Connecting Palladio with Multicore CPU Simulators
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Toward Harnessing High-Level Language Virtual Machines for Further Speeding up Weak Mutation Testing
2012 IEEE Fifth International Conference on Software Testing, Verification and Validation Toward Harnessing High-level Language Virtual Machines for Further Speeding up Weak Mutation Testing Vinicius H. S. Durelli Jeff Offutt Marcio E. Delamaro Computer Systems Department Software Engineering Computer Systems Department Universidade de Sao˜ Paulo George Mason University Universidade de Sao˜ Paulo Sao˜ Carlos, SP, Brazil Fairfax, VA, USA Sao˜ Carlos, SP, Brazil [email protected] [email protected] [email protected] Abstract—High-level language virtual machines (HLL VMs) have tried to exploit the control that HLL VMs exert over run- are now widely used to implement high-level programming ning programs to facilitate and speedup software engineering languages. To a certain extent, their widespread adoption is due activities. Thus, this research suggests that software testing to the software engineering benefits provided by these managed execution environments, for example, garbage collection (GC) activities can benefit from HLL VMs support. and cross-platform portability. Although HLL VMs are widely Test tools are usually built on top of HLL VMs. However, used, most research has concentrated on high-end optimizations they often end up tampering with the emergent computation. such as dynamic compilation and advanced GC techniques. Few Using features within the HLL VMs can avoid such problems. efforts have focused on introducing features that automate or fa- Moreover, embedding testing tools within HLL VMs can cilitate certain software engineering activities, including software testing. This paper suggests that HLL VMs provide a reasonable significantly speedup computationally expensive techniques basis for building an integrated software testing environment. As such as mutation testing [6]. -

A Post-Apocalyptic Sun.Misc.Unsafe World
A Post-Apocalyptic sun.misc.Unsafe World http://www.superbwallpapers.com/fantasy/post-apocalyptic-tower-bridge-london-26546/ Chris Engelbert Twitter: @noctarius2k Jatumba! 2014, 2015, 2016, … Disclaimer This talk is not going to be negative! Disclaimer But certain things are highly speculative and APIs or ideas might change by tomorrow! sun.misc.Scissors http://www.underwhelmedcomic.com/wp-content/uploads/2012/03/runningdude.jpg sun.misc.Unsafe - What you (don’t) know sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE sun.misc.Unsafe - What you (don’t) know • Internal class (sun.misc Package) • Used inside the JVM / JRE // Unsafe mechanics private static final sun.misc.Unsafe U; private static final long QBASE; private static final long QLOCK; private static final int ABASE; private static final int ASHIFT; static { try { U = sun.misc.Unsafe.getUnsafe(); Class<?> k = WorkQueue.class; Class<?> ak = ForkJoinTask[].class; example: QBASE = U.objectFieldOffset (k.getDeclaredField("base")); java.util.concurrent.ForkJoinPool QLOCK = U.objectFieldOffset (k.getDeclaredField("qlock")); ABASE = U.arrayBaseOffset(ak); int scale = U.arrayIndexScale(ak); if ((scale & (scale - 1)) != 0) throw new Error("data type scale not a power of two"); ASHIFT = 31 - Integer.numberOfLeadingZeros(scale); } catch (Exception e) { throw new Error(e); } } } sun.misc.Unsafe -

Openjdk – the Future of Open Source Java on GNU/Linux
OpenJDK – The Future of Open Source Java on GNU/Linux Dalibor Topić Java F/OSS Ambassador Blog aggregated on http://planetjdk.org Java Implementations Become Open Source Java ME, Java SE, and Java EE 2 Why now? Maturity Java is everywhere Adoption F/OSS growing globally Innovation Faster progress through participation 3 Why GNU/Linux? Values Freedom as a core value Stack Free Software above and below the JVM Demand Increasing demand for Java integration 4 Who profits? Developers New markets, new possibilities Customers More innovations, reduced risk Sun Mindshare, anchoring Java in GNU/Linux 5 License + Classpath GPL v2 Exception • No proprietary forks (for SE, EE) • Popular & trusted • Programs can have license any license • Compatible with • Improvements GNU/Linux remain in the community • Fostering adoption • FSFs license for GNU Classpath 6 A Little Bit Of History Jun 1996: Work on gcj starts Nov 1996: Work on Kaffe starts Feb 1998: First GNU Classpath Release Mar 2000: GNU Classpath and libgcj merge Dec 2002: Eclipse runs on gcj/Classpath Oct 2003: Kaffe switches to GNU Classpath Feb 2004: First FOSDEM Java Libre track Apr 2004: Richard Stallman on the 'Java Trap' Jan 2005: OpenOffice.org runs on gcj Mai 2005: Work on Harmony starts 7 Sun & Open Source Java RIs Juni 2005: Java EE RI Glassfish goes Open Source Mai 2006: First Glassfish release Mai 2006: Java announced to go Open Source November 2006: Java ME RI PhoneME goes Open Source November 2006: Java SE RI Hotspot und Javac go Open Source Mai 2007: The rest of Java SE follows suit 8 Status: JavaOne, Mai 2007 OpenJDK can be fully built from source, 'mostly' Open Source 25,169 Source code files 894 (4%) Binary files (“plugs”) 1,885 (8%) Open Source, though not GPLv2 The rest is GPLv2 (+ CP exception) Sun couldn't release the 4% back then as free software. -

Free Java Developer Room
Room: AW1.121 Free Java Developer Room Saturday 2008-02-23 14:00-15:00 Welcome to the Free Java Meeting Welcome and introduction to the projects, people and themes that make Rich Sands – Mark Reinhold – Mark up the Free Java Meeting at Fosdem. ~ GNU Classpath ~ OpenJDK Wielaard – Tom Marble 15:00-16:00 Mobile Java Take your freedom to the max! Make your Free Java mobile. Christian Thalinger - Guillaume ~ CACAO Embedded ~ PhoneME ~ Midpath Legris - Ray Gans 16:00-16:40 Women in Java Technology Female programmers are rare. Female Java programmers are even more Clara Ko - Linda van der Pal rare. ~ Duchess, Ladies in Java Break 17:00-17:30 Hacking OpenJDK & Friends Hear about directions in hacking Free Java from the front lines. Roman Kennke - Andrew Hughes ~ OpenJDK ~ BrandWeg ~ IcePick 17:30-19:00 VM Rumble, Porting and Architectures Dalibor Topic - Robert Lougher - There are lots of runtimes able to execute your java byte code. But which Peter Kessler - Ian Rogers - one is the best, coolest, smartest, easiest portable or just simply the most fun? ~ Kaffe ~ JamVM ~ HotSpot ~ JikesRVM ~ CACAO ~ ikvm ~ Zero- Christian Thalinger - Jeroen Frijters assembler Port ~ Mika - Gary Benson - Chris Gray Sunday 2008-02-24 9:00-10:00 Distro Rumble So which GNU/Linux distribution integrates java packages best? Find out Petteri Raty - Tom Fitzsimmons - during this distro shootout! ~ Gentoo ~ Fedora ~ Debian ~ Ubuntu Matthias Klose 10:00-11:30 The Free Java Factory OpenJDK and IcedTea, how are they made and how do you test them? David Herron - Lillian Angel - Tom ~ OpenJDK ~ IcedTea Fitzsimmons 11:30-13:00 JIT Session: Discussion Topics Dynamically Loaded Want to hear about -- or talk about -- something the Free Java world and don't see a topic on the agenda? This time is reserved for late binding Tom Marble discussion. -

Eclipse (Software) 1 Eclipse (Software)
Eclipse (software) 1 Eclipse (software) Eclipse Screenshot of Eclipse 3.6 Developer(s) Free and open source software community Stable release 3.6.2 Helios / 25 February 2011 Preview release 3.7M6 / 10 March 2011 Development status Active Written in Java Operating system Cross-platform: Linux, Mac OS X, Solaris, Windows Platform Java SE, Standard Widget Toolkit Available in Multilingual Type Software development License Eclipse Public License Website [1] Eclipse is a multi-language software development environment comprising an integrated development environment (IDE) and an extensible plug-in system. It is written mostly in Java and can be used to develop applications in Java and, by means of various plug-ins, other programming languages including Ada, C, C++, COBOL, Perl, PHP, Python, Ruby (including Ruby on Rails framework), Scala, Clojure, and Scheme. The IDE is often called Eclipse ADT for Ada, Eclipse CDT for C/C++, Eclipse JDT for Java, and Eclipse PDT for PHP. The initial codebase originated from VisualAge.[2] In its default form it is meant for Java developers, consisting of the Java Development Tools (JDT). Users can extend its abilities by installing plug-ins written for the Eclipse software framework, such as development toolkits for other programming languages, and can write and contribute their own plug-in modules. Released under the terms of the Eclipse Public License, Eclipse is free and open source software. It was one of the first IDEs to run under GNU Classpath and it runs without issues under IcedTea. Eclipse (software) 2 Architecture Eclipse employs plug-ins in order to provide all of its functionality on top of (and including) the runtime system, in contrast to some other applications where functionality is typically hard coded. -

Installing Open Java Development Kit – Ojdkbuild for Windows
Installing Open Java Development Kit – ojdkbuild for Windows © IZUM, 2019 IZUM, COBISS, COMARC, COBIB, COLIB, CONOR, SICRIS, E-CRIS are registered trademarks owned by IZUM. CONTENTS 1 Introduction ......................................................................................................... 1 2 OpenJDK distribution .......................................................................................... 1 3 Removing Oracle Java ......................................................................................... 2 4 Installing OJDK – 32bit or 64bit, IcedTea Java .................................................. 3 5 Installing the COBISS3 interface ........................................................................ 7 6 Launching the COBISS3 interface .................................................................... 11 7 COBISS3 interface as a trusted source in IcedTea ojdkbuild ........................... 11 © IZUM, 16. 7. 2019, VOS-NA-EN-380, V1.0 i VOS Installing Open Java Development Kit – ojdkbuild for Windows 1 Introduction At the end of 2018 Oracle announced a new business policy for Java SE which entered into force in April 2019. That is why when you install Java a notification and warning window appears. All versions of Java from 8 u201 onwards not intended for personal use are payable. For this reason, we suggest you do not update Java 8 to a newer version for work purposes. If you want a newer version of Java 8, install OpenJDK 8 and IcedTea. Also, do not install Java 8 on new computers (clients), but install OpenJDK 8 with IcedTea support. 2 OpenJDK distribution OpenJDK 1.8. build for Windows and Linux is available at the link https://github.com/ojdkbuild/ojdkbuild. There you will find versions for the installation. The newest version is always at the top, example from 7 May 2019: © IZUM, 16. 7. 2019, VOS-NA-EN-380, V1.0 1/11 Installing Open Java Development Kit – ojdkbuild for Windows VOS 3 Removing Oracle Java First remove the Oracle Java 1.8 software in Control Panel, Programs and Features. -

Openjdk 8 Getting Started with Openjdk 8 Legal Notice
OpenJDK 8 Getting started with OpenJDK 8 Last Updated: 2021-07-21 OpenJDK 8 Getting started with OpenJDK 8 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. The OpenStack ® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. -

EINLADUNG Zum Gastvortrag Am Freitag, 26
Fachbereich Computerwissenschaften EINLADUNG zum Gastvortrag am Freitag, 26. Nov. 2010, 15:15 Uhr, T01 Institutsgebäude Jakob-Haringer-Str. 2, Itzling von Doug Simon Sun Microsystems Laboratories zum Thema: “What a meta-circular JVM buys you - and what not!” Abstract: Since the open source release of the Maxine VM, it has progressed to the point where it can now run application servers such as Glassfish and WebLogic. With the recent addition of a new compiler that leverages the mature design behind the HotSpot client compiler (aka C1), the VM is on track to deliver performance on par with the HotSpot client compiler and better. At the same time, its adoption by VM researchers and enthusiasts is increasing. That is, we believe the productivity advantages of system level programming in Java are being realized. This talk will highlight and demonstrate the advantages of both the Maxine architecture and of meta-circular JVM development in general. Bio: Doug Simon is a Principle Member of Technical Staff at Oracle working in Sun Labs and is currently leading the Maxine project, an open source Virtual Machine for the JavaTM platform written in Java. Prior to Maxine, Doug co-developed Squawk, a CLDC compliant JVM implemented also in Java. His first project at the labs was investigating secure, fine-grained dynamic provisioning of applications on small devices. Once again, this work was in the context of a VM, this time a modified version of the KVM, which was the last non-Java-in-Java VM Doug hacked on! Doug obtained a Bachelors in Information Technology from the University of Queensland in 1997, graduating with first class honors. -

Openjdk 11 Getting Started with Openjdk 11 Legal Notice
OpenJDK 11 Getting started with OpenJDK 11 Last Updated: 2021-07-21 OpenJDK 11 Getting started with OpenJDK 11 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. The OpenStack ® Word Mark and OpenStack logo are either registered trademarks/service marks or trademarks/service marks of the OpenStack Foundation, in the United States and other countries and are used with the OpenStack Foundation's permission. -
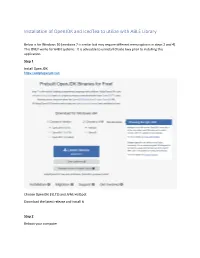
Installation of Openjdk and Icedtea to Utilize with ABLE Library
Installation of OpenJDK and IcedTea to utilize with ABLE Library Below is for Windows 10 (windows 7 is similar but may require different menu options in steps 2 and 4). This ONLY works for 64Bit systems. It is advisable to uninstall Oracle Java prior to installing this application. Step 1 Install Open JDK https://adoptopenjdk.net/ Choose OpenJDK 8 (LTS) and JVM: HotSpot Download the latest release and Install it Step 2 Reboot your computer Step 3 Run your JNLP file by clicking your link OR by double clicking on the JNLP file on your desktop. You should see the IcedTea loading window before the Java application starts up. If you do NOT see the IcedTea loading window AND you have Oracle Java installed: 1. Right click on your JNLP file and choose Open With 2. 3. Select Choose another app 4. If you see javaws.exe in your list choose this (do not choose Java™ Web Launcher (this is the Oracle version of Java) 5. If you do NOT see javaws.exe as an option choose More Apps and scroll to the bottom and click on the Use Another App on this PC link 6. Browse to: C:\Program Files\IcedTeaWeb\WebStart\bin in the window that opens and choose javaws.exe and click Open 7. The next time you to this javaws.exe should be in your menu as an option – you can also choose Always Use this app the next time and you should be able to double click a JNLP file to open using IcedTea Web Remember the OpenJDK will ONLY work on the JNLP files with “Open” in the name – this helps to differentiate between the standard JNLP files and the ones that work with OpenJDK. -

Title of the Work
Masters Thesis Performance Analysis and Improvement of GuestVM for running OSGi-based MacroComponents by Jianyuan Li Due date 22. August 2010 Advisors: Jan Simon Rellermeyer Adrian Sch¨upbach Prof. Gustavo Alonso ETH Zurich, Systems Group Department of Computer Science 8092 Zurich, Switzerland ii Abstract MacroComponents defined as software components that run in isolated environ- ments but without the full foundations of the traditional software stack is an alternative, lightweight and composable approach to virtualization. GuestVM, which is a bare-metal, meta-circular Java Virtual Machine, is the core of the MacroComponents in this work. It sits directly between Xen hypervisor and OSGi applications to play a role as an operating system as well as a JVM. GuestVM has the potential for good performance because of its minimal, all- Java software stack and the elimination of traditional operating system layer. Nevertheless, GuestVM performs very poor in reality according to the previous work. The main aim of this work is to analyze and figure out the performance bottlenecks and remove them to improve GuestVM's performance, and thus make it a possible solution for MacroComponents in practice. Through the evaluations, GuestVM does not add overhead to Maxine in terms of memory access, and the performance is comparable to HotSpot JVM without considering the optimization of HotSpot JVM's working memory. By optimiz- ing code, giving sufficient file system buffer cache and implementing a prefetch- ing mechanism, the I/O performance of GuestVM on average can be improved to only 50% slower than HotSpot JVM (even outperforms HotSpot JVM in many cases), and 4 times faster than Maxine. -

What's Behind JOSM ?
What’s behind JOSM ? @VincentPrivat – #sotm2019 – Heidelberg – CC-BY-SA 4.0 Intro : Quick facts about JOSM Oldest still developed: created in 2005, only one year after OSM Most used editor since 2010 (67 % of 2018 contributions) Feature-rich, extensible Available on Linux, Windows, macOS Translated in 36 languages Important community Site : https://josm.openstreetmap.de 2 Intro : Plan 1) Technologies & Extensibility 2) Project Management 3) Statistics 4) Work in progress & to come 3 1. Technologies & extensibility Core features, formats and protocols Load, Edit, Render, Validate, Upload : ● OSM data: XML, JSON (new in 2018-08) ● Traces: GPX, NMEA, RTKLib (new in 2019-08) ● OSM notes: XML With the help of : ● Edition/Search/Filtering/Remote control tools ● OSM presets: XML ● Mappaint styles: MapCSS ● Validation rules: Java, MapCSS ● Imagery: WMS, TMS, WMTS ● Geottaged pictures: JPG, PNG ● Audio recordings: WAV, MP3/AAC/AIF (new in 2017-06) 5 Technologies Java 8+ / Swing Very few dependencies Apache Commons Compress : Bzip2, XZ compression Apache Commons JCS: Imagery tile cache Apache Commons Validator : Validation routines (URLs…) SvgSalamander : SVG Support Metadata Extractor : EXIF metadata reading of geotagged pictures Signpost : OAuth authentification Jsonp: JSON support * opening_hours.js: opening_hours syntax * = JavaScript libraries at risk * overpass-wizard: Overpass API wizard 6 Extensions : plugins More than 100 plugins adding for example: ● New data formats/ protocols : ● pbf, o5m, geojson, opendata (csv, ods, xls, shapefile,