Research Topics in Software Evolution and Maintenance
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Ansys SCADE Lifecycle®
EMBEDDED SOFTWARE Ansys SCADE LifeCycle® SCADE LifeCycle is part of the Ansys Embedded Software family of products and solutions that includes modules providing unique support for application lifecycle management. This product line features requirements traceability via Application Lifecycle Management (ALM) tools, traceability from models, configuration and change management, and automatic documentation generation. SCADE LifeCycle enhances the functionalities of Ansys SCADE® tools with add-on modules that bridge SCADE solutions and Requirement Management tools or PLM/ALM (Product Lifecycle Management/ Application Lifecycle Management) tools. With SCADE LifeCycle, all systems and software teams involved in critical applications development can manage and control their design and verification activities across the full life cycle of their SCADE applications. / Requirements Traceability SCADE LifeCycle Application Lifecycle Management (ALM) Gateway provides an integrated traceability analysis solution for safety-critical design processes with SCADE Architect, SCADE Suite, SCADE Display, SCADE Solutions for ARINC 661 and SCADE Test: • Connection to ALM tools: linkage to DOORS NG, DOORS (9.6 and up) Jama Connect, Siemens Polarion, Dassault Systèmes Reqtify 2016. • Graphical creation of traceability links between requirements or other structured documents and SCADE models. • Traceability of test cases from SCADE Test Environment projects. • Bidirectional navigation across requirements and tests. • Customizable Export of SCADE artifacts to DOORS or Jama Connect. • Compliant with DO-178B, DO-178C, EN 50128, IEC 61508, ISO 26262, and IEC 60880 standards. EMBEDDED SOFTWARE / SCADE LifeCycle® // 1 / Project Documentation Generation SCADE LifeCycle Reporter automates the time-consuming creation of detailed and complete reports from SCADE Suite, SCADE Display, SCADE Architect and SCADE UA Page Creator for ARINC 661 designs through: • Generation of reports in RTF or HTML formats. -

Configuration Management for Distributed Development
Software Configuration Management Configuration Management for Distributed Development By Nina Rajkumar. © Think Business Networks Pvt. Ltd., July 2001 All rights reserved. You may make one attributed copy of this material for your own personal use. For additional information or assistance please contact Nina at (+91)422-320-606. www.thinkbn.com • 697A, Trichy Road, Coimbatore, TN 641045. Table of Contents Configuration Management for Distributed Development.............................. 4 Configuration Management ................................................................................ 5 Distributed Development.................................................................................... 5 Cases of Distributed Development ..................................................................... 6 Distance Working ........................................................................................... 6 Outsourcing..................................................................................................... 6 Co-located Groups .......................................................................................... 7 Distributed Groups.......................................................................................... 7 Architecture ........................................................................................................ 8 Remote Login.................................................................................................. 8 Several sites by Master-Slave connections .................................................... -

Comparative Study on Agile Software Development Methodologies
Global Journal of Computer Science and Technology Software & Data Engineering Volume 13 Issue 7 Version 1.0 Year 2013 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc. (USA) Online ISSN: 0975-4172 & Print ISSN: 0975-4350 Comparative Study on Agile Software Development Method- ologies By A B M Moniruzzaman & Dr. Syed Akhter Hossain Daffodil International University, Bangladesh Abstract - Today‘s business environment is very much dynamic, and organizations are constantly changing their software requirements to adjust with new environment. They also demand for fast delivery of software products as well as for accepting changing requirements. In this aspect, traditional plan-driven developments fail to meet up these requirements. Though traditional software development methodologies, such as life cycle-based structured and object oriented approaches, continue to dominate the systems development few decades and much research has done in traditional methodologies, Agile software development brings its own set of novel challenges that must be addressed to satisfy the customer through early and continuous delivery of the valuable software. It‘s a set of software development methods based on iterative and incremental development process, where requirements and development evolve through collaboration between self-organizing, cross-functional teams that allows rapid delivery of high quality software to meet customer needs and also accommodate changes in the requirements. In this paper, we significantly indentify and describe the major factors, that Agile development approach improves software development process to meet the rapid changing business environments. We also provide a brief comparison of agile development methodologies with traditional systems development methodologies, and discuss current state of adopting agile methodologies. -
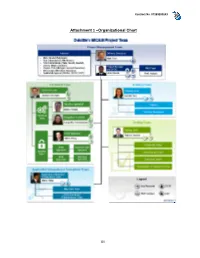
85 Attachment 1 –Organizational Chart
Contract No. 071B3200143 Attachment 1 –Organizational Chart 85 Contract No. 071B3200143 Appendix A - Breakdown of Hardware and Related Software Table 1: Hardware Cost ($): State Brand, Model # Item Specifications will provide from Comments and Description existing Contracts Total # of Virtual The hardware is Machines: 48 sized for Production, QA/Staging, Secure-24 VMware Total # of Virtual Development, and Cluster Access for CPUs: 96 Sandbox Server deploying ISIM, environments in the ISAM and ISFIM Total Virtual RAM: primary data center components 416 GB and for Production, and QA environments in the OS: RedHat Linux secondary data 6.x center The total storage is estimated for Total Storage: 35.7 Production, , TB QA/Staging, Development and Enterprise Class Sandbox Storage (3.8TB of Bronze SAN Storage Tier, 15.8TB of environments in the Silver Tier, 5.1TB of primary data center Logs Tier, 11TB of and for Production, Gold Tier) QA environments in the secondary data center CD/DVD Backup Device None None Rack w/ Power Supply Rack mountable Redundant Power Screen None None A total of 10 Web Gateway appliances are estimated for Production, QA/Staging, Web Gateway Development and Any other Hardware (list) v7.0 Hardware Appliance Sandbox environments in the primary data center and for Production, QA environments in the secondary data center. TOTAL $ 86 Contract No. 071B3200143 Table 2: Related Software Software Component Product Name Cost ($): State # of Licenses Comments License and Version will provide from existing Contracts Contractor user laptops already include this software. We will reuse the Report writers MS Office 2010 State owned software State of Michigan user licenses laptops will need this software for up to 4 users. -

Using Visual COBOL in Modern Application Development Micro Focus the Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK
Using Visual COBOL in Modern Application Development Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 2018-2020 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Visual COBOL are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2020-08-25 ii Contents Using Visual COBOL in Modern Application Development ........................... 4 Introduction to Modern Application Development ................................................................4 What is Modern Application Development? ..............................................................4 Key Concepts in Modern Application Development ..................................................5 Steps Involved in Modern Application Development ................................................ 6 Agile Methods ..................................................................................................................... 7 Introduction to Agile Methods ...................................................................................7 Agile Development Workflow ....................................................................................7 Agile Development and Micro Focus Development Tools .........................................9 Continuous Integration ...................................................................................................... 11 Introduction to Continuous Integration .................................................................. -

Revision Control Solutions to Protect Your Documents and Track Workflow
Revision Control Solutions to Protect Your Documents and Track Workflow WHITE PAPER Contents Overview 3 Common Revision Control Systems 4 Revision Control Systems 4 Using BarTender with Revision Control Systems 4 Limitations of Windows Security 5 Librarian 6 Librarian Features 6 Benefits of Using Librarian with BarTender 7 File States, Publishing and Workflow in Librarian 8 Don’t Forget About Security! 9 Related Documentation 10 Overview A revision control system is based around the concept of tracking changes that happen within directories or files, and preventing one user from overwriting the work of another. Some revision control systems are also used to establish and track workflow for the progression of a file through a series of states. The collection of files or directories in a revision control system are usually called a repository. These systems allow you to specify a directory, file or group of files that will have their changes tracked. This frequently entails users "checking out" and "checking in" files from a repository. Changes are tracked as the user edits the folder or file; these changes will be visible to all users once the item is checked back in. Each revision is annotated with a timestamp and the person making the change. Some of the benefits of revision control include: l Automatic revision numbering for easy tracking. l Enhanced security. Not only does a "check in" and "check out" system keep one user's work from overwriting another, it can prevent unauthorized or even malicious users from accessing a document. l Some revision control systems include publishing "states," which allow you to track the publishing progress of a document and establish a logical, traceable workflow. -

Disciplined Agile
Disciplined Agile Jas Madhur and Scott Ambler Presentation for PMI Luxembourg November 22nd, 2016 - Chambre des Metiers, Kirchberg #pmiluxagile Agenda • Part 1 – Jas Madhur (Luxembourg) • Part 2 – Plan A - Scott Ambler (Toronto) • Part 2 – Plan B – Slides. No refunds. Free event. Even food! Sponsors. • agilepartner • Since 2004 architecting agile information systems • Don’t worry be AP! • Lux – Advisory • Since 2009 consulting company specialising in organisation and strategy Questions and comments use #pmiluxagile Part 1 - Jas Madhur – Who am I? • PMI Luxembourg – Director of Finance … 2017 + Sponsorship • Agile Practitioner / Methodologist • 1993 Iterative/Object Oriented Development (Canadian Air Traffic System) • 1997 Rational Unified Process (RUP) Development Team (IBM Rational Software) • 2004 Agile Vancouver – Dr.Philippe Kruchten • 2008 Agile Toronto – Scott Ambler • 2011 Luxembourg • AZUR ERP for Health Insurance Companies • SMEs • Agile RUP (Matisse) • PM / PMO • Write proposals and submit tenders EU institutions at infeurope • jasmadhur.blogspot.com - @jmadhur Who are you? Why are we here? • Audience • IT Project Managers • HR • Curious about what is all this ‘AGILE’ noise is about? • Know • Agile. Like teenage romance. Rampant and variable. Great experts. Let’s hope it’s safe. • Patterns and anti-patterns of agile and agility. • Do • How could the agile approach be useful throughout your organization? • Think • Being agile stimulates evolution and innovation. • Feel • Being agile and adaptive is engrained in our DNA. • It’s natural. The Context • Software/Systems Engineering • 1 Dimensional .. Waterfall .. DoD Mil-Spec 2167a • 2 Dimensional .. Iterative .. IBM Rational Unified Process (RUP) (1996) • Market Pressures of the “Internet Economy” • Small Teams • The Agile Movement • Rapid Delivery and Innovation • A Balanced Reliable Approach • Disciplined Agile DoD Mil-Spec 2167a (1989) Hardware (HW) Computer Software (CS) Unit (U) Component (C) Configuration Item (CI) Baselines WATERFALL 1. -

Git for the ASP.NET Programmer
git for the ASP.NET Programmer Paul Litwin Fred Hutchinson Cancer Research Center [email protected] @plitwin Slides & samples can be found here… • http://tinyurl.com/DevInt2015Oct Litwin Git for the ASP.NET Programmer 2 Session Itinerary • Why distributed version control? • git basics • Command line git • Using git from VS Code • Using git from Visual Studio • Branching and merging • Wrap up Litwin Git for the ASP.NET Programmer 3 Why distributed version control? Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency Created by Linux creator, Linus Torvalds Litwin Git for the ASP.NET Programmer 5 The name git? “I'm an egotistical bastard, and I name all my projects after myself. First Linux, now git.” Linus Torvalds quote from 2007 Litwin Git for the ASP.NET Programmer 6 Centralized Version Control One repository using a client-server model Litwin Git for the ASP.NET Programmer 7 Distributed Version Control Many repositories using peer to peer model Litwin Git for the ASP.NET Programmer 8 Comparing centralized (tfs) vs distributed (git) Attribute Centralized Distributed TFS, SVN, PVCS git, Mercurial Repositories 1 Many Model Client-server Peer-to-peer Speed of common Slower Fast against local repo operations Redundancy of system None; single point of Redundancy built in failure Offline work More difficult Easy Merging of changes When you check When you sync changes changes in (push/pull) Litwin Git for the ASP.NET Programmer 9 git Basics -

TIBCO Designer User's Guide
TIBCO Designer™ User’s Guide Software Release 5.10 August 2015 Two-Second Advantage® Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE. USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME. This document contains confidential information that is subject to U.S. and international copyright laws and treaties. No part of this document may be reproduced in any form without the written authorization of TIBCO Software Inc. TIBCO, Two-Second Advantage, TIBCO Hawk, TIBCO Rendezvous, TIBCO Runtime Agent, TIBCO ActiveMatrix BusinessWorks, TIBCO Administrator, TIBCO Designer, TIBCO ActiveMatrix Service Gateway, TIBCO BusinessEvents, TIBCO BusinessConnect, and TIBCO BusinessConnect Trading Community Management are either registered trademarks or trademarks of TIBCO Software Inc. -

Disciplined Agile Delivery Enterprise Transformation Coach Helping to Create Agile and Lean Enterprises Around the World
Governance, Phases, and Milestones are not Agile Dirty Words! Mark Lines, Scott Ambler + Associates Co-creator of Disciplined Agile Delivery Enterprise Transformation Coach Helping to create Agile and Lean enterprises around the world @Mark_Lines © Scott Ambler + Associates 1 DAD Has Caught On! - Organizations using Disciplined Agile Delivery (DAD) © Scott Ambler + Associates 2 Disciplined Agile Delivery (DAD) is a process decision framework The key characteristics of DAD: – People-first – Goal-driven – Hybrid agile – Learning-oriented – Full delivery lifecycle – Solution focused – Risk-value lifecycle – Enterprise aware © Scott Ambler + Associates 3 DAD is a Hybrid Framework SAFe DevOps …and more Outside In Dev. “Traditional” Agile Data Extreme Unified Process Agile Modeling Programming Scrum Kanban Lean DAD leverages proven strategies from several sources, providing a decision framework to guide your adoption and tailoring of them in a context-driven manner. © Scott Ambler + Associates 4 DAD is Goal-Driven, Not Prescriptive © Scott Ambler + Associates 5 © Scott Ambler + Associates 6 Functional Requirements: Potential Model Types Usage Domain Epic/User Story Domain/Conceptual Model Persona Logical Data Model (LDM) Usage Scenario UML Class Diagram Story Mapping UML Component Diagram UML Use Case Diagram User Interface (UI) Process Value Stream Map UI Flow Diagram Business Process Model UI Prototype (Low Fidelity) Data Flow Diagram (DFD) UI Prototype (High Fidelity) Flow Chart UI Specification UML Activity Diagram UML State Chart General -

Quality in an Agile World Software
TALKING POINTS Quality is an inherent aspect of true agile software development. The majority of agilists take a test-driven approach to development where they write a unit test Quality in an before they write the domain code to fulfill that unit test, with the end result being that they have a regression unit test suite at all Agile World times. They also consider acceptance tests as first-class requirements artifact, not only promoting regular stakeholder validation of BY SCOTT AMBLER their work but also their active inclusion in Ambysoft, Inc. the modeling effort itself. Agilists refactor their source code and database schema to keep their work at the highest possible qual- ity at all times. The challenge for quality professionals is that agilists work in a highly INTRODUCTION collaborative and evolutionary (iterative and Modern software processes are evolutionary, iterative, and incremental) manner, often requiring tradi- incremental in nature. This includes processes such as Rational tional quality professionals to change their Unified Process (RUP) (Kruchten 2004), Extreme Programming approach. (XP) (Beck 2000), Enterprise Unified Process (EUP) (Ambler, Key words: agile model driven development, Nalbone, and Vizdos 2005), and rapid application development agile software development, collaborative (RAD), to name a few. Furthermore, many modern processes development, evolutionary, incremental are agile, which for the sake of simplicity I will characterize as development, iterative development, refac- toring, software processes, test-driven both evolutionary and highly collaborative in nature. The fun- development damental nature of software development is changing, and qual- ity professionals must change with it. In this article I introduce SQP References readers to common agile software development techniques and The Role of Testers in the Agile Methods argue that they lead to software that proves in practice to be of much higher quality than what traditional software teams usu- vol. -

Requirements Engineering and Agile Methodology
Requirements – Architecture - Agility R. Kuehl/J. Scott Hawker p. 1 R I T Software Engineering Requirements Engineering and Agile Processes (You may be thinking) Requirements engineering model as presented is not very agile Writing a SRS, etc. sounds like a classic heavy weight process It is! But, two points to consider as good software engineers: 1. Fit the software methodology and process to the problem 2. Agile processes do equivalent requirement engineering activities – still need requirements validated by stakeholders for success R. Kuehl/J. Scott Hawker p. 2 R I T Software Engineering Requirements and Agile Traditional approach – the requirements document Agile argument against tradition Communication gaps between authors and readers Change cycle is too long Challenging to capture the complete problem and system context Brain’s capacity to retain information Agile answer: Continuous collaboration with stakeholders . Workshops, conversation Stories (index cards) record conversations Are they the requirements? R. Kuehl/J. Scott Hawker p. 3 R I T Software Engineering Requirements Engineering in Agile Processes Where is the Knowledge? Requirements Eng. Agile Methodology 1. Elicitation 1. Stories 2. Iteration design, 2. Analysis customer collaboration 3. Specification 3. Stories, code, acceptance tests, unit 4. Validation tests 5. Management 4. Customer collaboration, acceptance tests 5. Planning cycle, frequent iterations R. Kuehl/J. Scott Hawker p. 4 R I T Software Engineering A Picture Worth a 1000 Words Requirements Waterfall Incremental Evolutionary “Classic” or agile style Design Always maps Construction (coding & testing) Deployment The Requirements Engineering Model The General Software Engineering Framework R. Kuehl/J. Scott Hawker p. 5 R I T Software Engineering R.