The Onions Have Eyes: a Comprehensive Structure and Privacy Analysis of Tor Hidden Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations
UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations Title A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Permalink https://escholarship.org/uc/item/6w76f8x7 Author Swift, Kathy Publication Date 2017 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA Santa Barbara A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Education by Kathleen Anne Swift Committee in charge: Professor Richard Duran, Chair Professor Diana Arya Professor William Robinson September 2017 The dissertation of Kathleen Anne Swift is approved. ................................................................................................................................ Diana Arya ................................................................................................................................ William Robinson ................................................................................................................................ Richard Duran, Committee Chair June 2017 A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Copyright © 2017 by Kathleen Anne Swift iii ACKNOWLEDGEMENTS I would like to thank the members of my committee for their advice and patience as I worked on gathering and analyzing the copious amounts of research necessary to -

Pairing-Based Onion Routing with Improved Forward Secrecy ∗
Pairing-Based Onion Routing with Improved Forward Secrecy ∗ Aniket Kate Greg M. Zaverucha Ian Goldberg David R. Cheriton School of Computer Science University of Waterloo Waterloo, ON, Canada N2L 3G1 {akate,gzaveruc,iang}@cs.uwaterloo.ca Abstract This paper presents new protocols for onion routing anonymity networks. We define a provably secure privacy-preserving key agreement scheme in an identity-based infrastructure setting, and use it to forge new onion routing circuit constructions. These constructions, based on a user’s selection, offer immediate or eventual forward secrecy at each node in a circuit and require significantly less computation and communication than the telescoping mechanism used by Tor. Further, the use of the identity-based infrastructure also leads to a reduction in the required amount of authenticated directory information. Therefore, our constructions provide practical ways to allow onion routing anonymity networks to scale gracefully. Keywords: onion routing, Tor, pairing-based cryptography, anonymous key agreement, forward secrecy 1 Introduction Over the years, a large number of anonymity networks have been proposed and some have been implemented. Common to many of them is onion routing [RSG98], a technique whereby a message is wrapped in multiple layers of encryption, forming an onion. As the message is delivered via a number of intermediate onion routers (ORs), or nodes, each node decrypts one of the layers, and forwards the message to the next node. This idea goes back to Chaum [Cha81] and has been used to build both low- and high-latency communication networks. A common realization of an onion routing system is to arrange a collection of nodes that will relay traffic for users of the system. -

How to Get the Daily Stormer Be Found on the Next Page
# # Publishing online In print because since 2013, offline Stormer the (((internet))) & Tor since 2017. is censorship! The most censored publication in history Vol. 97 Daily Stormer ☦ Sunday Edition 23–30 Jun 2019 What is the Stormer? No matter which browser you choose, please continue to use Daily Stormer is the largest news publication focused on it to visit the sites you normally do. By blocking ads and track- racism and anti-Semitism in human history. We are signifi- ers your everyday browsing experience will be better and you cantly larger by readership than many of the top 50 newspa- will be denying income to the various corporate entities that pers of the United States. The Tampa Tribune, Columbus Dis- have participated in the censorship campaign against the Daily patch, Oklahoman, Virginian-Pilot, and Arkansas Democrat- Stormer. Gazette are all smaller than this publication by current read- Also, by using the Tor-based browsers, you’ll prevent any- ership. All of these have dozens to hundreds of employees one from the government to antifa from using your browsing and buildings of their own. All of their employees make more habits to persecute you. This will become increasingly rele- than anyone at the Daily Stormer. We manage to deliver im- vant in the years to come. pact greater than anyone in this niche on a budget so small you How to support the Daily Stormer wouldn’t believe. The Daily Stormer is 100% reader-supported. We do what Despite censorship on a historically unique scale, and The we do because we are attempting to preserve Western Civiliza- Daily Stormer becoming the most censored publication in his- tion. -

Name Synopsis Description Arguments Options
W3M(1) General Commands Manual W3M(1) NAME w3m − a text based web browser and pager SYNOPSIS w3m [OPTION]... [ file | URL ]... DESCRIPTION w3m is a text based browser which can display local or remote web pages as well as other documents. It is able to process HTML tables and frames but it ignores JavaScript and Cascading Style Sheets. w3m can also serveasapager for text files named as arguments or passed on standard input, and as a general purpose directory browser. w3m organizes its content in buffers or tabs, allowing easy navigation between them. With the w3m-img extension installed, w3m can display inline graphics in web pages. And whenever w3m’s HTML rendering capabilities do not meet your needs, the target URL can be handed overtoagraphical browser with a single command. Forhelp with runtime options, press “H” while running w3m. ARGUMENTS When givenone or more command line arguments, w3m will handle targets according to content type. For web, w3m gets this information from HTTP headers; for relative orabsolute file system paths, it relies on filenames. With no argument, w3m expects data from standard input and assumes “text/plain” unless another MIME type is givenbythe user. If provided with no target and no fallback target (see for instance option −v below), w3m will exit with us- age information. OPTIONS Command line options are introduced with a single “−” character and may takeanargument. General options −B with no other target defined, use the bookmark page for startup −M monochrome display −no-mouse deactivate mouse support −num display each line’snumber −N distribute multiple command line arguments to tabs. -
Maelstrom Web Browser Free Download
maelstrom web browser free download 11 Interesting Web Browsers (That Aren’t Chrome) Whether it’s to peruse GitHub, send the odd tweetstorm or catch-up on the latest Netflix hit — Chrome’s the one . But when was the last time you actually considered any alternative? It’s close to three decades since the first browser arrived; chances are it’s been several years since you even looked beyond Chrome. There’s never been more choice and variety in what you use to build sites and surf the web (the 90s are back, right?) . So, here’s a run-down of 11 browsers that may be worth a look, for a variety of reasons . Brave: Stopping the trackers. Brave is an open-source browser, co-founded by Brendan Eich of Mozilla and JavaScript fame. It’s hoping it can ‘save the web’ . Available for a variety of desktop and mobile operating systems, Brave touts itself as a ‘faster and safer’ web browser. It achieves this, somewhat controversially, by automatically blocking ads and trackers. “Brave is the only approach to the Web that puts users first in ownership and control of their browsing data by blocking trackers by default, with no exceptions.” — Brendan Eich. Brave’s goal is to provide an alternative to the current system publishers employ of providing free content to users supported by advertising revenue. Developers are encouraged to contribute to the project on GitHub, and publishers are invited to become a partner in order to work towards an alternative way to earn from their content. Ghost: Multi-session browsing. -

The Elinks Manual the Elinks Manual Table of Contents Preface
The ELinks Manual The ELinks Manual Table of Contents Preface.......................................................................................................................................................ix 1. Getting ELinks up and running...........................................................................................................1 1.1. Building and Installing ELinks...................................................................................................1 1.2. Requirements..............................................................................................................................1 1.3. Recommended Libraries and Programs......................................................................................1 1.4. Further reading............................................................................................................................2 1.5. Tips to obtain a very small static elinks binary...........................................................................2 1.6. ECMAScript support?!...............................................................................................................4 1.6.1. Ok, so how to get the ECMAScript support working?...................................................4 1.6.2. The ECMAScript support is buggy! Shall I blame Mozilla people?..............................6 1.6.3. Now, I would still like NJS or a new JS engine from scratch. .....................................6 1.7. Feature configuration file (features.conf).............................................................................7 -

Cyber Laws for Dark Web: an Analysis of the Range of Crimes and the Level of Effectiveness of Law Over It
An Open Access Journal from The Law Brigade Publishers 1 CYBER LAWS FOR DARK WEB: AN ANALYSIS OF THE RANGE OF CRIMES AND THE LEVEL OF EFFECTIVENESS OF LAW OVER IT Written by Sanidhya Mahendra 5th Year B.A.LL.B.(Hons.) Student, Uttaranchal University, Dehradun, India ABSTRACT In the 21st century, when we say “The future is now”, we mean that everything is possible, everything is accessible, everything is on our fingertips. This is because our entire world today is connected and controlled by the internet. This world wide connectivity offers us everything to use, like from shopping to travelling, from eating to feeding, and even for connecting to the people virtually, however the internet is not just limited to the millions of websites available for our daily use, rather it is far beyond that. We just access the 5 per cent of the entire internet and the rest of it is what may be a true horror for those who have been affected by it. This domain of internet is popularly known as the Dark Web. In this article the author has described the disturbing truths of the Dark Web. The author has described about its history and has pointed out the usage of the same by the criminals. The author further discusses the types of crime that are committed behind the veil of internet. The article thereafter defines the remedies available in various laws of India for the victims of cyber crimes. The author concludes the article with suggestions of improvement in the present laws. KEYWORDS: Dark Net, Dark web, Deep Web, TOR, Onion, Cryptocurrency, privacy, anonymous, VPN, ARPANET, Crawlers, Silk Road, Phishing INTRODUCTION Today the most significant invention is the invention Internet, and it has taken the eyes of all the generation in one go. -

Into the Reverie: Exploration of the Dream Market
Into the Reverie: Exploration of the Dream Market Theo Carr1, Jun Zhuang2, Dwight Sablan3, Emma LaRue4, Yubao Wu5, Mohammad Al Hasan2, and George Mohler2 1Department of Mathematics, Northeastern University, Boston, MA 2Department of Computer & Information Science, Indiana University - Purdue University, Indianapolis, IN 3Department of Mathematics and Computer Science, University of Guam, Guam 4Department of Mathematics and Statistics, University of Arkansas at Little Rock, AK 5Department of Computer Science, Georgia State University, Atlanta, GA [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract—Since the emergence of the Silk Road market in Onymous" in 2014, a worldwide action taken by law enforce- the early 2010s, dark web ‘cryptomarkets’ have proliferated and ment and judicial agencies aimed to put a kibosh on these offered people an online platform to buy and sell illicit drugs, illicit behaviors [5]. Law enforcement interventions such as relying on cryptocurrencies such as Bitcoin for anonymous trans- actions. However, recent studies have highlighted the potential for Onymous, along with exit scams and hacks, have successfully de-anonymization of bitcoin transactions, bringing into question shut down numerous cryptomarkets, including AlphaBay, Silk the level of anonymity afforded by cryptomarkets. We examine a Road, Dream, and more recently, Wall Street [6]. Despite these set of over 100,000 product reviews from several cryptomarkets interruptions, new markets have continued to proliferate. The collected in 2018 and 2019 and conduct a comprehensive analysis authors of [7] note that there appears to be a consistent daily of the markets, including an examination of the distribution of drug sales and revenue among vendors, and a comparison demand of about $500,000 for illicit products on the dark web, of incidences of opioid sales to overdose deaths in a US city. -
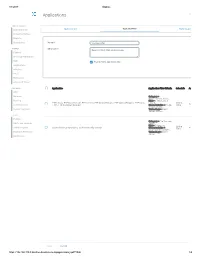
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

Arena Training Guide for Administrators Table of Contents
Arena training guide for administrators Table of contents Preface 4 About this guide 4 Get to know Axiell 4 About Arena 5 Liferay 5 Portlets 5 Language handling 5 Styling 5 Arena architecture 6 Administration in Arena 7 Arena articles 7 Signing in to Arena 7 Signing in to Liferay 8 The Arena administration user interface 8 Accounts 11 User types in Arena 11 Permissions 12 Managing users in Liferay 14 Managing a roles in Liferay 16 Arena portal site administration 17 Admin: installation details 17 Site settings 19 Managing pages 21 Page permissions 21 Navigation 21 Configuring pages 21 Creating a page 22 Deleting a page 23 Arena Nova 25 Focus shortcuts 25 That’s how it works-articles 25 News articles 26 Event articles 26 Branch articles 26 FAQ articles 27 Image resources and image handling 27 Portlets in Arena 28 Symbols in the list of portlets 28 Portlets required for basic Arena functionality 28 Placement of portlets 29 Configuring portlets 30 The control toolbar 30 Look and feel 30 2 Assigning user permissions to portlets and pages 30 Liferay articles 32 Creating a Liferay article 32 Adding a Liferay article on a page 32 Arena articles 33 Approving articles 33 Handling abuse and reviews 34 Admin: moderation 34 Searching in catalogue records 36 Single words 36 Phrases 36 Multiple words 36 Truncation 36 Boolean operators 36 Fuzzy search and the similarity factor 36 Search parameters for catalogue records 37 Search parameters for Arena articles 40 Examples 40 Linking and syntaxes 41 Dynamic links 41 Syntax for similar titles 42 Syntax for other titles by the same author 42 Syntax for dynamic news list 42 3 Preface Simple, stylish and engaging, Arena is perfect for archives, libraries and museums to showcase and organize their collections in the public domain. -

A Framework for Identifying Host-Based Artifacts in Dark Web Investigations
Dakota State University Beadle Scholar Masters Theses & Doctoral Dissertations Fall 11-2020 A Framework for Identifying Host-based Artifacts in Dark Web Investigations Arica Kulm Dakota State University Follow this and additional works at: https://scholar.dsu.edu/theses Part of the Databases and Information Systems Commons, Information Security Commons, and the Systems Architecture Commons Recommended Citation Kulm, Arica, "A Framework for Identifying Host-based Artifacts in Dark Web Investigations" (2020). Masters Theses & Doctoral Dissertations. 357. https://scholar.dsu.edu/theses/357 This Dissertation is brought to you for free and open access by Beadle Scholar. It has been accepted for inclusion in Masters Theses & Doctoral Dissertations by an authorized administrator of Beadle Scholar. For more information, please contact [email protected]. A FRAMEWORK FOR IDENTIFYING HOST-BASED ARTIFACTS IN DARK WEB INVESTIGATIONS A dissertation submitted to Dakota State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cyber Defense November 2020 By Arica Kulm Dissertation Committee: Dr. Ashley Podhradsky Dr. Kevin Streff Dr. Omar El-Gayar Cynthia Hetherington Trevor Jones ii DISSERTATION APPROVAL FORM This dissertation is approved as a credible and independent investigation by a candidate for the Doctor of Philosophy in Cyber Defense degree and is acceptable for meeting the dissertation requirements for this degree. Acceptance of this dissertation does not imply that the conclusions reached by the candidate are necessarily the conclusions of the major department or university. Student Name: Arica Kulm Dissertation Title: A Framework for Identifying Host-based Artifacts in Dark Web Investigations Dissertation Chair: Date: 11/12/20 Committee member: Date: 11/12/2020 Committee member: Date: Committee member: Date: Committee member: Date: iii ACKNOWLEDGMENT First, I would like to thank Dr. -

Introduction Points
Introduction Points Ahmia.fi - Clearnet search engine for Tor Hidden Services (allows you to add new sites to its database) TORLINKS Directory for .onion sites, moderated. Core.onion - Simple onion bootstrapping Deepsearch - Another search engine. DuckDuckGo - A Hidden Service that searches the clearnet. TORCH - Tor Search Engine. Claims to index around 1.1 Million pages. Welcome, We've been expecting you! - Links to basic encryption guides. Onion Mail - SMTP/IMAP/POP3. ***@onionmail.in address. URSSMail - Anonymous and, most important, SECURE! Located in 3 different servers from across the globe. Hidden Wiki Mirror - Good mirror of the Hidden Wiki, in the case of downtime. Where's pedophilia? I WANT IT! Keep calm and see this. Enter at your own risk. Site with gore content is well below. Discover it! Financial Services Currencies, banks, money markets, clearing houses, exchangers. The Green Machine Forum type marketplace for CCs, Paypals, etc.... Some very good vendors here!!!! Paypal-Coins - Buy a paypal account and receive the balance in your bitcoin wallet. Acrimonious2 - Oldest escrowprovider in onionland. BitBond - 5% return per week on Bitcoin Bonds. OnionBC Anonymous Bitcoin eWallet, mixing service and Escrow system. Nice site with many features. The PaypalDome Live Paypal accounts with good balances - buy some, and fix your financial situation for awhile. EasyCoin - Bitcoin Wallet with free Bitcoin Mixer. WeBuyBitcoins - Sell your Bitcoins for Cash (USD), ACH, WU/MG, LR, PayPal and more. Cheap Euros - 20€ Counterfeit bills. Unbeatable prices!! OnionWallet - Anonymous Bitcoin Wallet and Bitcoin Laundry. BestPal BestPal is your Best Pal, if you need money fast. Sells stolen PP accounts.