciplinary science communication. Access to most 5 6 Elena I. Kostyukova, Alexey N. Gerasimov, specialist databases is through subscription schemes and membership in professional 1,7 and George D. Kitas associations. Several aggregators of information and database vendors, such as EBSCOhost 1Departments of Rheumatology and Research and and ProQuest, facilitate advanced searches supported by specialist keyword thesauri. Development, Dudley Group NHS Foundation Trust Searches of items through specialist databases are complementary to those through (Teaching Trust of the University of Birmingham, multidisciplinary research platforms, such as PubMed, Web of Science, and Google UK), Russells Hall Hospital, Dudley, West Midlands, Scholar. Familiarizing with the functional characteristics of biomedical and nonbiomedical UK; 2Department of Biochemistry, Biology and Microbiology, South Kazakhstan State bibliographic search tools is mandatory for researchers, authors, editors, and publishers. Pharmaceutical Academy, Shymkent, Kazakhstan; The database users are offered updates of the indexed journal lists, abstracts, author 3Department of Marketing and Trade Deals, Kuban profiles, and links to other metadata. Editors and publishers may find particularly useful State University, Krasnodar, Russian Federation; source selection criteria and apply for coverage of their peer-reviewed journals and grey 4Department of Technological Management, Stavropol State Agrarian University, Stavropol, literature sources. -

A Protocol for a Systematic Literature Review: Comparing the Impact Of
Bishop-Williams et al. Systematic Reviews (2017) 6:19 DOI 10.1186/s13643-016-0399-x PROTOCOL Open Access A protocol for a systematic literature review: comparing the impact of seasonal and meteorological parameters on acute respiratory infections in Indigenous and non-Indigenous peoples Katherine E. Bishop-Williams1*, Jan M. Sargeant1,2, Lea Berrang-Ford3, Victoria L. Edge1, Ashlee Cunsolo4 and Sherilee L. Harper1 Abstract Background: Acute respiratory infections (ARI) are a leading cause of morbidity and mortality globally, and are often linked to seasonal and/or meteorological conditions. Globally, Indigenous peoples may experience a different burden of ARI compared to non-Indigenous peoples. This protocol outlines our process for conducting a systematic review to investigate whether associations between ARI and seasonal or meteorological parameters differ between Indigenous and non-Indigenous groups residing in the same geographical region. Methodology: AsearchstringwillbeusedtosearchPubMed®, CAB Abstracts/CAB Direct©, and Science Citation Index® aggregator databases. Articles will be screened using inclusion/exclusion criteria applied first at the title and abstract level, and then at the full article level by two independent reviewers. Articles maintained after full article screening will undergo risk of bias assessment and data will be extracted. Heterogeneity tests, meta-analysis, and forest and funnel plots will be used to synthesize the results of eligible studies. Discussion and registration: This protocol paper describes our systematic review methods to identify and analyze relevant ARI, season, and meteorological literature with robust reporting. The results are intended to improve our understanding of potential associations between seasonal and meteorological parameters and ARI and, if identified, whether this association varies by place, population, or other characteristics. -

Strategies to Improve Treatment Coverage in Community-Based Public Health Programs: a Systematic Review of the Literature
RESEARCH ARTICLE Strategies to improve treatment coverage in community-based public health programs: A systematic review of the literature Katrina V. Deardorff1☯*, Arianna Rubin Means1,2☯, Kristjana H. A sbjoÈrnsdo ttir1,2☯, Judd Walson1,2,3☯ 1 Department of Global Health, University of Washington, Seattle, Washington, United States of America, 2 DeWorm3, Natural History Museum, London, United Kingdom, 3 Departments of Medicine, Pediatrics, and Epidemiology, University of Washington, Seattle, Washington, United States of America a1111111111 a1111111111 ☯ These authors contributed equally to this work. a1111111111 * [email protected] a1111111111 a1111111111 Abstract OPEN ACCESS Background Citation: Deardorff KV, Rubin Means A, Community-based public health campaigns, such as those used in mass deworming, AÂsbjoÈrnsdoÂttir KH, Walson J (2018) Strategies to vitamin A supplementation and child immunization programs, provide key healthcare inter- improve treatment coverage in community-based ventions to targeted populations at scale. However, these programs often fall short of estab- public health programs: A systematic review of the lished coverage targets. The purpose of this systematic review was to evaluate the impact literature. PLoS Negl Trop Dis 12(2): e0006211. https://doi.org/10.1371/journal.pntd.0006211 of strategies used to increase treatment coverage in community-based public health campaigns. Editor: Rachel L. Pullan, London School of Hygiene and Tropical Medicine, UNITED KINGDOM Methodology/ principal findings Received: July 7, 2017 We systematically searched CAB Direct, Embase, and PubMed archives for studies utilizing Accepted: January 4, 2018 specific interventions to increase coverage of community-based distribution of drugs, vac- Published: February 8, 2018 cines, or other public health services. We identified 5,637 articles, from which 79 full texts Copyright: © 2018 Deardorff et al. -

The Impact of Land Use and Cover Change
Syampungani et al. Environmental Evidence 2014, 3:25 http://www.environmentalevidencejournal.org/content/3/1/25 SYSTEMATIC REVIEW PROTOCOL Open Access The impact of land use and cover change on above and below-ground carbon stocks of the miombo woodlands since the 1950s: a systematic review protocol Stephen Syampungani1*, Jessica Clendenning2, Davison Gumbo3, Robert Nasi2, Kaala Moombe3, Paxie Chirwa4, Natasha Ribeiro5, Isla Grundy6, Nalukui Matakala1, Christopher Martius2, Moka Kaliwile3, Gillian Kabwe1 and Gillian Petrokofsky7 Abstract Background: Increasingly, forests are on the international climate change agenda as land use and cover changes drive forest and carbon loss. The ability of forests to store carbon has created programs such as Reducing Emissions from Deforestation and Degradation plus (REDD+), in order to provide incentives for particular land uses and forest management practices. A critical element to REDD+ is the ability to know the carbon-storage potential of an ecosystem, and the factors likely to affect the rate of carbon accumulation or the maximum amount stored. Most REDD+ initiatives have focused on humid tropical forests because of their large stocks per unit area. Less attention has been paid to the carbon-storage potential of tropical dry forests, woodlands and savannas. Although these ecosystems support a lower biomass per unit area, they are more widespread than humid forests. This proposed systematic review examines miombo woodlands, which are the most extensive vegetation formation in Africa and support over 100 million people. We ask: To what extent have changes in land use and land cover influenced above- and below-ground carbon stocks of miombo woodlands since the 1950s? Methods: We will search systematically for studies that document the influence of land use and cover change on above and below ground carbon in miombo woodlands since the 1950s. -
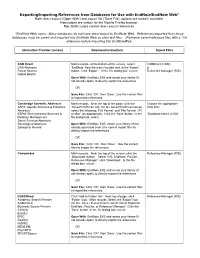
Exporting/Importing References From
Exporting/Importing References from Databases for Use with EndNote/EndNote Web* Both direct export (‘Open With’) and export file (‘Save File’) options are noted if available. Instructions are written for the Mozilla Firefox browser. Mac Safari users cannot direct export references . *EndNote Web users: Many databases do not have direct export to EndNote Web. References exported from those databases must be saved and imported into EndNote Web as plain text files. (Re)name saved reference files with a *.txt extension before importing into EndNoteWeb. Information Provider (vendor) Download instructions Import Filter CAB Direct Mark records. At the bottom of the screen, select CABDirect (CABI) CAB Abstracts ‘EndNote’ from the menu located next to the ‘Export’ or Forest Science button. Click ‘Export’. In the file dialog box, select: Reference Manager (RIS) Global Health Open With : EndNote.EXE and locate your library (if not already open) to directly export the references. OR Save File: Click ‘OK’, then ‘Save’. Use the correct filter to import the references. Cambridge Scientific Abstracts Mark records. Near the top of the page, click the Choose the appropriate ASFA: Aquatic Sciences & Fisheries ‘Save/Print/Email’ link. On the Save/Print/Email screen, CSA filter: Abstracts select the following: ‘Full Format’ and ‘File Format : PC ESPM: Environmental Sciences & or Mac’ (as appropriate). Click the 'Save' button. In the “Database Name (CSA)” Pollution Management file dialog box, select: Social Services Abstracts Sociological Abstracts Open With : EndNote.EXE, locate your library (if not Zoological Record already open)and select the correct import filter to directly export the references. OR Save File: Click ‘OK’, then ‘Save’. -

Scoping Review of Microplastics in Marine Mammals 1 1 2 1 Author(S) Garudadri, P.A
Protocol for a scoping/systematic review: Scoping Review of Microplastics in Marine Mammals 1 1 2 1 Author(s) Garudadri, P.A. , Lang, J. , Fausak, E.D. , Gjeltema, J. Dept/School: 1 V eterinary Medicine & Epidemiology, UC Davis School of Veterinary Medicine 2 U niversity Library, UC Davis Correspondence: Prathima Garudadri, [email protected] Author contributions: - Prathima Garudadri is the guarantor, Jackelyn Lang and Jenessa Gjeltema will contribute to risk of bias and selection criteria, Erik Fausak will help develop the search strategy. Abstract: Background: Pollution of the environment by microplastics is a growing global concern. Microplastics are plastic particles smaller than 5mm that come from a wide variety of sources including physical breakdown of larger plastics into smaller pieces over time in the environment as well as from direct production of small plastic pieces for use in cosmetics, toy fillings, cleaning agents, and many industrial processes. Recent studies have documented the presence of microplastics in wild animal and human stool samples (Liebmann 2018) as well as food, posing a potential human and environmental health risk. Marine mammals have been suggested as a potential indicator species for the amount of microplastics present in marine environments (Perez-Venegas, 2018). The few studies that have looked into the presence of microplastics in marine mammals have primarily looked for larger particle sizes, studied animals in captivity, and used acid digestion methods that likely deteriorated plastics of certain polymer types. In this review, we will explore the available literature to determine what we currently know about microplastic pollution in marine environments used by marine mammals, its effect on the health of marine mammals, and help direct future research into this topic. -

Pilot SER Discussion Questions
Systematic Review Pilot Project: Final Report February, 2008 Prepared by: Institute for Natural Resources 210 Strand Ag Hall Oregon State University Corvallis, Oregon 97331 Table of Contents Executive Summary ...................................................................................................................................... 2 Key findings .............................................................................................................................................. 2 1. Purpose of this document ........................................................................................................................ 7 2. Introduction ............................................................................................................................................. 7 3. Background .............................................................................................................................................. 7 4. Project description ................................................................................................................................... 9 5. Review process ......................................................................................................................................... 9 5a. Question development ....................................................................................................................... 9 5b. Recruitment of expert reviewers ...................................................................................................