Thesis Submitted for Examination for the Degree of Master of Science in Technology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Internet Engineering Task Force A. Hutton Internet-Draft Unify Intended Status: Standards Track J
Internet Engineering Task Force A. Hutton Internet-Draft Unify Intended status: Standards Track J. Uberti Expires: December 29, 2014 Google M. Thomson Mozilla June 27, 2014 HTTP Connect - Tunnel Protocol For WebRTC draft-hutton-httpbis-connect-protocol-00 Abstract This document describes a mechanism to enable HTTP Clients to provide an indication within a HTTP Connect request as to which protocol will be used within the tunnel established to the Server identified by the target resource. The tunneled protocol is declared using the Tunnel- Protocol HTTP Request header field. Label usage relating to the use of HTTP Connect by WebRTC clients (e.g. turn, webrtc) are described in this document. Status of This Memo This Internet-Draft is submitted in full conformance with the provisions of BCP 78 and BCP 79. Internet-Drafts are working documents of the Internet Engineering Task Force (IETF). Note that other groups may also distribute working documents as Internet-Drafts. The list of current Internet- Drafts is at http://datatracker.ietf.org/drafts/current/. Internet-Drafts are draft documents valid for a maximum of six months and may be updated, replaced, or obsoleted by other documents at any time. It is inappropriate to use Internet-Drafts as reference material or to cite them other than as "work in progress." This Internet-Draft will expire on December 29, 2014. Copyright Notice Copyright (c) 2014 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust’s Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. -
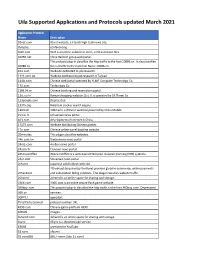
3000 Applications
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

Silk Performer 20.5
Silk Performer 20.5 Help Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 1992-2019 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Silk Performer are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2019-10-28 ii Contents Silk Performer Workbench 20.5 .........................................................................6 What's New in Silk Performer 20.5 ......................................................................................6 Results Publishing with InfluxDB and Grafana ......................................................... 6 Record and Replay Windows File Selection Dialog in SAPGUI ............................... 6 Granular Selection of Measures for Real-time Monitoring ........................................6 Web on Protocol-level Enhancements ......................................................................6 Browser-driven Load Testing Enhancements ...........................................................7 CloudBurst Enhancements .......................................................................................7 Workbench and Editor Enhancements .....................................................................7 Technology Updates .................................................................................................7 Getting Started ....................................................................................................................7 -

An Investigation on Detecting Applications Hidden in Ssl Streams Using Machine Learning Techniques
AN INVESTIGATION ON DETECTING APPLICATIONS HIDDEN IN SSL STREAMS USING MACHINE LEARNING TECHNIQUES by Curtis S. McCarthy Submitted in partial fulfillment of the requirements for the degree of Master of Electronic Commerce at Dalhousie University Halifax, Nova Scotia August 2010 c Copyright by Curtis S. McCarthy, 2010 DALHOUSIE UNIVERSITY FACULTY OF COMPUTER SCIENCE The undersigned hereby certify that they have read and recommend to the Faculty of Graduate Studies for acceptance a thesis entitled “AN INVESTIGATION ON DETECTING APPLICATIONS HIDDEN IN SSL STREAMS USING MACHINE LEARNING TECHNIQUES” by Curtis S. McCarthy in partial fulfillment of the requirements for the degree of Master of Electronic Commerce. Dated: August 13, 2010 Supervisor: Dr. Nur Zincir-Heywood Readers: Dr. Vlado Keselj Dr. Evangelos Milios ii DALHOUSIE UNIVERSITY DATE: August 13, 2010 AUTHOR: Curtis S. McCarthy TITLE: AN INVESTIGATION ON DETECTING APPLICATIONS HIDDEN IN SSL STREAMS USING MACHINE LEARNING TECHNIQUES DEPARTMENT OR SCHOOL: Faculty of Computer Science DEGREE: M.E.C. CONVOCATION: October YEAR: 2010 Permission is herewith granted to Dalhousie University to circulate and to have copied for non-commercial purposes, at its discretion, the above title upon the request of individuals or institutions. Signature of Author The author reserves other publication rights, and neither the thesis nor extensive extracts from it may be printed or otherwise reproduced without the author’s written permission. The author attests that permission has been obtained for the use of any copyrighted material appearing in the thesis (other than brief excerpts requiring only proper acknowledgement in scholarly writing) and that all such use is clearly acknowledged. iii Table of Contents List of Figures ................................. -

IOLAN Secure User's Guide V5.0
IOLAN Secure User’s Guide V5.0 Updated: June 2020 Revision: A.06.29-2020 Document Part: 5500431-10 (Rev D) IOLAN Secure User’s Guide V5.0 Preface Audience This guide is for the networking professional managing your IOLAN. Before using this guide, you should be familiar with the concepts and terminology of Ethernet and local area networking. Purpose This guide provides the information that you need to configure and manage your Perle IOLAN Product. For Web Manager (GUI) users, this guide provides the navigation reference that can be used within web sessions for each feature. Product installation information can be found in the IOLAN Hardware Installation Guide for your product model on our Perle website at www.perle.com and in the Quick Start Guide that came with your product. Additional Documentation Document Description IOLAN Hardware Installation Guide Product specific hardware guide on how to install your IOLAN. IOLAN Quick Start Guide Product specific Quick Start Guide that came with your IOLAN. IOLAN CLI (Command Reference Command reference guide using CLI commands to configure the Guide) Guide V5.0 and greater IOLAN (this is an advanced way to configure the IOLAN) Document Conventions This document contains the following conventions: Most text is presented in the typeface used in this paragraph. Other typefaces are used to help you identify certain types of information. The other typefaces are: Note: Means reader take note: notes contain helpful suggestions. Guide Updates This guide may be updated from time to time and is available at no charge from the download area of Perle’s web site at https://www.perle.com/downloads/ Licensing All Perle software pre-installed in Perle Products or downloaded from any other source or media is governed by Perle’s End User License Agreement. -

Cisco Firepower Application Detector Reference - VDB 307
Cisco Firepower Application Detector Reference - VDB 307 First Published: 2018-12-04 Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB's public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Fortios-5.6-Firewall.Pdf
FortiOS™ Handbook - Firewall VERSION 5.6.9 FORTINET DOCUMENT LIBRARY https://docs.fortinet.com FORTINET VIDEO GUIDE https://video.fortinet.com FORTINET KNOWLEDGE BASE http://kb.fortinet.com FORTINET BLOG https://blog.fortinet.com CUSTOMER SERVICE & SUPPORT https://support.fortinet.com FORTINET NSE INSTITUTE (TRAINING) https://training.fortinet.com/ FORTIGUARD CENTER https://fortiguard.com FORTICAST http://forticast.fortinet.com END USER LICENSE AGREEMENT AND PRIVACY POLICY https://www.fortinet.com/doc/legal/EULA.pdf https://www.fortinet.com/corporate/about-us/privacy.html FEEDBACK Email: [email protected] June 4, 2019 FortiOS™ Handbook - Firewall 01-563-1248222-20180124 TABLE OF CONTENTS Change Log 15 Firewall 16 How this Guide is Organized 16 Fundamentals 16 Firewall Optimization 18 How does a FortiGate Protect Your Network? 18 What's new for Firewall in 5.6 20 New Firewall Features in 5.6.4 20 Using a FortiCache as a cache service 20 New Firewall Features in 5.6.3 20 Multi-port support for Explicit Proxy (402775) 20 Nturbo support CAPWAP traffic and fix IPsec IPv6 firewall policy code typo (290708) (423323) 20 Toggling SNAT in Central SNAT policies (434981) 21 Improved wildcard support for firewall fqdn (444646) 22 Policy Matching based on Referrer Headers and Query Strings (446257) 22 New Firewall Features in 5.6.1 24 Improvement to NAT column in Policy List Display (305575) 24 GUI support for adding Internet-services to proxy-policies (405509) 25 Inline editing of profile groups on policy (409485) 25 Rename "action" to "nat" in -

Cisco IOS Security Command Reference: Commands M to R
Cisco IOS Security Command Reference: Commands M to R Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB's public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Virtual Private Networks
Concepts & Examples ScreenOS Reference Guide Virtual Private Networks Release 6.3.0, Rev. 02 Published: 2012-12-10 Revision 02 Copyright © 2012, Juniper Networks, Inc. Juniper Networks, Inc. 1194 North Mathilda Avenue Sunnyvale, California 94089 USA 408-745-2000 www.juniper.net Juniper Networks, Junos, Steel-Belted Radius, NetScreen, and ScreenOS are registered trademarks of Juniper Networks, Inc. in the United States and other countries. JunosE is a trademark of Juniper Networks, Inc. All other trademarks, service marks, registered trademarks, or registered service marks are the property of their respective owners. Juniper Networks assumes no responsibility for any inaccuracies in this document. Juniper Networks reserves the right to change, modify, transfer, or otherwise revise this publication without notice. Products made or sold by Juniper Networks or components thereof might be covered by one or more of the following patents that are owned by or licensed to Juniper Networks: U.S. Patent Nos. 5,473,599, 5,905,725, 5,909,440, 6,192,051, 6,333,650, 6,359,479, 6,406,312, 6,429,706, 6,459,579, 6,493,347, 6,538,518, 6,538,899, 6,552,918, 6,567,902, 6,578,186, and 6,590,785. Copyright © 2009, Juniper Networks, Inc. All rights reserved. Revision History December 2012—Revision 02 Content subject to change. The information in this document is current as of the date listed in the revision history. SOFTWARE LICENSE The terms and conditions for using this software are described in the software license contained in the acknowledgment to your purchase order or, to the extent applicable, to any reseller agreement or end-user purchase agreement executed between you and Juniper Networks.