Analysis and Prototyping of the RELOAD Protocol
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On IP Networking Over Tactical Links
On IP Networking over Tactical Links Claude Bilodeau The work described in this document was sponsored by the Department of National Defence under Work Unit 5co. Defence R&D Canada √ Ottawa TECHNICAL REPORT DRDC Ottawa TR 2003-099 Communications Research Centre CRC-RP-2003-008 August 2003 On IP networking over tactical links Claude Bilodeau Communications Research Centre The work described in this document was sponsored by the Department of National Defence under Work Unit 5co. Defence R&D Canada - Ottawa Technical Report DRDC Ottawa TR 2003-099 Communications Research Centre CRC RP-2003-008 August 2003 © Her Majesty the Queen as represented by the Minister of National Defence, 2003 © Sa majesté la reine, représentée par le ministre de la Défense nationale, 2003 Abstract This report presents a cross section or potpourri of the numerous issues that surround the tech- nical development of military IP networking over disadvantaged network links. In the first sec- tion, multi-media services are discussed with regard to three aspects: applications, operational characteristics and service models. The second section focuses on subnetworks and bearers; mainly impairments caused by characteristics of the wireless environment. An overview of the Iris tactical bearers is provided as an example of a tactical IP environment. The last section looks at how IP can integrate these two elements i.e. multi-media services and impaired sub- network links. These three sections are unified by a common theme, quality of service, which runs in the background of the discussions. Résumé Ce rapport présente une coupe transversale ou pot-pourri de questions reliées au développe- ment technique des réseaux militaires IP pour des liaisons défavorisées. -

RADIUS and Freeradius
RADIUS and FreeRADIUS Frank Kuse Presented at AfNOG 2018 Dakar Ingredients Theory What is RADIUS Why use RADIUS How RADIUS works User databases Attributes Practical Installing FreeRADIUS Configuration of Radius with LDAP Database backend Testing Radius Authentication with LDAP user account What is RADIUS? Remote Authentication Dial In User Service Authentication “Who are you?” Authorization “What services am I allowed to give you?” Accounting “What did you do with my services while you were using them?,,Accounting information may be used to track the user's usage for charging purposes Why RADIUS? What are the alternatives? LDAP, Kerberos, Active Directory Advantages of RADIUS: Lightweight and efficient Supported by many clients, e.g. 802.1x, switches and routers Disadvantages of RADIUS: Limited attribute set, limited use for desktop authentication How does RADIUS work? Authentication Password authentication, plain text and hashed Lookup in various user databases: passwd, SQL, text Authorization Using a set of rules or other templates Accounting Measuring, communicating and recording resources accessed by user See Wikipedia for list of RFCs RADIUS Architecture (1) RADIUS protocol is between NAS(Network Access Server) or a RAS(Remote Access server) and AAA server NAS controls access to protected resource RADIUS Architecture (2) Scenario 1 In this scenario, a front-end NAS (network access server) or RAS (remote access server) performs authentication of a user with a backend RADIUS server. The NAS/RAS sends user information (credentials) to the RADIUS server carried in RADIUS packets. The RADIUS server implements the access policy (who is granted access with what authorizations) or may retrieve policies from a database through LDAP (Lightweight Directory Access Protocol). -

Reference Manual GUI Graphical User Interface EAGLE One Rel. 5.3
Reference Manual GUI Graphical User Interface Industrial Ethernet Firewall EAGLE One RM GUI EAGLE One Technical Support Release 5.3.0 09/2013 https://hirschmann-support.belden.eu.com The naming of copyrighted trademarks in this manual, even when not specially indicated, should not be taken to mean that these names may be considered as free in the sense of the trademark and tradename protection law and hence that they may be freely used by anyone. © 2013 Hirschmann Automation and Control GmbH Manuals and software are protected by copyright. All rights reserved. The copying, reproduction, translation, conversion into any electronic medium or machine scannable form is not permitted, either in whole or in part. An exception is the preparation of a backup copy of the software for your own use. For devices with embedded software, the end-user license agreement on the enclosed CD/DVD applies. The performance features described here are binding only if they have been expressly agreed when the contract was made. This document was produced by Hirschmann Automation and Control GmbH according to the best of the company's knowledge. Hirschmann reserves the right to change the contents of this document without prior notice. Hirschmann can give no guarantee in respect of the correctness or accuracy of the information in this document. Hirschmann can accept no responsibility for damages, resulting from the use of the network components or the associated operating software. In addition, we refer to the conditions of use specified in the license contract. You can get the latest version of this manual on the Internet at the Hirschmann product site (www.hirschmann.com). -

SAP Business Connector SAP Adapter Guide
SAP Business Connector SAP Adapter Guide SAP SYSTEM Release 4.7 SAP® AG Neurottstr. 16 D-69190 Walldorf SAP AG SAP Business Connector SAP Adapter Guide Copyright ©Copyright 2003 SAP AG. All rights reserved. No part of this description of functions may be reproduced or transmitted in any form or for any purpose without the express permission of SAP AG. The information contained herein may be changed without prior notice. Some software products marketed by SAP AG and its distributors contain proprietary software components of other software vendors. Microsoft®, WINDOWS® and EXCEL®, NT® and SQL-Server® are registered trademarks of Microsoft Corporation. IBM®, OS/2®, DB2/6000®, AIX®, OS/400® and AS/400® are registered trademarks of IBM Corporation. OSF/Motif® is a registered trademark of Open Software Foundation. ORACLE® is a registered trademark of ORACLE Corporation, California, USA. webMethods® is a registered trademark of webMethods Incorporated, Virginia, USA. INFORMIX®-OnLine for SAP is a registered trademark of Informix Software Incorporated. UNIX® and X/Open® are registered trademarks of SCO Santa Cruz Operation. SAP®, R/2®, R/3®, RIVA®, ABAP/4®, SAPaccess®, SAPmail®, SAPoffice®, SAP-EDI®, SAP Business Workflow®, SAP EarlyWatch®, SAP ArchiveLink®, R/3 Retail®, ALE/WEB®, SAPTRONIC® are registered trademarks of SAP AG. All rights reserved. SAP Business Connector ii SAP AG SAP Business Connector SAP Adapter Guide Typographical Conventions Type Style Description Interface Text Words or characters that appear on the screen. This includes field names, screen titles, pushbuttons, menu names, and menu options. Document Title Cross-references to other documentation. User Entry Words and characters that you enter exactly as they appear in the documentation. -

Hrpc Research Group Presentation
Proposed Human Rights Protocol Considerations Research Group IRTF Chairs: Avri Doria & Niels ten Oever Presentation: Joana Varon & Niels ten Oever March 27 2015 - IETF92 Dallas 1 Agenda ● Agenda ● Jabber scribe, note takers ● Notewell ● Introduction ● Status of proposed research group ● Context of research ● Discussion of draft draft-doria-hrpc-proposal-01 ● Next steps ● Other relevant research, issues or topics 2 ● Discussion ● Note Well Any submission to the IETF intended by the Contributor for publication as all or part of an IETF Internet-Draft or RFC and any statement made within the context of an IETF activity is considered an "IETF Contribution". Such statements include oral statements in IETF sessions, as well as written and electronic communications made at any time or place, which are addressed to: • The IETF plenary session • The IESG, or any member thereof on behalf of the IESG • Any IETF mailing list, including the IETF list itself, any working group or design team list, or any other list functioning under IETF auspices • Any IETF working group or portion thereof • Any Birds of a Feather (BOF) session • The IAB or any member thereof on behalf of the IAB • The RFC Editor or the Internet-Drafts function All IETF Contributions are subject to the rules of RFC 5378 and RFC 3979 (updated by RFC 4879). Statements made outside of an IETF session, mailing list or other function, that are clearly not intended to be input to an IETF activity, group or function, are not IETF Contributions in the context of this notice. Please consult RFC 5378 and RFC 3979 for details. -

Network Models and Protocols
669-5ch01.fm Page 1 Friday, April 12, 2002 2:01 PM CHAPTER 1 Network Models and Protocols EXAM OBJECTIVES fter completing this chapter, you will be able to meet the following Network Administration Exam objectives: 1.1 Layered Network Models A •Identify the purpose of each layer in the TCP/IP 1.2 The Layers of the TCP/IP 5-layer model. 5-Layer Model •Describe the functionality of each of the following 1.3 Network Protocols Network Protocols: TCP, UDP, IP, and ICMP. 1.4 Peer-to-Peer Communication •Describe the relationship between the following Network Protocols: TCP, UDP, IP, and ICMP. 1.5 TCP/IP Protocols by Name •Describe peer-to-peer communication. and Function To help you meet these objectives, this chapter covers the following topics: •layered network models •the layers of the TCP/IP 5-layer model •network protocols •peer-to-peer communications •TCP/IP protocols by name and function 1 669-5ch01.fm Page 2 Friday, April 12, 2002 2:01 PM 2 Chapter 1 | Network Models and Protocols 1.1 Layered Network Models This chapter first introduces layered network models and then describes the services provided by each layer of the model. We then briefly describe, in the context of a protocol stack, the network protocols that pro- vide the services to upper layer protocols or applications at each layer. You will learn about the features of the most important network proto- cols, TCP/UDP/IP and ICMP, and this information will serve as the foundation for later chapters that cover these protocols in greater detail. -

RFC 2626 the Internet and the Millennium Problem (Year 2000) June 1999
Network Working Group P. Nesser II Request for Comments: 2626 Nesser & Nesser Consulting Category: Informational June 1999 The Internet and the Millennium Problem (Year 2000) Status of this Memo This memo provides information for the Internet community. It does not specify an Internet standard of any kind. Distribution of this memo is unlimited. Copyright Notice Copyright (C) The Internet Society (1999). All Rights Reserved. Abstract The Year 2000 Working Group (WG) has conducted an investigation into the millennium problem as it regards Internet related protocols. This investigation only targeted the protocols as documented in the Request For Comments Series (RFCs). This investigation discovered little reason for concern with regards to the functionality of the protocols. A few minor cases of older implementations still using two digit years (ala RFC 850) were discovered, but almost all Internet protocols were given a clean bill of health. Several cases of "period" problems were discovered, where a time field would "roll over" as the size of field was reached. In particular, there are several protocols, which have 32 bit, signed integer representations of the number of seconds since January 1, 1970 which will turn negative at Tue Jan 19 03:14:07 GMT 2038. Areas whose protocols will be effected by such problems have been notified so that new revisions will remove this limitation. 1. Introduction According to the trade press billions of dollars will be spend the upcoming years on the year 2000 problem, also called the millennium problem (though the third millennium will really start in 2001). This problem consists of the fact that many software packages and some protocols use a two-digit field for the year in a date field. -

Lab - Researching Rfcs
Lab - Researching RFCs Objectives Part 1: RFC Editor Navigate to the RFC Editor. Search for RFCs using keywords. Find RFCs by status. Search for humorous RFCs. Part 2: Publishing RFCs Background / Scenario Request for Comments (RFCs) were created by Steve Crocker to help record notes on development of Advanced Research Projects Agency Network (ARPANET) in 1969 and eventually evolved into an official collection of memorandum that describes topics that are mainly related to the Internet and the TCP/IP protocol suite. Today the RFCs are managed by the IETF. There are currently over 6,000 RFCs, and the complete list is available at http://www.ietf.org/download/rfc-index.txt. In this lab, you will learn how an RFC is published today by IETF. Additionally, you will also identify a few well- known RFCs that are used in your network. You can also find a few non-technical RFCs that can provide information or engineering humor. Required Resources Device with Internet access Part 1: RFC Editor RFCs started as a collection of memorandum on the development of the first Internet (ARPANET). In this collection, only a few RFCs are considered as Internet standards. Most of the RFCs describe experimental protocols. Some of the RFCs are only informational. The main purpose of RFCs is to stimulate comment and discussion. Step 1: Navigate to the RFC Editor. All the published RFCs are available for access at http://www.rfc-editor.org. The RFC Editor is an RFC repository maintained by the IETF. At the top banner of this page, you can click any of the links, and these links direct you to the different searches, databases, and information. -

RFC 8963 Evaluation of a Sample of Rfcs Produced in 2018
Stream: Independent Submission RFC: 8963 Category: Informational Published: January 2021 ISSN: 2070-1721 Author: C. Huitema Private Octopus Inc. RFC 8963 Evaluation of a Sample of RFCs Produced in 2018 Abstract This document presents the author's effort to understand the delays involved in publishing an idea in the IETF or through the Independent Stream, from the first individual draft to the publication of the RFC. We analyze a set of randomly chosen RFCs approved in 2018, looking for history and delays. We also use two randomly chosen sets of RFCs published in 2008 and 1998 for comparing delays seen in 2018 to those observed 10 or 20 years ago. The average RFC in the 2018 sample was produced in 3 years and 4 months, of which 2 years and 10 months were spent in the working group, 3 to 4 months for IETF consensus and IESG review, and 3 to 4 months in RFC production. The main variation in RFC production delays comes from the AUTH48 phase. We also measure the number of citations of the chosen RFC using Semantic Scholar, and compare citation counts with what we know about deployment. We show that citation counts indicate academic interest, but correlate only loosely with deployment or usage of the specifications. Counting web references could complement that. Status of This Memo This document is not an Internet Standards Track specification; it is published for informational purposes. This is a contribution to the RFC Series, independently of any other RFC stream. The RFC Editor has chosen to publish this document at its discretion and makes no statement about its value for implementation or deployment. -

Requirements for Ipv6 in ICT Equipment
Requirements for IPv6 in ICT Equipment Proposal authors: • Merike Käo, <[email protected]> • Jan Žorž, <[email protected]> • Sander Steffann, <[email protected]> Document ID: ripe-554 Date: June 2012 Obsoletes: ripe-501 Table of contents: • Introduction o General information on how to use this document o How to specify requirements • Proposed generic text for the tender initiator • Lists of mandatory and optional RFC/3GPP standards support for various hardware and software o IPsec: mandatory or optional o Definitions and descriptions of different types of devices o Lists of required RFC/3GPP standards for different types of hardware o Requirements for "host" equipment o Requirements for consumer grade "Layer 2 switch" equipment o Requirements for enterprise/ISP grade "Layer 2 switch" equipment o Requirements for "router or Layer 3 switch" equipment o Requirements for "network security equipment” o Requirements for CPE equipment o Requirements for mobile devices o Requirements for load balancers: • Requirements for IPv6 support in software • Skill requirements of the systems integrator o Declaration of IPv6 competence • Acknowledgments Introduction To ensure the smooth and cost-efficient uptake of IPv6 across their networks, it is important that governments and large enterprises specify requirements for IPv6 compatibility when seeking tenders for Information and Communication Technology (ICT) equipment and support. This document is intended to provide a Best Current Practice (BCP) and does not specify any standards or policy itself. It can serve as a template that can be used by governments, large enterprises and all other organisations when seeking IPv6 support in their tenders or equipment requirements and offer guidance on what specifications to ask for. -

Advanced Computer Networks - Semester 1 of 5781 Summative Assignment
Advanced Computer Networks - Semester 1 of 5781 Summative Assignment Directions A. Due Date: 1 March 2021 at 11:55pm B. You may work in groups of up to two (2) students. The assignment must be submitted via Moodle. C. Submit your concept maps in DOCX, PDF, or PPTX format via Moodle. D. When submitting via Moodle, each member of the group must submit a copy of the work. Students who do not submit a copy of the work will not be given a grade for the assignment, even if their names appear in the submission of another student. The submission must contain the following items: Concept map for the RFC in PPTX, PDF, or DOCX format. Ten minute video explanation (video or link to video on a video hosting platform). A README file (e.g. README.txt, README.pdf) for each part of the assignment with the following sections: 1. A list of the students in the group, including names and ID numbers 2. A list of how many hours were spent on each part of the assignment E. Submissions missing one or more of the above or not following the above instructions will be penalized 5 points. Advanced Computer Networks Semester 1 of 5781 Summative Assignment Page 2 of 5 Published: 24 January 2021 Due: 1 March 2021 at 11:55pm Computer Networks Protocol Exploration In this assignment you will select a network protocol documented in an RFC, analyze it, use it, and prepare explanations that will be of help to others. You will need to select an RFC from the list provided below or propose one of similar complexity and importance. -
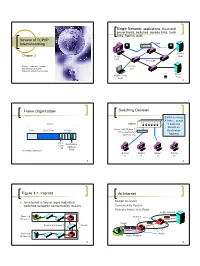
Review of TCP/IP Internetworking Path Frame
Single Network: applications, client and server hosts, switches, access links, trunk links, frames, path Review of TCP/IP Internetworking Path Frame Server Chapter 3 Client Host Host Trunk Link Panko, Corporate Computer Access and Network Security Link Copyright 2004 Prentice-Hall Server Mobile Client Host Host 1 2 Frame Organization Switching Decision Switch receives A frame, sends Frame Switch 123456 It back out Based on Frame with Station C TrailerData Field Header Destination In the destination Address field Address Other Destination Header Field Address Message Structure Field Station Station Station Station A B C D 3 4 Figure 3-1: Internet An Internet Multiple Networks An internet is two or more individual switched networks connected by routers Connected by Routers Path of a Packet is its Route Single Network Switched Routers Network 1 Packet Switched Network 3 Router Switched Route Network 2 Single Network 5 6 1 The global The Internet Internet has Figure 3-6: Frames and Packets thousands of networks Frame 1 Packet Webserver Carrying Packet Browser in Network 1 Network Software Router A Packet Packet Switch Frame 2 Router Carrying Packet Client PC Frame 3 in Network 2 Carrying Packet Route Router Packet in Network 3 Router Packet Switch Server Router B 7 8 Frames and Packets Figure 3-2: TCP/IP Standards (Study Figure) Like passing a shipment (the packet) from a truck (frame) to an airplane (frame) at an airport. Origins { Defense Advanced Research Projects Agency Receiver Shipper Same (DARPA) created the ARPANET Shipment { An